基于改进BP神经网络算法的配网电采暖负荷预测方法与流程
本发明涉及一种负荷预测方法,具体的,涉及一种基于改进bp神经网络算法的配网电采暖负荷预测方法。
背景技术:
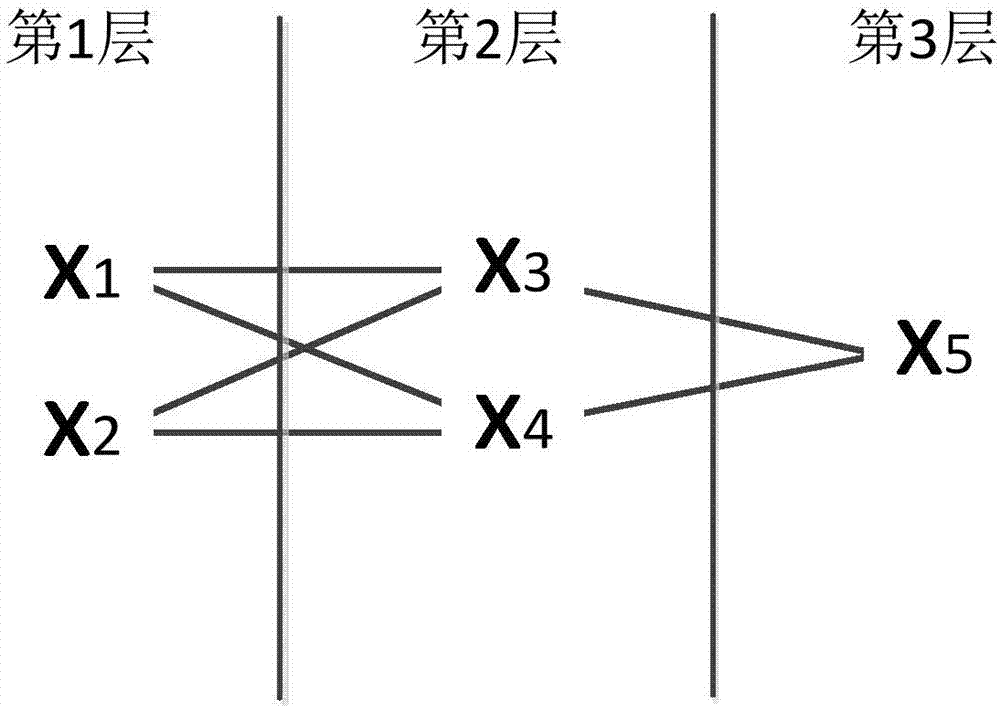
:配网负荷预测,是配电网规划的基础,然而随着大量电采暖负荷的接入,采暖内大幅度增加了配电网的负荷,配电网的规划需及时调整适应大规模电采暖负荷的接入,因此,准确的预测电采暖负荷是当前配电网规划前提和基础。电采暖负荷预测与历史数据的关系较小,主要受以下两个因素的影响:1)我国推广电采暖的主要目的之一是弃风供暖,大规模消纳多余风电,提高新能源利用效率,电采暖的推广受当地年风力发电量利用率的影响较大;2)随着我国新建建筑节能标准的提高,大量新建建筑采用节能75%设计标准,相对于传统采暖,推广电采暖有助于用户节约采暖费用,提高了用户采用电采暖的积极性。目前,还没有考虑以上两个因素的电采暖负荷预测方法。虽然,bp神经网络法可考虑以上影响因素对电采暖负荷预测的影响,但是目前还没有基于bp神经网络法的电采暖负荷预测方法研究。目前,bp神经网络方法大量应用于配网负荷预测,步骤为:1)随机赋值权系数;2)计算各层输出;3)判断输出与期望值是否满足要求,若满足转向步骤5;4)计算各层学习误差,修正权系数,转向步骤2);5)基于计算的权,预测负荷。但是,该技术应用到电采暖负荷预测后,存在的问题是:权是随机给定的,大量的反复实验导致收敛过程慢;对于给定的权修正量很小,这样优化是通过沿局部改善的方向逐渐进行调整的,很难达到满意的预测结果;在输出接近边界值0或1的条件下,易出现平坦区,权改变极小,容易使训练过程停顿。因此,如何优化神经网络算法,提高收敛速度,避免输出平坦区,改善训练效果成为现有技术亟需解决的技术问题。技术实现要素:本发明的目的在于提出一种基于改进bp神经网络算法的配网电采暖负荷预测方法,能够克服现有bp神经网络算法的缺点,提高电采暖负荷预测的精度,提高收敛速度,避免输出平坦区,提高权值改变幅度。为达此目的,本发明采用以下技术方案:一种基于改进bp神经网络算法的配网电采暖负荷预测方法,包括如下步骤:获取历史数据以及参数设置步骤s1:获取表示输入的历年规划的新建建筑的建筑面积和历年风力发电量利用率,表示输出的历年电采暖负荷值,所述历年包括同时有风力发电和电采暖负荷的时间段,设有m层的神经网络,所述神经网络共有n个神经元,并从1到n顺序编号,所述神经网络计算的数据组数为vmax=year-1,year是历史数据的年数,令迭代次数it=1,给定最大迭代次数itmax,设训练组数变量v=1,给定输出误差εy,给定神经元接近上限值的误差ε上和接近下限值的误差ε下,给定学习率η和各神经元的偏倚θi,i=3,4,...,n,电采暖负荷期望输出为y;相关系数计算步骤s2,分别利用历年的风力发电量利用率、历年新建建筑面积与历年电采暖负荷值计算相关系数;权系数赋值步骤s3:将计算得到的相关系数分别赋值给各层神经元对应相应变量的权系数ωij,ωij为位于第k-1层总第j个神经元到位于第k层总第i个神经元的权系数,其中i的序号范围对应从第2层到第m层的神经元,j的序号范围对应从第1层到第m-1层的神经元;各层神经元计算输出步骤s4,对于第k层总第i个神经元输出利用如下公式计算:其中j为第k-1层的总第j个神经元,k取值从第2层到第m层,式中θi是第i个神经元的偏倚;结果输出判断步骤s5,计算输出层输出值与电采暖负荷期望输出y之差的绝对值,如果该绝对值小于输出误差εy,或迭代次数超过itmax,则转向步骤s11,否则进入步骤s6;上下限判断步骤s6,通过将神经元输出值与神