提升SSD响应延迟的方法及装置与流程
本发明涉及到ssd读写领域,特别是涉及到一种提升ssd响应延迟的方法及装置。
背景技术
现有的ssd应用系统中,一般采用4kb映射。对于主机写入的数据,ssd内部切分成4kb单元的数据块并分配物理地址,并在内存中维护一张映射表,跟踪逻辑到物理的转换关系。
基于此因素,4kb对齐的用户数据必然落在唯一的物理块上。当主机访问此数据时,需要依次触发nand的读(tr),nand的数据传输(txfer)。
传统nand的读(tr)大约为50us,数据传输(txfer)大约8.8us,此情形下,系统响应延迟主要由tr决定。随着企业级应用的推广,某些nand的tr会很短,例如东芝的xlflash,其tr只有8us左右,故此时串行的传输方式将极大地影响读命令响应延迟。
技术实现要素:
为了解决上述现有技术的缺陷,本发明的目的是提供一种提升ssd响应延迟的方法及装置,用于降低ssd响应延迟,提高数据传输效率。
为达到上述目的,本发明的技术方案是:
提出一种提升ssd响应延迟的方法,包括以下步骤,
发起写入4kb数据请求;
将4kb数据切分成多个分片单元,并写入到不同的nanddie上;
更新分片单元对应的物理地址到映射表;
发起读取4kb数据请求;
根据映射表中的物理地址从对应的nanddie并发读取数据。
进一步地,所述根据映射表中的物理地址从对应的nanddie并发读取数据步骤,包括,
通过查找映射表,获取读取数据对应的物理地址;
发起读操作,直到内部读操作完成;
将各个分片单元的数据并发传输到读写缓冲区,返回主机。
进一步地,所述将4kb数据切分成多个分片单元,并写入到不同的nanddie上步骤,包括,
使用读写缓冲区存放4kb数据;
将4kb数据按照自定义大小进行切分成分片单元;
连续的扇区数据关联到同一分片单元中;
为每个分片单元分配物理地址,保证相邻的分片单元落在物理独立的nanddie上。
进一步地,所述将4kb数据按照自定义大小进行切分成分片单元步骤,包括,
根据使用场景选择分片单元的大小;
根据纠错单元选择分片单元的大小。
进一步地,所述分片单元的大小可以为512b、1024b或2048b。
本发明还公开了一种提升ssd响应延迟的装置,包括,
写入发起单元,用于发起写入4kb数据请求;
切分写入单元,用于将4kb数据切分成多个分片单元,并写入到不同的nanddie上;
地址更新单元,用于更新分片单元对应的物理地址到映射表;
读取发起单元,用于发起读取4kb数据请求;
并发读取单元,用于根据映射表中的物理地址从对应的nanddie并发读取数据。
进一步地,所述并发读取单元包括:
地址获取模块,用于通过查找映射表,获取读取数据对应的物理地址;
内部读取模块,用于发起读操作,直到内部读操作完成;
并发传输模块,用于将各个分片单元的数据并发传输到读写缓冲区,返回主机。
进一步地,所述切分写入单元包括:
存放模块,用于使用读写缓冲区存放4kb数据;
切分模块,用于将4kb数据按照自定义大小进行切分成分片单元;
关联模块,用于连续的扇区数据关联到同一分片单元中;
分配模块,用于为每个分片单元分配物理地址,保证相邻的分片单元落在物理独立的nanddie上。
进一步地,所述切分模块用于根据使用场景选择分片单元的大小,根据纠错单元选择分片单元的大小。
进一步地,所述分片单元的大小可以为512b、1024b或2048b。
