一种基于大数据和云计算业务下的智能监控方法及系统与流程
本发明涉及信息技术领域,尤其涉及一种基于大数据和云计算业务下的智能监控方法及基于大数据和云计算业务下的智能监控系统。
背景技术:
1998年vmware提出x86架构的虚拟化技术后,虚拟化技术浪潮发展迅猛,并且在短短几年时间后,基于虚拟化技术的云计算的概念被提出,用户可以在云计算环境中按需取用资源,基于云端在网络可达的条件下随时随地使用资源。通过10多年的发展,虚拟化技术和云计算技术逐渐成熟,并为大多数用户接纳,越来越多的业务都将跑在云端上。而根据《国务院关于加快培育和发展战略性新兴产业的决定》中提及的战略新兴产业的未来预期,中国云计算市场未来5年内将会达到至少30%以上的增长水平。
另一方面,在全球信息化快速发展的大背景下,大数据已成为国家重要的基础性战略资源,正引领新一轮科技创新。根据中国信息通信研究院发布的《2015年中国大数据发展调查报告》显示,2015年中国大数据市场规模将达到115.9亿元,增速达38%。此外,预计2016至2018年中国大数据市场规模还将维持40%左右的高速增长。
云计算和大数据技术是21世纪初至今信息技术发展的主要潮流,并且由于云计算灵活的易扩展的特性,其成为大数据数据分析和处理的基础节点架构,在2013年开始,两种技术已经展现出非常有效且紧密的结合关系,这一关系在未来发展中将愈发紧密。
基于以上技术发展趋势,云计算平台上不仅会支撑大数据业务,也会有大量的传统业务运行在上面。基于这种模式下,我们需要提供一种智能的监控系统,对大数据业务和云计算业务进行监控管理,帮助用户实时掌握业务运行情况。
目前常见的云计算平台上的监控管理方式主要是以下几种:
(1)基础监控:对物理服务器和虚拟机的cpu运行、内存运行、存储运行、io读写的进行实时监控,提供利用率数据,提供告警机制,根据固定的阈值触发告警。
(2)高级监控:监控的对象包括底层资源、应用层、安全等。监控对象全面,即包括底层资源,也包括资源上面的应用监控,同时还对虚拟化环境下的安全进行监控。
上述的两个技术方案,比较呆板,不够智能。方案(1)中,只是对云计算环境的资源层面进行监控管理,只能帮助用户及时发现资源使用的瓶颈,在一定的程度上能够预防大数据业务以及传统的业务系统出现问题。而方案(2)中,虽然监控的范围比较广,即能监控业务运行的底层资源,也能监控上层的应用运行情况,还可以及时提供触发告警信息帮助用户解决业务运行的问题,但是方案(2)依然不是最佳的监控方案,因为每个业务系统对底层资源的灵敏度是不一样的,即不同的业务系统对同样的资源使用瓶颈所产生的反应是不一样。比如,大数据业务中,数据的采集和处理过程对cpu运算、io读写有比较大的要求,如果网络出现问题,读写出现延迟,那么整个大数据的数据采集业务将收到严重的影响。另一方面,方案(1)和方案(2)中,都没有提供精细化的闲置资源的监控和处理机制。
技术实现要素:
本发明所要解决的技术问题在于,提供一种基于大数据和云计算业务下的智能监控方法及系统,可能根据不同业务系统进行可自定义的差异化监控策略,并且提供智能处理中心和分析中心,对出现的告警进行智能化处理。
为了解决上述技术问题,本发明提供了一种基于大数据和云计算业务下的智能监控方法,包括:监控中心以业务系统为单位设置差异化的监控策略;当业务系统触发监控策略时,监控中心生成告警信息并将告警信息发送至智能处理中心及智能分析中心;智能处理中心根据所述告警信息及处理策略对业务系统进行处理,所述处理策略包括扩展策略、回收策略及冷却策略;智能分析中心收集并统计分析告警信息,并将结果反馈至监控中心。