经元接近上限值的误差ε上或接近下限值的误差ε下进行比较判断神经元输出值是否接近其上下限值,如果是则进入步骤s9,否则进入步骤s7;神经元学习误差计算步骤s7,计算隐藏和输出层学习误差步骤,若该层为输出层,即k=m,则第i个神经元学习误差y是电采暖负荷期望输出;若该层为隐藏层,即k≠m,则学习误差l为第k+1层的神经元的序号;基于学习误差的权系数修正步骤s8,根据学习误差修正权系数,令it=it+1,然后转向步骤s10;随机修正权系数步骤s9,令it=it+1,随机产生一个很小的正数ε修,令ωij(it)=ωij(it-1)+ε修;随机修正偏倚和学习率步骤s10,基于[-0.2,0.2]的均匀分布函数,随机产生一个数,修正偏倚和学习率,然后转向步骤s4;判断是否到最后一组数据步骤s11,令v=v+1,再将v与vmax比较,判断是否到最后一组数据,如果若v≤vmax转向步骤s3,否则进入步骤s12;预测步骤s12,依据计算的各层权系数、神经元偏倚、学习率,给定的预测年的规划新建建筑的建筑面积和风力发电量利用率,预测电采暖负荷值。可选的,在步骤s2中,首先对历年的风力发电量利用率、历年新建建筑面积与历年电采暖负荷值进行归一化计算,再进行相关系数的计算。可选的,在步骤s2中,归一化的公式为:p=(q-0.7qmin)/(1.3qmax-0.7qmin)其中,p是归一化后的值,q是归一化前的值,qmax,qmin是归一化变量q的最大值、最小值。可选的,给定输出误差εy为0.01,给定神经元接近上限值的误差ε上和接近下限值的误差ε下均为0.01。可选的,步骤s1的各用户能够按采暖时间分成5类,包括学校、行政事业单位、公司企业、商业宾馆和居民。可选的,在对每一组数据进行训练时的电采暖负荷期望输出y为该组数据中的电采暖负荷值。即采用历年的真实的电采暖负荷值,作为神经网络训练的期望输出值。可选的,学习率η在[0,1]区间内按均匀分布随机产生。可选的,在获取历史数据以及参数设置步骤s1中,itmax=500。可选的,在步骤s9中,ε修在[0,0.1]区间按均匀分布条件随机产生。本发明的配电网电采暖负荷预测方法,能够提高收敛速度,避免输出平坦区,提高权值改变幅度,考虑了弃风供暖和新建绿色建筑对电采暖推广的影响,使电采暖负荷预测结果更接近实际值,有助于电网公司确定针对性的规划方案,不仅保证采暖期内电采暖用户可靠供电,而且能够降低投资,提高电网公司运营的经济效益。附图说明图1是根据本发明的基于改进bp神经网络算法的配网电采暖负荷预测方法的流程图;图2是根据本发明具体实施例的bp神经网络的示意图。具体实施方式下面结合附图和实施例对本发明作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅仅用于解释本发明,而非对本发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与本发明相关的部分而非全部结构。参见图1,示出了根据本发明的基于改进bp神经网络算法的配网电采暖负荷预测方法的流程图,该方法包括如下步骤:获取历史数据以及参数设置步骤s1:获取表示输入的历年规划的新建建筑的建筑面积和历年风力发电量利用率,表示输出的历年电采暖负荷值,所述历年包括同时有风力发电和电采暖负荷的时间段,设有m层的神经网络,所述神经网络共有n个神经元,并从1到n顺序编号,所述神经网络计算的数据组数为vmax=year-1,year是历史数据的年数,令迭代次数it=1,给定最大迭代次数itmax,设训练组数变量v=1,给定输出误差εy,给定神经元接近上限值的误差ε上和接近下限值的误差ε下,给定学习率η和各神经元的偏倚θi,i=3,4,...,n,电采暖负荷期望输出为y;在该步骤中,由于输入变量为两个,即历年规划的新建建筑的建筑面积和历年风力发电量利用率,因此,该神经网络每层的神经元个数为2,输入神经元x1、x2无需具有偏倚值,因此神经元的偏倚从3到n。