适用于大规模地震数据存储、快速定位的方法及装置与流程
本发明涉及石油地震勘探资料数据存储领域,更具体地讲,涉及一种适用于大规模地震数据存储、快速定位的方法及装置。
背景技术:
当前的石油天然气地震勘探工作中,由于可控震源高效采集技术的推广应用和高密度三维地震勘探的迅速发展,地震观测采样精度越来越高,采集的数据越来越大。采集获得的数据量呈几何指数增长,从几十tb到上百tb,甚至更大。同时,多业务的并发应用规模对于地震数据存储的访问频率越来越高。如此庞大的数据量和应用规模对地震数据的存储技术提出了新的要求。地震数据存储的文件系统必须具备对pb甚至eb级存储空间进行管理的能力。
由于现有的大多数计算机集群文件系统均采用对象存储的方法来管理数据,每个文件被分成固定大小的对象存储在系统中,随着存储总量和处理性能的提高,系统中对象的数量和其访问频率均会有大幅度的增加,数据放置和定位的开销随存储对象数量的增多而增加。当地震数据的存储规模达到pb级时,文件系统需要对超过上亿规模的对象提供放置和定位服务。特别是当数据多以小文件的方式存储时,需管理的对象位置信息可达到万亿规模。但是受计算机集群文件系统技术现状和数据位置信息管理维护方法局限性的影响,在面向大规模地震数据存储读写应用时,多个存储服务器会随着数据规模的扩大和应用的增多而造成负载的不均衡,计算机集群文件系统会根据服务器的磁盘空间利用率和访问负载来调整数据分布。在进行负载均衡时,对于通过记录位置来管理存储空间的系统而言,大量地震数据对象文件的迁移会导致数据位置信息的频繁更改,对象位置信息一致性的系统开销工作量增大。由于需维护的地震数据与对象存储服务器映射规模较大,存储服务器管理维护的映射关系信息总量会大大的超过服务器的系统内存容量,数据存储的效率和空间的可扩展性很低。
技术实现要素:
针对现有技术中存在的不足,本发明的目的之一在于解决上述现有技术中存在的一个或多个问题。
为了实现上述目的,本发明的一方面提供了一种适用于大规模地震数据存储方法。所述方法包括设计第一级哈希索引结构,将数据对象存储空间划分为多个数据分区,并将所述数据分区分布到不同数据存储服务器以支持并发操作;设计第二级哈希索引结构,将所述数据分区划分为多个数据块组,以支持文件系统调整数据分区大小;将数据对象存储在所属的数据分区和数据块组。
本发明的另一方面提供了一种适用于大规模地震数据的快速定位方法。所述方法包括根据数据对象第一哈希值,确定数据对象所属数据分区;根据每个存储服务器所应处理数据分区的哈希范围,确定数据分区所属对象存储服务器;通过数据对象第二哈希值,确定数据对象所属数据块组;确定对象位置信息,得到数据对象存储位置。
本发明的再一方面提供了一种适用于大规模地震数据的存储装置。所述装置包括数据分区模块,通过第一级哈希索引结构,将数据对象存储空间划分为多个数据分区,用于存储对象位置信息;数据块组模块,通过第二级哈希索引结构,将数据分区划分为多个数据块组,用于存储对象位置信息;数据存储模块,包括多个存储服务器;其中,所述数据存储服务器根据所应处理数据分区的哈希范围将所述数据分区分布到不同数据存储服务器。
与现有技术相比,本发明的数据存储、快速定位方法及装置支持对大规模地震数据对象存储空间的弹性扩展,同时,本发明的方法及装置通过对象位置信息在多个储服务器的分布结果来放置数据,文件系统通过对索引结构的调整,能够以较低的开销实现负载均衡,不仅能支持大规模地震数据的高效管理,而且通过负载均衡的方式,多个存储服务器的i/o聚合带宽具有稳定的加速比,在多节点客户端并发访问地震数据存储的情况下,其性能优势更明显。
附图说明
通过下面结合附图进行的描述,本发明的上述和其他目的和特点将会变得更加清楚,其中:
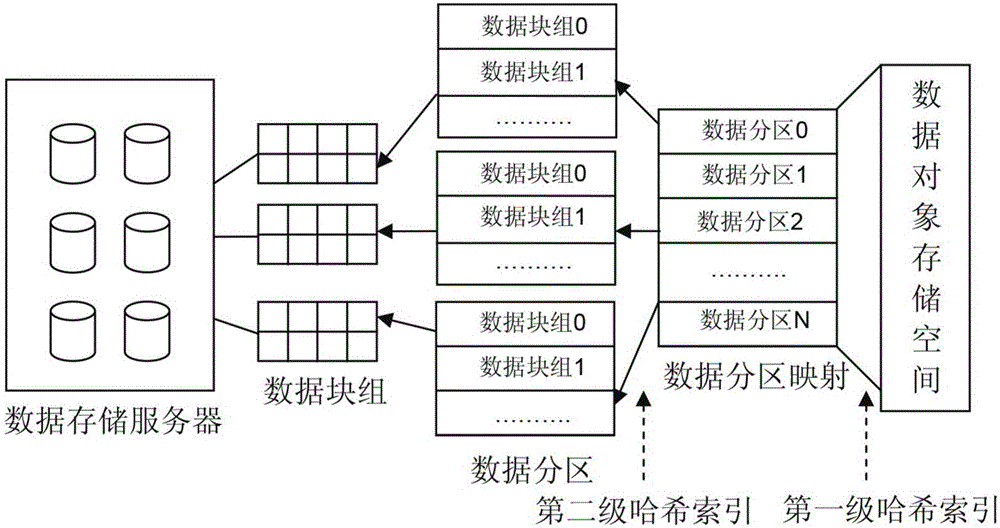
图1示出了根据本发明示例性实施例的数据对象文件存储结构示意图。
图2示出了根据本发明示例性实施例的扩展的两级哈希索引结构示意图。
具体实施方式
在下文中,将结合附图和示例性实施例详细地描述根据本发明的适用于大规模地震数据存储、快速定位的方法及装置。
