一种层次性分类方法及装置与流程
本发明涉及神经网络学习技术领域,特别涉及一种层次性分类方法及装置。
背景技术:
神经网络被广泛应用在图像识别领域。一般情况下,一个训练好的神经网络只能够对特定的几类事物进行分类,并且要求这几种类别之间独立不包含,如苹果和梨,且需要对所有类别的得分进行归一化(所有数值在0~1之间且和为1)。我们可以把这些类别称为细类别,在这之上则是粗一级类别,例如苹果和梨都属于梨果类,再往上粗一级别还有水果类,依次类推。假如存在归一化的粗类输出得分,因为粗类囊括的类别范围更大,所以理论上目标的粗类得分应当比包含的细类得分高。
神经网络提取的图像特征只是物体的表面特征,例如形状、纹理、颜色,还不能完全理解事物间的本质区别,所以对外表相近的事物容易混淆,具体表现就是:相似物品的得分相近,同时得分也都比较低,不易区分。
一个用于多分类的图像识别系统的一般工作流程是:将待分类图像输入神经网络,得到归一化的数组,数组中每个地址位置对应一个类别,每个数值代表了这幅图像属于这个类别的得分或预测概率,然后在数组中查找最大的得分及其所属的类别,若这个最大得分大于某个阈值则将其得分值和类别输出,否则不输出。在一些开放的图像识别应用场景中,需要识别区分的种类非常多,例如冰箱内部物品识别、识别功能演示,这种场景经常遇到新的、未知的、模糊的或特征相似的物体类别,这会导致神经网络输出的最大得分仍然较小,那么上述用阈值作区分的办法就可能造成漏识别或错识别,准确率下降,影响用户体验。
技术实现要素:
本发明主要解决的技术问题是提供一种层次性分类方法及装置,以解决现有技术中图像识别任务中当所有细类的得分较低时导致的错漏识别技术问题。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种层次性分类方法,所述方法包括:神经网络接收输入的图像,并对所述图像进行识别处理以输出归一化得分;其中,所述神经网络预先已经完成训练,输出的所述归一化得分为对类别的预测概率;查找所述归一化得分中的最大得分,并确定对应的类别;判断所述最大得分是否大于阈值;当所述最大得分大于所述阈值时,输出所述最大得分及对应的类别作为识别结果;当所述最大得分不大于所述阈值时,将所述得分分布转换为粗类得分分布,然后循环执行查找所述归一化得分中的最大得分,并确定对应的类别,以及判断所述最大得分是否大于阈值的步骤,直至确定所述最大得分大于所述阈值时停止循环,输出所述最大得分及对应的类别作为识别结果。
其中,将所述得分分布转换为粗类得分分布,具体包括:所述神经网络输入作为细分类的得分分布;输入类别层次树;其中,所述类别层次树预先构建,用于存储细类到粗类的树形关系结构;以当前输入的作为细分类的所述得分分布为子节点,查询所述类别层次树上所有父节点,以得到对应的粗类;计算全部粗类的得分,并进行归一化处理;以及输出粗类的得分分布。
其中,计算全部粗类的得分,并进行归一化处理,具体为:利用如下计算公式计算全部粗类的得分:
其中,m为细类数量,n为粗类数量,c为粗类编号;若c包含mc为粗类c包含的细类数量,rc为粗类c的平衡系数,P(c)为粗类c的得分,x为粗类c包含的细类编号,P(x)为细类得分;对计算得到的粗类得分利用如下公式进行归一化处理。
其中,构建所述类别层次树,具体包括:选取部分数据集作为评估集,并输入所述评估集;神经网络识别处理所述评估集以得到归一化的输出结果;结合真实标签,统计神经网络的细分类结果,构建细类混淆矩阵;将所述混淆矩阵中易混淆类别聚为一组,作为粗类;对所述粗类命名、编号,以树形数据结构保存细类和粗类的关系;判断保存所述粗类的节点是否到达树的根节点;若是,则保存并输出所述类别层次树;否则,计算所述粗类混淆矩阵,并从将所述混淆矩阵中易混淆类别聚为一组作为粗类的步骤开始循环,直至保存所述粗类的节点达到树的根节点时,停止循环,并输出所述类别层次树。