相关系数计算步骤s2,分别利用历年的风力发电量利用率、历年新建建筑面积与历年电采暖负荷值计算相关系数。进一步的,在步骤s2中,首先对历年的风力发电量利用率、历年新建建筑面积与历年电采暖负荷值进行归一化计算。具体的,归一化公式为:p=(q-0.7qmin)/(1.3qmax-0.7qmin)其中,p是归一化后的值,q是归一化前的值,qmax,qmin是归一化变量q的最大值、最小值。归一化计算为现有技术中常见的归一化计算方法,可以利用如下公式进行归一化计算。公式为其中,在计算历年风力发电量和历年电采暖负荷的相关系数时,xi是历年风力发电量数据,xj是历年电采暖负荷值,cov表示协方差,var表示方差;同理,将历年风力发电量数据替换为历年新建建筑面积,可计算历年新建建筑面积和电采暖负荷的相关系数。权系数赋值步骤s3:将计算得到的相关系数分别赋值给各层神经元对应相应变量的权系数ωij,ωij为位于第k-1层总第j个神经元到位于第k层总第i个神经元的权系数,其中i的序号范围对应从第2层到第m层的神经元,j的序号范围对应从第1层到第m-1层的神经元。例如ω31表示位于第1层的总第1个神经元到位于第2层的总第3个神经元的权系数,ω53表示位于第2层的总第3个神经元到位于第3层的总第5个神经元的权系数,其中如步骤s1所述,整个神经网络的神经元是从1到n顺序编号的。各层神经元计算输出步骤s4,对于第k层总第i个神经元输出利用如下公式计算:其中j为第k-1层的总第j个神经元,k取值从第2层到第m层,式中θi是第i个神经元的偏倚。结果输出判断步骤s5,计算输出层输出值与电采暖负荷期望输出y之差的绝对值,如果该绝对值小于输出误差εy,或迭代次数超过itmax,则转向步骤s11,否则进入步骤s6。可选的,在对每一组数据进行训练时的电采暖负荷期望输出y为该组数据中的电采暖负荷值。即采用历年的真实的电采暖负荷值,作为神经网络训练的期望输出值。上下限判断步骤s6,通过将神经元输出值与神经元接近上限值的误差ε上或接近下限值的误差ε下进行比较判断神经元输出值是否接近其上下限值,如果是则进入步骤s9,否则进入步骤s7。例如,若神经元x3或x4或x5的输出值接近其上下限值1和0,即1-xj≤ε1或xj-0≤ε0j=3,4,5,ε1,ε0分别是上下限的误差限值,则转向步骤s9。神经元学习误差计算步骤s7,计算隐藏和输出层学习误差步骤,若该层为输出层,即k=m,则第i个神经元学习误差y是电采暖负荷期望输出;若该层为隐藏层,即k≠m,则学习误差l为第k+1层的神经元的序号;基于学习误差的权系数修正步骤s8,根据学习误差修正权系数,令it=it+1,然后转向步骤s10;可选的,对于学习率η能够在[0,1]区间内按均匀分布随机产生。随机修正权系数步骤s9,令it=it+1,随机产生一个很小的正数ε修,令ωij(it)=ωij(it-1)+ε修;随机修正偏倚和学习率步骤s10,基于[-0.2,0.2]的均匀分布函数,随机产生一个数,修正偏倚和学习率,然后转向步骤s4;在该步骤中,该修正公式类似于步骤s9的修正公式。判断是否到最后一组数据步骤s11,令v=v+1,再将v与vmax比较,判断是否到最后一组数据,如果若v≤vmax转向步骤s3,否则进入步骤s12;预测步骤s12,基于各层的权系数和给定的输入,预测电采暖负荷值。下面以一具体示例,结合图2的神经网络对本发明进行进一步的说明。