一种挖掘多维时序数据稀有模式的方法与流程
技术领域:
:本发明属于数据挖掘
技术领域:
,尤其涉及一种挖掘分析多维时序数据中的稀有模式的方法。
背景技术:
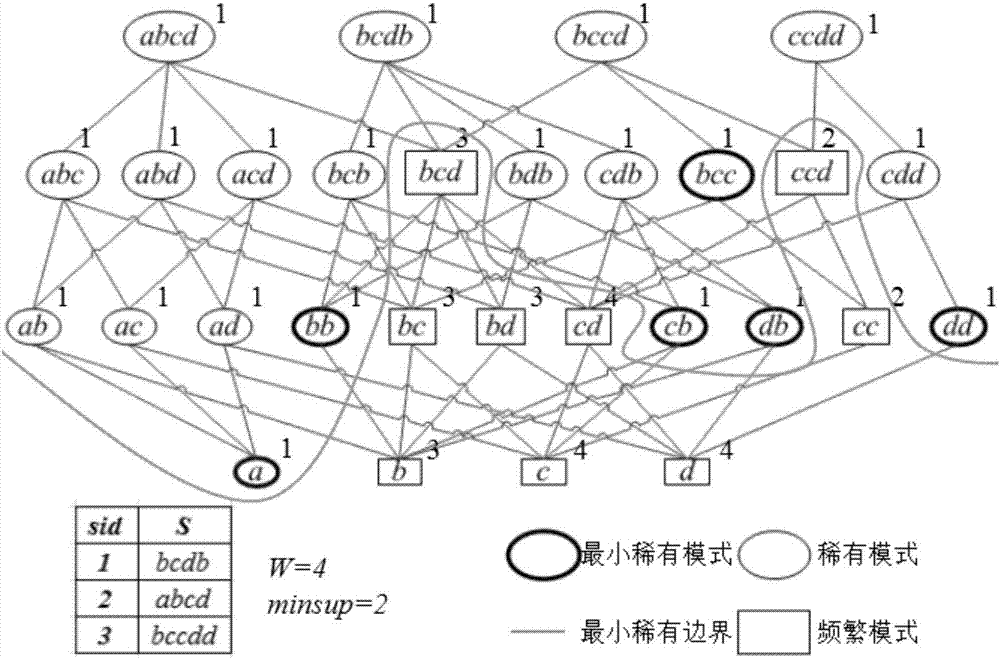
::多维时序数据分析在环境、金融、医疗等邻域具有广泛应用。例如,环境监测领域,相对于平常的天气监测数据,人们更关注于那些罕见的或者恶劣天气质量监测数据。常态化的空气质量数据是频繁出现的,而非常见的天气现象,如严重污染天气等,则相对少见,但这些异常天气也不是随机出现的,其中也存在一些共性的规律。对空气质量指标数据进行稀有模式分析,可以揭示出罕见天气产生的规律,以及不同指标之间的相互关系,从而为大气污染治理提供数据支持。在金融领域,可以用来检测异常交易。因此得到一个高效的多维时序数据稀有模式分析方法是非常具有实际意义的。现有的多维时序数据分析研究主要集中在频繁模式挖掘上,近年来由于稀有模式在异常检测中广泛应用,国内外的学者也取得了一定的研究成果。lei等人提出单向、逐层地挖掘稀有序列模式的arspm算法,随后提出了在搜索模式上采用双向搜索的优化算法biarspm算法。这两种算法都适合挖掘时间序列中的稀有模式的完全集,但是面对海量数据时,将遇到组合爆炸问题,导致算法效率下降。lei等人又提出了最小稀有序列模式概念,最小稀有序列模式包含稀有模式全集的信息,通过挖掘最小稀有模式,可以提高算法效率以及避免组合爆炸问题,并提出了amrspm算法。但是,amrspm算法只是挖掘了最小稀有模式,并没有挖掘出稀有模式的全集详细信息,在实际应用中有一定的局限性。此外,lin等人提出了一种挖掘稀有模式的nspm算法;hsueh等人提出了一种能够挖掘频繁模式和稀有模式的pnsp算法;dong等人提出了一个高效挖掘稀有模式的e-nsp算法。然而,这些现有的算法主要适用于一维时序数据集的稀有模式的发现,而现实中的时序数据一般呈现出多个维度,例如,空气质量中各个指标的监测数据。在实际应用中不同维度之间的稀有模式可能存在着某种因果关系,而仅仅分析一维时序数据的稀有模式,很难发现多维时序数据稀有模式之间的相互关系。技术实现要素:本发明要解决的技术问题是,提供一种挖掘多维时序数据的稀有模式的方法,首先利用lei等人提出的amrspm算法对一维时序数据提取最小稀有模式,并根据最小稀有模式去搜索稀有模式全集,然后利用聚类算法对所有维度的时序稀有模式全集进行聚类操作,把存在相关关系的多个维度之间的稀有模式归为一类,并输出。本发明面向海量多维时序数据集,提出了一种挖掘多维时序数据的稀有模式的方法。将海量的多维时序数据集分割成一维的时序数据集,利用amrspm算法对每一维度的时序数据计算最小稀有模式。然后把生成的最小稀有模式作为模式串字典,利用字符串匹配算法brute-fore或者kmp算法对每一维度时序数据搜索出全部的模式。相对于其他算法,amrspm算法只挖掘最小稀有模式,并且采用二分搜索的思想,快速对格空间进行搜索,从而减少了格空间的搜索量,挖掘出最小稀有模式。加上使用kmp算法来获取模式的全集详细信息,因此,这种组合可以避免组合爆炸问题,并且可以获得模式的全集详细信息。最后将得到所有维度的模式全集进行聚类操作,将不同维度的同时发生或者拥有先前滞后关系的稀有模式归为一类。由于不同维度的稀有序列都是非频繁项集,通过聚类算法将产生大量的簇,而且簇内数据是非频繁的稀有模式。所以采用affinitypropagation聚类算法(ap算法),ap算法相对于其他算法具有不需要制定最终聚类簇的个数,对初始相似度矩阵数据的对称性没有要求,而且模型对数据的初始值不敏感。通过调节算法的阻尼系数,可以灵活控制簇的数量。所以基于ap聚类的多维时序稀有模式的方法,可有效地解决在稀有序列形成的稀疏分布众多细小簇挖掘不完全问题。