作为上述方案的改进,所述监控策略包括底层资源基础监控策略、上层业务应用监控策略及闲置资源高级监控策略。
作为上述方案的改进,所述底层资源基础监控策略包括:监控中心实时获取虚拟主机的技术指标,所述技术指标包括中央处理器cpu利用率、虚拟主机内存使用率及磁盘io使用率;分别设置各技术指标触发告警的阈值及逻辑关系。
作为上述方案的改进,所述上层业务应用监控策略包括:监控中心获取业务系统里安装的应用,并设置开启业务监控功能。
作为上述方案的改进,所述闲置资源高级监控策略包括:为业务系统的虚拟机设定监控指标,所述监控指标包括指标单点闲置阈值、单点采集周期、闲置统计周期、指标闲置比例及逻辑关系;根据监控指标判断虚拟机的闲置结果。
作为上述方案的改进,所述智能分析中心收集并统计分析告警信息并将结果反馈至监控中心的方法包括:获取监控中心的告警信息,所述告警信息包括:告警对象、虚拟机所在的业务系统、告警触发时间、告警的类型、触发告警时指标参数值及指标阈值;划分告警信息的告警类型,所述告警类型包括底层资源基础、上层业务应用、闲置资源;根据告警类型对告警信息进行规律分析及预判。
相应地,本发明还提供了一种基于大数据和云计算业务下的智能监控系统,包括:监控中心,用于以业务系统为单位设置差异化的监控策略,并当业务系统触发监控策略时生成告警信息并将告警信息发送至智能处理中心及智能分析中心;智能处理中心,用于根据所述告警信息及处理策略对业务系统进行处理,所述处理策略包括扩展策略、回收策略及冷却策略;智能分析中心,用于收集并统计分析告警信息,并将结果反馈至监控中心。
作为上述方案的改进,所述监控中心包括:监控策略设置单元,用于以业务系统为单位设置差异化的监控策略;告警信息生成单元,用于当业务系统触发监控策略时生成告警信息;告警信息发送单元,用于将告警信息发送至智能处理中心及智能分析中心。
作为上述方案的改进,所述监控策略设置单元包括:底层资源基础监控策略设置单元,用于实时获取虚拟主机的技术指标并分别设置各技术指标触发告警的阈值及逻辑关系;上层业务应用监控策略设置单元,用于获取业务系统里安装的应用并设置开启业务监控功能;闲置资源高级监控策略设置单元,用于为业务系统的虚拟机设定监控指标并根据监控指标判断虚拟机的闲置结果。
作为上述方案的改进,所述智能分析中心包括:获取单元,用于获取监控中心的告警信息,所述告警信息包括:告警对象、虚拟机所在的业务系统、告警触发时间、告警的类型、触发告警时指标参数值及指标阈值;划分单元,用于划分告警信息的告警类型,所述告警类型包括底层资源基础、上层业务应用、闲置资源;分析单元,用于根据告警类型对告警信息进行规律分析及预判;反馈单元,用于将结果反馈至监控中心。
实施本发明,具有如下有益效果:
1、本发明是以业务系统为颗粒度的自定义监控系统,允许用户在海量业务系统的云计算平台上以业务系统为单位,设置具有差异化的监控策略。
2、监控中心可以联动智能处理中心,当业务系统在运行过程中触发了设置好的监控策略,由系统自动解决资源瓶颈问题。
3、闲置资源监控算法过程支持自定义,可以自定义指标单点闲置阈值、采集周期、统计周期、闲置比例逻辑关系。
4、监控系统包含智能分析中心,分析结果反向关联监控中心,帮助用户在设置监控策略的时候根据智能分析中心的数据进行合理的监控设置。
附图说明
图1是本发明基于大数据和云计算业务下的智能监控方法的流程图;
图2是本发明基于大数据和云计算业务下的智能监控系统的结构示意图;
图3是图2中监控中心的结构示意图;
