在并行化处理器中的刷新的制作方法
发明领域
本发明大体上涉及处理器设计,特别是用于刷新指令的方法和系统。
发明背景
已经提出了用于在运行时使软件代码动态并行化的各种技术。例如,marcuellu等人在1998年的第12届国际超级计算会议的论文集“speculativemultithreadedprocessors”中描述了一种处理器微架构,其借助于不需要编译器或用户支持的控制推测技术,同时执行从单个程序获得的多个控制线程,其内容通过引用并入本文。
发明概述
本文中所描述的本发明的实施例提供一种方法,其包括在具有流水线的处理器中,以与程序代码中的指令的出现顺序不同的顺序在运行时提取程序代码的指令。指令被划分成具有段标识符(id)的段。检测保证从属于段的指令开始刷新指令的事件。响应于该事件,段中的在该指令之后的至少一些指令以及在段之后的一个或更多个后续段中的至少一些指令基于段id被从流水线刷新。
在实施例中,检测事件包括检测分支误预测。在另一实施例中,检测事件包括检测未被预测的分支指令。在又一实施例中,检测事件包括检测在储存之前加载的依赖性违规(violation)。
在一些实施例中,刷新指令包括基于段id从流水线的级或从在流水线的级之间缓冲指令的缓冲区刷新指令。在示例实施例中,刷新指令包括通过耦合到级或缓冲区的电路来检查段id,以及由该电路决定刷新指令中的哪个指令。在另一实施例中,刷新指令包括基于段id仅刷新在缓冲区被缓冲的指令的部分子集。
在公开的实施例中,流水线包括多个并行硬件线程,并且处理单个程序的段包括在多个硬件线程之中分布段。在实施例中,指令由第一硬件线程处理,并且刷新指令包括刷新与第一硬件线程不同的第二硬件线程中的至少一个后续段中的一个或更多个指令。
在一些实施例中,检测事件包括在相同的时钟周期中检测保证刷新不同的硬件线程中的指令的多个单独的事件。在示例实施例中,刷新指令包括基于段id来识别由于多个事件而待刷新的指令之中最旧的指令,以及从待刷新的指令之中的最旧的指令开始刷新指令。
在实施例中,刷新指令包括避免刷新在段之后但与该段独立的段。在实施例中,检测事件包括检测保证指令的刷新并发生在多个不同的段中的多个单独的事件,以及刷新指令包括独立地刷新由多个事件保证的指令。
根据本发明的实施例,另外提供了包括流水线和控制电路的处理器。控制电路被配置为:指示流水线以与程序代码中的指令的出现顺序不同的顺序在运行时提取程序代码的指令;将指令划分成具有段标识符(id)的段;检测保证从属于段的指令开始刷新指令的事件;以及响应于该事件,基于段id来从流水线刷新在段中的指令之后的至少一些指令以及在段之后的一个或更多个后续段中的至少一些指令。
根据结合附图进行的本发明的实施例的以下详细描述,将更完整地理解本发明,其中:
附图说明
图1是根据本发明的实施例示意性图示了处理器的框图;
图2是根据本发明的实施例示意性说明了用于在处理器中刷新指令的方法的流程图;以及
图3是根据本发明的实施例示意性图示了基于段_id来刷新指令的过程的图。
具体实施方式
概览
本发明的实施例提供了用于在并行化处理器中刷新指令的改进技术。本文中所描述的实施例主要涉及多线程处理器,但所公开的技术也同样适用于单线程处理器。
在一些公开的实施例中,处理器包括包含多个并行硬件线程的流水线和控制流水线的控制电路。通常,流水线无序地,即以与程序代码中的指令出现的序列顺序不同的顺序,提取指令并对其进行处理。在本上下文中,术语“程序代码中的指令的出现顺序”是指在运行时实际处理指令的顺序。该顺序例如由于分支通常不按程序计数器(pc)值的序列顺序进行。
