基于深度信念网络算法支持向量机的软件缺陷预测方法与流程
本发明涉及软件缺陷预测技术,尤其涉及一种基于深度信念网络算法支持向量机的软件缺陷预测方法。
背景技术
软件缺陷分布预测在软件开发过程中起着重要的作用,对缺陷软件模块的及时准确预测将能够大大提高软件测试资源的有效配置。静态分析能够在软件发布前发现软件中存在的缺陷,且不会降低软件运行的效率。
因此近年来,许多研究人员通过提取软件模块的软件度量属性形成训练样本,并利用机器学习技术构建软件缺陷分布预测模型,将机器学习技术应用于软件缺陷静态预测领域。传统的缺陷预测模型主要指在缺陷数据充足的情况下,利用常用的有监督的机器学习算法,对同一软件中的缺陷数据进行训练和预测的模型,其中常用到的机器学习算法主要包括决策树(dt)、随机森林(rf)、朴素贝叶斯(nb)、逻辑回归(lr)、支持向量机(svm)、人工神经网络(ann)等。
但随着现代大规模软件系统在软件规模和软件复杂性方面的增长,使用机器学习方法构建软件缺陷预测模型需要面对巨大的高维度数据。在软件缺陷预测过程中,过多的度量属性将会导致数据冗余,从而导致较高的预测成本和较低的预测精度,同时由于数据具有非线性的特征,在单独使用svm,构建分类超平面并进行预测时会形成干扰。
技术实现要素:
有鉴于此,本发明提供了一种基于深度信念网络算法支持向量机(dbn-svm)的软件缺陷分布预测方法,采用新型的软件缺陷分布预测模型——dbn-svm,解决软件缺陷分布的预测中,由多维测量引起的数据冗余所导致的预测精度降低的问题。
为了解决上述技术问题,本发明是这样实现的:
一种基于深度信念网络算法支持向量机dbn-svm的软件缺陷预测方法,包括:
采用深度信念网络dbn对从待预测软件提取的软件度量属性进行降维;
降维后的数据进入支持向量机svm进行分类,得到软件缺陷预测结果。
优选地,dbn-svm模型的样本数据集来自美国国家航空航天局nasa的软件缺陷预测数据集mdp。
优选地,选取mdp中的jm1、mc1和pc5数据集进行训练和验证。
优选地,dbn-svm模型的训练包括如下步骤:
步骤1、在样本数据集中选择部分作为训练集x,用于对dbn进行预训练,获得经过降维的训练集x1以及构建好的dbn;
步骤2、将所述训练集x1输入svm分类器,对分类器进行训练;
步骤3、从所述样本数据集中选择测试集y,输入训练好的dbn-svm,获得预测结果,与实际结果进行比较,以验证模型效果。
优选地,将样本数据集随机分为10个子集;每次选取其中一个子集作为测试集,而剩余的9个子集被用作训练集,采用十倍交叉验证,共进行10次验证实验;将10次实验结果与实际结果进行比较,并取十次比较的平均值来评价模型的性能。
有益效果:
(1)本发明采用dbn和svm构建两层网络,dbn可以解决软件度量属性数据冗余的问题,达到降维的作用。降维后的数据使用svm进行分类,使得最后的缺陷分布预测结果较其他传统的预测技术相比拥有更高的准确度,同时由于dbn的使用,使得本发明较其他基于神经网络的缺陷预测方法相比,能够有效地提高神经网络训练速度。
(2)与传统预测方法相比,本专利能够有效地提取和处理源程序的数据特征,性能优于svm、lle-svm、npe-svm等部分缺陷预测方法。
附图说明