图4是图2中智能分析中心的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述。仅此声明,本发明在文中出现或即将出现的上、下、左、右、前、后、内、外等方位用词,仅以本发明的附图为基准,其并不是对本发明的具体限定。
参见图1,图1显示了本发明基于大数据和云计算业务下的智能监控方法的实施例,其包括:
s101,监控中心以业务系统为单位设置差异化的监控策略;
所述监控策略包括底层资源基础监控策略、上层业务应用监控策略及闲置资源高级监控策略。具体地:
所述底层资源基础监控策略包括:监控中心实时获取虚拟主机的技术指标,并分别设置各技术指标触发告警的阈值及逻辑关系。所述技术指标包括中央处理器cpu利用率、虚拟主机内存使用率及磁盘io使用率。
需要说明的是,底层资源基础监控策略中用户可以分别对“中央处理器cpu利用率、虚拟主机内存使用率及磁盘io使用率”这三个技术指标自定义设置触发告警的阈值,并且可以自定义这三个技术指标的逻辑关系。比如,对a虚拟机,用户可以设置当cpu利用率高于80%并且内存使用率高于90%的时候立刻触发虚拟机告警机制。
所述上层业务应用监控策略包括:监控中心获取业务系统里安装的应用,并设置开启业务监控功能。具体地,业务应用监控支持:mysql、oracle、web应用。mysql:业务系统、触发时间、连接状态、线程连接数、最频繁sql、慢查询sql;oracle:业务系统、触发时间、连接状态、线程连接数、最频繁sql、慢查询sql;web应用:业务系统、端口号、连接状态。
所述闲置资源高级监控策略包括:为业务系统的虚拟机设定监控指标并根据监控指标判断虚拟机的闲置结果。所述监控指标包括指标单点闲置阈值、单点采集周期、闲置统计周期、指标闲置比例及逻辑关系;
为业务系统的虚拟机设定指标单点闲置阈值,即在某采集时间点上判断虚拟机是否为闲置的指标标准,对应具体的参数就是cpu、内存、存储的闲置阈值。如设置指标单点闲置阈值:cpu利用率≤85%,内存利用率≤60%,存储利用率≤90%,那么每个采集点得到的数据都会与设置好的单点闲置阈值进行对比和记录。
为业务系统的虚拟机设定单点采集周期,也就是采集时间的间隔。假设为业务系统a设置的采集周期为30分钟,那么监控系统每隔30分钟会采集一次业务系统a中的4台虚拟机的cpu、内存、存储利用率并与单点闲置阈值进行对比。
为业务系统的虚拟机设定闲置统计周期,即设置在一段时间内,闲置情况的统计。假设为业务系统a设置的闲置统计周期为10天,那么监控系统会通过设置好的策略以10天为一个周期,对这10天内,每隔30分钟都对业务系统a的虚拟机进行数据采集和闲置监控,得出闲置结果。
为业务系统的虚拟机设定指标闲置比例和逻辑关系。即设置cpu、内存、存储指标项闲置标准,假设为cpu设置的闲置比例为70%,为内存设置的闲置比例为80%,为存储设置的闲置比例为90%,它们的逻辑关系是且。在上文中,我们为业务系统a的虚拟机设置了10天的统计周期和30分钟的采集周期,并且为虚拟机设置了指标单点闲置阈值,分别为cpu利用率≤85%,内存利用率≤60%,存储利用率≤90%。那么10天内每台虚拟机采集到数量为:10×24×60/30=480。即480个cpu利用率的值、480个内存利用率的值、480个存储利用率的值。假设这10天时间内,采集到的cpu利用率≤85%的次数占总的次数占总的次数480的比例超过70%,并且采集到的内存利用率≤60%的次数占总的次数占总的次数480的比例超过80%,并且采集到的存储利用率≤60%的次数占总的次数占总的次数480的比例超过90%,那么可以判断该虚拟机在这10天的统计周期内,为闲置虚拟机。
