一种计算大图节点邻近度的TopPPR方法与流程
本发明涉及一种大图节点邻近度计算方法,特别是关于一种计算大图节点邻近度的topppr方法。
背景技术
ppr(personalizedpagerank)是一种经典的大图邻近度的度量标准,它衡量了有向图中所有节点与某一给定节点的相关度大小。ppr的相关研究中,主要关心三类ppr查询:
①点到点查询:计算有向图中源点s到一固定点v的ppr值;
②单源查询:计算有向图中源点s到图中所有点的ppr值;
③top-k查询:找到有向图中从源点s出发最大的k个ppr值对应的点集。在上面这几类查询里,top-kppr查询尤其重要。
目前已有的解决top-kppr查询问题的算法有着两大局限性。第一是这些方法应用在大图上面都有着不可接受的空间和时间占用,或者对top-kppr的返回结果没有准确率(precision)的保证,这意味着如果想要准确的top-kppr结果,也许会漏掉一些。其次,大多数的算法需要对有向图进行一个预处理,这样就使得这些方法无法应用到频繁更新的图上(比如twitter、weibo这样的社交网络图)。
技术实现要素:
针对上述问题,本发明的目的是提供一种计算大图节点邻近度的topppr方法,它拥有极高的效率使其可以应用在大图上,同时对准确度还有很强的理论保证。只需初始给定一个准确度参数ρ∈(0,1],topppr就会以1-1/n的可能性返回准确度至少为ρ的top-kppr结果。
为实现上述目的,本发明采取以下技术方案:一种计算大图节点邻近度的topppr方法,其特征在于包括以下步骤:
1)根据给定图的点集v确定top-k节点集vk和候选集c的初始值;
2)根据预先确定的前向搜索截止阈值以及给定源点对当前候选集c执行前向搜索,并根据得到的各个节点的前向残余值rf(s,u)和前向已确定值πf(s,u),对当前top-k节点集vk和候选集c进行更新;
3)以前向搜索得到的所有非零的前向残余值为基础,采用candidateupdate算法执行nr次随机游走采样,并根据随机游走采样结果对步骤2)中top-k节点集vk和候选集c进行更新;
4)根据预先确定的后向搜索截止阈值和给定终点对步骤3)中的候选集c执行批量后向搜索,根据批量后向搜索结果建立关于后向残余量和已确定量的倒排表rb和πb,并对当前top-k节点集vk以及候选集c进行更新;
5)对步骤4)得到的top-k节点集vk中的节点数目进行判断,当满足阈值条件时,停止迭代,否则重复步骤2)~4),直到满足阈值条件,此时得到的top-k节点集vk即为最终结果。
所述步骤2)中,对当前候选集进行前向搜索,并对当前top-k节点集vk和候选集c进行更新的方法,包括以下步骤:
2.1)确定进行前向搜索的截止阈值
前向搜索截止阈值的初始值的计算公式为:
式中,m为给定图的边数,n是给定图的节点数;
2.2)根据前向搜索截止阈值以及给定源点s对当前候选集c执行前向搜索,对于候选集中的每一个节点u,得到其前向残余值rf(s,u)和前向已确定值πf(s,u),
2.3)根据各个节点的前向残余值rf(s,u)和前向已确定值πf(s,u),对top-k节点集vk和候选集c进行更新。
所述步骤3)中,采用candidateupdate算法执行随机游走采样,并对top-k节点集vk以及候选集c进行更新的方法,包括以下步骤:
3.1)确定进行随机游走采样的次数nr;