其中,计算粗类混淆矩阵,具体为:利用如下计算公式计算所述粗类混淆矩阵:
其中,m为细类数量,i、j为细类编号,xij为细类混淆矩阵X中第i行第j列的元素;n为粗类数量,u、v为粗类编号,cuv为则粗类混淆矩阵C中的第u行第v列的元素,U、V分别为粗类u、v包含的细类编号的集合。
为解决上述技术问题,本发明采用的另一个技术方案是:提供一种层次性分类装置,所述装置包括:图像处理单元,用于接收输入的图像,并对所述图像进行识别处理以输出归一化得分;其中,所述输出的归一化得分为对类别的预测概率;查找单元,用于查找所述归一化得分中的最大得分,并确定对应的类别;判断单元,用于判断所述最大得分是否大于阈值;识别结果输出单元,用于当所述最大得分大于所述阈值时,输出所述最大得分及对应的类别作为识别结果;粗类转换单元,用于当所述最大得分大于所述阈值时,将所述得分分布转换为粗类得分分布,并触发所述查找单元查找所述归一化得分中的最大得分以确定对应的类别,以及触发所述判断单元对所述最大得分是否大于阈值进行判断。
其中,所述粗类转换单元具体用于:以当前输入的作为细分类的所述得分分布为子节点,查询类别层次树上所有父节点,以得到对应的粗类;其中,所述类别层次树预先构建,用于存储细类到粗类的树形关系结构;计算全部粗类的得分,并进行归一化处理以得到所述粗类的得分分布。
其中,所述粗类转换单元具体用于:利用如下计算公式计算全部粗类的得分:
其中,m为细类数量,n为粗类数量,c为粗类编号;若c包含mc为粗类c包含的细类数量,rc为粗类c的平衡系数,P(c)为粗类c的得分,x为粗类c包含的细类编号,P(x)为细类得分;对计算得到的粗类得分利用如下公式进行归一化处理。
其中,还包括类别层次树构建单元,用于:选取部分数据集作为评估集,并输入所述评估集;识别处理所述评估集以得到归一化的输出结果;结合真实标签,统计神经网络的细分类结果,构建细类混淆矩阵;将所述混淆矩阵中易混淆类别聚为一组,作为粗类;对所述粗类命名、编号,以树形数据结构保存细类和粗类的关系;判断保存所述粗类的节点是否到达树的根节点;若是,则保存并输出所述类别层次树;否则,计算所述粗类混淆矩阵,并从将所述混淆矩阵中易混淆类别聚为一组作为粗类的步骤开始循环,直至保存所述粗类的节点达到树的根节点时,停止循环,并输出所述类别层次树。
其中,所述类别层次树构建单元具体用于利用如下计算公式计算所述粗类混淆矩阵:
其中,m为细类数量,i、j为细类编号,xij为细类混淆矩阵X中第i行第j列的元素;n为粗类数量,u、v为粗类编号,cuv为则粗类混淆矩阵C中的第u行第v列的元素,U、V分别为粗类u、v包含的细类编号的集合。
以上方案中,通过本发明中的层次性分类方法及装置,当所有细类的得分都较低时转换为粗类识别结果,因为粗类的得分一般大于细类得分,所以在用阈值筛选的时候能够保留更多结果且每个结果的可信度更高,从而减少错漏识别、提高准确率。
附图说明
图1是本发明实施方式中的一种层次性分类方法的流程示意图;
图2是图1所示的得分分布作为细类得分分布转换为粗类得分分布方法的流程示意图;
图3是本发明实施方式中的构建类别层次树方法的流程示意图;
图4是本发明第一实施方式中的一种层次性分类装置的结构示意图;
图5是本发明第二实施方式中的一种层次性分类装置的结构示意图。
具体实施方式
为详细说明本发明的技术内容、构造特征、所实现目的及效果,以下结合附图和实施例对本发明进行详细说明。