本发明的有益效果是:采用可变的分片策略,将4kb数据切分成多份,并写入到不同nanddie上,在主机读取对应4kb数据时,从对应的nanddie并发传输数据,降低了数据传输时间,进而降低了ssd数据读取的命令响应延迟时间,提高数据传输效率。
附图说明
图1为本发明一种提升ssd响应延迟的方法的流程图;
图2为本发明一种4kb数据写入的方法流程图;
图3为本发明一种选择分片单元的大小的方法流程图;
图4为本发明一种并发读取分片单元的方法流程图;
图5为本发明一实施例一种提升ssd响应延迟的方法数据写入的原理图;
图6为本发明一实施例一种提升ssd响应延迟的方法数据读取的原理图;
图7为本发明一实施例响应延迟计算原理图;
图8为本发明一种提升ssd响应延迟的装置的结构框图;
图9为本发明一种并发读取单元的结构框图;
图10为本发明一种切分写入单元的结构框图。
具体实施方式
为阐述本发明的思想及目的,下面将结合附图和具体实施例对本发明做进一步的说明。
lpa:分片单元。
lba:扇区。
ppa:物理地址。
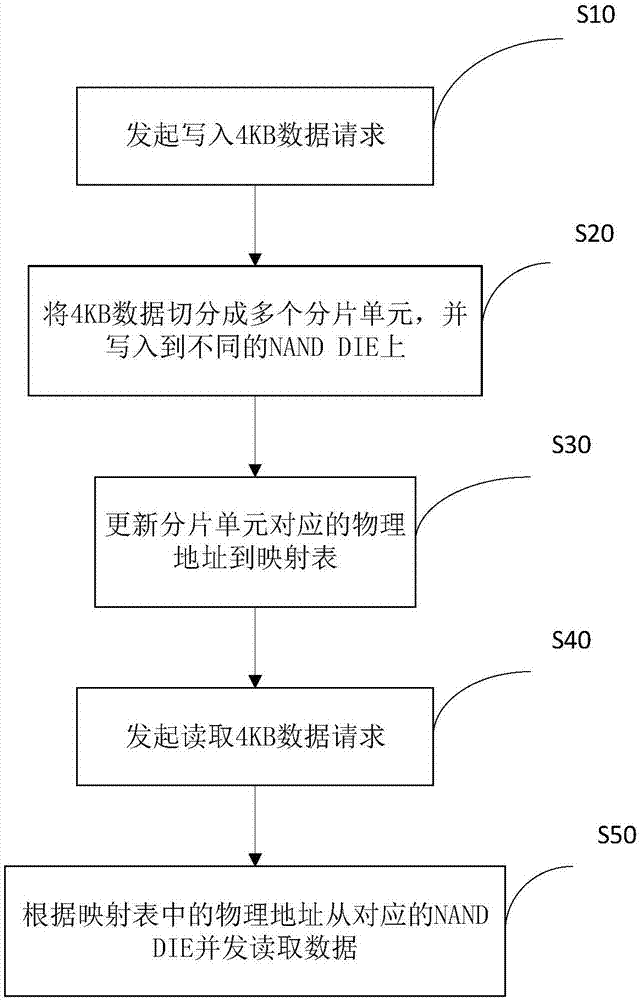
参照图1-图4,本发明一具体实施例提出一种提升ssd响应延迟的方法,具体包括以下步骤,
s10、发起写入4kb数据请求。
s20、将4kb数据切分成多个分片单元,并写入到不同的nanddie上。
s30、更新分片单元对应的物理地址到映射表。
s40、发起读取4kb数据请求。
s50、根据映射表中的物理地址从对应的nanddie并发读取数据。
对于步骤s10,数据写入ssd的过程为:主机提交写入4kb数据命令,调用对应的数据做写入准备,将准备写入的4kb数据先存放在缓冲区,后续根据分配好的物理地址,将4kb数据写入对应的nanddie中。
对于步骤s20,将4kb数据进行切分得到多份相同大小的分片单元,将不同的分片单元写入到不同的nanddie中,后续主机访问该4kb数据时,触发nand的读(tr),并发读取不同nanddie上的分片单元,减少4kb数据的整体读取时间。具体的,切分后的分片单元的大小可以为512b、1024b或2048b,同时分片单元的大小越小,最后传输(txfer)时间就越短,性能收益更高。例如,当分片单元的大小为2048b时,传输一完整4kb数据的时间为4.4us;当分片单元的大小为1024b时,传输一完整4kb数据的时间为2.2us;当分片单元的大小为512b时,传输一完整4kb数据的时间为1.1us,分片单元的大小越小,完成传输(txfer)的时间越短,数据传输整个过程的效率更高。
参考图2,步骤s20,包括以下步骤:
s21、使用读写缓冲区存放4kb数据。
s22、将4kb数据按照自定义大小进行切分成分片单元;。
s23、连续的扇区数据关联到同一分片单元中。
s24、为每个分片单元分配物理地址,保证相邻的分片单元落在物理独立的nanddie上。
对于步骤s21,在写入4kb数据时,先将4kb数据写入到读写缓冲区,在读写缓冲区完成后续的切分操作,将4kb数据按照需要进行切分成更小的分片单元。
对于步骤s22,根据需要将4kb数据进行均匀切分得到相同大小的分片单元,即得到的分片单元大小为4kb/n,其中n为大于0的自然数。将4kb数据进行切分得到多份相同大小的分片单元,并将不同的分片单元写入到不同的nanddie中,后续主机访问该4kb数据时,触发nand的读(tr),并发读取不同nanddie上的分片单元,减少4kb数据的整体读取时间。
