一种定位方法、装置及移动设备与流程
本申请涉及信息处理技术领域,尤其涉及一种定位方法、装置及移动设备。
背景技术:
随着配送行业的迅猛发展,无人配送技术也日益受到人们的关注。由于无人车、无人机或配送机器人等移动设备可对其周围环境进行感知,对行驶路径进行规划,因而用户可以根据实际环境选取相应的移动设备配送货物,进而可以解决偏远山区、交通拥堵的城市等环境货物配送难度大的问题。
上述移动设备在自动驾驶过程中,需要对自身进行准确地定位,以执行环境感知、路径规划等操作。而现有的定位方案,如基于视觉的即时定位与地图构建vslam技术等,通常需要基于每帧图像进行定位,且依赖从每帧图像中提取特征点后形成的庞大的特征点库,即定位的范围越大,所需特征点库的数据越多,进而导致定位方案可行性较低,且由于仅基于每帧图像进行定位,因而导致定位准确性也较低。
技术实现要素:
有鉴于此,本申请提供一种定位方法、装置及移动设备,可以提高定位方案的可行性,并提高定位的准确性。
具体地,本申请是通过如下技术方案实现的:
根据本申请的第一方面,提出了一种定位方法,包括:
获取移动设备在目标环境下采集的相邻两帧图像;
将所述两帧图像中后采集的图像输入到第一深度学习模型中,得到所述移动设备的第一定位结果,以及,基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果;
基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果。
在一实施例中,所述第一深度学习模型根据以下步骤训练得到:
获取目标环境的多帧样本图像;
确定每帧所述样本图像对应的定位结果;
将所述多帧样本图像以及每帧所述样本图像对应的定位结果作为训练集,训练第一深度学习模型。
在一实施例中,所述基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果,包括:
将所述两帧图像输入第二深度学习模型中,得到所述移动设备的动作预估结果;
基于所述动作预估结果和所述移动设备的上次综合定位结果,确定所述移动设备当前的第二定位结果。
在一实施例中,所述第二深度学习模型根据以下步骤训练得到:
获取移动设备采集的目标环境下的连续多帧样本图像;
确定所述多帧样本图像中每相邻两帧样本图像对应的动作预估结果;
将所述多帧样本图像以及所述每相邻两帧样本图像对应的动作预估结果作为训练集,训练第二深度学习模型。
在一实施例中,所述基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果,包括:
基于卡尔曼滤波原理,将所述第一定位结果与所述第二定位结果进行融合,得到所述移动设备的综合定位结果。
在一实施例中,所述基于卡尔曼滤波原理,将所述第一定位结果与所述第二定位结果进行融合,得到所述移动设备的综合定位结果,包括:
将用于表征所述第一定位结果的第一高斯分布参数和用于表征所述第二定位结果的第二高斯分布参数相乘,得到用于表征综合定位结果的最终高斯分布参数。
在一实施例中,所述第一定位结果包括六自由度的定位信息,所述第二定位结果包括所述六自由度的定位信息,所述综合定位结果包括所述六自由度的定位信息。
根据本申请的第二方面,提出了一种定位装置,包括:
相邻图像获取模块,用于获取移动设备在目标环境下采集的相邻两帧图像;