通常,在运行时被提取的指令被控制电路划分成指令组。为了简洁起见,组在本文中被称为“代码段”或简称“段”。每个段包括按序列顺序提取的多个指令。控制电路在运行时决定如何将程序代码划分成段,何时调用下个段或多个段,以及还决定哪个硬件线程要处理每个段。这些决定通常是推测性的,例如,基于分支和/或轨迹预测。基于这些决定,控制电路调用适当的段并将其分布到适当的线程以进行处理。
在处理期间发生的各种事件(例如,分支误预测)可保证从流水线刷新指令。响应于在属于某个段的某个指令中发生的这样的事件,控制电路应从流水线刷新(i)在相同段中的所讨论的指令之后的至少一些指令,以及(ii)取决于该段的后续段中的至少一些指令。
当流水线以上述方式操作时,不同的硬件线程并行地、可能是无序地处理不同的段,并且线程可同时处理属于不同段的指令。如可认识到的,从这样的流水线刷新指令是高度复杂的。例如,有时需要从线程仅刷新属于特定段的指令,而保留属于另一段的指令。
在一些实施例中,控制电路通过以下操作来执行刷新:为每个段分配段标识符(段_id);使流水线中的每个指令与指令所属的段的段_id相关联;以及基于段_id从流水线选择性地刷新指令。在一个示例实施例中,每个被提取的指令用其段_id进行标记,并连同该标记一起流经流水线。在另一示例实施例中,控制电路将段_id插入“段的开始”标记和/或“段的结束”标记中,该“段的开始”标记和/或“段的结束”标记被插入到流经流水线的指令流中。
在任一实现中,流水线的任何模块能够立即确定其处理的指令的段_id。该功能显著简化了刷新过程。本文中描述了用于基于段_id刷新指令的各种技术。刷新可在流水线的任何期望的级执行,例如,仅举几个例子,在提取级和解码级之间,从解码级的输出起,在提取级或解码级的连续子级之间,或者从重排序缓冲区起。
还描述了额外的技术,例如,用于处理在相同时钟周期中发生的多个刷新事件的技术,以及在刷新之后恢复正常操作的恢复技术。
系统描述
图1是根据本发明的实施例示意性图示了处理器20的框图。在本示例中,处理器20包括多个硬件线程24,其被配置为并行地进行操作。虽然本文中所描述的实施例主要涉及多线程处理器,但所公开的技术也同样适用于单线程处理器。
在图1的示例中,每个线程24被配置为处理代码的一个或更多个相应段。例如,线程并行化的某些方面在美国专利申请14/578,516、14/578,518、14/583,119、14/637,418、14/673,884、14/673,889、14/690,424、14/794,835、14/924,833、14/960,385和15/196,071中得到了解决,这些美国专利申请全部转让给本专利申请的受让人,并且其公开内容通过引用并入本文。
在一些实施例中,每个线程24包括提取模块28、解码模块32和重命名模块36。提取模块24从存储器中(例如,从多级指令高速缓存中)提取其相应代码段的程序指令。在本示例中,处理器20包括存储器系统41,其用于储存指令和数据。存储器系统41包括多级指令高速缓存,其包括1级(l1)指令高速缓存40和2级(l2)高速缓存42,其缓存在存储器43中储存的指令。
在给定的线程24中,所提取的指令被缓冲在先进先出(fifo)缓冲区30中,并从缓冲区30的输出端提供给解码模块32。在本示例中,缓冲区30缓冲八个指令。然而,可替代地,可使用任何其他合适的缓冲区大小。解码模块32对提取的指令进行解码。
在给定的线程24中,解码的指令被缓冲在fifo缓冲区34中,并从缓冲区34的输出端提供给重命名模块36。在本示例中,缓冲区34缓冲八个指令/微操作(micro-op)。然而,可替代地,可使用任何其他合适的缓冲区大小。
