数据集生成方法及装置与流程
本发明涉及数据安全领域,具体而言,涉及一种数据集生成方法及装置。
背景技术:
随着智慧城市、智能电网、智慧医疗等数字化技术的快速发展和移动终端设备的广泛普及,人们的衣食住行、健康医疗等信息被数字化,每天产生海量数据,促成了大数据时代的到来。大量的数据往往由不同的数据拥有者所有,例如,医院和金融机构分别拥有一组医疗数据和金融数据。当分布在多方的数据具有相同的id包含不同的属性时,称之为多方垂直分割数据。发布多方垂直分割数据,有利于数据分析者充分分析和挖掘数据中潜在价值。然而,垂直分割数据中往往包含个体大量敏感信息,直接发布这种数据将不可避免地泄露个体隐私信息。
差分隐私保护模型的提出为解决满足隐私保护的数据发布问题提供了一种可行的方案。与基于匿名的隐私保护模型不同,差分隐私保护模型提供了一种严格、可量化的隐私保护手段,且所提供的隐私保护强度不依赖于攻击者所掌握的背景知识。
当前,在单方场景下,通过贝叶斯网络发布隐私的数据(privatedatareleaseviabayesiannetworks,privbayes)技术解决了满足差分隐私的数据发布问题:它首先基于原始数据构建一个贝叶斯网络,接着在构建的贝叶斯网络中加入噪音,使其达到差分隐私保护要求;最后利用含有噪音的贝叶斯网络生成新的数据发布。然而由于算法本身是面向单方数据设计,privbayes在多方场景不可用。
在多方场景下,现有的满足差分隐私保护的垂直分割数据发布方法(distdiffgen)仅能够用于发布构建决策树分类器所需的统计信息,因此,该方法仅是一种与具体数据分析任务绑定的数据发布方法。目前,实际应用中满足差分隐私保护的垂直分割数据发布方法仅能够应用于基于决策树的分类任务,而对于其他类型分类任务、聚类任务、统计分析任务等数据分析和挖掘任务则不可用。
技术实现要素:
本发明实施例提供了一种数据集生成方法及装置,以至少解决相关技术中数据的隐私保护问题。
根据本发明的一个方面,提供了一种数据集生成法,包括:每个数据拥有者获取本地原始数据集中显变量对的互信息,生成叶子层隐变量;所述每个数据拥有者在本地建立树状索引,所述数据拥有者两两组合形成数据拥有者对,进行树状索引的匹配和叶子层隐变量之间的互信息的计算;所述每个数据拥有者执行隐树结构学习和隐树参数学习,各自在本地生成隐树;所述每个数据拥有者根据学习到的隐树结构和隐树参数自顶向下生成目标数据集。
根据本发明的另一方面,提供了一种数据集生成装置,该装置包括:隐变量生成模块,用于为每个数据拥有者获取本地原始数据集中显变量对的互信息,生成叶子层隐变量;互信息计算模块,用于为所述每个数据拥有者在本地建立树状索引,将所述数据拥有者两两组合形成数据拥有者对,进行树状索引的匹配和叶子层隐变量之间的互信息的计算;隐树生成模块,用于为所述每个数据拥有者执行隐树结构学习和隐树参数学习,各自在本地生成隐树;数据集生成模块,用于为所述每个数据拥有者根据学习到的隐树结构和隐树参数自顶向下生成目标数据集。
根据本发明的又一方面,还提供了一种数据集生成系统,该系统包括前文实施例中的多个数据集生成装置,其中,每个数据集生成装置对应一个数据拥有者的数据处理,所有数据集生成装置通过网络相连接。
根据本发明的再一方面,还提供了一种存储介质,所述存储介质中存储有计算机可读程序,其中,所述程序运行时执行前文实施例中的方法步骤。
在本发明上述实施例中,通过采用隐树模型来建模垂直分割于多个数据拥有者之间的数据集分布,依据学习到的隐树模型联合发布含噪声的数据集,减少了噪音加入的量,保证在多方垂直分割数据的发布过程中,满足对于所发布的数据集的差分隐私的要求,同时发布的整体数据能够支持多种数据分析任务。
附图说明
