基于非负矩阵分解和多样-一致性的多视图聚类方法与流程
本发明属于计算机视觉和模式识别技术领域,涉及一种多视图聚类方法,具体涉及一种基于非负矩阵分解和多样-一致性的多视图聚类方法,可应用于生物信息分析、金融投资分析和商务应用等领域。
背景技术
近年来,互联网信息技术的发展,使得数据成为当今社会中重要的组成部分。随着多媒体技术的发展,数据呈现爆炸式增长,海量成为当今数据的一个显著特征。此外,随着信息采集技术的迅速发展,人们可以从不同数据源中获取大量数据,这些异质数据在不同角度描述同一目标的不同特征,将每个数据源的数据看作一个视图的数据,由此可得多视图数据。多视图数据中包含比单视图数据更加详细全面的信息,通常包含公共和互补信息。因此,多视图学习成为当今数据时代的一个研究方向。综上,如何从海量的多视图数据中提取出有用的信息成为现代数据处理的主要任务。数据挖掘是数据预处理中最常用的基本方法,聚类是数据挖掘领域中常用的基本分析方法之一。如今,针对单视图数据的传统聚类方法已取得较好的效果,但若将传统聚类方法直接应用到多视图数据中进行聚类,不能有效利用多视图数据中的公共和互补信息,因而影响了多视图数据的聚类效果。因此,如何利用多视图数据中包含的丰富信息提高聚类性能,成为现阶段聚类领域中的关键问题,如何设计快速有效的多视图聚类方法,成为大数据时代亟待解决的问题。
聚类是机器学习和数据挖掘领域的基本方法,其目的在于利用数据中的潜在数据结构,将数据集划分为若干个聚类簇,使得同一簇中的数据点之间的相似性较高,不同簇间的数据点间的相似性较低。传统的单视图聚类方法可分为基于原型、基于层次、基于密度、基于网格、基于图和基于模型等聚类方法。多视图聚类方法的关键在于如何融合多视图数据,充分利用多视图数据中的有用信息提高多视图数据的聚类性能。一种朴素的多视图聚类方法是将多视图数据进行拼接得到一个新的单视图数据,再通过传统的单视图聚类方法得到聚类结果。此类方法只是原则上组合了不同视图的数据,忽略了不同视图数据中包含的公共和互补信息,从而影响了多视图数据的聚类效果。另一种多视图聚类方法是学习多视图数据的一个公共子空间,并在此公共子空间中进行多视图数据的聚类分析,由此得到多视图数据的聚类结果。这类算法通常可以学习到多视图数据中的公共信息,因此可以得到较好的聚类结果。
非负矩阵分解(nonnegativematrixfactorization,nmf)将数据矩阵分解为两个低秩矩阵的乘积,实现了数据的降维,一般情况下,分解后的基矩阵和系数矩阵是非负且稀疏的,该方法具有较好的可解释性和明确的物理意义,因此,非负矩阵分解成为数据表示中有力的基本方法,被广泛应用于单视图数据聚类和多视图数据聚类领域中。现有基于非负矩阵分解的多视图聚类方法虽然取得了较好的聚类结果,但是此类方法在对多视图数据进行聚类时,忽略了多视图数据中包含的互补信息,使得聚类精度和归一化交互信息较低,影响了多视图数据的聚类效果。