重命名模块36执行寄存器重命名。由解码模块32提供的解码的指令通常根据处理器的指令集架构的架构寄存器来指定。处理器20包括寄存器文件,该寄存器文件包括多个物理寄存器。重命名模块将解码的指令中的每个架构寄存器关联到寄存器文件中的相应物理寄存器(通常为目标寄存器分配新的物理寄存器,并将操作数映射到现有的物理寄存器)。
被重命名的指令(例如,由重命名模块36输出的微操作/指令)在一个或更多个重排序缓冲区(rob)44(也称为无序(ooo)缓冲区)中被有序地缓冲。在可替代的实施例中,使用一个或更多个指令队列缓冲区来代替rob。所缓冲的指令对于由多个执行模块52的无序执行(即,不是按照它们被提取的顺序)是未决的。在可替代的实施例中,所公开的技术也可以在有序执行指令的处理器中实施。
在rob44中缓冲的被重命名的指令被调度以用于由各个执行单元52执行。指令并行化通常通过同时向各个执行单元(可能无序地)发出一个或多个被重命名的指令/微操作来实现。在本示例中,执行单元52包括被表示为alu0和alu1的两个算术逻辑单元(alu)、乘法累加(mac)单元、被表示为lsu0和lsu1的两个加载-储存单元(lsu)、分支执行单元(bru)和浮点单元(fpu)。在可替代的实施例中,执行单元52可包括任何其他合适类型的执行单元和/或每种类型的任何其他合适数量的执行单元。线程24(包括提取模块28、解码模块32和重命名模块36)、rob44和执行单元52的级联结构在本文被称为处理器20的流水线。
由执行单元52产生的结果被保存在寄存器文件中,和/或被储存在存储器系统41中。在一些实施例中,存储器系统包括介于执行单元52和存储器43之间的多级数据高速缓存。在本示例中,多级数据高速缓存包括1级(l1)数据高速缓存56和l2高速缓存42。
在一些实施例中,处理器20的加载-储存单元(lsu)在执行储存指令时将数据储存在存储器系统41中,并在执行加载指令时从存储器系统41中获取数据。数据储存操作和/或获取操作可使用数据高速缓存(例如,l1高速缓存56和l2高速缓存42)来减小存储器访问延迟。在一些实施例中,高级别高速缓存(例如,l2高速缓存)可被实现为例如在同一物理存储器中的单独的存储器区域,或者在没有固定预分配的情况下仅仅共享相同的存储器。
分支/轨迹预测模块60预测分支或流控制轨迹(单次预测中的多个分支),在本文中为简化而被称为的“轨迹”,其预期在由各种线程24执行期间由程序代码遍历。基于预测,分支/轨迹预测模块60指示提取模块28将从存储器提取出哪些新的指令。如上所述,被提取的指令由控制电路例如基于分支或轨迹预测被划分成被称为段的指令组。在该背景下,分支/轨迹预测可预测段或段的部分的整个轨迹,或预测各个分支指令的结果。
在一些实施例中,处理器20包括段管理模块64。模块64监测由处理器20的流水线处理的指令,并构建调用数据结构(也被称为调用数据库68)。通常,段管理模块64决定如何将提取的指令流划分成段,例如,何时终止当前段并开始新的段。在示例非限制性实施例中,模块64可识别代码的程序循环或其他重复区域,并将每个重复(例如,每个循环迭代)定义为相应的段。也可使用不一定与代码的重复性相关的任何其他合适形式的分割成段。
调用数据库68将程序代码划分成轨迹,并指定它们之间的关系。模块64使用调用数据库68来选择待处理的指令段,并指示流水线处理它们。数据库68通常被储存在处理器的合适的内部存储器中。在以上所引用的美国专利申请15/196,071中详细描述了数据库68的结构和使用。
由于提取模块28根据分支/轨迹预测并根据调用数据库68的遍历来提取指令,因此指令通常被无序地即,以与代码中的指令出现的序列顺序不同的顺序提取。