s102,当业务系统触发监控策略时,监控中心生成告警信息并将告警信息发送至智能处理中心及智能分析中心;
s103,智能处理中心根据所述告警信息及处理策略对业务系统进行处理;
需要说明的是,智能处理中心联动监控中心,虚拟机底层资源使用一旦出现瓶颈,可以按照预先设定好的智能处理方式,横向添加资源,并自动继承至所属的业务系统中,一旦资源使用达到释放的条件,将自动将上一次横向添加的虚拟机移除出业务系统,并解除与业务系统中其他虚拟机的关系。
具体地,所述处理策略包括扩展策略、回收策略及冷却策略。
扩展策略:联动监控中心的底层资源基础监控,获取业务系统下虚拟机的资源使用情况。设置需要横向添加的虚拟机的数量以及资源规格,横向添加的虚拟机是基于原虚拟机为模版进行的。
回收策略:获取业务系统下虚拟机的资源使用情况。设置同样指标参数的回收阈值,运行触发阈值,将自动回收扩展策略添加的虚拟机。
冷却时间:添加虚拟机成功后开始计算冷却时间,在冷却时间内,不执行回收策略。
回收方式:手动删除、自动关机。
以业务系统a为例子,设置当虚拟机cpu利用率高于80%并且内存使用率高于90%的时候立刻触发虚拟机告警机制,并联动智能处理中心进行处理。假设虚拟机acpu利用率高于了90%,则触发告警,并通过智能处理中心,以虚拟机a为模版,横向向业务系统a中添加2台虚拟机。在运行过程中,虚拟机a以及由它为模版添加的两台虚拟机的平均cpu利用率低于阈值(如:20%),并且已经过了冷却时间,那么会回收新添加的两天虚拟机的资源,回收的方式支持手动删除和自动关机。
s104,智能分析中心收集并统计分析告警信息,并将结果反馈至监控中心。
智能分析中心将所有触发的告警信息进行统计。然后按照一定的规则进行分类和分析,把得到的结论反向反馈给监控中心,用户在设置监控策略的时候可以参照分析中心提供的趋势进行设置。
具体地,所述智能分析中心收集并统计分析告警信息并将结果反馈至监控中心的方法包括:
a、获取监控中心的告警信息,所述告警信息包括:告警对象、虚拟机所在的业务系统、告警触发时间、告警的类型、触发告警时指标参数值及指标阈值;
b、按照监控中心的准则划分告警信息的告警类型,所述告警类型包括底层资源基础、上层业务应用、闲置资源,具体分类如下表所示:
c、根据告警类型对告警信息进行规律分析及预判。
底层资源基础:分别分析cpu、内存、存储三个维度与时间、阈值的关系,并且根据过去一个月的规律预判未来一周内资源出现瓶颈的走势。
上层业务应用:分别分析mysql、oracle查询语句的规律,统计一个月内的top最频繁sql和top慢查询。并且根据过去一个月的规律预判未来一周内会出现的最频繁sql和慢查询语句。
闲置资源:分析哪些类型的业务系统存在的闲置虚拟机数量最多,并且在时间上统计闲置虚拟机数量变化趋势,并且根据过去一个月的规律预判未来一周内闲置数量的走势。
由上可知,本发明允许用户在海量业务系统的云计算平台上以业务系统为单位,设置具有差异化的监控策略;而当这些业务系统在运行过程中触发了设置好的监控策略,则会联动智能处理中心,由联动中心处理问题(例如,当触发的告警满足智能处理中心触发条件时,将会在该业务系统中横向自动添加资源,以动态保证业务对资源的需求);同时智能分析中心会收集并统计分析产生的告警信息,从而反向反馈给用户,帮助用户在设置监控策略的时候根据智能分析中心的数据进行合理的监控设置。
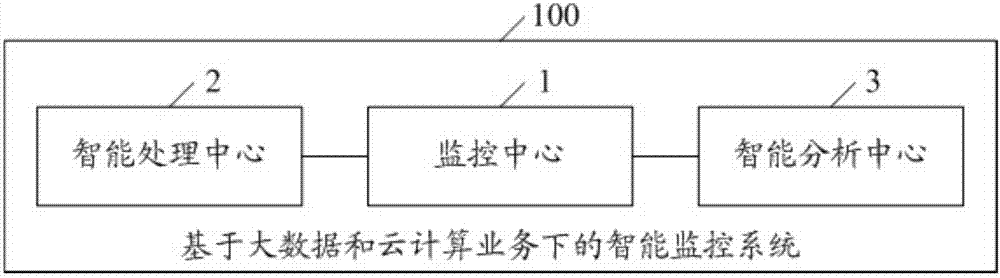