3.2)根据步骤2)中所有非零的前向残余值rf(s,t)构建alias结构;
3.3)以
3.4)假设该随机游走停止在节点v,则在批量后向搜索中形成的倒排表rb中找到所有使得残余量rb(v,t)不为0的点t,并对t的ppr的估计值
3.5)重复步骤3.2)~3.4),直到完成nr次随机游走采样,nr次随机游走采样结束后,对候选集c中每个节点的ppr的估计值
3.6)根据各个节点t的ppr的估计值
所述步骤3.1)中,随机采样次数nr的初始值的计算公式为:
式中,m为给定图的边数,n是给定图的节点数。
所述步骤3.4)中,各个节点的ppr的估计值的计算公式为:
式中,
所述步骤3.5)中,各个节点的ppr的估计值
式中,
所述步骤4)中,采用批量后向搜索方法,对top-k节点集vk以及候选集c进行更新的方法,包括以下步骤:
4.1)确定候选集c中各节点的后向残余量和后向已确定值的初始值;
4.2)确定候选集c中各个节点的后向截止阈值
4.3)根据各个节点的后向截止阈值,执行后向搜索,对满足阈值条件的节点进行后向残余量和后向已确定值的更新;
4.4)后向搜索结束后,将各节点的(t,rb(v,t))和(t,πb(v,t))添加到倒排表rb和πb中。
所述步骤5)中,对当前top-k节点集vk中的节点数目进行判断的方法为:
当|vk|≥ρk时,迭代结束,得到最终的top-kppr结果;
当|vk|<ρk时,对当前的前向搜索截止阈值
其中,ρ和k为预先给定的精确度参数以及邻近度参数。
本发明由于采取以上技术方案,其具有以下优点:1、本发明综合了前向搜索、后向搜索和随机游走采样的综合优势,在前向搜索和随机游走基础上,利用后向搜索来减少ppr估计的方差,实现了更高的计算效率。2、本发明在批量后向搜索方法中,对候选集中的不同节点设置不同的后向搜索截止阈值,实现了对候选集中不同节点设置不同的搜索深度,进一步提高了计算效率,减小了时间开销。3、本发明在各次迭代过程中,通过设置合理的前向搜索截止阈值、后向搜索截止阈值以及随机游走采样次数,使得对准确率及运行时间有良好的理论保证,给大图上的top-kppr查询提供了可行的解决方案。4、本发明根据有向图进行top-k查询时,不需要索引所以天然支持动态更新的图,而且在实验下的查询效率、准确度和可扩展性都优于已有的其他算法。因此,本发明可以广泛应用于大图节点邻近度的计算领域。
附图说明
图1是本发明topppr的逻辑结构。
具体实施方式
下面结合附图和实施例对本发明进行详细的描述。
本发明中涉及的标识符及其含义如下表1所示。
表1标识符及其含义
本发明首先对ppr的基本定义及其准确度定义进行简单介绍。
ppr定义:
令g=(v,e)表示一个有向图,v是图中的点集,其点数为n,e是图中的边集,边数为m。给定一个源点s∈v,一个衰减因子α,定义一个从源点s出发的依靠拓扑关系的随机游走,它的每一步要么以α的概率停在当前点上,或是以(1-α)的概率随机游走到当前点的任意一个出邻居节点上。则对于图中的所有点v∈v,从s到v的精确的ppr值π(s,v)等于一个randomwalk从源点s出发停在v的概率。
若把以s为源点的所有ppr值中第k大的ppr值对应的点命名为tk,则根据上面的定义可知,vk={t1,…,tk}就是以s为源点的top-kppr的点集。也即如果给定一个有向图g,一个源点s以及一个参数k,top-kppr查询会返回对于源点s点ppr值最大的k个节点的集合。