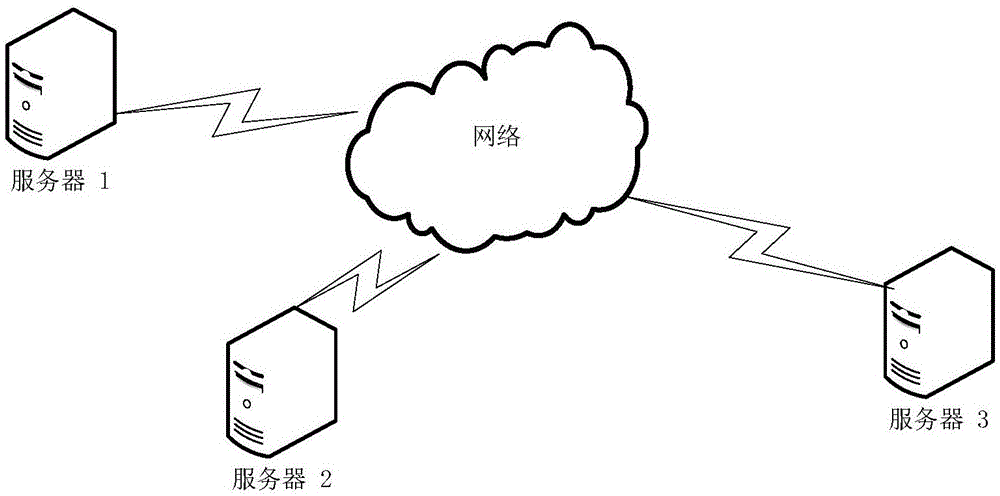
图1是根据本发明实施例的系统架构示意图;
图2是根据本发明实施例的数据集生成方法流程图;
图3是根据本发明实施例的多方垂直分割的数据发布方法流程图;
图4是根据本发明实施例的数据集生成装置的结构框图;
图5是根据本发明实施例的多方垂直分割的数据发布装置的结构框图;
图6是根据本发明实施例一的方法流程图;
图7是根据本发明实施例二的方法流程图;
图8是根据本发明实施例三的方法流程图;
图9是根据本发明实施例四的方法流程图。
具体实施方式
下文中将参考附图结合实施例来详细说明本发明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
本发明通过下面的实施例提供了一种与具体数据分析任务无关的、满足差分隐私保护的多方垂直分割数据发布的方法。使得在大数据环境下,在多方垂直分割数据的发布过程中,既满足了对于所发布的数据集的差分隐私的要求,同时又使得发布的整体数据能够支持多种数据分析任务。从而实现在保护个体隐私的前提下,数据分析者可以充分地分析挖掘数据中的价值,为决策支持和科学研究提供更多依据。
需要说明的是,在本发明的实施例中,数据拥有者并不是指具体的人,而是指多方垂直分割数据的所有方,其可以是对多方垂直分割数据进行处理的各种数据处理装置。例如,数据库、大数据平台、服务器等,每个数据拥有者都有各自的数据(即保存在数据仓库或者数据库中的数据)。
图1为本发明的实施例的系统架构。如图1所示,具有相同的id,但包含不同的属性的多方垂直分割数据(例如,医疗数据或金融数据)分布在三个不同的数据拥有者上。在本实施例中,所述数据拥有者可以为服务器,因此,服务器1、服务器2和服务器3分别代表不同的数据拥有者。其中,服务器1、服务器2和服务器3之间通过有线或无线网络连接。在本实施例中,连接服务器1、服务器2和服务器3的网络形式和拓扑结构不受限制。主要取决于各个数据拥有者之间的地理分布和实际需要。例如,可以是局域网,也可以是因特网,或者是其他专用网络。通过所连接的网络,各服务器之间可以发送心跳信息,注册成为多方垂直分割数据发布参与者,并发布所生成的多方垂直分割数据集等。
通过在图1所示系统架构上运行本发明实施例所提供的技术方案,可以保证在多方垂直分割数据的发布过程中,既满足对于所发布的数据集的差分隐私的要求,同时发布的整体数据能够支持多种数据分析任务。
在本实施例中提供了一种数据集生成方法,所述方法可以基于上述实施例的系统架构来实现。图2是根据本发明实施例的数据集生成方法的流程图。在本实施例中包括了多个数据拥有者,如图2所示,该流程包括如下步骤:
步骤s202,每个数据拥有者计算本地原始数据集中显变量对的互信息,生成叶子层隐变量。
步骤s204,所述每个数据拥有者在本地建立树状索引,所述数据拥有者两两组合形成数据拥有者对,进行树状索引的匹配和叶子层隐变量之间的互信息的计算。
步骤s206,所述每个数据拥有者执行隐树结构学习和隐树参数学习,各自在本地生成隐树。
步骤s208,所述每个数据拥有者根据学习到的隐树结构和隐树参数自顶向下的生成目标数据集。
在上述的实施例中,通过采用隐树模型来建模垂直分割于多个数据拥有者之间的数据集分布,依据学习到的隐树模型联合发布含噪声的数据集,从而在发布的数据满足差分隐私的条件下,最大程度地减少噪音加入的量。
本发明还提供了另一与具体数据分析任务无关的满足差分隐私保护的多方垂直分割的数据发布方法实施例,如图3所示,该方法包括如下流程:
步骤s301,将原始数据集进行统一编码、缺失数据填充、离散化、二进制化,得到规整的显变量数据集。
步骤s302,将显变量两两组合形成一组显变量对,访问数据计算出每对显变量之间的互信息。