为了实现上述目的,本发明采用以下技术方案:为了避免在一维时序数据搜索稀有模式时出现的组合爆炸问题,所以采用amrspm算法可以避免挖掘稀有模式的全集。然后把得到的最小稀有序列作为模式串字典,使用kmp算法依次匹配对应的一维时序数据(目标串),并输出这一维度时序数据的稀有模式全集。在输出每一个稀有模式的信息应该包括,这个稀有模式的所在的维度,以及这个稀有模式在这个时序数据链中的起始位置(坐标)。最后,使用ap聚类算法对所有维度的稀有模式进行聚类操作。其中使用稀有模式的起始坐标来计算两个模式的相似度,并且采用欧式距离的相反数作为相似度的评价标准,很显然,相似度越大说明点与点的距离就越近,方便后面的计算。这样一来,就得到了一个基于ap聚类算法的多维时序数据集的稀有模式挖掘的方法。一种挖掘多维时序数据的稀有模式的方法包括以下步骤:步骤1、获取相关领域的多维时序数据集,并对这些数据进行预处理。步骤2、对预处理后的多维时序数据进行按照维度分组,使用amrspm算法计算每一维度时序数据的最小稀有模式。步骤3、把每一维度产生的最小稀有模式当作模式串字典,使用kmp算法,匹配当前时序数据,获取稀有模式的全集。步骤4、使用ap聚类算法,对多维时序数据所有维度的稀有模式全集进行聚类操作,把同时发生或者先前滞后关系的不同维度的稀有模式归为一类。作为优选,步骤2具体包括以下步骤:步骤2.1、设置滑动窗口的大小,以及最小支持度,并按照滑动窗口分割出相应的子模式作为格空间的上界;步骤2.2、分割出格空间的下界,使用二分查找思想,在格空间中进行“跳跃式”查找;步骤2.3、输出最小稀有模式的所有上界序列,即,稀有序列的全集;作为优选,步骤3具体包括以下步骤:步骤3.1、把最小稀有模式的所有上界模式作为模式串字典;步骤3.2、采用kmp算法,对一维时序数据(目标串)进行搜索获取所有稀有模式的位置信息。作为优选,步骤4具体包括以下步骤:步骤4.1、设置阻尼系数,以及ap算法迭代次数;步骤4.2、输入所有维度时序数据的稀有模式(包含位置信息);步骤4.3、计算相似矩阵,并迭代归属度矩阵和吸引度矩阵;步骤4.4、输出聚类结果(拥有同时发生或者先前滞后关系的稀有模式集);与现有技术相对,本发明具有以下明显优势:本发明方法在挖掘一维时序数据稀有模式时,采用挖掘时序数据的最小稀有模式信息,然后在格空间中获取所有稀有模式的全集,进而通过kmp算法获取所有稀有模式的详细信息(在时序数据中的起始位置)。相对其他方法,使用这种方式获取稀有模式的全集信息,可以避免在搜索模式时的组合爆炸问题,加之,kmp算法的时间复杂度为o(n+m),所以在面向海量的多维时序数据时,获取所有维度的稀有模式也可以拥有较好的性能表现。在后期的聚类操作上,采用ap算法,通过调节阻尼系数的大小,可以使众多的细小粒度的簇划分出来,并且不需要输入聚类簇的个数,从而避免簇的大小不稳定。此外,ap算法的聚类中心自身的数据点,而不是新生成一个簇的中心,且对数据的初始值不敏感。综上所述,本文提出的基于ap聚类的多维时序数据稀有模式挖掘方法具有面向海量数据、泛化能力强、应用领域广泛的优势。附图说明:图1为本发明所涉及方法的流程图;图2为本发明在时序数据中提取模式对应的格空间;表1为本发明在时序数据的模式全集信息的数据结构;图3为本发明ap算法聚类时的迭代图示;图4为本发明最终输出的多维时序数据稀有模式的分布图示;具体实施方式:以下结合具体实施例,并参照附图,对本发明进一步详细说明。本发明所用到的硬件设备有pc机1台;如图1所示,本发明提供一种挖掘多维时序数据稀有模式的方法,具体包括以下步骤:步骤1,获取相关领域的多维时序数据集,并对这些数据进行预处理。步骤2,对预处理后的多维时序数据进行按照维度分组,使用amrspm算法计算每一维度时序数据的最小稀有模式。