具体的,切分后的分片单元的大小可以为512b、1024b或2048b,同时分片单元的大小越小,最后传输(txfer)时间就越短,性能收益更高。例如,当分片单元的大小为2048b时,传输一完整4kb数据的时间为4.4us;当分片单元的大小为1024b时,传输一完整4kb数据的时间为2.2us;当分片单元的大小为512b时,传输一完整4kb数据的时间为1.1us,分片单元的大小越小,完成传输(txfer的时间越短,数据传输整个过程的效率更高。
参考图3,步骤s22包括以下步骤:
s221、根据使用场景选择分片单元的大小。
s222、根据纠错单元选择分片单元的大小。
对于步骤s221,由于分片单元(lpa)变小,而需要为每个分片单元保存一个存放数据的物理地址,所以切分越小,dram要求越大,需要在收益和成本之间折衷,根据传输的数据大小,数据类型,以及数据的应用要求等具体化场景,选定分片单元的大小。
对于步骤s222,nand对于纠错能力有要求,例如1kb(纠错单元)纠200bits或者等效的纠错能力,如512b(纠错单元)纠112bits等.不同的控制器支持的最小纠错单元不一,对于所切分的分片单元必需是能够独立纠错的,所以切分后的分片单元大小必需是控制器最小纠错单元。举例说明,最小纠错单元为512b时,分片单元的大小只能为n*512b,n为大于0的自然数,具体的,不同的控制的最小纠错单元也可以为256b、128b或其他数值。
对于步骤s23,连续的扇区(lba)数据关联到同一分片单元中,可以保证扇区数据在读和写时作为一个完整的客体进行,保证数据的完整和安全。
对于步骤s24,为每个分片单元分配对应的物理地址,保证相邻的分片单元落在物理独立的nanddie上。这样后续主机访问该4kb数据时,触发nand的读(tr),通过并发传输不同nanddie上的分片单元,相当于同时只需要使用传输单个分片单元(大小4kb/n)的时间就可传输全部的4kb数据,减少4kb数据的整体传输时间,提高ssd数据传输效率。
对于步骤s30,完成写入后,将分片单元的物理地址更新到映射表,便于后续主机读取数据时,根据映射表找到对应的4kb数据(分片单元),进行数据读取。
对于步骤s40,数据读取流程,主机提交读取4kb数据命令,通过映射表查找对应4kb数据的物理地址,根据物理地址从对应的nanddie读取所需的4kb数据并存放在读写缓冲区,并返回主机。
对于步骤s50,现有的ssd应用系统中,一般采用4kb映射。对于主机写入的数据,ssd内部切分成4kb数据块并分配物理地址,并在内存中维护一张映射表,跟踪逻辑到物理的转换关系。基于此因素,4kb对齐的用户数据必然落在唯一的物理块上。当主机访问此数据时,需要依次触发nand的读(tr),nand的数据传输(txfer)。传统的nand的tr大约为50us,,txfer大约8.8us,此情形下,系统响应延迟主要由tr决定。随着企业级应用的推广,某些nand的tr会很短,例如东芝的xlflash,其tr只有8us左右,此时串行的传输方式将极大地影响读命令响应延迟。
而先将4kb数据切分成多个相同大小的分片单元再写入到不同的nanddie中,在读取4kb数据时根据映射表内的物理地址,并发读取不同nanddie中的分片单元,从而降低4kb数据的整体传输(txfer)的时间,提高了4kb数据传输的效率。
参照图4,步骤s50,包括:
s51、通过查找映射表,获取读取数据对应的物理地址。