步骤s303,利用差分隐私指数机制,在满足差分隐私保护的条件下生成叶子层隐变量。
步骤s304,对于每个数据拥有者,将叶子层隐变量两两组合形成隐变量对,访问隐变量数据计算出每对隐变量之间的互信息。
步骤s305,基于计算出来的叶子层隐变量之间的互信息,对叶子层隐变量在满足差分隐私保护的条件下进行分组,生成上层隐变量。
步骤s306,自底向上地重复上述由底层隐变量生成上层隐变量的步骤,直至上层隐变量只有一个隐变量节点,将该隐变量记为根节点;与父子节点之间的连接边,各个隐变量节点共同组成树状索引,存储在数据拥有者本地。
步骤s307,各个数据拥有者两两组合形成数据拥有者对,然后各个数据拥有者传递协商相关参数,包括不限于数据拥有者组合配对情况、数据拥有者对后续计算的执行次序、单个数据拥有者同时可以通讯的其他数据拥有者最大数目等等。
步骤s308,对于每对数据拥有者,共同运行安全多方计算协议,在安全多方计算协议加密的条件下运行基于树状索引匹配的两方隐变量互信息计算方法。对于每个数据拥有者,可以同时与多个其他数据拥有者进行通讯,同时进行上述计算。多个数据拥有者共同运行安全协议,在多方安全计算协议加密的条件下将之前计算到的隐变量对之间的互信息广播给其他所有数据拥有者;直至每个数据拥有者本地存储着相同而完备的叶子层隐变量对之间的关联强度。
步骤s309,多个数据拥有者独立地在本地运行最大生成树构建方法,以叶子层隐变量和显变量为节点,计算到的变量之间的关联强度作为相应连接边的权值,构建权重和最小的无环连通图。随机为该无环连通图选择根节点,按照与根节点路径长度距离来为每一条连接边所连接的节点对确定父子关系,得到隐树结构。
步骤s310,按照生成的隐树结构,自顶向下的为每一对相互连接的父子节点,运用拉普拉斯机制,在满足差分隐私保护的条件下计算出父子节点间的条件概率。
步骤s311,计算根节点在原始数据集的概率分布,依据概率分布抽取根节点对应的生成数据集;然后自顶向下的逐层为每个节点依据父节点当前的生成数据,计算出父子节点的联合分布概率,依据联合分布概率和随机分布来为每个节点生成含噪声的数据。得到含有噪声的、满足差分隐私保护的生成数据集。
在本发明的上述实施例中,一方面,运用数据隐私领域领先的差分隐私模型在多方数据联合发布过程为各数据拥有者联合生成的数据提供差分隐私保护,保证数据隐私受到严格保护。另一方面,还采用隐树模型来建模垂直分割于多个数据拥有者之间的数据集分布,依据学习到的隐树模型联合发布含噪声的数据集,从而在发布的数据满足-差分隐私的条件下,最大程度地减少噪音加入的量,使得发布的数据的效用得到提升,保证整体数据服务的质量。另外,本实施例中还采用基于树状索引的隐变量互信息计算方法来舍弃关联强度较小的隐变量之间的互信息的计算,减少了需要加入噪声的次数,从而在综合利用各方数据提供高质量服务的同时,减少了通讯开销。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到根据上述实施例的方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是计算机,服务器,或者网络设备等)执行本发明各个实施例所述的方法。
在本实施例中还提供了一种数据集生成装置,该装置用于实现上述实施例及优选实施方式,已经进行过说明的不再赘述。如以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能被构想的。
图4是根据本发明实施例的数据集生成装置的结构框图,如图4所示,该装置包括隐变量生成模块10、互信息计算模块20、隐树生成模块30和数据集生成模块40。