参见图2,图2显示了本发明基于大数据和云计算业务下的智能监控系统100的结构示意图,其包括:
监控中心1,用于以业务系统为单位设置差异化的监控策略,并当业务系统触发监控策略时生成告警信息并将告警信息发送至智能处理中心2及智能分析中心3;
智能处理中心2,用于根据所述告警信息及处理策略对业务系统进行处理,所述处理策略包括扩展策略、回收策略及冷却策略;需要说明的是,智能处理中心联动监控中心1,虚拟机底层资源使用一旦出现瓶颈,可以按照预先设定好的智能处理方式,横向添加资源,并自动继承至所属的业务系统中,一旦资源使用达到释放的条件,将自动将上一次横向添加的虚拟机移除出业务系统,并解除与业务系统中其他虚拟机的关系。具体地,所述处理策略包括扩展策略、回收策略及冷却策略。扩展策略:联动监控中心1的底层资源基础监控,获取业务系统下虚拟机的资源使用情况。设置需要横向添加的虚拟机的数量以及资源规格,横向添加的虚拟机是基于原虚拟机为模版进行的。回收策略:获取业务系统下虚拟机的资源使用情况。设置同样指标参数的回收阈值,运行触发阈值,将自动回收扩展策略添加的虚拟机。冷却时间:添加虚拟机成功后开始计算冷却时间,在冷却时间内,不执行回收策略。回收方式:手动删除、自动关机。以业务系统a为例子,设置当虚拟机cpu利用率高于80%并且内存使用率高于90%的时候立刻触发虚拟机告警机制,并联动智能处理中心2进行处理。假设虚拟机acpu利用率高于了90%,则触发告警,并通过智能处理中心2,以虚拟机a为模版,横向向业务系统a中添加2台虚拟机。在运行过程中,虚拟机a以及由它为模版添加的两台虚拟机的平均cpu利用率低于阈值(如:20%),并且已经过了冷却时间,那么会回收新添加的两天虚拟机的资源,回收的方式支持手动删除和自动关机。
智能分析中心3,用于收集并统计分析告警信息,并将结果反馈至监控中心1。智能分析中心3将所有触发的告警信息进行统计,然后按照一定的规则进行分类和分析,把得到的结论反向反馈给监控中心1,用户在设置监控策略的时候可以参照智能分析中心3提供的趋势进行设置。
如图3所示,所述监控中心1包括:
监控策略设置单元11,用于以业务系统为单位设置差异化的监控策略;所述监控策略包括底层资源基础监控策略、上层业务应用监控策略及闲置资源高级监控策略。
告警信息生成单元12,用于当业务系统触发监控策略时生成告警信息;
告警信息发送单元13,用于将告警信息发送至智能处理中心2及智能分析中心3。
进一步,所述监控策略设置单元11包括:
底层资源基础监控策略设置单元11,用于实时获取虚拟主机的技术指标并分别设置各技术指标触发告警的阈值及逻辑关系;所述技术指标包括中央处理器cpu利用率、虚拟主机内存使用率及磁盘io使用率。需要说明的是,底层资源基础监控策略中用户可以分别对“中央处理器cpu利用率、虚拟主机内存使用率及磁盘io使用率”这三个技术指标自定义设置触发告警的阈值,并且可以自定义这三个技术指标的逻辑关系。比如,对a虚拟机,用户可以设置当cpu利用率高于80%并且内存使用率高于90%的时候立刻触发虚拟机告警机制。
上层业务应用监控策略设置单元112,用于获取业务系统里安装的应用并设置开启业务监控功能;具体地,业务应用监控支持:mysql、oracle、web应用。mysql:业务系统、触发时间、连接状态、线程连接数、最频繁sql、慢查询sql;oracle:业务系统、触发时间、连接状态、线程连接数、最频繁sql、慢查询sql;web应用:业务系统、端口号、连接状态。
闲置资源高级监控策略设置单元113,用于为业务系统的虚拟机设定监控指标并根据监控指标判断虚拟机的闲置结果。所述监控指标包括指标单点闲置阈值、单点采集周期、闲置统计周期、指标闲置比例及逻辑关系。