请参阅图1,为本发明实施方式中的一种层次性分类方法的流程示意图。该方法包括如下步骤:
步骤S10,神经网络接收输入的图像,并对该图像进行识别处理以输出归一化得分。
其中,该图像可以来源于图片、影片、照相机、摄像机等多种途径。
该神经网络预先已经训练完成且具备分类能力,其输出具有归一化的分布形式,即,输出的所有数值均在0~1的区间,且输出的所有数值之和为1。该神经网络输出的数值代表对各个类别的评分或预测概率。
进一步地,该神经网络的结构可以是线性分类器、BP神经网络、深度卷积神经网络或递归神经网络等等。该神经网络可以应用于图像识别、目标检测、图像分割等与分类有关的任务。
步骤S11,查找归一化得分中的最大得分p和对应的类别c。
例如,当p=0.75,c=苹果。
步骤S12,判断最大得分p是否大于阈值h;若p>h,则进入步骤S13;否则,进入步骤S14。
其中,0<h<1,并且阈值h在不同循环阶段(即,不同类别层次)可以采用不同的值,例如,第一次循环时h=0.7,第二次循环时h=0.8,以此类推。阈值h的具体数值一般由技术人员根据实际测试情况而设定。
步骤S13,输出p、c值作为最终的识别结果;然后,流程结束。
步骤S14,将得分分布作为细类得分分布,转换为粗类得分分布;然后,返回步骤S11。
细类转换为粗类以后,粗类得分大于等于所属细类的得分,所以循环若干次以后,粗类得分(最大为1.0)必定大于阈值,从而跳出循环。
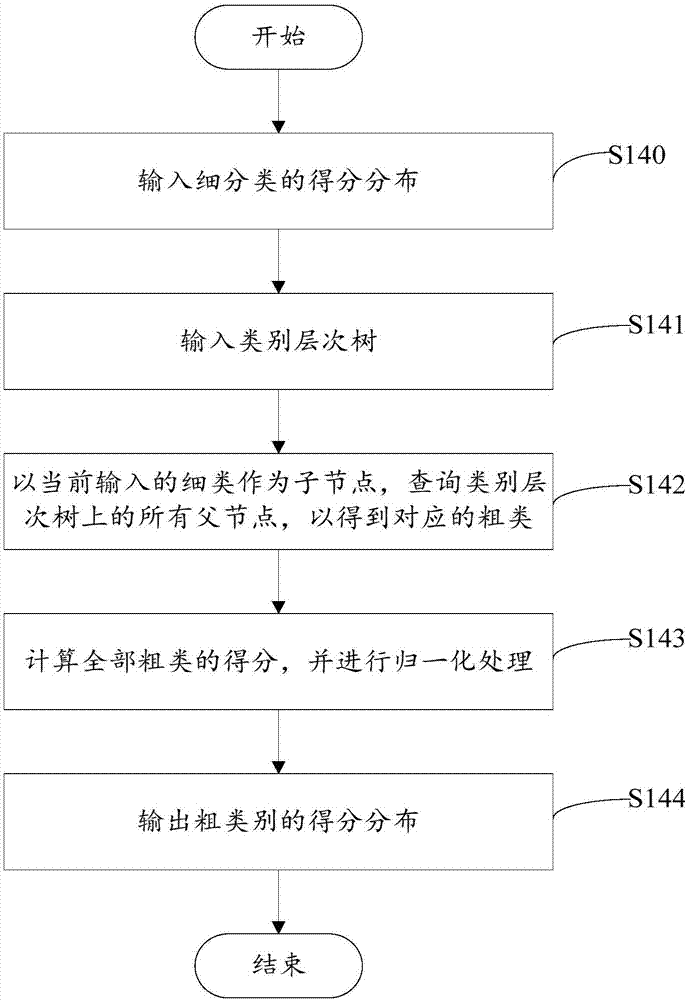
请参阅图2,步骤S14,即,将得分分布作为细类得分分布转换为粗类得分分布,具体包括如下步骤:
步骤S140,输入细分类的得分分布。
具体地,该输入可能来自神经网络的输出,也可能来自该粗类转换模块的上一轮递归输出。该得分分布必须是归一化的分布形式,即,所有数值在0~1之间,且和为1。以下表为例,表中每一层(最顶层除外)都是归一化的,都可以作为输入。
表1类别层次树示例
步骤S141,输入类别层次树。
其中,该输入是树型的数据组织结构。如表1所示,为类别层次树的一个实施例,在类别层次树中,树的子节点代表细一级类别,例如,梨果类和坚果类;树的父节点则代表粗一级类别,例如,水果。所以树的叶子节点代表最精细的类别,例如,表1最底层的苹果、梨、核桃等,这些类别和前述神经网络的输出类别相一致;树的根节点只有一个,例如,表1最顶层的实物类,它是最粗糙的类别,囊括了所有的细类。
步骤S142,以当前输入的细类作为子节点,查询类别层次树上的所有父节点,以得到对应的粗类。
例如,已知输入是表1中的梨果类、坚果类、矿泉水和雪碧的分布,则查询得到粗类为:水果、饮料。
步骤S143,计算全部粗类的得分,并进行归一化处理。
样本不均衡是大数据中的常见问题,在深度学习中的一种解决方法是为每个类别分配平衡系数,计算时每类对应的损失函数乘以该系数,其中,平衡系数=平均每类样本数/该类样本数。在本实施方式,假设细类的得分是经过平衡样本以后的结果,但粗类包含的细类数量不一,例如表1中,梨果类包含两种细类,而雪碧只包含一种,这会导致粗类的样本仍然不均衡。可以看出,粗类的样本数就是其包含的细类数,那么类似的,可以计算出粗类的平衡系数。具体地,计算公式如下:
设共有m个细类,n个粗类,c为粗类编号;若c包含mc个细类,则粗类c的平衡系数rc为:
设粗类c得分为P(c),其包含的细类编号为x,细类得分为P(x),则:
对计算得到的粗类得分利用如下公式进行归一化处理:
以前述表1为例,苹果和梨为细类,梨果类为粗类,则梨果类的平衡系数为:7/(4×2)=0.875,所以P(梨果类)=0.895×[P(苹果)+P(梨)]=0.875×(0.5+0.2)=0.6125,同理可以计算出坚果类、矿泉水、雪碧的得分分别为:0.21875,0.035,0.0175,最后再归一化分别得到表1第三行的粗类得分(四舍五入)为:[0.6930,0.2475,0.0396,0.0198]。同理可计算出表1中水果、饮料的得分。
步骤S144,输出粗类别的得分分布。
进一步地,请参阅图3,该类别层次树用于存储细类到粗类的树形关系结构。构建该类别层次树的方法包括如下步骤:
步骤S20,选取部分数据集作为评估集,输入评估集;
其中,评估集包含各类图像和真实标签,每类图片不宜过少,大于50张较为合适。
步骤S21,神经网络识别处理该评估集,得到归一化的输出结果;
步骤S22,结合真实标签,统计神经网络的细分类结果,构建细类混淆矩阵;
混淆矩阵是一种可视化数学工具,用于比较预测结果和真实标签值。若细类数为m,则细类混淆矩阵X的大小为m×m,矩阵的列对应预测的精细类别,矩阵的行对应精细的真实标签,也就是说矩阵的第i行第j列的元素表示第i类真实的标签被分类为第j类预测标签的数量。以表2为例,矩阵主对角线的数值是被正确分类的数量,其余是被错误分类的数量,错误分类数量越多说明对应类别越容易混淆。
表2细类混淆矩阵示例
步骤S23,将混淆矩阵中易混淆类别聚为一组,作为粗类;
其中,观察混淆矩阵以发现易混淆类别,并以当前类别作为细类,将易混淆的多个细类聚为一组,作为粗类。人为地或自动地将易混淆的多个细类聚为一组,作为粗类。例如,人为将苹果和梨聚合为梨果类。单个细类可以聚合为一个粗类,全部细类也可以聚合成一个粗类。
步骤S24,对该粗类进行命名、编号,以树形数据结构保存细类和粗类的关系。
其中,保存粗类为树的父节点,对应细类为子节点,所有关系结构构成一个类别层次树。
步骤S25,判断保存粗类的节点是否到达树的根节点,若是,则进入步骤S26;否则,进入步骤S27。
其中,当粗类只有一个时,表示到达根节点,即,判断粗类是否只有一个,以确定是否到达根节点。
因为粗类数量总是小于细类数量,所以,循环若干次以后粗类必定只有一个(即,前述“实物类”),即表示到达根节点,从而跳出循环。
步骤S26,保存并输出该类别层次树。然后,流程结束。
步骤S27,计算粗类混淆矩阵,然后,返回步骤S23。
其中,粗类混淆矩阵的计算公式如下:
设细类数为m,则细类混淆矩阵X的大小为m×m,第i行第j列的元素为xij,i和j也表示了细类编号;设粗类数为n,则粗类混淆矩阵C的大小为n×n,第u行第v列的元素为cuv,u和v也表示了粗类编号,U、V分别为粗类u、v包含的细类编号的集合。循环地计算每一个cuv,则cuv的计算公式为:
以表3为例,梨果类包含苹果和梨,所以第一个数值97等于前述表2中的前两行前两列的数值之和,即94=46+2+2+47;坚果类包含核桃和板栗,所以第一行第二个数值3等于前述表2中的前两行第三第四列的数值之和,即3=1+1+1+0,以此类推。
表3粗类混淆矩阵示例
请参阅图4,为本发明第一实施方式中的一种层次性分类装置的结构示意图。其中,该装置30可应用于多分了的图像识别场景中,该装置30可设置在各种运算设备,例如,计算机、掌上电脑、单片机等,可以是运行于这些设备的软件单元、硬件单元或软硬件相结合的单元,也可以作为独立的挂件集成到这些设备中或运行于这些设备的应用系统中。
该装置30包括:
图像处理单元31,用于接收输入的图像,并对该图像进行识别处理以输出归一化得分;其中,该输出的归一化得分为对类别的预测概率。在本实施方式中,该图像处理单元设置在一神经网络模块,用于通过神经网络处理和识别图像,得到图像的细类得分预测。该神经网络可以被部署在云端或本地的计算设备。进一步地,该神经网络模块是已经训练完成的且具备分类能力的,其输出必须具有归一化的分布形式。
