基于时间和空间数据模型的时空数据处理平台及处理方法与流程
本发明属于时空大数据处理和分析技术领域,具体涉及一种集数据采集、处理、存储、分析于一体的时空大数据处理平台及其处理方法,主要用于时空数据的快速分析、写入、持久化、多纬度聚合查询及交互分析。
背景技术
随着现代gis系统(gis,全称:geographicinformationscience,地理信息科学的缩写)快速发展和技术应用的深入,很多场景已不再满足于简单的路径截取、位置查询、结果评估,而是要在高时间、高空间多维数据基础上,对数据进行复合查询显示、交互分析、区域统计、历史比较和叠加分析等,这些需求在已有gis系统里实现起来都非常复杂,需要编写大量程序,开发时间比较长,而且程序运行速度比较慢。
为了解决上述问题,提高大规模时空数据分析的效率,例如降低数据分析处理的难度及能够快速的对时空数据进行迭代处理,同时减少程序编写量,缩短开发时间,降低对专业gis知识的依赖程度,我们开发了基于时间和空间数据模型的时空数据处理平台及其处理方法。
技术实现要素:
为了解决现有技术的上述问题,本发明提供一种基于时间和空间数据模型的时空数据处理平台,其通过对时间与空间数据联合建立数据模型,可以实现空间要素随时间的变化,将地理事物和现象的时间、空间及属性特征有机结合,以丰富地理事物和现象作为表达内容,同时支持时空数据快速分析、写入、持久化、多纬度聚合查询。
本发明还提供一种基于时间和空间数据模型的时空数据处理方法,其通过对时间与空间数据联合建立数据模型,可以实现空间要素随时间的变化,将地理事物和现象的时间、空间及属性特征有机结合,以丰富地理事物和现象作为表达内容,同时支持时空数据快速分析、写入、持久化、多纬度聚合查询。
为了达到上述目的,本发明采用的主要技术方案包括:
一种基于时间和空间数据模型的时空数据处理平台,其包括:
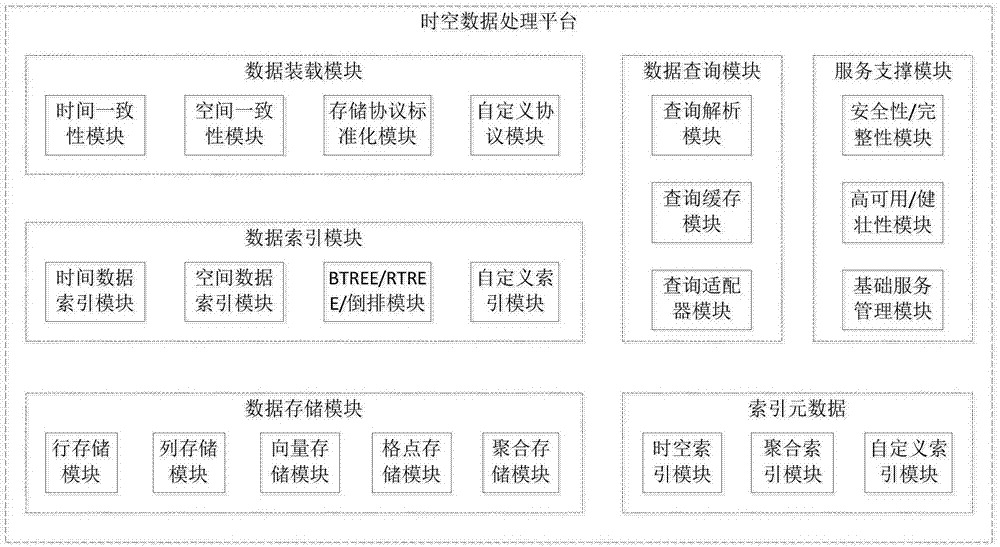
数据装载模块,作为时空数据处理平台的数据接入组件,用于异构时空数据的接入,例如提供标准的sdk和数据接入方法,为时空数据处理平台及/或第三方数据接入提供标准化的数据接入过程;
数据索引模块,用于完成时空数据索引过程,较佳的,当数据接入后,首先对数据按时间和空间进行索引;
数据存储模块,用于对索引后的数据进行存储,数据存储较佳是nosql数据库,也可以是其它数据存储服务,例如hbase、casandra等;
数据查询模块,用于时空数据查询,较佳的,它是数据查询的统一出口,用户可以自定义模型对数据进行查询,查询模型的格式为json;
数据查询服务支撑模块,用于实现数据存储加密、传输加密、组件服务的高可用等;
数据分析模块,用于提供数据分析服务,例如叠加分析、预测、地理代数分析等;
数据分析服务支撑模块,用于数据分析的并行计算支撑,其底层基于spark并行计算框架;
基础服务支撑模块,用于实现整个平台的管理,例如:集群服务管理、状态监控、安装部署等。
借助上述方案,本发明的基于时间和空间数据模型的时空数据处理平台,其通过对时间与空间联合建立数据模型,能够实现空间要素随时间的变化,将地理事物和现象的时间、空间和属性特征有机结合,是集时间和空间地理信息数据采集、处理、存储、展现于一体的时空数据库。
本发明的一个实施例中,数据接入组件为api编程模型(api,全称applicationprogramminginterface,应用程序编程接口的缩写),借此,使得开发者不仅可以编写新的java代码,也可以重用现有的通用java代码,可以降低编写大数据应用所需的专业知识要求,有助于降低应用门槛,使其更易推广普及。例如,现有的演示和可重用的算子就能够促进应用程序的快速开发。
较佳的,api编程模型支持原生的hadoop,原生的hadoop支持能够使并行数据处理平台(即时空数据处理平台)快速的安装在现有yarn(yarn,全称yetanotherresourcenegotiator,另一种资源协调者的缩写)集群中。
其中,yarn集群包括:
若干节点,用于集群目录管理、数据存储、任务调度和任务执行;
若干节点管理器nodemanager(nm),用于管理每个节点上的资源和任务;
动态的资源池container,用于封装节点上的对应资源;
若干表示对应应用的应用管理器appmaster(am),用于对运行在集群中的任务进行管理,每一个应用管理器appmaster拥有多个资源池container在节点管理器nodemanager上运行;