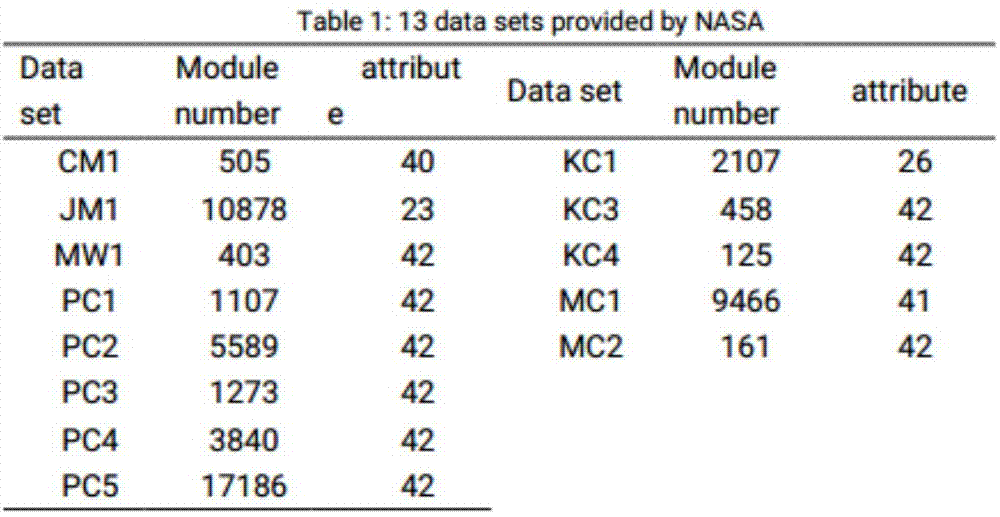
图1为mdp数据中的不同数据集。
图2为数据集中包含的软件度量属性。
图3为dbn进行预训练的结构。
图4为dbn和svm构建的两层网络。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
为了更准确地预测软件中的各种缺陷以提高软件的质量,降低高维软件度量数据的维度是非常有必要的事情。流形学习是处理高维数据的一种重要方法,它可以发现隐藏在高维软件度量数据中的真实结构。目前,研究者主要提出了局部线性嵌入(lle)、邻域嵌入保护(npe)以及等距特征映射等方法。经过降维之后的度量数据还需要使用机器学习的方法构建预测模型对其进行分类。
受深度学习在图像处理、语音识别、和自然语言处理方面的成功启发,本申请认为深度信念网络(dbn)等深度学习方法也可以成为检测软件缺陷的有效方法。dbn,deepbeliefnets,是一种神经网络算法。dbn由若干层神经元构成,组成元件是受限玻尔兹曼机(rbm)。使用dbn对特征进行学习,通过训练其神经元间的权重,能够保留原始特征的特点,同时降低特征的维度。dbn可以有效在第一层降低数据维度,降低高维度数据对svm带来的干扰。与其他神经网络相比,dbn的最大优点是,计算速度更快,进而有效解决了大型神经网络训练速度慢的问题。
因此,本发明提出了一种结合深度信念网络和支持向量机的新型软件缺陷分布预测模型,其构建深度信念网络对软件度量属性进行有效特征提取,从而实现数据降维,然后利用降维后的数据构建缺陷分布预测模型,该模型使用svm作为软件缺陷分布预测模型的基本分类器。
可见,本发明采用dbn和svm构建两层网络,如图4所示,dbn可以解决软件度量属性数据冗余的问题,达到降维的作用。降维后的数据使用svm进行分类,使得最后的缺陷分布预测结果较其他传统的预测技术相比拥有更高的准确度,同时由于dbn的使用,使得本发明较其他基于神经网络的缺陷预测方法相比,能够有效地提高神经网络训练速度。
下面对本发明进行详细描述。
步骤1:获得软件缺陷预测数据集。
本发明使用的实验数据来自nasa的mdp,它被广泛应用于软件缺陷预测研究。它包含13个数据集,如下图1所示。每个数据集合包含多个样本,每个样本对应于一个软件模块,并且每个软件模块由21个静态代码属性,以及1个标识属性组成。静态代码属性对每条数据中进行标识,包括代码行(loc),halstead属性和mccabe属性,以及最后的判断标签,该标签的值表示该条数据所对应的软件是否具有缺陷,有缺陷为true,无缺陷为false。在本专利中选择了nasa中jm1,mc1和pc5的数据集进行训练和验证。
用户可以从中选择特定的数据集作为样本数据集。
该步骤将在缺陷分布预测模型开始预测之前完成。
步骤2:在样本数据集中选择训练集,用于构建dbn,进行预训练,获得经过降维的训练集以及构建好的dbn。
该步骤是在步骤1获得的样本数据集之上选取训练集x和测试集y,训练集x用于构建dbn,进行预训练;测试集则用于检验模型构建成果。
为了验证模型的预测能力,本专利采用十倍交叉验证方法。首先,将步骤1获得的样本数据集随机分为10个子集。每次实验中,选取其中一个子集被作为测试集,而剩余的9个子集被用作训练集,总共进行10个验证实验。经过10次实验,我们通过10次实验的平均值来评价模型的性能。每次使用的训练集和测试集分别用x和y进行表示。