隐变量生成模块10用于为每个数据拥有者计算本地原始数据集中显变量对的互信息,生成叶子层隐变量。互信息计算模块20用于为所述每个数据拥有者在本地建立树状索引,将所述数据拥有者两两组合形成数据拥有者对,进行树状索引的匹配和叶子层隐变量之间的互信息的计算。隐树生成模块30用于为所述每个数据拥有者执行隐树结构学习和隐树参数学习,各自在本地生成一棵隐树。数据集生成模块40用于为所述每个数据拥有者根据学习到的隐树结构和隐树参数自顶向下生成目标数据集。
在上述实施例中,该数据集生成装置可以为多个,每个数据集生成装置对应一个数据拥有者的数据的处理,所有数据拥有者可通过网络进行连接。
本发明实施例还提供了另一种数据集生成装置。该装置可以为数据库、大数据平台、服务器等数据处理装置。需说明的是,虽然同样能用于实现满足差分隐私的垂直分割数据发布,但在本实施例中,其模块的名称以及功能划分与上述实施例中的模块不相同。如图5所示,具体地,在本实施例中各模块所实现的功能如下:
数据预处理模块50主要完成对原始数据的编码统计、数据清洗、缺失数据填充、离散化和二进制化等操作。数据预处理模块50可进一步具体包括数据编码子模块51、数据填充子模块52、离散化子模块53和二进制化子模块54。
具体地,数据编码子模块51用于完成对多个数据源编码的统一编码。数据填充子模块52用于完成对原始数据的清洗和填充。离散化子模块53用于将连续数据或离散的类型值映射为离散数字。二进制化子模块54用于将离散变量转化为取值0、1的二进制变量。
关联信息采集模块60用于为各个数据拥有者生成隐变量,以及构建树状索引,进行树状索引匹配。关联信息采集模块60可进一步具体包括隐变量生成子模块61、树状索引构建子模块62和树状索引匹配子模块63。
具体地,隐变量生成子模块61用于在满足差分隐私的条件下将显变量进行分组,对应生成叶子层隐变量。树状索引构建子模块62用于完成在满足差分隐私保护的条件下自底向上地构建树状索引结构。树状索引匹配子模块63通过对树状索引进行自顶向下地匹配,完成对要计算的隐变量对地剪枝,在计算隐变量关联强度的过程中减少通讯开销。
模型学习与构建模块70用于依据隐变量之间的互信息学习隐树模型。模型学习与构建模块70可进一步包括无环连通图构建子模块71、隐树结构学习子模块72、隐树参数学习子模块73。
具体地,无环连通图构建子模块71是以叶子层隐变量为节点,变量间互信息的大小作为连接边的权值,构建出权值和最小的无环连通图。隐树结构学习子模块72主要完成隐树结构的构建。隐树参数学习子模块73主要完成隐树结构中父子节点之间条件分布参数的学习。
数据发布模块80根据学习到的所述隐树结构和父子节点之间的条件分布参数,从根节点开始,自顶而下的生成合成数据集中的每一条记录。
需要说明的是,上述各个模块是可以通过软件或硬件来实现的,对于后者,可以通过以下方式实现,但不限于此:上述模块均位于同一处理器中;或者,上述模块分别位于多个处理器中。
实施例一
在本实施例中,以k家不同专科医院(k>=2)在各自设备上联合发布医疗数据为例进行详细描述:
实施环境说明:所述的k家不同专科医院作为k个数据拥有者,各自部署所述数据集生成装置(可以为数据库、大数据平台、服务器等),使用该装置进行满足差分隐私保护的数据集生成。
如图6所示,该实施例包括如下步骤:
步骤601、k家医院独立的对本地数据集进行统一编码、缺失数据填充、离散化、二进制化;存储原始数据集到二进制数据集的对应数位的转化关系。
步骤602、k家医院将显变量两两组合形成一组显变量对,访问数据计算出每对显变量之间的互信息;互信息的计算方法如下:
其中p(x)、p(y)分别为变量x、y取值x=x、y=y时的概率分布,p(x,y)是变量x取值x=x,且变量y取值y=y的联合概率分布。