步骤2.1,设置滑动窗口的大小w,以及最小支持度,并按照滑动窗口分割出w序列作为格空间的上界;步骤2.2,分割出格空间的下界,使用二分查找思想,在格空间中进行“跳跃式”查找;步骤2.3,输出最小稀有模式的所有上界序列,即,稀有模式的全集;如图2所示,每一维度时序数据形成的长度为w的模式作为搜索的上界,而最小粒度的模式作为格空间的搜索的下界,并使用二分法思想进行搜索。从上界向下搜索并计算相对的模式的支持度,如果为频繁的序列则停止向下搜索,其思想类似于apriori算法的中频繁序列的子串一定为频繁的。相对地,从最小粒度向上搜索,如果遇到非频繁的子串,则一定为最小稀有模式项,并以此为界限,向上全为稀有模式集。这样一来就可以获得这一维度的所有稀有模式。步骤3,把每一维度产生的最小稀有模式当作模式串字典,使用kmp算法,匹配当前时序数据,获取稀有模式的全集。步骤3.1,把最小稀有模式的所有上界模式作为模式串字典;步骤3.2,采用kmp算法,对一维时序数据(目标串)进行搜索获取所有稀有模式的位置信息。如表1所示,在步骤3.2之后,将获的对应维度稀有模式的全集的详细信息,其中{(abc1,<t1,t2>),(abc2,<t1,t2>)},的abc1表示稀有模式abc第一次出现的模式,abc2第二次出现的模式,<t1,t2>表示稀有模式在对应维度的时序数据序列的开始和结束的位置信息,并作为后面聚类操作中的距离(相似度)评估标准。表1:sid稀有子序列全集信息1{(abc1,<t1,t2>),(abc2,<t1,t2>)},{(abd1,<t1,t2>)}…2{(ac1,<t1,t2>)},{(bcd1,<t1,t2>)},{(bc2,<t1,t2>)}…3{(bd1,<t1,t2>)},{(cbb1,<t1,t2>),(cbb2,<t1,t2>)}………步骤4,使用ap聚类算法,对多维时序数据所有维度的稀有模式全集进行聚类操作,把同时发生或者先前滞后关系的不同维度的稀有模式归为一类。步骤4.1,设置阻尼系数,以及ap算法迭代次数;步骤4.2,输入所有维度时序数据的稀有模式(包含位置信息);步骤4.3,计算相似矩阵,并迭代归属度矩阵和吸引度矩阵;步骤4.4,输出聚类结果(拥有同时发生或者先前滞后关系的稀有模式集);如图3所示,ap算法以稀有模式在时序数据中的位置信息作为相互之间的距离评价标准,并采用欧式距离的相反数作为相似度矩阵值。其公式如下:-||(xi-xj)2+(yi-yj)2||其中,xi,xj,yi,yj,分别代表两个不同维度的稀有序列的起始位置坐标(xi,yi)(xj,yj),而公式则表示这两个稀有系列的之间的欧式距离。很显然,不同维度的模式以及同一维的模式,如果它们是同时发生或者拥有先前滞后的关系,那么它们的位置一定处在某一个模式的周围,而取负值,则说明越靠近“距离”越大则越相近,方便后面吸引度矩阵和归属度矩阵的迭代计算。其中responsibility:r(i,k)用来描述点k适合作为数据点i的聚类中心的程度,即吸引矩阵的计算。availability:a(i,k)用来描述点i选择点k作为其聚类中心的适合程度,即,归属度矩阵的计算。其计算公式如下:r(i,k)=s(i,k)-max{a(i,j)+s(i,j)}其中,a(i,j)表示除稀有序列j外其他序列对i序列的归属度值;s(i,j)表示除j外其他序列对i的吸引度,所以r(i,k)表示序列k成为序列i的聚类中心的累积证明,r(i,k)值越大,则表示序列k成为聚类中心的能力较强。图4所示,为本发明最终输出的多维时序数据的稀有模式示例图。以上实施例仅为本发明的示例性实施例,不用于限制本发明,本发明的保护范围由权利要求书限定。本领域技术人员可以在本发明的实质和保护范围内,对本发明做出各种修改或等同替换,这种修改或等同替换也应视为落在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1