ρ-precisetop-kpprqueries(准确度为ρ的top-kppr查询定义):
给定一个源点s和准确率参数ρ∈(0,1],一个ρ-precisetop-kpprquery会返回含有k个节点的点集s,并且s中至少有ρ*k个点在top-kppr的点集vk中。
对于一个固定的参数ρ,存在着n2种可能的top-kppr查询。如果一个top-kppr算法最多有x的概率以低于ρ的概率回答n2中任意一个top-kppr查询,那么我们称该算法以1-x的可能性是ρ-precise的。
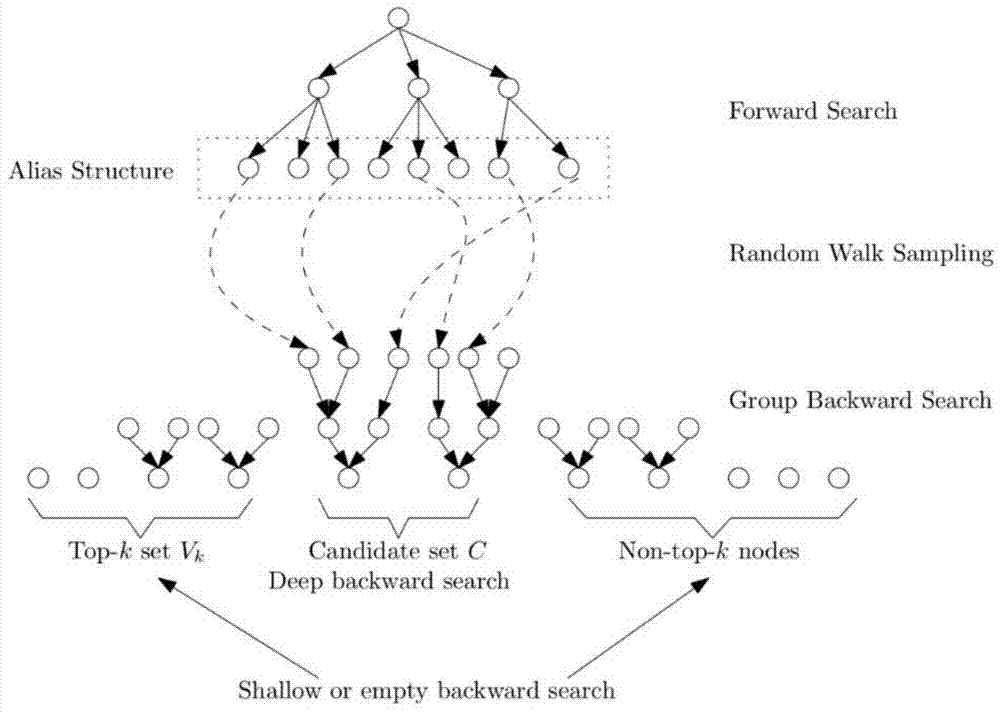
如图1所示,本发明提供的一种计算大图节点邻近度的topppr方法,首先以s为源点做前向搜索,之后对所有非零的残余量点做随机游走采样,最后对一些目标点执行后向搜索,将得到的结果与之前的随机游走相结合用来估计ppr,得到top-k结果。具体的,包括以下步骤:
1)将给定图的点集v分为三类,分别为top-k节点集vk、候选集c以及非top-k节点集v\(vk∪c),并令top-k节点集vk的初始值为空集,候选集c的初始值为给定图中的所有点(即c=v),也即算法开始时给定图中的所有点都可能为top-k点;
其中,各节点集的含义分别为:
top-k节点集vk(top-ksetvk):是指已确定属于top-k集合里的节点集;
候选集c(candidatesetc):根据目前各节点的置信区间无法确定其是否属于top-k中的节点集;
非top-k节点集v\(vk∪c)(non-top-knodes):算法已确定不属于top-k集合里的节点集。
2)根据预先确定的前向搜索截止阈值以及给定源点对当前候选集c执行前向搜索(forwardsearch),并根据得到的各个节点的前向残余值rf(s,u)和前向已确定值πf(s,u),对当前top-k节点集vk和候选集c进行更新;
3)确定进行随机游走采样的次数nr,根据步骤2)中所有非零的前向残余量rf(s,u)构建aliasstructure(别名结构),并采用candidateupdate算法执行nr次随机游走采样(randomwalksampling),对步骤2)中的top-k节点集vk和候选集c进行更新;
4)确定候选集c中各节点的后向截止阈值
5)对top-k节点集vk中的节点数目进行判断:
当|vk|≥ρk时,迭代结束,得到最终的top-kppr结果;
当|vk|<ρk时,重复步骤2)~4),并将前向搜索截止阈值
上述步骤2)中,对当前候选集进行前向搜索,并对当前top-k节点集vk和候选集c进行更新的方法,包括以下步骤:
2.1)确定进行前向搜索的截止阈值
前向搜索截止阈值的初始值的计算公式为:
式中,m为给定图的边数,n是给定图的节点数;
2.2)根据前向搜索截止阈值以及给定源点s对当前候选集c执行前向搜索,对于候选集中的每一个节点u,得到其前向残余值rf(s,u)和前向已确定值πf(s,u),
2.3)根据各个节点的前向残余值rf(s,u)和前向已确定值πf(s,u),对top-k节点集vk和候选集c进行更新。根据给定源点对给定图进行前向搜索的方法为常规方法,本发明在此不再赘述。