s52、发起读操作,直到内部读操作完成。
s53、将各个分片单元的数据并发传输到读写缓冲区,返回主机。
对于步骤s51,在步骤s30中,更新分片单元对应的物理地址到映射表,在后续读取分片单元时,先根据映射表获取分片单元的物理地址,后续根据物理地址进行数据读取。
对于步骤s52,nand控制器发起nand读操作,并等待nand内部读(tr)操作完成,进而发起nand数据传输(txfer)。
对于步骤s53,将要读取的分片单元并发传输,并存放在读写缓冲区,后续返回给主机。存储在不同nanddie上的分片单元大小为4kb/n,其中n为大于0的自然数。并发读取4kb数据时,相当于只需要传输4kb数据本身1/n的大小的分片单元,能够有效的减少读取4kb数据的传输(txfer)时间,,降低ssd数据传输时间,进而降低了命令响应延迟。
本方案采用可变的分片策略,将4kb数据切分成多份,并写入到不同nanddie上,在主机读取对应4kb数据时,从对应的nanddie并发传输数据,降低了数据传输时间,进而降低了ssd数据读取的命令响应延迟时间,提高数据传输效率。
参考图5-7,为本发明一种提升ssd响应延迟的方法的具体应用实施例。
如图5所示,为数据写入的原理图。为便于说明,此处以4ch(对应4个独立的nanddie,ch0-ch4)进行说明;每个编程单元物理页的大小为8kb;切分后的分片单元大小以2kb举例。
a、先使用读写缓冲区存放主机写入的数据。
b、再将命令缓冲区的4kb数据按自定义大小进行切分成相同大小的分片模块。
c、连续的lba数据被关联到一个分片单元(lpa)中:如lba0-3对应lpa0,lba4-7对应lpa1。
d、为每个2kblpa分片单元分配物理地址,且保证相邻的lpa落在物理独立的die上。
e、更新物理地址映射表:lpa->ppa。
图示中的0/1/3/…为从属于同一命令的逻辑连续的分片单元在物理nand上的分布。
如图6所示,为数据读取的原理图。为便于说明,此处以4ch(对应4个独立的nanddie,ch0-ch4)进行说明;每个编程单元物理页的大小为8kb;切分后的分片单元大小以2kb举例。
f、主机读取lba0–7,通过数据写入流程可知,写入数据分别关联到lpa0/1。
g、通过查找映射表,找到对应的物理地址,具体为die0block0page0的第一个2kb以及die1block0page0的第一个2kb。
h、ssdnand控制器对ch0/1发起nand读操作,直到nand内部读完成(tr)。
i、完成nand内部读以后,由于分属于不同通道,并行进行各自2kb的数据传输(txfer)
j、完成数据传输(txfer)后,所要读取的数据已经存放到读写缓冲区中,可返回给主机。
如图7所示,在上述过程中,由于将4kb数据分配到物理独立的通道中,故而可以复用tr以及txfer时间。以上述为例,该4kb数据由于nand数据加载导致的延迟为:8us+8.8us/2=12.4us.相比传统的16.8us有很大的提升。分片单元的大小越小,由于nand数据加载导致的延迟就越少。由如上的规则可知,可进一步地调整分片单元大小,以便发起更多的通道并发度,从而降低传输时间。
参考图8-10,本发明还公开了一种提升ssd响应延迟的装置,包括,
写入发起单元10,用于发起写入4kb数据请求;
切分写入单元20,用于将4kb数据切分成多个分片单元,并写入到不同的nanddie上;