资源管理器resourcemanager(rm),负责整个yarn集群的资源管理和分配。
其中,每个节点管理器可以对应多个资源池container。
其中,节点管理器nodemanager一方面定时地向资源管理器rm汇报本节点上的资源使用情况和各个资源池container的运行状态;另一方面,它接收并处理来自应用管理器am的资源池container启动/停止等各种请求。
借助上述yarn集群结构,当结点运行失败时,能够通过资源管理器自动恢复,而无任何状态和数据的丢失。
同时,使得本发明的时空数据处理平台能够在hadoop集群上以线性的方式进行扩展,达到每秒处理数十亿事件的水平。
其中,所述yarn集群设置hdfs(hdfs是hadoopdistributefilesystem的简称,也就是hadoop的一个分布式文件系统)作为后端的检查点机制,能够保证无论是机器故障或处理流程发生失败时,都能够将应用状态保存,保证使其自动快速恢复。
在实际应用时,客户在并行处理管理平台提交任务包,hadoop集群上的资源管理器接受客户提交的任务包,根据各节点的节点状态、资源请求管理和分配yarn集群的资源,例如向各节点分配节点任务,进而完成任务包的处理。
其中,各节点的节点管理器向资源管理器反馈各节点的节点状态。
其中,各节点的节点任务向本节点或其他节点的资源池中的应用管理器反馈任务状态。
其中,各节点的资源池中的应用管理器向资源管理器请求资源。
借此,本发明的并行数据处理平台可以实现高可用的事件流转。
本发明的一个实施例中,数据装载模块包括下列组件中的任一个或任几个:
时间一致性组件,用于实现数据的时间一致性控制,即将时间格式统一为标准的utc时间;
空间一致性组件,用于实现数据的空间一致性控制,对所有数据添加经度、纬度和高度3个基本空间属性;
存储协议标准化组件,用于统一数据存储格式,对数据进行压缩转换,提高存储空间利用率;
自定义协议组件,用于数据传输协议的标准化,例如tcp、avro、thrift。
借此,可以进行时间和空间数据信息的采集,支持时空数据的快速写入,进行统一数据装载,有利于降低数据分析处理的难度,提高平台整体运行速度,解决大规模时空数据分析的效率问题。
其中,数据装载模块还包括下列组件中的任一个或任几个:
tjsjmangement组件(即并行处理管理组件),用于供应用管理员进行管理、监控和可视化操作;
tjsjassemble程序组件(即装配程序组件),用于供用户直观地构建各种数据接入组件。
应用管理员可以从tjsjmangement组件(即并行处理管理组件)完成一整套的管理、监控和可视化操作,可以通过tjsjassemble程序组件(即装配程序组件)这个程序组件装配工具,来直观的构建各种数据接入组件。
本发明的一个实施例中,数据索引模块包括下列组件中的任一个或任几个:
时间数据索引模块,用于实现对数据按时间属性进行索引;
空间数据索引模块,用于实现对数据按空间属性进行索引;
btree模块,用于低纬度数据的索引;
rtree模块,用于高纬度数据的索引;
倒排索引模块,用于提高数据查询效率,对需要查询和检索的属性创建倒排索引;
自定义索引模块,用于供用户自定义创建索引,例如当现有索引方法不能满足需求时,由用户自定义创建索引。
借此,可以进行统一数据索引,支持多维度聚合查询。
本发明的一个实施例中,数据存储模块包括下列组件中的任一个或任几个:
行存储模块,用于数据管理应用较多的场景,借以获得较快的存取速度,便于数据更新及管理,但数据量较大时存取效率会变低;
列存储模块,用于实时计算且数据量较大的应用场景,借以提高数据处理的速度,但数据管理的效率较低;
向量存储模块,用于地理数据模型中区域、道路、河流的存储,可以链表的方式存储在系统中;
格点存储模块,根据相应的数据精度对数据进行格点化并存储到系统中;
聚合存储模块,用于对数据进行预计算,在数据接入的进程按照一定的规则和维度,对数据的指标进行计算并存储,以便在后续查询的时候,可以直接查询聚合结果。
本发明的时空数据处理平台中,时空数据索引与存储较佳的可以采用瓦片金字塔技术。
例如,可以采用如下方式实施:
根据实际数据提供给数据分析服务平台所需的数据的缩放级别数,建立网格坐标系,同时设置数据比例尺最大,缩放级别最低的数据层级位于金字塔的底层,并将其定义为第0层,按照从左到右、从下到上的规则进行切片;
将该0层数据瓦片的左上角开始进行切割分块,分割成大小相同的正方形数据瓦片,用(tile)表示,从而得到第0层的瓦片矩阵;