上述步骤3)中,采用candidateupdate算法执行随机游走采样,并对top-k节点集vk以及候选集c进行更新的方法,包括以下步骤:
3.1)确定进行随机游走采样的次数nr;
随机采样次数nr的初始值的计算公式为:
式中,m为给定图的边数,n是给定图的节点数;
3.2)根据步骤2)中所有非零的前向残余量rf(s,t)构建alias结构;
3.3)以rf(s,t)/rfsum的概率从构建的alias结构中随机采样一个点u,从点u出发以α的停止概率执行随机游走,其中,rfsum为所有前向残余量之和,即:
rfsum=∑t∈vrf(s,t);
3.4)假设该随机游走停止在节点v,则在批量后向搜索中形成的倒排表rb中找到所有使得残余量rb(v,t)不为0的点t,并对t的ppr的估计值
本发明采用bernstein不等式和经验bernstein不等式来计算各节点的置信区间。给定图中两个节点s和t,对图中任意节点u和v,假设前向搜索得到的已确定值为πf(s,u),残余值为rf(s,u),后向搜索得到的已确定值为πb(v,t),残余值为rb(v,t),令
其中,各节点t的ppr的估计值
式中,
由于本发明对前向搜索的截止阈值
3.5)重复步骤3.2)~3.4),直到完成nr次随机游走采样,nr次随机游走采样结束后,对候选集c中每个节点的ppr的估计值
本发明采用bernstein不等式和经验bernstein不等式来计算当前候选集c中各节点的置信区间。令
3.6)根据各个节点t的ppr的估计值
根据节点t的ppr的估计值
首先计算有多少个点t的置信区间上界小于其下界,如果个数超过|c|+|vk|-k,则表明超过n-k个点的ppr值比π(s,t)小,也即t点一定在top-k结果里,此时我们就将c中的点t放入vk里;如果个数小于|c|+|vk|-k,则说明该点t不一定在top-k节点集vk里,此时不对点t进行操作;
然后计算有多少个点t的置信区间的下界大于其上界,如果个数超过k-|vk|,则表明t点一定不在top-k结果,这时我们就把t从c中剔除;如果个数小于k-|vk|,则说明点t不一定不在top-k节点集vk里,此时不对点t进行操作。
上述步骤4)中,采用批量后向搜索方法,对top-k节点集vk以及候选集c进行更新的方法,包括以下步骤:
4.1)确定候选集c中各节点的后向残余量和后向已确定值的初始值;
对于候选集c中的所有节点t∈c,令其后向残余量的初始值为rb(t,t)=1,对于所有v≠t,令其后向残余量rb(v,t)=0,同时令所有节点的初始已确定值πb(v,t)=0;
4.2)确定候选集c中各个节点的后向截止阈值
本发明中令
其中,din(v)是v的入度,
4.3)根据各个节点的后向截止阈值,执行后向搜索,对满足阈值条件的节点进行后向残余量和后向已确定值的更新;
具体的,若节点v的后向残余量大于其后向搜索阈值,即
4.4)后向搜索结束后,将各节点的(t,rb(v,t))和(t,πb(v,t))添加到倒排表rb和πb中,目的在于当给定一个节点v时,可以利用线性的时间将所有的非零的rb(v,t)和πb(v,t)取出。
上述各实施例仅用于说明本发明,其中各部件的结构、连接方式和制作工艺等都是可以有所变化的,凡是在本发明技术方案的基础上进行的等同变换和改进,均不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!