基于深度卷积神经网络模型的SAR图像目标形状生成方法与流程
本发明涉及图像处理领域,更具体的涉及一种基于深度卷积神经网络模型(dcnn)的合成孔径雷达(sar)图像目标形状生成方法。
背景技术:
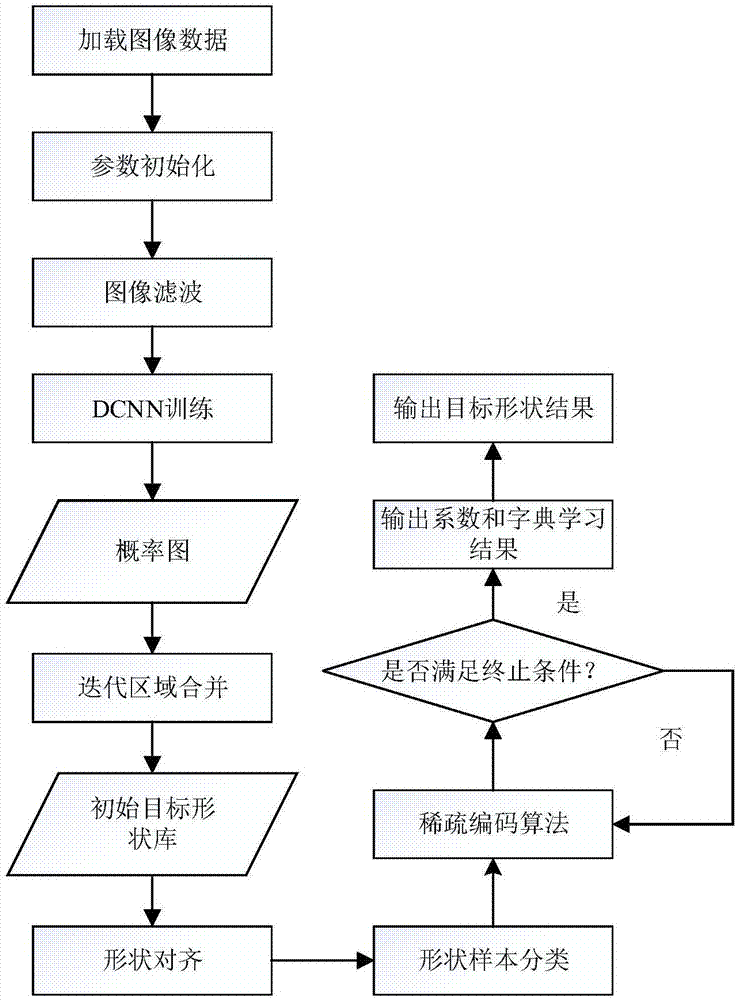
:图像分类是图像解译的基础,是实现系统自动目标识别的必要技术手段,同时图像分类技术也是信息技术众多领域的核心技术之一。sar图像分类即是通过研究目标散射回波来提取目标特征,分析目标特征,对不同的类别目标加以区分。目标形状的生成是sar图像分割的重要研究内容,在后续的图像分析、处理及识别中占有重要地位。由于sar图像中的乘性相干斑噪声和目标强度的非同质性变化等内在性特点,即使采用较优秀的目标形状建模方案,也仍然面临多种挑战,例如,目标形状的生成对初始位置较为敏感,在目标异质性变化区域难以生成理想的形状;基于形状先验方法的目标形状建模方案使用单一形状模板或基于固定参数的形状仿射变换,表示能力不强,对目标形状的大幅度变形不具鲁棒性。因此,设计有效的目标形状生成方案来适应sar图像典型目标强度表征变化的复杂性,显得极为迫切。综上所述,本发明提出了一个基于深度卷积神经网络模型和稀疏表示的sar图像目标形状生成方法,有效地解决了sar图像目标形状的生成问题。技术实现要素:本发明目的是为了克服sar图像中的乘性相干斑噪声和目标强度的非同质性变化等内在性特点,以提高sar图像目标形状生成的准确性,提出了一种基于深度卷积神经网络模型的sar图像目标形状生成方法。本发明的主要思路是首先设计深度卷积神经网络算法,并制定迭代区域合并算法,以获取目标形状初始化机制,然后设计基于稀疏表示的目标形状生成算法,以获取更加精确的目标形状生成结果。本发明是通过以下技术方案来实现的,基于深度卷积神经网络模型的sar图像目标形状生成方法,包括以下具体步骤:步骤1,加载图像数据。步骤2,参数初始化,设置以下参数的数值:时间步长timestep、最大迭代次数iter、滤波算子窗口大小w、批次大小batch_size、基本学习率lr。步骤3,对图像进行二维高斯卷积操作,再进行平滑处理。步骤4,将图像灰度值归一化到[0,255]范围内。步骤5,通过深度学习的思想进行目标形状的初始化。步骤6,设计迭代区域合并算法。步骤7,应用procrustes分析方法对初始目标形状结果进行排列对齐。步骤8,利用k-means算法对已对齐的样本数据进行分类,并设计基于稀疏表示的目标形状生成算法,得到稀疏编码模型。步骤9,基于步骤8得到的稀疏编码模型,使用omp(正交匹配追踪算法)得到目标形状结果s。进一步地,所述步骤5包括如下步骤:步骤5-1,设计深度卷积神经网络模型(deepconvolutionalneuralnetworks,dcnn);所述深度卷积神经网络由一系列成对的卷积层(convolutionallayer)、最大池层(maxpoolinglayer)和几个充分连接层(fully-connectedlayer)组成。卷积池层用于学习局域多层特征,最大池层获取每个特征图中相邻区域的最大值,充分连接层学习更高阶特征表示,最后一层输出类别的概率分布。步骤5-2,本发明中使用的dcnn结构主要由两个卷积层、两个最大池化层以及两个全连接层组成。输入图像块的大小为55×55。第1个卷积层的卷积核大小为6×6,卷积核滑动步长为1,卷积后得到图像尺寸为50×50。第1个最大池化层的池化窗大小为2×2,池化窗滑动步长为2,池化后得到图像尺寸为25×25。第2个卷积层的卷积核大小为4×4,卷积核滑动步长为1,卷积后得到图像尺寸为22×22。第2个最大池化层的池化窗大小为2×2,池化窗滑动步长为2,池化后得到图像尺寸为11×11。