在一些实施例中,段管理模块64管理对由处理器流水线处理的指令的刷新。在一些实施例中,模块64的一些功能或甚至全部功能可被分布在线程24之中。在随后的实施例中,线程24彼此进行通信并以分布式方式执行刷新。以下详细地描述示例刷新技术。在各个实施例中,本文中所描述的技术可由段管理模块64执行,或者其可分布在模块64、模块60和/或处理器的其他元件(例如,耦合到线程24的硬件)之间。在本专利申请的上下文中和在权利要求中,管理指令的刷新的任何和全部处理器元件被统称为“控制电路”。
图1中所示的处理器20的配置是纯粹为了概念清晰而被选择的示例配置。在可替代的实施例中,可使用任何其他合适的处理器配置。例如,并行化可以以任何其他合适的方式来执行或者可以被完全省略。处理器可以在没有高速缓存的情况下或者借助不同的高速缓存结构来实现。处理器可包括图中未示出的附加元件。此外,可替代地,所公开的技术可借助具有任何其它合适的微架构的处理器来执行。作为另一示例,处理器执行寄存器重命名不是强制的。
处理器20可使用任何合适的硬件例如使用一个或更多个专用集成电路(asic)、现场可编程门阵列(fpga)或其他设备类型来实现。另外或可替代地,处理器20的某些元件可使用软件或使用硬件元件和软件元件的组合来实现。指令和数据高速缓存存储器可使用任何合适类型的存储器(诸如,随机存取存储器(ram))来实现。
处理器20可以以软件来编程,以执行本文中所描述的功能。例如,软件可通过网络以电子形式被下载到处理器,或者软件可以可替代地或附加地被提供和/或储存在非暂时性有形介质(诸如,磁性存储器、光学存储器或电子存储器)上。
基于段_id的指令的选择性刷新
在一些实施例中,段管理模块64在运行时决定如何将程序代码的指令序列划分成段,何时调用下个段或多个段,以及还决定哪个硬件线程24要处理每个段。基于这些决定,模块64调用适当的段并将它们分布到适当的线程24以进行处理。线程24处理其所分配的程序代码的段。
通常,段被无序地处理,即,处理段的顺序与程序代码中的段的序列顺序不同。以下在图3中示出了这样的无序处理的示例。
在一些实施例中,在处理代码期间发生的某些事件保证从流水线刷新指令。例如,如果模块60误预测了某条件分支指令的分支决策,则模块64通常应刷新在该误预测的分支指令之后的至少一些指令。在一个实施例中,模块64刷新在误预测的分支指令之后的所有指令。然而,可替代地,模块64可仅刷新在误预测的分支指令之后的一些指令。特别地,模块64不必从紧跟在误预测的分支指令之后的指令开始刷新。
作为另一示例,“在储存之前加载”的违规也保证刷新。在这种情境下,属于某个段并从寄存器或存储器地址读取的加载指令取决于属于较早段并写入该寄存器或存储器地址的储存指令。如果在储存指令之前推测性地执行了加载指令,则加载的值可能是错误的。因此,“在储存之前加载”的违规保证了指令的刷新。在各个实施例中,模块64可从加载指令开始刷新指令或可替代地从另一适当的指令开始刷新。示例可能性是从储存指令开始刷新,或从先于加载指令并被标记为“检查点”的最近指令开始刷新。检查点通常被定义为已知和记录处理器状态的指令,因此将处理回滚至其是可能的。
作为又一示例,当解码模块32识别未由分支/轨迹预测模块60预测的分支指令时,可能发生“解码器刷新”。这样的情境可能发生在例如处理器处理分支指令第一次时或在处理器“忘记”分支之后的第一次时。该事件可保证在另一线程中和/或从未来的段刷新指令。