例如linlinzong,xianchaozhang,longzhao,hongyu和qianlizhao等人,在2017年的neuralnetworks期刊中,发表了名为“multi-viewclusteringviamulti-manifoldregularizednon-negativematrixfactorization”的文章,提出基于多流形正则的非负矩阵分解的多视图聚类方法,该方法分别利用非负矩阵分解、基于质心的协同正则化和流形正则化方法对多视图数据进行建模,保持多视图数据所在的特征空间中的局部几何结构信息,同时寻找多视图数据共享的一致性表示矩阵,对一致性表示矩阵进行k-均值聚类,得到多视图数据的聚类结果。但该方法只利用了多视图数据中包含的公共信息,忽略了多视图数据中的互补信息,使得聚类精度和归一化交互信息较低,影响了多视图数据的聚类性能。
技术实现要素:
本发明的目的在于针对上述已有技术存在的不足,提出了一种基于非负矩阵分解和多样-一致性的多视图聚类方法,用于解决现有技术中存在的聚类精度和归一化交互信息较低的技术问题。
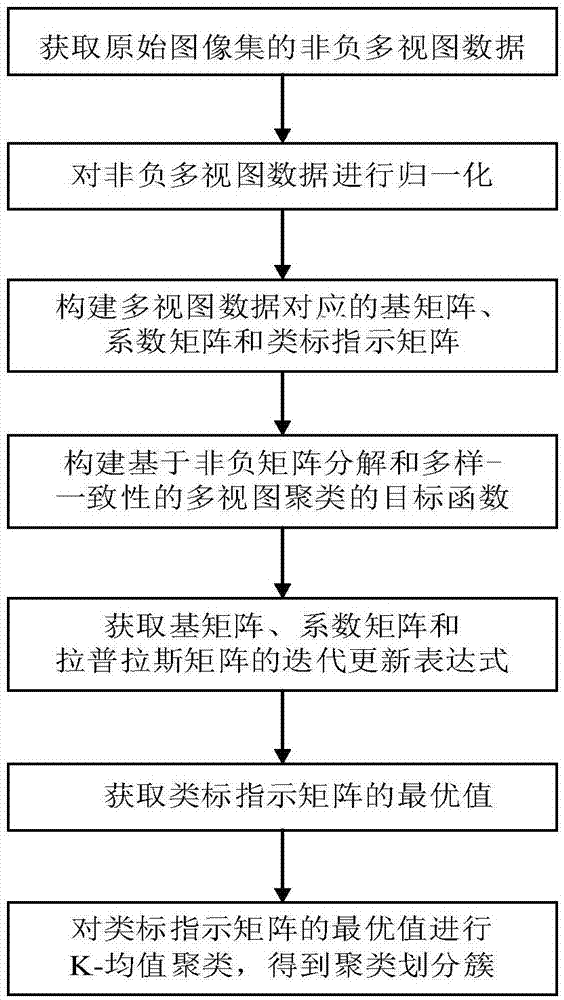
本发明的技术思路是:获取原始图像集的归一化非负多视图数据,构建多视图数据对应的基矩阵、系数矩阵和类标指示矩阵,并利用非负矩阵分解的重构误差项、表示多样性约束项、类标一致性约束项和相似性保持项,构建基于非负矩阵分解和多样-一致性多视图聚类的目标函数,通过拉格朗日乘子法,获取基矩阵、系数矩阵和拉普拉斯矩阵的迭代更新表达式,并得到类标指示矩阵的最优值,对类标指示矩阵的最优值进行k-均值聚类,得到多视图数据对应的聚类簇。实现步骤如下:
(1)获取原始图像集的非负多视图数据
提取原始图像集中每幅图像的多种图像特征,得到原始图像集的非负多视图数据
(2)对非负多视图数据
对非负多视图数据
(3)构建多视图数据
对多视图数据
(4)构建多视图数据
构建多视图数据
(5)构建基于非负矩阵分解和多样-一致性的多视图聚类的目标函数:
(5a)利用多视图数据
(5b)利用希尔伯特-施密特独立准则,通过系数矩阵
(5c)利用流形正则化方法,通过系数矩阵
(5d)利用谱聚类方法,通过拉普拉斯矩阵
(5e)获取基于非负矩阵分解和多样-一致性的多视图聚类的目标函数:
设置表示多样性约束项的权重为λ1,相似性保持项的权重为λ2,类标一致性约束项的权重为λ3,并对非负矩阵分解的重构误差项、表示多样性约束项、相似性保持项和类标一致性约束项进行加权相加,得到基于非负矩阵分解和多样-一致性的多视图聚类的目标函数,其中,λ1、λ2和λ3的取值范围为[0,1];
(6)获取基矩阵
(6a)构建基于非负矩阵分解和多样-一致性的多视图聚类的目标函数对应的拉格朗日函数
(6b)利用拉格朗日函数
(7)获取类标指示矩阵f的最优值f*:
(7a)设定目标函数差值的阈值和最大迭代次数;
(7b)定义e1对
(7c)对
(7d)计算类标指示矩阵f的最优值f*:
(7d1)计算拉普拉斯矩阵
(7d2)对m进行奇异值分解,对分解得到的多个特征值按照从小到大的顺序排列,并计算前c个特征值中每个特征值对应的特征向量,得到c个特征向量,其中,c为聚类簇的个数,且c≥1;
(7d3)将c个特征向量对应的c个特征值按照从小到大的顺序排列,得到特征矩阵,并将该特征矩阵作为类标指示矩阵f的最优值f*;
(8)对类标指示矩阵f的最优值f*进行k-均值聚类,得到多视图数据对应的聚类簇。