在第0层数据瓦片的基础上再次按照分块原则,对第一层数据同样建立网格坐标系,以同样的方法进行切割,同时将该层每2*2像素合成为一个像素,形成第1层数据瓦片,并对该层数据进行分块切割,得到与第0层相同大小的正方形数据瓦片,形成第1层瓦片矩阵;
依此循环,应用类似的方法生成第二层瓦片矩阵、第三层矩阵、直到第n-1层矩阵,影像数据就可以采用瓦片金字塔服务模型的结构存储管理。
具体计算方式为:
假设第0层分辨率为res0,l为金字塔的层数,第l层的分辨率用resl表示,则第l层的分辨率resl由下面公式计算得出:
resl=res0*2l(1);
设第l层像素矩阵大小用rowl*coll表示,正方形瓦片大小用height*width表示,相邻层数的重叠度用over_size表示,则瓦片矩阵的行列(trowl*tcoll)由下列式子计算:
trowl=(rowl-over_size)/height(2),
tcoll=(coll-over_size)/width(3);
按照2*2像素将瓦片合成,形成第l+1层时,第l+1层的像素矩阵行列pirow(l+1)*picol(l+1)的大小和分辨率由下面公式计算:
pirow(l+1)=pirowl/2(4),
picol(l+1)=picoll/2(5),
res(l+1)=resl/2(6)。
在实际应用中,可以根据己知数据源分辨率来计算瓦片在金字塔中的所在层数。如果原数据的分辨率与金字塔中数据的分辨率存在差别,则应先对原始影像进行重采样处理,再对其进行瓦片矩阵划分。
对切割好的瓦片,构建线性四叉树索引机制进行检索,以便实现地图的快速检索,提供快速流畅的数据服务,例如,可以按照如下步骤构建索引机制:
首先,对金字塔模型中的所有瓦片进行编号处理,用tile_id来表示,从第0层按照从左到右,从下到上的顺序依次编号。(tx,ty,l)用来唯一标识某瓦片在金字塔模型中的位置,其中l为瓦片所在层数;
例如,给定的瓦片(tx,ty,l),使用对角线的描述方式,则其左下角的像素坐标(pix1,piy2)由下式计算出:
pix1=tx*height(7),
piy2=ty*width(8);
对应右上角的像素坐标为(pix3,piy4)由下式计算出:
pix3=(tx+1)*height+(over_size-1)(9),
piy4=(ty+1)*width+(over_size-1)(10);
而对于给定的像素坐标(pix,piy),其所在的瓦片坐标由以下公式计算出:
tx=pix/height(11),
ty=piy/width(12)。
上述金字塔模型中的瓦片拓扑关系主要体现在以下两个方面:
1)同一层间瓦片间为兄弟关系;
2)上下层瓦片之间为父与子关系。
具体的,兄弟关系分别为东、西、南、北四个相互邻接的瓦片。父与子关系,对于父而言,与下层四个孩子的关系为西北、西南、东北、东南四个孩子瓦片。
因此,假设选定的瓦片唯一标识码为(tx,ty,l),由上面所述瓦片的拓扑关系可计算得到其东、西、南、北四个邻接兄弟瓦片的坐标,分别为:(tx+1,ty,l)、(tx-1,ty,l)、(tx,ty-1,l)、(tx,ty+1,l),其四个孩子瓦片西南、东南、西北、东北的坐标分别为:(2*tx,2*ty,l-1)、(2*tx+1,2*ty,l-1)、(2*tx,2*ty+1,l-1)、(2*tx+1,2*ty+1,l-1),其父类瓦片的坐标为:(tx/2,ty/2,l+1)。
本发明的一个实施例中,数据查询模块包括下列组件中的任一个或任几个:
解析模块,用于自定义查询模型的解析,查询模型可以是基于json语法结构,较佳的,可指定查询的数据存储、持久化位置、缓存时间;
查询缓存模块,用于模型查询结果缓存,较佳的,在一定时间内多次查询同一结果时,只会进行一次计算;
查询适配器模块,用于将模型查询语句指向对应的数据存储。例如可以作为不同数据存储的查询适配器,可以将同样的模型查询语句指向不同的数据存储,并进行计算返回结果。
本发明的一个实施例中,数据查询服务支撑模块包括下列组件中的任一个或任几个:
安全性/完整性模块,用于为数据存储的安全性和完整性提供保障,例如:所有数据在系统都会存储多份且每份都会进行完整性校验;
高可用/健壮性模块,用于为组件服务的高可用提供支持,各服务组件都以集群的方式运行,当其中一个组件服务停止时,系统会将运行在当前服务上的任务无缝的转移到其它组件服务上。
本发明的一个实施例中,数据分析模块包括索引元数据模块,用于存储时间和空间数据的索引元数据。