另外或可替代地,模块64可检测保证指令的刷新的任何其他合适的事件。在一些实施例中,在检测到保证从属于某个段的某个指令刷新的事件时,模块64刷新(i)在相同段中的所讨论的指令之后的至少一些指令,以及(ii)取决于所讨论的段的后续段中的至少一些指令。刷新应从其开始的指令在本文中也被称为“第一刷新的指令”。第一刷新的指令所属的段在本文中也被称为“第一刷新的段”。
当段由多个并行硬件线程24无序地处理时,从某个指令开始刷新指令是复杂的任务。例如,线程24可同时处理应被刷新的段和不应被刷新的段。因此,可能需要从线程仅刷新属于某个段的指令的子集,而保留属于另一段的指令。
在一些实施例中,模块64通过以下操作来执行刷新:为每个段分配段标识符(段_id);使流水线中的每个指令与指令所属的段的段_id相关联;以及基于段_id在各种线程24中选择性地刷新指令。
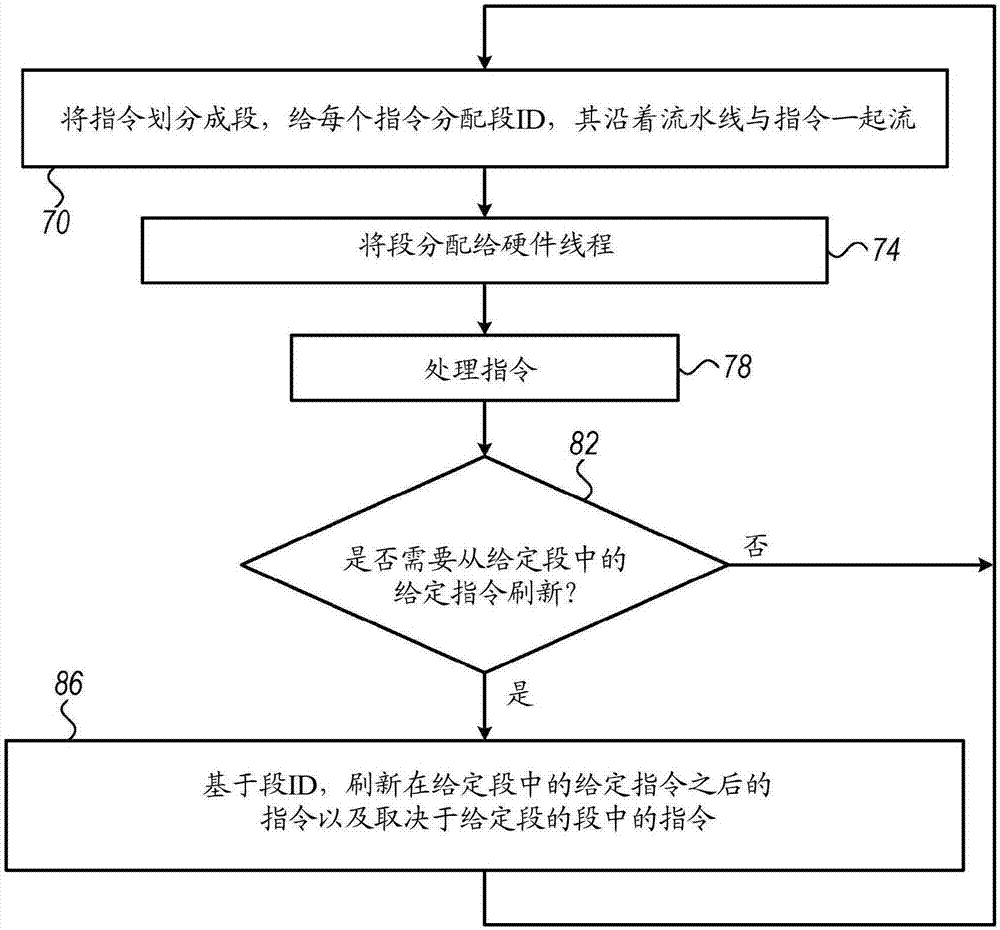
图2是根据本发明的实施例示意性说明了用于在处理器20中刷新指令的方法的流程图。在id分配步骤70,模块64给程序代码的每个段(如上所定义的指令组)分配相应的段_id。段_id通常包括根据程序代码中的段的顺序递增的数值。然而,可替代地,模块64可使用指示代码中的段的顺序的任何其他合适的段_id分配方案。
模块64使被提取的每个指令与指令所属的段的段_id相关联。在一个实施例中,提取单元28用适当的段_id来标记被提取的每个指令,例如,通过将指令字中的预定义的位组设置为指示段_id的值。随后,标记的指令连同其段_id标记一起流经流水线。因此,沿着流水线的任何模块都能够通过检查标记来使指令与其段相关联。
在另一实施例中,提取模块28不标记每个指令,而是在连续的段之间将“段的开始”标记和/或“段的结束”标记插入到流经流水线的指令流中。每个“段的开始”标记和/或“段的结束”标记包括(即将开始的段的或者刚刚结束的段的)段_id。沿着流水线的任何模块都能够通过识别标记并跟踪当前段的段_id来使指令与其段相关联。此外,可替代地,任何其他技术可用于使每个指令与其所属的段相关联。
在分布步骤74,模块64使段分布在线程24之间以用于并行处理。(在使用单线程处理器的实施例中,省略该步骤)。在处理步骤78,处理器流水线处理被分布到线程的指令。
在刷新检测步骤82,模块64检查是否需要刷新。可验证上述任何事件(例如,分支误预测或在储存之前加载违规)或任何其他合适的事件。如果没有刷新被保证,则该方法循环回到以上的步骤70。
在检测到保证从某个段中的某个指令开始刷新指令的事件时,模块64在刷新步骤86通过段_id执行刷新。通常,模块64从流水线刷新(i)在相同段中的所讨论的指令之后的至少一些指令,以及(ii)在该段之后的段中的至少一些指令。模块64根据指令的相关联的段_id选择待刷新的指令。
换句话说,如果第一刷新的指令属于段n(段_id=n),则模块64刷新在段n中的第一刷新的指令之后的至少一些指令(例如,从第一刷新的指令开始直到段的结束)。模块64还刷新在段n之后的段(即,段n+1、段n+2...)中的至少一些指令(例如,所有指令)。先于第一刷新的指令的指令(即,其段_id<n的段中的所有指令以及段n中先于第一刷新的指令的指令)通常未被刷新。然后,该方法循环回到上面的步骤70。
待刷新的指令可由任何硬件线程(可能由所有线程)处理。
图3是根据本发明的实施例示意性图示了基于段_id来刷新指令的过程的图。在本示例中,处理器20的流水线包括被表示为线程#1、线程#2、线程#3和线程#4的四个硬件线程24。段管理模块64给连续的段分配被表示为0.1、0.2、0.3、0.4...的段_id,并对段进行分布以由四个硬件线程并行化处理。