实施例1:获取历史数据以及参数设置步骤s1:获取供电区域内历年规划的新建建筑的建筑面积,历年的风力发电量利用率,历年的电采暖负荷;设有m=3层神经网络,即一个输入层,一个隐藏层,一个输出层,神经元总数是n=5,因此输入层神经元为x1,x2,隐藏层神经元为x3,x4,输出层神经元为x5,电采暖负荷期望输出为y,神经网络计算的数据组数为vmax=year-1,year是历史数据的年数,令迭代次数it=1,训练组数变量v=1,给定最大迭代次数itmax,给定输出误差限值εy,给定神经元接近上限值的误差ε上和接近下限值的误差ε下,给定学习率η和各神经元的偏倚θi,i=3,4,...,n。相关系数计算步骤s2,分别计算历年的风力发电量利用率与电采暖负荷值的相关系数ξ1,历年的新建建筑面积与电采暖负荷值的相关系数ξ2。权系数赋值步骤s3,将步骤s2计算的相关系数赋值给隐藏层和输出层的权系数,即ω31=ω41=ω53=ξ1,ω32=ω42=ω52=ξ2。各层神经元计算输出步骤s4,对于第k层总第i个神经元输出利用如下公式计算:其中j为第k-1层的总第j个神经元,k取值从第2层到第m层,式中θi是第i个神经元的偏倚。进一步的,能够以隐藏层的神经元x3为例,有神经元x4,x5计算方式与神经元x3的计算方法类似。结果输出判断步骤s5,若|x5-y|<εyεy为输出误差限值,或者it>itmax,itmax为最大迭代次数,则转向步骤s11,否则进入步骤s6。上下限判断步骤s6,若神经元x3或x4或x5的输出值接近其上下限值1和0,即1-xj≤ε1或xj-0≤ε0j=3,4,5,ε1,ε0分别是上下限的误差限值,如果是则进入步骤s9,否则进入步骤s7。神经元学习误差计算步骤s7,计算隐藏和输出层学习误差,对于输出层神经元x5的学习误差d5=x5(1-x5)(y-x5),隐藏层神经元x3,x4的学习误差d3=x3(1-x3)d5ω53,d4=x4(1-x4)d5ω54;基于学习误差的权系数修正步骤s8,根据学习误差修正权系数,令it=it+1,η为学习率,在[0,1]区间内按均匀分布随机产生,然后转向步骤s10;随机修正权系数步骤s9,令it=it+1,随机产生一个很小的正数ε修,令ωij(it)=ωij(it-1)+ε修;其中,ε修在[0,0.1]区间按均匀分布条件随机产生。随机修正偏倚和学习率步骤s10,基于[-0.2,0.2]的均匀分布函数随机产生偏倚δθ3,δθ4,δθ5,修正偏倚θ3(it)=θ3(it-1)+δθ3,θ4(it)=θ4(it-1)+δθ4,θ5(it)=θ5(it-1)+δθ5,基于[-0.2,0.2]均匀分布函数随机产生学习率修正值δη,修正学习率η(it)=η(it-1)+δη,然后转向步骤s4;判断是否到最后一组数据步骤s11,v=v+1,判断是否到最后一组数据,如果若v≤vmax,转向步骤s3,否则进入步骤s12;预测步骤s12,基于各层的权系数和给定的输入,依据计算的权系数、神经元偏倚、学习率,给定的预测年的规划新建建筑的建筑面积和风力发电量利用率,预测电采暖负荷值。其中,步骤s1的各用户能够按采暖时间分成5类,包括学校、行政事业单位、公司企业、商业宾馆和居民,以分别训练神经网络并进行计算。