其中,索引元数据模块包括下列组件中的任一个或任几个:
时空索引模块,用于时空索引元数据存储;
聚合索引模块,用于聚合索引元数据存储;
自定义索引模块,用于自定义索引元数据存储。
本发明的一个实施例中,基础服务支持模块包括基础服务管理模块,用于实现整个平台的管理,例如:集群服务管理、状态监控、安装部署等。
上述任一实施例的基于时间和空间数据模型的时空数据处理平台,较佳的,还包括时空数据查询引擎,作为统一的时空数据出口。
其中,所述时空数据查询引擎是构建在spark并行处理框架基础上的数据分析与处理系统。
其中,所述时空数据查询引擎具有下列组件中的任一个或任几个:
api网关,用于实现restapi服务的统一管理、认证、路由;
api及数据权限管理模块,用于实现restapi服务权限管理和控制;
数据缓存服务模块,用于模型查询结果的缓存;
dql查询解析引擎,用于实现自定义查询模型的语法解析;
数据分析服务模块,用于实现时空数据地理代数分析、叠加分析、预测等;
时间数据模型管理模块,用于提供查询模型的基础管理功能;
并行任务处理框架模块,用于任务处理框架模块,用于为数据处理的并行计算过程提供服务支撑;
restapi模块,用于为平台所有数据分析、存储、控制和管理提供标准的restapi服务。
其中,dql查询解析引擎具有下列组件中的任一个或任几个:
解析器,用于解析模型语言,转化为时空数据存储的查询语言;
查询模块,以并行或串行的方式查询;
查询结果缓存模块,通过层次组合将首次查询结果缓存;
结果预报模块,用于为机器学习、ai智能分析、结果预测提供基础服务支撑,优先预报时效组合;
聚合输出模块,将查询数据聚合并输出。
上述任一实施例的基于时间和空间数据模型的时空数据处理平台,较佳的,还包括访问控制模块,用于对数据进行权限访问控制和管理。
其中,访问控制模块包括数据访问监视器,用于对任务数据的进出进行监视并做记录,以便做到数据来去可控。
其中,数据访问监视器是从数据访问主体、客体,以及为识别和验证这些实体的子系统和控制实体间访问来建立的。
上述任一实施例的基于时间和空间数据模型的时空数据处理平台,较佳的,还包括对关键数据存储进行加密的关键数据存储加密模块。其不对全量数据进行加密,而只对部分关键数据进行加密,即使数据泄漏也必须使用特定算法进行解密才可以查看,借以在保证数据安全的前提下,提高数据加载的效率。
上述任一实施例的基于时间和空间数据模型的时空数据处理平台,较佳的,还包括对数据文件进行分布式存储和批量还原的存储异形模块,借此,将时空数据处理平台里面的数据文件通过分布式文件系统进行存储,使其只具有极低的可还原特性,即便单一服务器单一文件泄漏时,也需要通过集群统一文件批量才能进行还原,借以提高数据存储的安全性。
一种基于时间和空间数据模型的时空数据处理方法,其对时间和多维空间数据联合建立数据模型,实现多维空间要素随时间的变化。
借助上述方案,本发明的基于时间和空间数据模型的时空数据处理方法,其通过对时间与多维空间联合建立数据模型,能够实现多维空间要素随时间的变化,可以将地理事物和现象的时间、空间和属性特征有机结合,可以丰富地理事物和现象作为表达内容,同时支持时空数据快速分析、写入、持久化、多纬度聚合查询。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其包括如下步骤:
s1、利用数据装载模块对时间数据和多维空间数据进行统一装载;
s2、对时间数据和多维空间数据进行统一的索引与存储,建立时空数据库;
s3、根据请求对时空数据库进行查询分析,据此得到时间与多维空间属性特征相结合的结果。
借此,可以进行统一数据装载,支持时空数据的快速写入,有利于降低数据分析处理的难度,提高整体处理速度,解决大规模时空数据分析的效率问题,可以进行统一数据索引,支持多维度聚合查询。
具体实施时,步骤s1中,数据装载可以是通过api编程模型编写新的和/或重用现有的通用java代码实现的。借此,现有的演示和可重用的算子能够促进应用程序快速开发。
较佳的,api编程模型支持原生的hadoop,原生的hadoop支持能够使时空数据处理平台快速的安装在现有的yarn集群中。
较佳的,api编程模型使得时空数据处理平台能够在hadoop集群上以线性的方式进行扩展。
较佳的,基于hdfs的后端检查点机制,能够保证无论是机器故障或处理流程发生失败时,都能够将应用状态保存,保证使其自动快速恢复。
具体的,数据装载模块包括下列组件中的任一个或任几个:
tjsjmangement组件(即并行处理管理组件),用于供应用管理员进行管理、监控和可视化操作,借此,应用管理员可以从并行处理管理组件完成一整套的管理、监控和可视化操作;
tjsjassemble程序组件(即装配程序组件),用于供用户直观地构建各种数据接入组件,借此,应用管理员可以通过装配程序组件,来直观的构建各种数据接入组件;
时间一致性组件,用于保证时空数据库中相应数据的时间一致性;
空间一致性组件,用于保证时空数据库中相应数据的空间一致性。
实施时,步骤s2中,对时空数据的索引与存储可以是基于瓦片金字塔技术进行的。借此,便于管理和存储海量时空数据,可以根据实际输入请求查找部分数据瓦片,而不需要加载完整数据,减少服务器端的响应时间,加快响应速度。
其中,时空数据包括影像数据。
具体实施时,步骤s2包括步骤s21、建模和步骤s22、发布。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其中,步骤s21建立的金字塔模型中的瓦片拓扑关系包括:同一层间瓦片间为兄弟关系,上下层瓦片间为父与子关系。例如,兄弟瓦片包括东西南北四个相互邻接的瓦片,在父瓦片的下层具有西北、西南、东北、东南四个孩子瓦片。
其中,瓦片具有唯一的标识码(tx,ty,l),可以唯一标识某瓦片在金字塔模型中的位置,其中l为瓦片所在层数。
进一步的,其东西南北四个兄弟瓦片的相对标识码则分别为(tx+1,ty,l)、(tx-1,ty,l)、(tx,ty-1,l)、(tx,ty+1,l),其下层的西南、东南、西北、东北四个孩子瓦片的相对标识码则分别为:(2×tx,2×ty,l-1)、(2×tx+1,2×ty,l-1)、(2×tx,2×ty+1,l-1)、(2×tx+1,2×ty+1,l-1),其父瓦片的相对标识码则为:(tx/2,ty/2,l+1)。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其中,步骤s21的具体步骤包括:
s211、根据实际数据提供给数据分析服务平台所需的数据的缩放级别数,建立网格坐标系,同时设置数据比例尺最大,缩放级别最低的数据层级位于金字塔的底层,并将其定义为第0层,按照从左到右、从下到上的规则进行切片;
s212、将该0层数据瓦片的左上角开始进行切割分块,分割成大小相同的正方形数据瓦片,用(tile)表示,从而得到第0层的瓦片矩阵;
s213、在第0层数据瓦片的基础上再次按照分块原则,对第一层数据同样建立网格坐标系,以同样的方法进行切割,同时将该层每2×2像素合成为一个像素,形成第1层数据瓦片,并对该层数据进行分块切割,得到与第0层相同大小的正方形数据瓦片,形成第1层瓦片矩阵;
依此循环,应用类似的方法生成第二层瓦片矩阵、第三层矩阵、直到第n-1层矩阵。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,瓦片金字塔建模过程中,相应参数的计算可以按照如下公式进行:
假设第0层分辨率为res0,l为金字塔的层数,则第l层的分辨率由式(1)计算得出:
resl=res0×2l式(1);
设第l层的分辨率用resl表示,第l层像素矩阵大小用rowl×coll表示,正方形瓦片大小用height×width表示,相邻层数的重叠度用over_size表示,则瓦片矩阵的行列(trowl×tcoll)由式(2)、式(3)计算:
trowl=(rowl-over_size)/height式(2),
tcoll=(coll-over_size)/width式(3);
按照2×2像素将瓦片合成,形成第l+1层时,第l+1层的像素矩阵行列pirow(l+1)×picol(l+1)的大小和分辨率由式(4)、式(5)、式(6)计算:
pirow(l+1)=pirowl/2式(4),
icol(l+1)=picoll/2式(5),
res(l+1)=resl/2式(6)。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其步骤s21中,还包括下列步骤中的一个或几个:
步骤s214、根据已知数据源分辨率计算瓦片在金字塔中所在的层数;
步骤s216、进行瓦片矩阵划分前,先对原始影像进行重采样处理。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其中,步骤s216之前还包括步骤s215、原数据的分辨率与金字塔中数据的分辨率存在差别,如果判断结果为是,则执行步骤s216。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其步骤s22中包括步骤:
s221、构建线性四叉树索引机制;
s222、基于性四叉树索引机制进行检索。
借此,可以对切割好的瓦片,实现地图的快速检索,提供快速流程的数据服务。
其中,步骤s221中包括:计算给定瓦片在金字塔模型中的位置。
较佳的,使用对角线的描述方式。
具体的,步骤s221中包括:
步骤s2211、按照式(7)、式(8)计算给定瓦片左上角的像素坐标(pix1,piy2):
pix1=tx*height式(7),
piy2=ty*width式(8);
步骤s2212、按照式(9)、式(10)计算给定瓦片右上角的像素坐标(pix3,piy4):
pix3=(tx+1)*height+(over_size-1)式(9),
piy4=(ty+1)*width+(over_size-1)式(10)。
步骤s2213、依据像素坐标(pix,piy),按照式(11)、式(12)计算瓦片的坐标:
tx=pix/height式(11),
ty=piy/width式(12)。
借助上述方案,本发明可以根据实际需要对矢量-栅格数据使用瓦片金字塔模型发布瓦片服务,以适应高时间、高空间、多源、动态、多维数据查询的需要,为地理时空数据及其属性数据的发布、存储、共享、查询等提供了高效率的解决方法。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其步骤s3中,是以时空数据查询引擎作为统一的时空数据出口的。
较佳的,所述时空数据查询引擎是构建在spark并行处理框架基础上的数据分析与处理系统。
其中,所述时空数据查询引擎具有:
api网关,用于实现restapi服务的统一管理、认证、路由;
api即数据权限管理模块,用于实现restapi服务权限管理和控制;
数据缓存服务模块,用于模型查询结果的缓存;
dql查询解析引擎,用于实现自定义查询模型的语法解析;
数据分析服务模块,用于实现时空数据地理代数分析、叠加分析、预测等;
时间数据模型管理模块,用于提供查询模型的基础管理功能;
并行任务处理框架模块,用于任务处理框架模块,用于为数据处理的并行计算过程提供服务支撑;
restapi模块,用于为平台所有数据分析、存储、控制和管理提供标准的restapi服务。
其中,dql查询解析引擎具有:
解析器,用于解析模型语言,转化为时空数据存储的查询语言;
查询模块,以并行或串行的方式查询;
查询结果缓存模块,通过层次组合将首次查询结果缓存;
结果预报模块,用于为机器学习、ai智能分析、结果预测提供基础服务支撑,较佳的,优先预报时效组合。
聚合输出模块,将查询数据聚合并输出。
借此,可以实现水平组合漫游完整的格点数;
并行任务拆分可以显著提升io性能,多区域拼接难度加大;
通过层次组合将首次查询结果缓存,极大的提高垂直查询速度,减少单次操作的数据压力和网络压力;
时空组合极大的提高数据获取速度;
优先考虑预报时效组合,以达到高速按范围获取的目标;
层次索引只拆分不组合,按照拆分的索引模式,可以达到降低网络传输量,节省浏览器端压力的效果;
将数据按时间/空间进行索引,对气象数据进行合理建模,优化了查询检索性能;
还可提交周期型的后台任务,依据算法模型的配置,定时计算并输出结果。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其还包括:
步骤s4、利用数据访问监视器对任务数据的进出进行监视并做记录,以便做到数据来去可控。
其中,数据访问监视器是从数据访问主体、客体,以及为识别和验证这些实体的子系统和控制实体间访问来建立的。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其还包括:
步骤s5、对关键数据存储进行加密。
借此,由于其对部分关键数据进行了加密,即使数据泄漏也必须使用特定算法进行解密才可以查看,同时,由于不对全量数据进行加密,因此可以在保证数据安全的前提下,提高数据加载的效率。
本发明一个实施例的基于时间和空间数据模型的时空数据处理方法,其还包括:
步骤s6、通过分布式文件系统进行存储,再通过集群统一文件批量进行还原。
借此,将时空数据处理平台里面的数据文件通过分布式文件系统进行存储,使其只具有极低的可还原特性,即便单一服务器单一文件泄漏时,也需要通过集群统一文件批量才能进行还原,借以提高数据存储的安全性。
附图说明