步骤603、利用差分隐私指数机制,在满足差分隐私保护的条件下将本地显变量分组,每个分组包含显变量个数尽量达到但不超过预设的隐变量最大分组个数。
步骤604、对于每个本地显变量分组,为其生成隐变量,得到叶子层隐变量数据集。
步骤605、对于每家医院,将叶子层隐变量两两组合形成隐变量对,访问隐变量数据计算出每对隐变量之间的互信息;计算方法参照步骤502。
步骤606、基于计算出来的叶子层隐变量之间的互信息,对叶子层隐变量在满足差分隐私保护的条件下进行分组,生成上层隐变量。
步骤607、自底向上地重复上述由底层隐变量生成上层隐变量的步骤,直至上层隐变量只有一个隐变量节点,将该隐变量记为根节点;与父子节点之间的连接边,各个隐变量节点共同组成树状索引,存储在数据拥有者本地。
步骤608、各个医院两两组合形成数据拥有者对,然后各个数据拥有者传递协商相关参数,包括不限于数据拥有者组合配对情况、数据拥有者对后续计算的执行次序、单个数据拥有者同时可以通讯的其他数据拥有者最大数目等等。
步骤609、对于每对医院,共同运行安全多方计算协议,在安全多方计算协议加密的条件下运行基于树状索引匹配的两方隐变量互信息计算方法。对于每个医院,可以同时与多个其他医院进行通讯,同时进行上述计算。
步骤610、多个医院共同运行安全协议,在多方安全计算协议加密的条件下将之前计算到的隐变量对之间的互信息发送给其他医院;直至每个医院本地存储着相同而完备的叶子层隐变量对之间的关联强度。
步骤611、多个医院独立地在本地运行最大生成树构建方法,以叶子层隐变量和显变量为节点,计算到的变量之间的关联强度作为相应连接边的权值,构建权重和最小的无环连通图。
步骤612、随机为该无环连通图选择根节点,按照与根节点路径长度距离来为每一条连接边所连接的节点对确定父子关系,得到隐树结构。
步骤613、按照生成的隐树结构,自顶向下的为每一对相互连接的父子节点,运用拉普拉斯机制,在满足差分隐私保护的条件下计算出父子节点间的条件概率。
步骤614、计算根节点在原始数据集的概率分布,依据概率分布抽取根节点对应的生成数据集;然后自顶向下的逐层为每个节点依据父节点当前的生成数据,计算出父子节点的联合分布概率,依据联合分布概率和随机分布来为每个节点生成含噪声的数据。得到含有噪声的、满足差分隐私保护的生成数据集。
实施例二
在本实施例中,以k家金融机构(k>=2)联合发布一批满足差分隐私的用户的金融信息为例进行详细描述:
实施环境说明:所述的k家金融机构为拥有用户不同类型金融信息的机构,如拥有存款信息的银行、拥有股票信息的证券机构等。k家金融机构各自部署所述数据集生成装置(可以为数据库、大数据平台、服务器等),直接借助该装置进行满足差分隐私保护的数据发布工作。如图7所示,该实施例包括如下步骤:
步骤701、各家金融机构的主机通过网络向其他机构发送心跳信息,注册成为数据发布参与者。
步骤702、各家金融机构独立而随机的生成不重复整型数字作为唯一id,每家金融机构向下个金融机构发布本机所接收到心跳的源机数量和本机id,在所有金融机构均未检测到矛盾信息的情况下,数据发布流程开始。
步骤703、各家金融机构进行通讯,协商统一编码标准、隐私参数设定、变量分组最大个数、和离散化方法等参数配置,将协商后的参数配置广播给所有的数据发布参与者。
步骤704、各家金融机构从本地数据仓库中取出原始数据集,依次运行统一编码子模块、数据填充子模块、离散化子模块、二进制化子模块,得到规整的二进制显变量数据集。
步骤705、各家金融机构运行变量分组子模块,将显变量两两组合形成一组显变量对,访问数据仓库计算出每对显变量之间的互信息;利用差分隐私指数机制,在满足差分隐私保护的条件下对显变量进行分组。