本发明的核心内容是可将地震数据和对象存储服务器之间的大规模映射关系转换为多级小规模映射,基于动态哈希算法原理,通过设计两级结构的可扩展哈希索引来组织数据,将地震数据信息均匀映射到一个有限的连续空间上,保证存储数据分布的均匀性和单调性。文件系统对数据的放置和定位可在两次i/o操作之内完成,数据均匀分散在各个对象存储上,支持和解决分布式存储系统中的数据规模扩展的问题。
图1示出了根据本发明示例性实施例的数据对象文件存储结构示意图。图2示出了根据本发明示例性实施例的扩展的两级哈希索引结构示意图。
如图2所示,具体来讲,为了支持对大规模地震数据对象映射关系的高效访问,本发明的方法及装置可将地震数据对象的位置信息抽取出来并组织成可扩展的索引结构进行独立管理,并将其索引结构分布到多个对象存储服务器以并发处理的方法将存储空间中的地震数据对象位置信息抽取出来独立组织,依靠对象位置信息在多个存储服务器的分布结果来放置对象。对象位置信息可采用两级结构的可扩展哈希索引的方式进行组织,通过第一级索引结构,存储空间被划分成多个数据分区并分布到不同的存储服务器上可支持并发操作;通过第二级索引结构,数据分区被划分成多个数据块组,可支持系统对数据分区大小的调整,使计算机集群文件系统可以在单个节点支持对包括tb级或者更大规模地震数据对象的快速定位。
本发明的一方面提供了一种适用于大规模地震数据的存储方法。根据本发明示例性实施例的数据存储方法可通过以下步骤实现:
(1)设计第一级哈希索引结构,将数据对象存储空间划分为多个数据分区,并将数据分区分布到不同的数据存储服务器上以支持并发操作。
维护数据分区在多个对象存储服务器的分布可以采用一致性哈希的方法。在具体的实施过程中,可将一致性哈希以全局映射表的方式缓存所有节点,全局映射表可采用二维数据的形式记录每个存储服务器所应处理数据分区的哈希范围,通过查询全局映射表,计算机群节点就可以获取指定数据分区所属的对象存储服务器。
当地震数据对象存储空间划分为多个数据分区后,在地震数据存储服务器中,为了确定对象数据所属数据分区,需要在多个节点维护对象到数据分区的映射信息。由于该映射是通过可扩展哈希索引建立的,定位节点需要维护第一级索引结构的信息包括表示所有数据分区的位图信息以及表示数据分区存储的最大空间数值。通过以上两个数据信息,计算出数据对象的第一哈希值,查询到该对象所属数据分区。优选的,这里的第一哈希值的计算可以采用一致性哈希算法得到,即使用一致性哈希算法使数据对象存储在相应的数据分区。
例如,假设数据为x,存储节点数目为n。将数据分布到各个数据分区的最直接做法可以是,计算数据x的hash(哈希)值,并将计算结果hash值同数据分区数目n取余数,余数就是数据x的目的存储数据分区,即目的数据分区为hash(x)%n。对数据计算hash值的目的为了可以让数据均匀分布在n个数据分区中。
(2)设计第二级哈希索引结构,将所述数据分区划分为多个数据块组,以支持文件系统调整数据分区大小。
当确定数据对象所属数据分区后,查询数据的请求被发送到数据分区所属数据对象存储服务器进行节点内查找,根据计算出的数据对象第二哈希值,服务器可直接确定数据对象所属的数据块组,即得出对象位置信息。最终,服务器可通过数据对象位置信息中的记录定位到对象数据的存储位置。这里,优选的,计算数据对象第二哈希值的方法可以采用一致性哈希算法,即使用一致性哈希算法使数据对象存储在相应的数据块组,在实现过程中,可以通过软件代码编程实现。第二级哈希索引结构可为可扩展哈希索引。
例如,假设数据为y,存储节点数目为m。将数据分布到各个数据块组的最直接做法可以是,计算数据y的hash(哈希)值,并将计算结果hash值同数据分区数目m取余数,余数就是数据y的目的存储数据块组,即目的数据块组为hash(y)%m。
以上,为了提高在存储服务器中的节点内的查找速度,优选的,数据分区数量可以2的幂次进行扩展。对象位置信息可包括数据对象所属的服务器、数据分区以及数据块组。