在图3中所示的某个时间点,线程#1正处理段0.1的指令。同时,线程#2正处理段0.2的指令,之后是段0.4的指令。线程#3正处理段0.3的指令,之后是段0.5的指令。线程#4正处理段0.6的指令。提取指令的顺序在图的底部示出。
如在该示例中所示,段0.1-段0.6被无序且至少部分并行地提取。另外,在某个时间点,某个线程可同时处理多个段的指令。
在本示例中,模块64检测属于由线程#2处理的段0.4的在一些条件分支指令(表示为100)中的分支误预测。因此,在该示例中,指令100之后的指令是第一刷新的指令,并且段0.4是第一刷新的段。
在本示例中,响应于检测到分支误预测,模块64刷新在(由线程#2处理的)段0.4中的指令100之后的所有指令、(由线程#3处理的)段0.5中的所有指令和(由线程#4处理的)段0.6中的所有指令。刷新的指令在图中用阴影图案标记。
如该示例所示,在一些线程(即,线程#2、线程#3和线程#4)中,模块64仅刷新指令的部分子集,并保留其他指令。由于每个指令与其段_id相关联,因此模块64能够选择要刷新的指令以及在线程中保留哪些指令。
图3的示例还示出了,在一些实施例中,由于发生在不同线程24中的事件(例如,分支误预测),模块64刷新由某个线程24处理的指令。
从流水线的任何级刷新
在各个实施例中,模块64可沿着线程24或通常沿着流水线在任何合适的级开始刷新指令。在本专利申请的上下文中和权利要求书中,术语“从流水线刷新指令”是指可用于防止指令被流水线完全处理的任何合适的技术。本文中的描述主要涉及刷新,该刷新涉及从流水线中移除整个指令,但这样的移除不是强制性的。可替代地,可例如通过设置或清除指令字中使指令无效的一个或更多个位,或者通过执行使指令停止、不被执行、不完全提交或以其他方式不完全处理的任何其他合适的动作来执行刷新指令。
在一些实施例中,模块64通过从缓冲区30(即,在提取级和解码级之间,从提取模块28的输出端或解码模块32的输入端)移除指令来刷新指令。另外或可替代地,模块64通过从缓冲区34(即,在解码级和重命名级之间,从解码模块32的输出端或重命名模块36的输入端)移除指令来刷新指令。进一步另外或可替代地,模块64通过从缓冲在提取模块28的连续的子级之间的指令的内部缓冲区(未示出)移除指令来刷新指令。
进一步另外或可替代地,模块64通过从重排序缓冲区44移除指令来刷新指令。进一步另外或可替代地,模块64通过从分支执行单元(bru)的输出缓冲区移除相应的程序计数器(pc)值来刷新指令。进一步另外或可替代地,模块64可通过从由流水线的加载-储存单元(lsu)(参见图1中的执行单元52)所使用的加载缓冲区和/或储存缓冲区移除指令来基于段_id刷新指令。这种刷新也利用了在加载和储存的缓冲区中缓冲的指令与段_id相关联的事实。进一步另外或可替代地,模块64可通过从处理器20的流水线中的任何其它合适的缓冲区移除指令来基于段_id刷新指令。在所有以上的示例中,模块64可根据指令的段_id仅刷新在流水线的缓冲区中缓冲的指令的部分子集。
当在某个级开始刷新指令时,刷新在流水线中向后继续。在该背景下,“向后”意味着朝向流水线的较低的级。例如,考虑图3中的线程#3。在示例实施例中,模块64识别段0.3和段0.5之间的边界当前所处于的流水线级。随后,模块64从该级向后刷新指令,以便刷新段0.5的指令,但保留段0.3的指令。例如,如果段0.3和0.5之间的边界当前在线程#3的缓冲区34中,则模块64在缓冲区34中的适当位置处开始刷新,并向后继续刷新在线程#3的解码模块32、缓冲区30和提取模块28中的指令。