使用训练集x对dbn进行预训练。
本专利预测模型中的dbn由5个堆叠rbm构成,其具体结构如下图3所示。
将之前获得的训练集x分为两部分,将判断标签这一属性单独提出,剩余的部分作为最底层rbm的显示层的输入,通过训练调整该rbm中隐藏层与显示层的权值参数,然后将该隐藏层作为第二个rbm的输入,充分训练第二个rbm之后,继续向上执行训练步骤,检测权值并生成新的权值;直到在顶层的rbm训练时,将判断标签与前一个隐藏层的输出合并作为该层rbm的输入,经过训练后输出。该输出即为经过预训练的训练集。dbn通过逐层训练调整层间的权值,使最终输出的经过预训练的训练集能够降低数据冗余情况,提取有效属性。
通过这一步获得经过降维的训练集,成为预训练的训练集x1,以及构建好的dbn。
该步骤将在缺陷分布预测模型开始预测之前完成。
步骤3:将步骤2获得的经过预训练的训练集x1用作步骤3的输入数据集,对svm分类器进行训练。
在这一步骤,将步骤2获得的经过预训练的训练集x1作为构建svm分类器的输入数据集,进行分类训练。在svm模型中引入惩罚因子和松弛变量来提高预测准确率,将svm的训练过程转化为解决公式(1)和公式(2)的优化问题。
s.t.yi(ωtγ(xi)+b)≥1-ξi,i=1,2,...,n(2)
其中,c是惩罚系数,ξi是松弛变量,ω是与分类超平面正交的d维向量,b是偏差项,γ(x)是svm使用的核函数。在dbn-svm中,γ(x)是径向基核函数。n为输入svm中参与分类器训练的样本的总数,此处为经过预训练的训练集x1。
选择rbf函数作为支持向量机的核函数,根据定义的值间隔和步长,使用网络搜索和十字交叉验证来优化参数,该方法用于优化svm模型的参数,找到其中对应的c和g的值,其中c为惩罚系数,g为核函数参数,使其能够提高svm的分类准确率。
通过这一步,获得训练完成的svm分类器。
该步骤在使用模型进行预测之前完成。
步骤4:将步骤2获得的测试集y作为测试输入集,使用步骤2及步骤3中获得dbn与svm进行缺陷预测,获得测试结果。
本步骤是用于对前面步骤的训练结果进行测试和验证。
测试集y输入步骤2训练好的dbn进行降维,提取有效特征属性,获得经过预训练的测试集y1,再将y1作为步骤3中训练好的svm分类器的输入,使用缺陷预测模型进行预测,获得的最终预测结果与实际结果进行比较。如果预测效果达到要求,则说明训练完成。否则再选取样本数据集继续进行训练。
被分为10个子集的样本数据集,均经过上述过程后,采用10次实验的平均值来评价模型的性能。
经过上述步骤1~4获得了训练好的dbn-svm。使用时,采用深度信念网络dbn对从待预测软件提取的软件度量属性进行降维;降维后的数据进入支持向量机svm进行分类,得到软件缺陷预测结果。
如前所述,本发明的优势在于:
(1)将软件安全漏洞静态检测和机器学习算法相结合。
(2)将深度信念网络算法(dbn)与支持向量机(svm)技术相结合,解决软件缺陷数据集中存在的数据冗余问题,解决数据非线性问题,有效改善预测指标,提高预测准确率。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!