步骤706、各家金融机构独立地运行隐变量生成子模块,利用拉格朗日乘子优化对显变量分布的极大似然估计,多次迭代直至生成的隐变量整体分布稳定。
步骤707、各家金融机构独立地运行树状索引构建子模块,生成隐变量索引树。
步骤708、各家金融机构运行完上述步骤之后,向其他金融机构发送心跳信息,宣布该机构已完成本地树状索引构建,等待其他机构完成数状索引的构建。
步骤709、在所有完后曾树状索引构建之后,多家金融机构两两组合形成金融机构对,相互广播多个金融机构对的计算次序和单个数据拥有者同时可以通讯的其他数据拥有者最大数目等参数,在所有金融机构通过网络确认相关次序以及参数之后,按协商的运算次序进行后续计算。
步骤710、对于每一对金融机构对,共同运行安全多方计算协议,在安全多方计算协议的加密下运行树状索引匹配子模块,在满足隐私保护的情况下计算隐变量之间的关联强度。
步骤711、各家金融机构运行完所有与自己相关的树状索引匹配之后,向其他金融机构发送心跳信息,宣布该机构已完成树状索引匹配,等待其他机构完成树状索引的匹配。
步骤712、各家金融机构共同运行安全协议,在多方安全计算协议加密的条件下将之前计算到的隐变量对之间的互信息广播给其他所有数据拥有者;直至每个数据拥有者本地存储着相同而完备的叶子层隐变量对之间的关联强度信息。
步骤713、各家金融机构独立地运行隐树结构学习子模块,采用最大生成树构建方法,以叶子层隐变量和显变量为节点,计算到的变量之间的关联强度作为相应连接边的权值,构建权重和最小的无环连通图。随机为该无环连通图选择根节点,按照与根节点路径长度距离来为每一条连接边所连接的节点对确定父子关系,得到隐树结构。
步骤714、各家金融机构独立地运行隐树参数学习子模块,按照生成的隐树结构,自顶向下的为每一对相互连接的父子节点,运用拉普拉斯机制,在满足差分隐私保护的条件下计算出父子节点间的条件概率。
步骤715、各家金融机构独立地运行数据生成子模块,计算根节点在原始数据集的概率分布,依据概率分布抽取根节点对应的生成数据集;然后自顶向下的逐层为每个节点依据父节点当前的生成数据,计算出父子节点的联合分布概率,依据联合分布概率和随机分布来为每个节点生成含噪声的数据。得到含有噪声的、满足差分隐私保护的生成数据集。
步骤716、各家金融机构在完成数据生成之后,向其他金融机构发送心跳信息,等待所有金融机构完成数据生成,对于无法完成数据生成的金融机构,向其广播生成的数据集。
实施例三
在本实施例中,某大型企业在内部多个部门间部署所述装置,来发布满足差分隐私保护的数据给运维和外包人员使用。
实施环境说明:企业内部不同部门具有同一批个体的不同层次的数据,数据位于各部门内部服务器的数据仓库上,与外网和其他部门网络隔离。在本实施中,各个数据集生成装置(可以为数据库、大数据平台、服务器等)通过企业内网相互通讯。如图8所示,本实施例包括如下步骤:
步骤801、部署于各个部门的数据集生成装置开放端口,监听来自外界的脱敏请求;每个数据源与一个数据集生成装置绑定。
步骤802、企业运维人员和外包人员向企业数据服务提供部门提交请求,请求得到来源于关于同一批用户的、属于不同部门的数据。
步骤803、数据服务提供部门对申请者进行鉴权,解析出请求的数据所属的数据源,向数据源绑定的数据集生成装置发送脱敏请求。
步骤804、涉及的多个数据集生成装置进行通讯,协商统一编码标准、隐私参数设定、变量分组最大个数、和离散化方法等参数配置,将协商后的参数配置广播给所有的数据发布参与者。
步骤805、各个装置调用本地数据仓库提供的内嵌udf(用户自定义函数)对原始数据进行编码转换、缺失数据填充、离散化、和二进制化,将结果存入临时表。