图1为本发明一个实施例的基于时间和空间数据模型的时空数据处理平台的逻辑架构示意图;
图2为本发明一个实施例的基于时间和空间数据模型的时空数据处理平台中的时空数据查询引擎的逻辑架构示意图;
图3为本发明一个实施例的基于时间和空间数据模型的时空数据处理方法的整体流程示意图;
图4为本发明一个实施例的基于时间和空间数据模型的时空数据处理方法中的事件流转过程示意图;
图5为本发明一个实施例的基于时间和空间数据模型的时空数据处理方法中的瓦片金字塔建立流程示意图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
本发明一个实施例的基于时间和空间数据模型的时空数据处理平台,其总体设计是:建立一个分布式时空数据库,通过对时间与空间联合建立数据模型,实现空间要素随时间的变化,将地理事物和现象的时间、空间和属性特征有机结合,是集时间和空间地理信息数据采集、处理、存储、展现于一体的时空数据库。
本发明一个实施例的基于时间和空间数据模型的时空数据处理平台,其主要包括以下几部分:统一数据装载、统一数据索引与存储、数据查询分析服务及基础服务支持模块,其逻辑架构如图1所示。
本发明一个实施例的基于时间和空间数据模型的时空数据处理平台,其统一数据装载。
具体的:
其时空数据库数据接入组件是一个api编程模型,能够使开发者编写新的或重用现有的通用java代码,降低编写大数据应用所需的专业知识要求。现有的演示和可重用的算子能够促进应用程序快速开发。原生的hadoop支持能够使并行数据处理平台快速的安装在现有yarn集群中,应用管理员可以从tjsjmangement完成一整套的管理、监控和可视化操作,可以通过tjsjassemble这个程序组件装配工具,来直观的构建各种数据接入组件。
该平台能够每秒处理数十亿事件,当结点失败时,能够自动恢复,而无任何状态和数据的丢失。该平台能够在hadoop集群上以线性的方式进行扩展,达到每秒处理数十亿的事件。基于hdfs(hdfs是hadoopdistributefilesystem的简称,也就是hadoop的一个分布式文件系统。)作为后端的检查点机制,能够保证无论是机器故障或处理流程发生失败时,都能够将应用状态保存,保证使其自动快速恢复,其高可用的事件流转过程如图4所示。
本发明一个实施例的基于时间和空间数据模型的时空数据处理平台,其时空数据索引与数据存储是基于瓦片金字塔技术进行的。
瓦片金字塔技术是管理和存储海量时空数据的一种模式,仅会根据当前的实际输入请求查找部分数据瓦片,不需要加载完整数据,加速服务器端的响应速度。
根据实际需要可以对任何矢量-栅格数据使用瓦片金字塔模型发布瓦片服务,这也更加对高时间、高空间、多源、动态、多维数据查询的需要,为地理时空数据及其属性数据的发布、存储、共享、查询等提供了高效率的解决方法,因此,在天机时空数据处理平台中瓦片金字塔建模及发布技术是一项关键技术。
下面对瓦片数据索引建立的详细过程进行说明:
根据实际数据提供给数据分析服务平台所需的数据的缩放级别数,建立网格坐标系,同时设置数据比例尺最大,缩放级别最低的数据层级位于金字塔的底层,并将其定义为第0层,按照从左到右、从下到上的规则进行切片
将该0层数据瓦片的左上角开始进行切割分块,分割成大小相同的正方形数据瓦片,用(tile)表示,从而得到第0层的瓦片矩阵
在第0层数据瓦片的基础上再次按照分块原则,对第一层数据同样建立网格坐标系,以同样的方法进行切割,同时将该层每2*2像素合成为一个像素,形成第1层数据瓦片,并对该层数据进行分块切割,得到与第0层相同大小的正方形数据瓦片,形成第1层瓦片矩阵;
依此循环,应用类似的方法生成第二层瓦片矩阵、第三层矩阵、直到第n-1层矩阵,影像数据就可以采用瓦片金字塔服务模型的结构存储管理。
其建立过程如图5所示,具体的过程为:
确定已知条件,计算相应参数
假设第0层分辨率为res0,l为金字塔的层数,则第l层的分辨率由下面公式计算得出:
resl=res0*2l(1)
设第l层的分辨率用resl表示,第l层像素矩阵大小用rowl*coll表示,正方形瓦片大小用height*width表示,相邻层数的重叠度用over_size表示,则瓦片矩阵的行列(trowl*tcoll)由下列式子计算:
trowl=(rowl-over_size)/height(2)
tcoll=(coll-over_size)/width(3)
按照2*2像素将瓦片合成,形成第l+1层时,第l+1层的像素矩阵行列pirow(l+1)*picol(l+1)的大小和分辨率由下面公式计算:
pirow(l+1)=pirowl/2(4)
picol(l+1)=picoll/2(5)
res(l+1)=resl/2(6)
在实际应用中,可以根据己知数据源分辨率来计算瓦片在金字塔中的所在层数。如果原数据的分辨率与金字塔中数据的分辨率存在差别,则应先对原始影像进行重采样处理,再对其进行瓦片矩阵划分。
可以按如下方式构建瓦片索引机制,以便对切割好的瓦片,实现地图的快速检索,提供快速流畅的数据服务,构建适宜的索引机制,这里选择构建线性四叉树索引机制进行说明:
首先,对金字塔模型中的所有瓦片进行编号处理,用tile_id来表示,从第0层按照从左到右,从下到上的顺序依次编号。(tx,ty,l)用来唯一标识某瓦片在金字塔模型中的位置,其中l为瓦片所在层数。
例如,给定的瓦片(tx,ty,l),使用对角线的描述方式,则其左下角的像素坐标(pix1,piy2)由下式计算出:
pix1=tx*height(7)
piy2=ty*width(8)
对应右上角的像素坐标为(pix3,piy4)由下式计算出:
pix3=(tx+1)*height+(over_size-1)(9)
piy4=(ty+1)*width+(over_size-1)(10)
而对于给定的像素坐标(pix,piy),其所在的瓦片坐标由以下公式计算出:
tx=pix/height(11)
ty=piy/width(12)
上述金字塔模型中的瓦片拓扑关系主要体现在以下两个方面:
1)同一层间瓦片间为兄弟关系;
2)上下层瓦片之间为父与子关系。兄弟关系分别为东、西、南、北四个相互邻接的瓦片。父与子关系,对于父而言,与下层四个孩子的关系为西北、西南、东北、东南四个孩子瓦片。
因此,假设选定的瓦片唯一标识码为(tx,ty,l),由上面所述瓦片的拓扑关系可计算得到东、西、南、北四个邻接兄弟瓦片的坐标,分别为:(tx+1,ty,l)、(tx-1,ty,l)、(tx,ty-1,l)、(tx,ty+1,l),四个孩子瓦片西南、东南、西北、东北的坐标分别为:(2*tx,2*ty,l-1)、(2*tx+1,2*ty,l-1)、(2*tx,2*ty+1,l-1)、(2*tx+1,2*ty+1,l-1),父类瓦片的坐标为:(tx/2,ty/2,l+1)。
本发明一个实施例的基于时间和空间数据模型的时空数据处理平台,其对时空数据的查询与分析可以按照如下方式进行。
将时空数据查询引擎作为时空数据库的统一出口,它可以是构建在spark并行处理框架基础之上的数据分析与处理系统,包括:api网关、查询服务安全、缓存服务、模型分析、任务调度与处理、并行任务处理、统一数据服务等,其逻辑架构如图2所示。
该时空数据查询引擎的数据加载过程可以是:查询引擎通过解析器,解析模型语言,转化为时空数据存储的查询语言,以并行或串行的方式查询、聚合数据并输出,其具有以下特点:
水平组合漫游完整的格点数;
并行任务拆分可以显著提升io性能,多区域拼接难度加大;
通过层次组合将首次查询结果缓存,极大的提高垂直查询速度,减少单次操作的数据压力和网络压力;
时空组合极大的提高数据获取速度;
优先考虑预报时效组合,以达到高速按范围获取的目标;
层次索引只拆分不组合,按照拆分的索引模式,以达到降低网络传输量,节省浏览器端压力;
将数据按时间/空间进行索引,对气象数据进行合理建模,优化查询检索性能;
可提交周期型的后台任务,依据算法模型的配置,定时计算并输出结果。
本发明一个实施例的基于时间和空间数据模型的时空数据处理平台,其还提供数据服务支撑与安全保障,具体如下:
例如可以进行访问控制。
访问监视模型是从数据访问主体、客体,以及为识别和验证这些实体的子系统和控制实体间访问的建立数据访问监视器,任务数据的进入出都会通监视器进行监视并做记录,做到数据来去可控。
例如可以进行存储异型。
平台里面的都是通分布式文件系统进行存储,单一服务器单一文件泄漏时,具有极低的可还原特性,需要通过集群统一文件批量才能进行还原。
例如可以进行数据加密。
关键数据存储进行加密,为了提高数据加载的效率,平台不会将全量数据进行加密,只会部分关键数据进行加密,即使数据泄漏也必须使用特定算法进行解密才可以查看。
综上所述,本发明通过对时间与空间数据联合建立数据模型,实现了空间要素随时间的变化,将地理事物和现象的时间、空间及属性特征有机结合,以丰富地理事物和现象作为表达内容,同时支持时空数据快速分析、写入、持久化、多纬度聚合查询。
- 还没有人留言评论。精彩留言会获得点赞!