为业务系统的虚拟机设定指标单点闲置阈值,即在某采集时间点上判断虚拟机是否为闲置的指标标准,对应具体的参数就是cpu、内存、存储的闲置阈值。如设置指标单点闲置阈值:cpu利用率≤85%,内存利用率≤60%,存储利用率≤90%,那么每个采集点得到的数据都会与设置好的单点闲置阈值进行对比和记录。
为业务系统的虚拟机设定单点采集周期,也就是采集时间的间隔。假设为业务系统a设置的采集周期为30分钟,那么监控系统每隔30分钟会采集一次业务系统a中的4台虚拟机的cpu、内存、存储利用率并与单点闲置阈值进行对比。
为业务系统的虚拟机设定闲置统计周期,即设置在一段时间内,闲置情况的统计。假设为业务系统a设置的闲置统计周期为10天,那么监控系统会通过设置好的策略以10天为一个周期,对这10天内,每隔30分钟都对业务系统a的虚拟机进行数据采集和闲置监控,得出闲置结果。
为业务系统的虚拟机设定指标闲置比例和逻辑关系。即设置cpu、内存、存储指标项闲置标准,假设为cpu设置的闲置比例为70%,为内存设置的闲置比例为80%,为存储设置的闲置比例为90%,它们的逻辑关系是且。在上文中,我们为业务系统a的虚拟机设置了10天的统计周期和30分钟的采集周期,并且为虚拟机设置了指标单点闲置阈值,分别为cpu利用率≤85%,内存利用率≤60%,存储利用率≤90%。那么10天内每台虚拟机采集到数量为:10×24×60/30=480。即480个cpu利用率的值、480个内存利用率的值、480个存储利用率的值。假设这10天时间内,采集到的cpu利用率≤85%的次数占总的次数占总的次数480的比例超过70%,并且采集到的内存利用率≤60%的次数占总的次数占总的次数480的比例超过80%,并且采集到的存储利用率≤60%的次数占总的次数占总的次数480的比例超过90%,那么可以判断该虚拟机在这10天的统计周期内,为闲置虚拟机。
如图4所示,所述智能分析中心3包括:
获取单元31,用于获取监控中心1的告警信息,所述告警信息包括:告警对象、虚拟机所在的业务系统、告警触发时间、告警的类型、触发告警时指标参数值及指标阈值;
划分单元32,用于划分告警信息的告警类型,所述告警类型包括底层资源基础、上层业务应用、闲置资源;
分析单元33,用于根据告警类型对告警信息进行规律分析及预判;其中,底层资源基础:分别分析cpu、内存、存储三个维度与时间、阈值的关系,并且根据过去一个月的规律预判未来一周内资源出现瓶颈的走势。上层业务应用:分别分析mysql、oracle查询语句的规律,统计一个月内的top最频繁sql和top慢查询。并且根据过去一个月的规律预判未来一周内会出现的最频繁sql和慢查询语句。闲置资源:分析哪些类型的业务系统存在的闲置虚拟机数量最多,并且在时间上统计闲置虚拟机数量变化趋势,并且根据过去一个月的规律预判未来一周内闲置数量的走势。
反馈单元34,用于将结果反馈至监控中心1。
由上可知,本发明具有以下有益效果:
1、本发明是以业务系统为颗粒度的自定义监控系统,允许用户在海量业务系统的云计算平台上以业务系统为单位,设置具有差异化的监控策略。
2、监控中心可以联动智能处理中心,由系统自动解决资源瓶颈问题。
3、闲置资源监控算法过程支持自定义,可以自定义指标单点闲置阈值、采集周期、统计周期、闲置比例逻辑关系。
4、监控系统包含智能分析中心,分析结果反向关联监控中心,提供决策数据。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!