步骤806、各个装置运行变量分组子模块,将显变量两两组合形成一组显变量对,访问数据仓库计算出每对显变量之间的互信息;利用差分隐私指数机制,在满足差分隐私保护的条件下对显变量进行分组。
步骤807、各个装置独立地运行隐变量生成子模块,利用拉格朗日乘子优化对显变量分布的极大似然估计,多次迭代直至生成的隐变量整体分布稳定。
步骤808、各个装置独立地运行树状索引构建子模块,生成隐变量索引树。
步骤809、各个装置运行完上述步骤之后,向其他部门发送心跳信息,宣布该部门已完成本地树状索引构建,等待其他部门完成数状索引的构建。
步骤810、在所有部门完成树状索引构建之后,多各部门两两组合形成部门对,相互广播多个部门对的计算次序和单个数据拥有者同时可以通讯的其他数据拥有者最大数目等参数,在所有部门进行通讯确认相关次序以及参数之后,按协商的运算次序进行后续计算。
步骤811、对于每一对部门对,共同运行安全多方计算协议,在安全多方计算协议的加密下运行树状索引匹配子模块,在满足隐私保护的情况下计算隐变量之间的关联强度。
步骤812、各个装置运行完所有与自己相关的树状索引匹配之后,向其他装置发送心跳信息,宣布该装置已完成树状索引匹配,等待其他装置完成树状索引的匹配。
步骤813、各个装置共同运行安全协议,在多方安全计算协议加密的条件下将之前计算到的隐变量对之间的互信息广播给其他所有装置;直至每个装置本地存储着相同而完备的叶子层隐变量对之间的关联强度信息。
步骤814、各个装置独立地运行隐树结构学习子模块,采用最大生成树构建方法,以叶子层隐变量和显变量为节点,计算到的变量之间的关联强度作为相应连接边的权值,权重和最小的无环连通图。随机为该无环连通图选择根节点,按照与根节点路径长度距离来为每一条连接边所连接的节点对确定父子关系,得到隐树结构。
步骤815、各个装置独立地运行隐树参数学习子模块,按照生成的隐树结构,自顶向下的为每一对相互连接的父子节点,运用拉普拉斯机制,在满足差分隐私保护的条件下计算出父子节点间的条件概率;
步骤816、各个装置独立地运行数据生成子模块,计算根节点在原始数据集的概率分布,依据概率分布抽取根节点对应的生成数据集;然后自顶向下的逐层为每个节点依据父节点当前的生成数据,计算出父子节点的联合分布概率,依据联合分布概率和随机分布来为每个节点生成含噪声的数据,得到含有噪声的、满足差分隐私保护的生成数据集。
步骤817、各个装置在完成数据生成之后,向其他装置发送心跳消息,等待所有装置完成数据生成,对于无法完成数据生成的装置,向其广播生成的数据集。
步骤818、将生成的数据集在本地缓存,以备下次查询;任选一个装置,将生成的数据发送给数据服务提供部门。
步骤819、数据服务提供部门对数据进行验证后,将数据发送给数据请求者。
实施例四
在本实施例中,企业从多个渠道收集和购买同一批用户的不同方面的数据后,在存入数据仓库前先对数据进行脱敏,以规避数据买卖和数据收集可能带来的法律纠纷。
实施环境说明:来源于多个渠道的同一批用户的数据以数据流形式,进入前文实施例所述的数据集生成装置(可以为数据库、大数据平台、服务器等),由该装置对数据集进行脱敏之后,将满足差分隐私保护的数据集存入数据仓库。如图9所示,本实施例包括如下步骤:
步骤901、各个数据源与数据发布装置绑定,各个装置之间相互发送心跳信息确认装置运行状态良好,数据流正常。
步骤902、各个数据发布装置读入相同长度的数据流到内存;然后暂时封闭绑定的数据流的数据读入。
步骤903、各个装置对数据流进行完整性与合法性校验;如果出现异常数据则舍弃该批次数据,继续读入下批流数据。
步骤904、各个数据源相互通讯,根据数据流大小确定隐私参数大小和分配策略。