本发明与现有技术相比,具有以下优点:
本发明利用希尔伯特-施密特独立准则,构造多视图数据的表示多样性约束项,利用谱聚类方法,构造多视图数据的类标一致性约束项,并通过非负矩阵分解的重构误差项、表示多样性约束项、类标一致性约束项和相似性保持项,构建基于非负矩阵分解和多样-一致性的多视图聚类的目标函数,该目标函数充分利用了多视图数据中包含的公共和互补信息,与现有技术相比,有效地提高了多视图聚类的精度和归一化交互信息。
附图说明
图1为本发明的实现流程图;
图2为本发明与现有技术在uci手写体数据集下的聚类精度的曲线对比图;
图3为本发明与现有技术在uci手写体数据集下的聚类归一化交互信息的曲线对比图;
图4为本发明与现有技术在extendyaleb数据集下的聚类精度的曲线对比图;
图5为本发明与现有技术在extendyaleb数据集下的聚类归一化交互信息的曲线对比图。
具体实施方式
下面结合附图和具体实施例,对本发明作进一步详细描述。
参照图1,基于非负矩阵分解和多样-一致性的多视图聚类方法,包括如下步骤:
步骤1获取原始图像集的非负多视图数据
提取原始图像集中每幅图像的多种图像特征,得到原始图像集的非负多视图数据
步骤2对非负多视图数据
对非负多视图数据
步骤3构建多视图数据
对多视图数据
步骤4构建多视图数据
(4a)计算多视图数据
将多视图数据
(4b)构建多视图数据
将
(4c)构建多视图数据
根据k近邻图,判断数据点xi是否为数据点xj的k近邻点,若是,令相似性矩阵
(4d)计算多视图数据
对相似性矩阵
(4e)对
步骤5构建基于非负矩阵分解和多样-一致性的多视图聚类的目标函数:
(5a)利用多视图数据
(5b)利用希尔伯特-施密特独立准则,通过系数矩阵
(5c)利用流形正则化方法,通过系数矩阵
(5d)利用谱聚类方法,通过拉普拉斯矩阵
(5e)获取基于非负矩阵分解和多样-一致性的多视图聚类的目标函数:
设置表示多样性约束项的权重为λ1,相似性保持项的权重为λ2,类标一致性约束项的权重为λ3,并对非负矩阵分解的重构误差项、表示多样性约束项、相似性保持项和类标一致性约束项进行加权相加,得到基于非负矩阵分解和多样-一致性的多视图聚类的目标函数,其表达式为:
s.t.u(m)≥0,v(m)≥0,m=1,…,nv,ftf=i
其中,λ1、λ2和λ3的取值范围为[0,1]。
步骤6获取基矩阵
(6a)构建基于非负矩阵分解和多样-一致性的多视图聚类的目标函数对应的拉格朗日函数
其中,ξ、η和
(6b)利用拉格朗日函数
其中,i=1,2,…,m,t=1,2,…,d,j=1,2,…,n,m为原始图像的像素个数,d为利用非负矩阵分解进行降维时的维度,
步骤7获取类标指示矩阵f的最优值f*:
(7a)设定目标函数差值的阈值和最大迭代次数;
(7b)定义e1对
(7c)对
(7d)计算类标指示矩阵f的最优值f*:
(7d1)计算拉普拉斯矩阵
(7d2)对m进行奇异值分解,对分解得到的多个特征值按照从小到大的顺序排列,并计算前c个特征值中每个特征值对应的特征向量,得到c个特征向量,其中c为聚类簇的个数,且c≥1,实际应用中,c的取值过小,会使得聚类精度低,影响聚类效果,c的取值过大,容易造成过拟合,使得算法的泛化能力差;