地址更新单元30,用于更新分片单元对应的物理地址到映射表;
读取发起单元40,用于发起读取4kb数据请求;
并发读取单元50,用于根据映射表中的物理地址从对应的nanddie并发读取数据。
对于写入发起单元10,数据写入ssd的过程为:主机提交写入4kb数据命令,调用对应的数据做写入准备,将准备写入的4kb数据先存放在缓冲区,后续根据分配好的物理地址,将4kb数据写入对应的nanddie中。
对于切分写入单元20,将4kb数据进行切分得到多份相同大小的分片单元,将不同的分片单元写入到不同的nanddie中,后续主机访问该4kb数据时,触发nand的读(tr),并发读取不同nanddie上的分片单元,减少4kb数据的整体读取时间。具体的,切分后的分片单元的大小可以为512b、1024b或2048b,同时分片单元的大小越小,最后传输(txfer)时间就越短,性能收益更高。例如,当分片单元的大小为2048b时,传输一完整4kb数据的时间为4.4us;当分片单元的大小为1024b时,传输一完整4kb数据的时间为2.2us;当分片单元的大小为512b时,传输一完整4kb数据的时间为1.1us,分片单元的大小越小,完成传输(txfer)的时间越短,数据传输整个过程的效率更高。
参考图9,切分写入单元20包括以下模块:
存放模块21,用于使用读写缓冲区存放4kb数据;
切分模块22,用于将4kb数据按照自定义大小进行切分成分片单元;
关联模块23,用于连续的扇区数据关联到同一分片单元中;
分配模块24,用于为每个分片单元分配物理地址,保证相邻的分片单元落在物理独立的nanddie上。
对于存放模块21,在写入4kb数据时,先将4kb数据写入到读写缓冲区,在读写缓冲区完成后续的切分操作,将4kb数据按照需要进行切分成更小的分片单元。
对于切分模块22,根据需要将4kb数据进行均匀切分得到相同大小的分片单元,即得到的分片单元大小为4kb/n,其中n为大于0的自然数。将4kb数据进行切分得到多份相同大小的分片单元,并将不同的分片单元写入到不同的nanddie中,后续主机访问该4kb数据时,触发nand的读(tr),并发读取不同nanddie上的分片单元,减少4kb数据的整体读取时间。
具体的,切分后的分片单元的大小可以为512b、1024b或2048b,同时分片单元的大小越小,最后传输(txfer)时间就越短,性能收益更高。例如,当分片单元的大小为2048b时,传输一完整4kb数据的时间为4.4us;当分片单元的大小为1024b时,传输一完整4kb数据的时间为2.2us;当分片单元的大小为512b时,传输一完整4kb数据的时间为1.1us,分片单元的大小越小,完成传输(txfer)的时间越短,数据传输整个过程的效率更高。
切分模块22用于根据使用场景选择分片单元的大小,根据纠错单元选择分片单元的大小。
由于分片单元(lpa)变小,而需要为每个分片单元保存一个存放数据的物理地址,所以切分越小,dram要求越大,需要在收益和成本之间折衷,根据传输的数据大小,数据类型,以及数据的应用要求等具体化场景,选定分片单元的大小。
nand对于纠错能力有要求,例如1kb(纠错单元)纠200bits或者等效的纠错能力,如512b(纠错单元)纠112bits等.不同的控制器支持的最小纠错单元不一,对于所切分的分片单元必需是能够独立纠错的,所以切分后的分片单元大小必需是控制器最小纠错单元。举例说明,最小纠错单元为512b时,分片单元的大小只能为n*512b,n为大于0的自然数,具体的,不同的控制的最小纠错单元也可以为256b、128b或其他数值。