查找单元32,用于查找该归一化得分中的最大得分,并确定对应的类别;
判断单元33,用于判断该最大得分是否大于阈值;
识别结果输出单元34,用于当该最大得分大于该阈值时,输出该最大得分及对应的类别作为识别结果;
粗类转换单元35,用于当该最大得分不大于该阈值时,将该得分分布转换为粗类得分分布,并触发该查找单元32查找该归一化得分中的最大得分以确定对应的类别,以及触发该判断单元33对该最大得分是否大于阈值进行判断。
进一步地,该述粗类转换单元35具体用于:
以当前输入的作为细分类的所述得分分布为子节点,查询类别层次树上所有父节点,以得到对应的粗类;其中,该类别层次树预先构建,用于存储细类到粗类的树形关系结构;
利用如下计算公式计算全部粗类的得分:
其中,m为细类数量,n为粗类数量,c为粗类编号;若c包含mc为粗类c包含的细类数量,rc为粗类c的平衡系数,P(c)为粗类c的得分,x为粗类c包含的细类编号,P(x)为细类得分;以及
对计算得到的粗类得分利用如下公式进行归一化处理。
进一步地,该装置30还包括类别层次树构建单元36,用于用于构建类别层次树,以描述所有细类到粗类的关系结构。具体地,该类别层次树构建单元36用于:
选取部分数据集作为评估集,并输入该评估集;
识别处理该评估集以得到归一化的输出结果;
结合真实标签,统计神经网络的细分类结果,构建细类混淆矩阵;
将该混淆矩阵中易混淆类别聚为一组,作为粗类;
对该粗类命名、编号,以树形数据结构保存细类和粗类的关系;
判断保存该粗类的节点是否到达树的根节点;若是,则保存并输出该类别层次树;否则,计算该粗类混淆矩阵,并从将该混淆矩阵中易混淆类别聚为一组作为粗类的步骤开始循环,直至保存该粗类的节点达到树的根节点时,停止循环,并输出该类别层次树。
进一步地,该类别层次树构建单元36利用如下计算公式计算粗类混淆矩阵:
其中,m为细类数量,i、j为细类编号,xij为细类混淆矩阵X中第i行第j列的元素;n为粗类数量,u、v为粗类编号,cuv为则粗类混淆矩阵C中的第u行第v列的元素,U、V分别为粗类u、v包含的细类编号的集合。
请参阅图5,进一步地,该装置40还包括通信模块47,用于实现各单元之间的通信,例如,传输识别结果给其他模块或其他模块对神经网络的控制。若神经网络被部署在云端,通信模块代表了以太网、WiFi或3G等通信形式;若神经网络被部署在本地,通信模块则代表了局域网、交换机、总线等通信形式。
该装置40还包括存储器48,用于存储和交换各个模块之间的数据和记录上述计算机程序本身。例如,这些数据包括类别层次树结构、神经网络模型结构、由细到粗的各个阶段的分类结果、预设阈值参数等。该存储器的介质可以是例如软盘、硬盘、CD-ROM和半导体存储器等。
如上所述,通过本发明中的层次性分类方法及装置,当所有细类的得分都较低时转换为粗类识别结果,因为粗类的得分一般大于细类得分,所以在用阈值筛选的时候能够保留更多结果且每个结果的可信度更高,从而减少错漏识别、提高准确率。
进一步地,本发明对新的或未知的物体类依然能够进行预测分类,例如网络看到一张骡子的图片,所以不确定是驴,仍然能预测为四蹄动物;本发明只是对识别结果的进一步处理,即增加了类别层次树构建模块和粗类转换模块,而不要求特殊的神经网络结构和训练方式,方法流程简单、运算量小,有较强的易用性和实用性。
以上所述仅为本发明的实施方式,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!