(7d3)将c个特征向量对应的c个特征值按照从小到大的顺序排列,得到特征矩阵,并将该特征矩阵作为类标指示矩阵f的最优值f*。
步骤8对类标指示矩阵f的最优值f*进行k-均值聚类:
(8a)将类标指示矩阵f的最优值f*的每行数据作为样本数据点,并从f*中随机选取c个样本数据点,并将每个样本数据点作为一个聚类中心,得到c个聚类中心,其中c≥1;
(8b)计算每个样本数据点与每个聚类中心的距离,并将每个样本数据点分配到与其距离最小的聚类中心所属的类别中,得到c个聚类簇;
(8c)计算每个聚类簇中所有样本数据点的均值,并将每个聚类簇对应的均值作为该簇的聚类中心,实现对每个聚类簇聚类中心的更新;
(8d)重复执行步骤(8b)~(8c),直到所有聚类中心不再发生变化时停止,得到多视图数据对应的聚类簇。
以下结合仿真实验,对本发明的技术效果作进一步说明。
1.仿真条件和内容:
本发明的仿真实验中计算机配置环境为intel(r)core(i7-3770)3.40ghz中央处理器、内存16g、windows7操作系统,计算机仿真软件采用matlabr2015b软件。本发明在公开的多视图数据集uci手写体数据集和extendyaleb数据集上进行仿真。实验中的参数设置为:λ1=0.1,λ2=0.2,λ3=0.5,c=10,k=10。
仿真1:使用本发明与现有基于多流形正则的非负矩阵分解的多视图聚类方法在uci手写体数据集中进行多视图聚类得到的聚类精度,其结果如图2所示。
仿真2:使用本发明与现有基于多流形正则的非负矩阵分解的多视图聚类方法在uci手写体数据集中进行多视图聚类得到的聚类归一化交互信息,其结果如图3所示。
仿真3:使用本发明与现有基于多流形正则的非负矩阵分解的多视图聚类方法在extendyaleb数据集中进行多视图聚类得到的聚类精度,其结果如图4所示。
仿真4:使用本发明与现有基于多流形正则的非负矩阵分解的多视图聚类方法在extendyaleb数据集中进行多视图聚类得到的聚类归一化交互信息,其结果如图5所示。
2.仿真结果分析:
参照图2和图4,图2和图4为取不同的降维维度时的聚类精度曲线图,横坐标轴表示降维的维数,纵坐标轴表示聚类精度,用正方形标注的曲线表示本发明,用五角形标注的曲线表示基于多流形正则的非负矩阵分解的多视图聚类方法。
参照图3和图5,图3和图5为取不同的降维维度时的聚类归一化交互信息的曲线图,横坐标轴表示降维的维数,纵坐标轴表示聚类归一化交互信息,用正方形标注的曲线表示本发明,用五角形标注的曲线表示基于多流形正则的非负矩阵分解的多视图聚类方法。
从图2~图5的仿真结果图中可见,在不同的降维维度下,对多视图数据进行聚类时,本发明的聚类精度和归一化交互信息的值明显高于现有技术的聚类精度和归一化交互信息的值。这是因为在进行多视图聚类时,与现有多视图聚类技术相比,本发明利用非负矩阵分解的重构误差项、表示多样性约束项、类标一致性约束项和相似性保持项,构建基于非负矩阵分解和多样-一致性的多视图聚类的目标函数,该目标函数充分利用了多视图数据中的互补和公共信息,与现有技术相比,有效地提高了多视图聚类的精度和归一化交互信息。
- 还没有人留言评论。精彩留言会获得点赞!