(3)将存储服务器中的对象数据可按其对象位置信息所属的数据分区和数据块组进行划分,放置在表示数据分区和数据块组的两级目录中,文件系统可通过对索引结构中的数据分区进行操作扩展实现数据分布的调整。
这里,可以由计算机文件系统对数据分区进行操作扩展。
根据本发明的数据存储方法,通过两级可扩展哈希索引将对象位置信息进行组织,转化为依次定位数据对象所在的数据分区、存储服务器以及数据块组,从而确定对象位置信息,服务器可通过对象位置信息中的记录定位到对象的存储位置,即定位地震数据对象文件所属数据分区和数据块组的过程仅需两次扩展哈希值计算,数据的放置和定位可在两次i/o操作之内完成。
本发明的另一方面提供了一种适用于大规模地震数据的快速定位方法,该定位方法可基于上述存储方法实现数据对象快速定位。
根据本发明示例性实施例的适用于大规模地震数据快速定位方法可通过以下步骤实现:
根据数据对象第一哈希值,确定数据对象所属数据分区;
根据每个对象存储服务器所应处理数据分区的哈希范围,确定数据分区所属对象存储服务器;
通过数据对象第二哈希值,确定数据对象所属数据块组;
确定对象位置信息,得到数据对象存储位置。
优选的,第一级哈希索引和第二级哈希索引均采用一致性哈希索引的算法,即数据对象的第一哈希值与第二哈希值均根据一致性哈希索引得到。在本发明的一个示例性实施例中,为了进一步验证本申请的应用效果,申请人进行了应用实例验证,例如分别采用8个和16个节点配置,运行iozone测试程序,采用同时产生数据写操作。所有客户端共写64gb大小的文件两次,第1次用于产生对象文件,使数据分区扩展不影响定位过程。数据定位开销以第2次写文件的定位操作所花费的时间为依据。在测试过程中,将写文件的操作屏蔽,因此不会有数据写操作对定位过程产生影响。对象文件的定位时间不随对象文件数量变化而变化。数据定位时间值在11.07μs~12.12μs之间,由此,本发明的方法采用对象文件的两级可扩展哈希索引结构,能以较小的内存空间完成快速的大规模数据定位操作。
本发明的再一方面提供了一种适用于大规模地震数据的数据存储装置。所述存储装置可与上述适用于大规模地震数据的存储方法以及快速定位方法相对应。
根据本发明示例性实施例的适用于大规模地震数据的数据存储装置可包括:
数据分区模块,可通过第一级哈希索引结构,将数据对象存储空间划分为多个数据分区,用于存储对象位置信息。
以上,数据对象与数据分区通过扩展哈希索引建立映射关系,可通过计算出数据对象的哈希值从而查询到该数据对象所属的数据分区。数据分区可分布到多个不同数据存储服务器以支持并发操作,维护分布的方法可采用一致性哈希的方法。第一级哈希索引结构可以为可扩展哈希索引。
数据块组模块,可通过第二级哈希索引结构,将数据分区划分为多个数据块组,用于存储对象位置信息。
以上,当确定数据对象所属数据分区后,查询数据的请求被发送到数据分区所属数据对象存储服务器进行节点内查找,根据第二级哈希索引结构,计算出的数据对象第二哈希值,得到数据对象所属的数据块组,从而确定其对象位置信息。最终,服务器可通过数据对象位置信息中的记录定位到对象数据的存储位置。第二级哈希索引结构可以为可扩展哈希索引。
数据存储模块,包括多个存储服务器;
其中,所述数据存储服务器所应处理数据分区的哈希范围将所述数据分区分布到不同数据存储服务器。
综上所述,本发明的适用于大规模地震数据存储、快速定位方法及装置将地震数据和对象存储服务器之间的大规模映射关系转换为多级小规模映射,设计两级结构的可扩展哈希索引来组织数据,文件系统对数据的放置和定位在两次i/o操作之内完成,可支持对大规模地震数据对象存储空间的弹性扩展。同时,该方法和装置通过对象位置信息在多个储服务器的分布结果来放置数据,文件系统通过对索引结构的调整,能够以较低的开销实现负载均衡,在多节点客户端并发访问地震数据存储的情况下,其性能优势明显。
尽管上面已经通过结合示例性实施例描述了本发明,但是本领域技术人员应该清楚,在不脱离权利要求所限定的精神和范围的情况下,可对本发明的示例性实施例进行各种修改和改变。
- 还没有人留言评论。精彩留言会获得点赞!