步骤905、各个装置依次运行统一编码子模块、数据填充子模块、离散化子模块、二进制化子模块,对存入内存的流数据进行预处理。
步骤906、各个装置运行变量分组子模块,将显变量两两组合形成一组显变量对,访问数据仓库计算出每对显变量之间的互信息;利用差分隐私指数机制,在满足差分隐私保护的条件下对显变量进行分组。
步骤907、各个装置独立地运行隐变量生成子模块,利用拉格朗日乘子优化对显变量分布的极大似然估计,多次迭代直至生成的隐变量整体分布稳定。
步骤908、各个装置独立地运行树状索引构建子模块,生成隐变量索引树。
步骤909、各个装置运行完上述步骤之后,向其他装置发送心跳信息,宣布该装置已完成本地树状索引构建,等待其他装置完成数状索引的构建。
步骤910、在所有装置完成树状索引构建之后,多个装置两两组合形成装置对,相互广播多个装置对的计算次序和单个装置同时可以通讯的其他装置最大数目等参数,在所有装置进行通讯确认相关次序以及参数之后,按协商的运算次序进行后续计算。
步骤911、对于每一对装置对,共同运行安全多方计算协议,在安全多方计算协议的加密下运行树状索引匹配子模块,在满足隐私保护的情况下计算隐变量之间的关联强度。
步骤912、各个装置运行完所有与自己相关的树状索引匹配之后,向其他装置发送心跳信息,宣布该装置已完成树状索引匹配,等待其他装置完成树状索引的匹配。
步骤913、各个装置共同运行安全协议,在多方安全计算协议加密的条件下将之前计算到的隐变量对之间的互信息广播给其他所有装置;直至每个装置本地存储着相同而完备的叶子层隐变量对之间的关联强度信息。
步骤914、各个装置独立地运行隐树结构学习子模块,采用最大生成树构建方法,以叶子层隐变量和显变量为节点,计算到的变量之间的关联强度作为相应连接边的权值,构建权重和最小的无环连通图。随机为该无环连通图选择根节点,按照与根节点路径长度距离来为每一条连接边所连接的节点对确定父子关系,得到隐树结构。
步骤915、各个装置独立地运行隐树参数学习子模块,按照生成的隐树结构,自顶向下的为每一对相互连接的父子节点,运用拉普拉斯机制,在满足差分隐私保护的条件下计算出父子节点间的条件概率。
步骤916、各个装置独立地运行数据生成子模块,计算根节点在原始数据集的概率分布,依据概率分布抽取根节点对应的生成数据集;然后自顶向下的逐层为每个节点依据父节点当前的生成数据,计算出父子节点的联合分布概率,依据联合分布概率和随机分布来为每个节点生成含噪声的数据。得到含有噪声的、满足差分隐私保护的生成数据集。
步骤917、各个装置在完成数据生成之后,向其他装置发送消息,宣布该装置已经完成数据生成,其他装置接收到数据生成完毕的消息后,立刻停止数据发布过程,以最大程度减少时间消耗。
步骤918、最先完成数据生成的装置对数据进行数据校验,然后存入数据仓库。
步骤919、各个装置继续从数据流中读入下批数据流,继续按照上述步骤在数据入库前进行脱敏。
本发明的实施例还提供了一种存储介质。在本实施例中,上述存储介质可以被设置为存储用于执行前文中实施例的步骤的程序代码。在本实施例中,上述存储介质可以包括不限于:u盘、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
显然,本领域的技术人员应该明白,上述的本发明的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,且在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本发明不限制于任何特定的硬件和软件结合。
以上所述仅为本发明的优选实施例而已,不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!