对于关联模块23,连续的扇区(lba)数据关联到同一分片单元中,可以保证扇区数据在读和写时作为一个整体进行,保证数据的完整和安全。
对于分配模块24,为每个分片单元分配对应的物理地址,保证相邻的分片单元落在物理独立的nanddie上。这样后续主机访问该4kb数据时,触发nand的读(tr),通过并发传输不同nanddie上的分片单元,相当于同时只需要使用传输单个分片单元(大小4kb/n)的时间就可传输全部的4kb数据,减少4kb数据的整体传输时间,提高ssd数据传输效率。
对于地址更新单元30,完成写入后,将分片单元的物理地址更新到映射表,便于后续主机读取数据时,根据映射表找到对应的4kb数据(分片单元),进行数据读取。
对于读取发起单元40,数据读取流程,主机提交读取4kb数据命令,通过映射表查找对应4kb数据的物理地址,根据物流地址从对应的nanddie读取所需的4kb数据并存放在读写缓冲区,并返回主机。
对于并发读取单元50,现有的ssd应用系统中,一般采用4kb映射。对于主机写入的数据,ssd内部切分成4kb数据块并分配物理地址,并在内存中维护一张映射表,跟踪逻辑到物理的转换关系。基于此因素,4kb对齐的用户数据必然落在唯一的物理块上。当主机访问此数据时,需要依次触发nand的读(tr),nand的数据传输(txfer)。传统的nand的tr大约为50us,txfer大约8.8us,此情形下,系统响应延迟主要由tr决定。随着企业级应用的推广,某些nand的tr会很短,例如东芝的xlflash,其tr只有8us左右,此时串行的传输方式将极大地影响读命令响应延迟。
而先将4kb数据切分成多个相同大小的分片单元再写入到不同的nanddie中,在读取4kb数据时根据映射表内的物理地址,并发读取不同nanddie中的分片单元,从而降低4kb数据的整体传输(txfer)的时间,提高了4kb数据传输的效率。
参考图10,并发读取单元50包括:
地址获取模块51,用于通过查找映射表,获取读取数据对应的物理地址;
内部读取模块52,用于发起读操作,直到内部读操作完成;
并发传输模块53,用于将各个分片单元的数据并发传输到读写缓冲区,返回主机。
对于地址获取模块51,更新分片单元对应的物理地址到映射表,在后续读取分片单元时,先根据映射表获取分片单元的物理地址,后续根据物理地址进行数据读取。
对于内部读取模块52,nand控制器发起nand读操作,并等待nand内部读(tr)操作完成,进而发起nand数据传输(txfer)。
对于并发传输模块53,将要读取的分片单元并发传输,并存放在读写缓冲区,后续返回给主机。存储在不同nanddie上的分片单元大小为4kb/n,其中n为大于0的自然数。并发传输4kb数据时,相当于只需要传输4kb数据本身1/n的大小的分片单元,能够有效的减少4kb数据的传输(txfer)时间,降低ssd数据传输时间,进而降低了命令响应延迟。
本方案采用可变的分片策略,将4kb数据切分成多份,并写入到不同nanddie上,在主机读取对应4kb数据时,从对应的nanddie并发传输数据,降低了数据传输时间,进而降低了ssd数据读取的命令响应延迟时间,提高数据传输效率。
以上所述仅为本发明的优选实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!