在一些实施例中,任何流水线级(例如,提取模块28、解码模块32、重命名模块36和/或任何执行模块52)可包括本地电路,该本地电路检查流经该级的指令的段id,并基于段id决定要刷新哪些指令。类似地,流水线的任何缓冲区(例如,缓冲区30、34和/或44)可包括本地电路,该本地电路检查在该缓冲区中缓冲的指令的段id,并基于段id决定要刷新哪些指令。这样的本地电路可耦合到每个流水线级和缓冲区,耦合到级和缓冲区的子集,或者甚至仅耦合到单个级或缓冲区。
在同一个指令周期中处理多个刷新事件
在一些情况下,保证刷新的多个单独的事件可能会同时发生,例如,在同一指令周期中。为了清楚起见,以下的描述涉及两个同时的事件,但所公开的技术可以以类似的方式应用于更多数量的事件。事件发生在不同的段中,可能在不同的线程24中。
在一些实施例中,模块64识别两个事件,识别两个相应的第一刷新的指令,以及与这些第一刷新的指令相关联的段_id。随后,模块64基于第一刷新的指令之中最旧的指令以及(在第一刷新的段之中最旧的)相关联的段_id来启动上述的刷新过程。
以上过程可以以各种方式来实现。在一个实施例中,其中独立发生刷新事件的每个线程24刷新比相应的第一刷新的指令更新(youngerthan)的指令。另外,两个线程中的每个线程向另一线程报告刷新事件。在从对等线程接收到刷新的指示时,接收的线程决定其自身的第一刷新的段比对等线程的第一刷新的段是更旧还是更新。如果其自身的第一刷新的段更旧,则线程继续进行(第一刷新的段的和可能在其他线程中的所有后续相关段的)刷新过程。如果其自身的第一刷新的段比对等线程的第一刷新的段更新,则线程停止刷新(因为对等线程将针对两个刷新事件刷新适当指令)。
在可替代的实施例中,其中独立发生刷新事件的每个线程24刷新比相应的第一刷新的指令更新的指令。另外,两个线程中的每个线程向模块64报告刷新事件。模块64识别第一刷新的指令之中的最旧指令(因此识别第一刷新的段之中的最旧的段)。模块64指示处理最旧的第一刷新的段的线程和任何其他合适的线程刷新适当的指令。
此外,可替代地,由于多个刷新事件而引起的刷新可以以任何其它合适的方式在线程之间进行协调。
附加的实施例和变型
在刷新过程之后,段管理模块64可以以任何合适的方式恢复对段的编号。在一个实施例中,在具有段_id=n的段(从第一刷新的指令)被部分刷新和具有段_id>n的段被完全刷新之后,代码的下个段将再次被分配段_id=n。
在一些实施例中,在具有段_id=n的段(从第一刷新的指令)被部分地刷新之后,提取该段的后续指令通过与最初处理该段的线程不同的线程来执行。
在一些实施例中,线程24同时处理两个或更多个彼此完全独立的段组。例如,线程24可同时处理代码中的远离彼此且没有相互依赖性的两个区域。在这些实施例中,即使一个段组比另一段组较新(较晚),也没有理由响应较旧(较早)组中的刷新事件来刷新更新的组。因此,在一些实施例中,模块64避免刷新完全独立于第一刷新的段的段组。如前所述,模块64可响应于同时发生的多个刷新事件来执行协调的刷新过程。当完全独立于彼此的两个(或更多个)段组在相同的时间点被处理时,处理器可在每个段组内单独地且独立于任何其他组执行这样的协调过程。
因此,将认识到的是,以上描述的实施例是通过示例引用的,并且本发明并不限于上文已具体示出和描述的内容。相反,本发明的范围包括上文所描述的各种特征的组合和子组合以及本领域技术人员在阅读以上描述之后将想到的且在现有技术中未公开的其变型和修改。通过引用并入本专利申请中的文档被视为本申请的组成部分,除了在这些并入的文档中定义的任何术语与本说明书中明确地或隐含地作出的定义冲突时,仅应考虑本说明书中的定义。
- 还没有人留言评论。精彩留言会获得点赞!