第2个最大池化层后跟着两个全连接层,两个全连接层的维度都为1024。最后为输出层,即softmax层。步骤5-3,dcnn训练过程:选取具有特定尺寸的目标图像块的原始像素值作为训练对象,图像块中心为像素本身,并对目标区域的几何中心进行标注;图像块的概率值的正负取决于标注区域与图像块之间的中心值距离(表示为dt),假设阈值为dt0,如果dt<dt0,概率值取正,否则取负;考虑旋转不变性的要求,对所有的正概率图像块,按照45度均值,进行共8个角度的旋转,得到的结果构成概率图p。进一步地,所述步骤6包括如下步骤:步骤6-1,基于生成的概率图p,首先计算距离图dt,其中每个像素对应一个值,该值用来衡量距离背景的最短距离。步骤6-2,基于距离图dt,应用h-minima变换求目标最小值,其基本原理如下:通过与设定的阈值h进行比较,消除低于阈值h的局部极小值,以消除部分噪声对图像的影响。对于概率图p上的每个连接区域,基于不同的距离值,采用迭代方式来扩展各个标记值,直至所有的标记合并融合。步骤6-3,在融合过程中,记录在下一次迭代过程中待融合的标记值。步骤6-4,应用简单的形态学运算平滑标记值,以有效地保存区域的形状,并作为初始目标形状结果。进一步地,所述步骤8包括如下步骤:步骤8-1,假设n个样本数据中有k个不同目标类别,构造字典集d=[d1,d2,...,dk],第i类样本数据对应的字典可以表示为di=[βi,1,...,βi,ni],其中ni表示第i类样本数据的个数;根据稀疏表示理论,基于稀疏度的形状建模的目标即是获取一个紧形状字典(d)和一个稀疏系数任何已对齐的形状(s)都可以用一些基元来表示:(ε表示残差)。步骤8-2,在设计的稀疏模型中,通过最小化局域约束的综合平方差(integratedsquarederror)来建模。基于稀疏重构准则,稀疏编码目标函数可以表示为:式中,第一项构成l2e标准,对极端值具鲁棒性。第二项用来约束使用加权稀疏编码的基元的局域表征,这项约束通过使用具有相似度保持性的邻域字典基元,从而确保每个目标均得到充分表征。式中的约束用来保证平移不变性,λ是正则项参数。步骤8-3,随机选取一组目标形状构成字典基元d。步骤8-4,采用基于映射的梯度下降法来获取最小化以更新字典基元d。步骤8-5,固定字典,使用局域约束的线性编码算法(locality-constrainedlinearcoding)来求解系数其中,邻域基元被定义为形状和字典基元之间的欧式距离。步骤8-6,计算每次迭代前后的重构误差和综合平方差值。步骤8-7,返回步骤8-3,直至重构误差和综合平方差值在字典基元再次更新之前达到最小,输出系数和字典学习结果d。附图说明图1为本发明的实现流程图。具体实施方式下面结合附图对本发明实施例作详细说明。本发明是通过以下技术方案来实现的,具体流程图参见图1。基于深度卷积神经网络模型的sar图像目标形状生成方法,包括以下具体步骤:步骤1,加载图像数据。步骤2,参数初始化,设置以下参数的数值:时间步长timestep、最大迭代次数iter。本发明中timestep设置为0.1,iter设置为400,批次大小batch_size设置为50,基本学习率lr设置为0.01。设置滤波算子窗口大小w,本发明中滤波算子设置为二维高斯滤波算子,窗口大小设置为17。步骤3,对图像进行二维高斯卷积操作,再进行平滑处理。步骤4,将图像灰度值归一化到[0,255]范围内。步骤5,通过深度学习的思想进行目标形状的初始化。步骤5-1,设计深度卷积神经网络模型(deepconvolutionalneuralnetworks,dcnn)。该神经网络由一系列成对的卷积层(convolutionallayer)、最大池层(maxpoolinglayer)和几个充分连接层(fully-connectedlayer)组成。