实施例2:步骤s1:获取步骤以新疆某市为例,下表给出了2013-2016年该城市的规划新建建筑面积、风力发电量利用率、电采暖负荷值;步骤s2:计算相关系数归一化后的数值如下表所示:年份规划新建建筑面积风力发电量利用率电采暖负荷20120.00000.00000.000020130.13310.27360.387020140.23140.67000.391320150.45600.38410.638320161.00001.00001.0000第一组数据为2012年规划新建建筑面积和风力发电量利用率预测2013年的电采暖负荷值,令迭代次数it=1,itmax=500,v=1,输出误差限值εy=0.01,ε1=0.01,ε0=0.01,θ3=0.1756,θ4=0.0472,θ5=0.0953,η=0.542;计算的新建建筑面积和电采暖负荷的相关系数为ξ1=0.92,风力发电量利用率和电采暖负荷的相关系数为ξ2=0.95;步骤s3:赋值权系数步骤ω31=ω4`=ω53=0.92,ω32=ω42=ω54=0.95;步骤s4:计算各层神经元输出经计算隐藏层神经元x3=0.544,x4=0.512,输出层神经元x5=0.746;步骤s5:结果输出判断步骤,若|0.746-0.387|=0.368>0.01,it=1<itmax=500,转向步骤s6;步骤s6:神经元输出上下限判断判断步骤神经元x3,x4,x5的计算值与上下限0和1之间的误差均大于0.01,转向步骤s7;步骤s7:计算隐藏和输出层神经元的学习误差步骤神经元x5的学习误差d5=-0.068,隐藏层神经元x3,x4的学习误差d3=-0.0155,d4=-0.0161;步骤s8:修正权系数步骤计算的迭代步骤it=2,计算的权系数为ω53(it)=0.95,ω54(it)=0.985,ω31(it)=0.927,ω32(it)=0.958,ω41(it)=0.928,ω42(it)=0.959步骤s9:随机修正权系数步骤第1组,第1次迭代,不满足要求,算法不经过此步骤;步骤s10:随机修正学习率和偏倚步骤随机修正后的偏倚值为θ3=0.0214,θ4=-0.1021,θ5=0.1310,学习率为η=0.249;步骤s11:将训练组数变量v加1,再判断是否到最后一组数据步骤;训练组数不到最后一组数据,转向步骤s3;步骤s12:预测电采暖负荷值步骤经363次迭代,确定了权系数、学习率和各神经元的偏倚如下:ω53(it)=0.872,ω54(it)=0.854,ω31(it)=0.831,ω32(it)=0.818,ω41(it)=0.814,ω42(it)=0.823,θ3=0.254,θ4=0.153,θ5=0.142,η=0.357。在给出预测的2017年的规划新建建筑面积167.57万平方,风力发电量利用率为75.36%条件下,下表给出了2013年到2017年,改进的bp设计网络方法和传统的bp神经网络方法电采暖负荷的预测结果对比。年份传统bp神经网络法预测值本文方法预测值实际电采暖负荷(mw)2012--7.48201319.5820.8221.99201420.1123.5822.15201529.4130.2431.41201640.2342.3544.97201725.3228.91-可见相对于现有技术,本发明的配电网电采暖负荷预测,提高收敛速度,避免输出平坦区,提高权值改变幅度,考虑了弃风供暖和新建绿色建筑对电采暖推广的影响,使电采暖负荷预测结果更接近实际值,有助于电网公司确定针对性的规划方案,不仅保证采暖期内电采暖用户可靠供电,而且能够降低投资,提高电网公司运营的经济效益。以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施方式仅限于此,对于本发明所属
技术领域:
的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单的推演或替换,都应当视为属于本发明由所提交的权利要求书确定保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1