基于Spark基因表达式优化的爆破振动预测方法与流程
技术特征:
1.一种基于Spark基因表达式优化的爆破振动预测方法,其特征在于包括下述步骤:
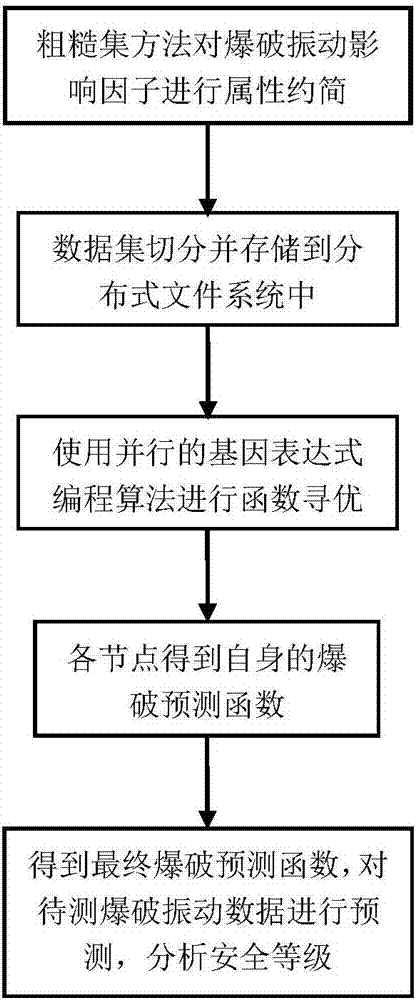
步骤1:利用数据预处理技术处理爆破数据,得到样本数据集,将样本数据集切分成多个子集,并且存储到HDFS分布式文件系统中;
所述的数据预处理为利用粗糙集的不协调率计算方法对爆破振动影响因子进行属性约简,具体包括以下步骤:
步骤1(a):基于原始数据集,计算原始数据集中各条件属性的不协调率,不协调率的公式定义为:
fi=(C-Ci)/C (1)
其中,fi为去掉条件属性i后的不协调率,C代表原始数据集,Ci代表去掉条件属性i之后不产生冲突的数据集,C-Ci即不协调的数据集;
步骤1(b):原始数据集中分别删除各条件属性i后,利用公式(1)计算出原始数据集中各条件属性i对决策属性的不协调率;
步骤1(c):根据步骤1(b)中得到的不协调率,去掉不协调率低于设定阈值的条件属性,保留高于阈值的条件属性;
步骤2:以步骤1(b)得到的各条件属性的不协调率,在原始数据集中删除不协调率低于阈值的条件属性后,从而生成新的数据集作为输入数据集,在各个节点上利用改进的基因表达式方法进行函数寻优,得到爆破振动效果预测函数;
步骤2中所述的改进的基因表达式方法进行函数寻优,具体包括以下步骤:
步骤2(a):对基因表达式方法中的个体染色体的结构进行调整,由原始“head+tail”结构调整为“head+body+tail”结构,head部分只能取运算集中的元素,body部分任意取运算集和终端集中的元素,tail部分只能取终端集中的元素;
步骤2(b):搭建Spark分布式集群,在Spark分布式集群中各个节点将训练数据作为弹性分布式数据集(Resilient Distributed Datasets,RDD)输入,将每个个体根据GEP的编码规则编码成个体,生成新的种群RDD数据集;
步骤2(c):将新生成的种群RDD数据集根据预先设定的适应度函数计算每个个体的适应度值;
步骤2(d):根据达尔文适者生存原则,选择适应度值高于设定阈值的个体进入下一代,生成优胜劣汰后的种群RDD;
步骤2(e):将步骤2(d)生成的种群RDD作交叉和变异操作;
步骤2(f):当步骤2(e)的交叉、变异操作达到设定的次数s,或者将测试数据代入预测函数,所述的预测函数为适应度值最大的个体所对应的函数,计算出的结果与实际值的误差结果小于设定误差值,则得到最终预测函数,本步骤结束;否则,进入步骤2(c)进行下一轮迭代;
在步骤2(c)到步骤步骤2(f)的迭代过程中,当迭代次数每迭代s/t次,则对各个节点上适应度值最大的个体进行个体扩散,扩散后再根据步骤2(f)所述的判断条件进行判断步骤是否结束,所述的t为节点间交流次数;
所述个体扩散是指在集群中包含m个节点,其中1个节点作为主节点,其余m-1个节点为从节点,每个从节点将本节点中适应度值最大的最优个体及从节点的编号发送给主节点,主节点从m-1个最优个体出选出适应度值最大的个体,并将该个体及该个体的节点的编号一起广播给所有从节点,并替换所有从节点中适应度值最小的个体,若被广播的个体的节点编号与从节点的节点编号相等时,则该从节点不做替换;
步骤3:将所需预测的工程爆破项目的数据参数输入到根据步骤2得到训练后的预测函数中,即可得到爆破振动峰值速度的预测值。
- 还没有人留言评论。精彩留言会获得点赞!