卷积池层用于学习局域多层特征,最大池层获取每个特征图中相邻区域的最大值,充分连接层学习更高阶特征表示,最后一层输出类别的概率分布。步骤5-2,本发明中使用的dcnn结构如表1所示。表1本发明中使用的dcnn结构层数层名称输出图像尺寸滤波器尺寸1输入层55×55-2卷积层50×506×63最大池化层25×252×24卷积层22×224×45最大池化层11×112×26全连接层1024×1-7全连接层1024×1-8输出层2×1-步骤5-3,dcnn训练过程。选取具有特定尺寸(本发明选取的图像块为原始图像的0.8倍)的目标图像块的原始像素值作为训练对象,图像块中心为像素本身,并以手动方式对目标区域的几何中心进行标注。图像块的概率值的正负取决于标注区域与图像块之间的中心值距离(表示为dt),假设阈值为dt0,如果dt<dt0(本发明中dt0取值为30),概率值取正,否则取负。考虑旋转不变性的要求,对所有的正概率图像块进行多个角度的旋转,得到的结果构成概率图p。步骤6,设计迭代区域合并算法。步骤6-1,基于生成的概率图p,首先计算距离图dt,其中每个像素对应一个值,该值用来衡量距离背景的最短距离。步骤6-2,基于距离图的逆,应用h-minima变换求目标最小值,其基本原理如下:通过与设定的阈值h进行比较,消除低于阈值h的局部极小值,以消除部分噪声对图像的影响。对于概率图p上的每个连接区域,基于不同的距离值,采用迭代方式来扩展各个标记值,直至所有的标记合并融合。步骤6-3,在融合过程中,记录在下一次迭代过程中待融合的标记值。步骤6-4,应用简单的形态学运算平滑标记值,以有效地保存区域的形状,并作为初始形状结果。步骤7,应用procrustes分析方法对初始目标形状结果进行排列对齐。步骤8,利用k-means算法对已对齐的样本数据进行分类,并设计基于稀疏表示的目标形状生成算法以获取更加精确的目标形状结果。步骤8-1,假设n个样本数据中有k个不同目标类别,构造字典集d=[d1,d2,...,dk],第i类样本数据对应的字典可以表示为di=[βi,1,...,βi,ni],其中ni表示第i类样本数据的个数。根据稀疏表示理论,基于稀疏度的形状建模的目标即是获取一个紧形状字典(d)和一个稀疏系数任何已对齐的形状(s)都可以用一些基元来表示:(ε表示残差,本发明中ε取值为10-4)。步骤8-2,在设计的稀疏模型中,通过最小化局域约束的综合平方差(integratedsquarederror)来建模。基于稀疏重构准则,稀疏编码目标函数可以表示为:式中,第一项构成l2e标准,对极端值具鲁棒性。第二项用来约束使用加权稀疏编码的基元的局域表征,这项约束通过使用具有相似度保持性的邻域字典基元,从而确保每个目标均得到充分表征。式中的约束用来保证平移不变性,λ是正则项参数,本发明中λ取值为0.5。步骤8-3,随机选取一组目标形状构成字典基元d。步骤8-4,采用基于映射的梯度下降法来获取最小化以更新字典基元d。步骤8-5,固定字典,使用局域约束的线性编码算法(locality-constrainedlinearcoding)来求解系数其中,邻域基元被定义为形状和字典基元之间的欧式距离。步骤8-6,计算每次迭代前后的重构误差和综合平方差值。步骤8-7,返回步骤8-3,直至重构误差和综合平方差值在字典基元再次更新之前达到最小,输出系数和字典学习结果d。步骤9,根据和d,基于上述稀疏编码模型,使用omp(正交匹配追踪算法)得到目标形状结果s。以上对本发明的优选实施例及原理进行了详细说明,对本领域的普通技术人员而言,依据本发明提供的思想,在具体实施方式上会有改变之处,而这些改变也应视为本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1