第一结果获取模块,用于将所述两帧图像中后采集的图像输入到第一深度学习模型中,得到所述移动设备的第一定位结果;以及,第二结果确定模块,用于基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果;
综合结果确定模块,用于基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果。
根据本申请的第三方面,提出了一种移动设备,包括:
处理器;
被配置为存储处理器可执行指令的存储器;
其中,所述处理器被配置为执行上述任一所述的定位方法。
根据本申请的第四方面,提出了一种计算机可读存储介质,所述存储介质存储有计算机器人机程序,所述计算机程序用于执行上述任一所述的定位方法。
由以上技术方案可见,本申请通过获取移动设备在目标环境下采集的相邻两帧图像,并将所述两帧图像中后采集的图像输入到第一深度学习模型中,得到所述移动设备的第一定位结果,以及,基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果,进而基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果,可以实现仅依赖于模型本身,而无需依赖于庞大的特征库进行定位,可以提高定位方案的可行性,并且,可以提高定位方案的准确性。
附图说明
图1是本申请一示例性实施例示出的一种定位方法的流程图;
图2是本申请又一示例性实施例示出的一种定位方法的流程图;
图3是本申请一示例性实施例示出的如何确定移动设备的第二定位结果的流程图;
图4是本申请又一示例性实施例示出的如何确定移动设备的第二定位结果的流程图;
图5是本申请一示例性实施例示出的一种定位装置的结构图;
图6是本申请又一示例性实施例示出的一种定位装置的结构图;
图7是本申请一示例性实施例示出的一种移动设备的结构图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本申请相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本申请的一些方面相一致的装置和方法的例子。
在本申请使用的术语是仅仅出于描述特定实施例的目的,而非旨在限制本申请。在本申请和所附权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其他含义。还应当理解,本文中使用的术语“和/或”是指并包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本申请可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本申请范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,如在此所使用的词语“如果”可以被解释成为“在......时”或“当......时”或“响应于确定”。本文所指“第二从pos终端”可以是一个、两个或多个从pos终端,“第二”不用于限定数量,仅用于与“第一”从pos终端作区分。
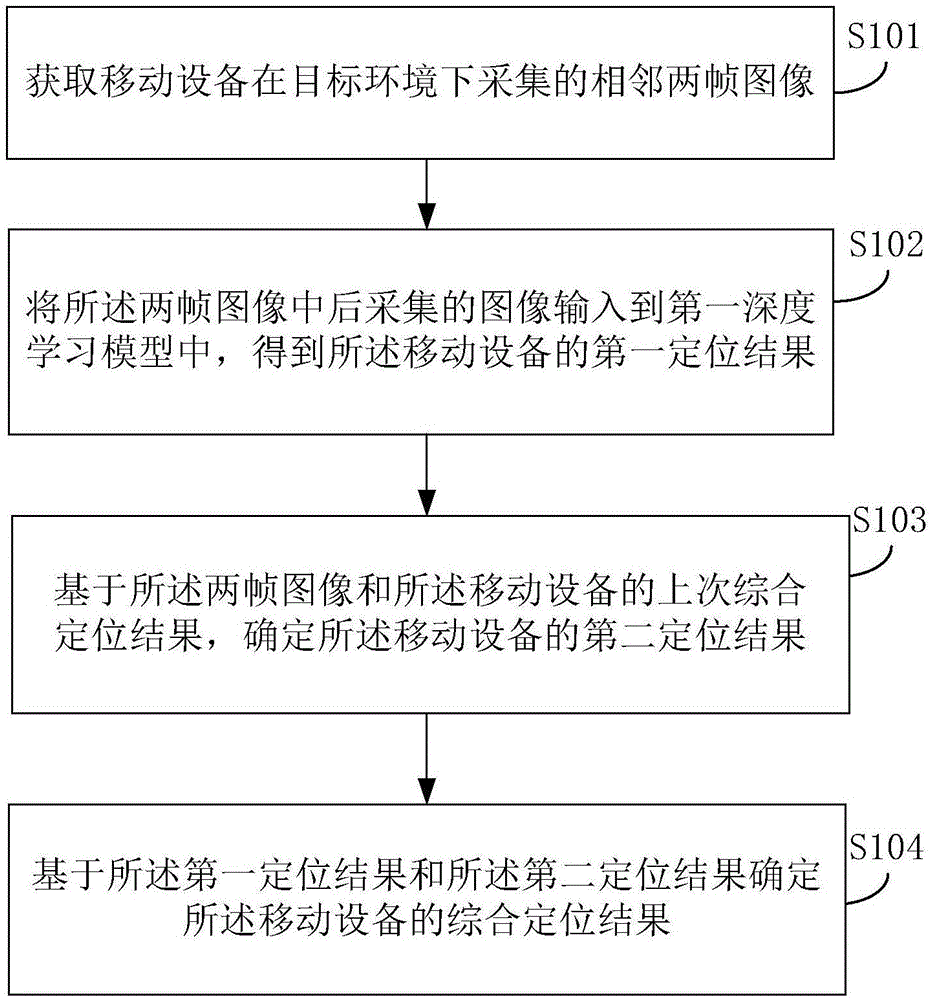
图1是本申请一示例性实施例示出的一种定位方法的流程图;该实施例可以用于移动设备,也可以用于服务端(例如,一台服务器和多台服务器组成的服务器集群等)。如图1所示,该方法包括步骤s101-s104:
s101:获取移动设备在行驶过程中采集的目标环境下的相邻两帧图像。
在一实施例中,上述移动设备可以包括但不限于无人车、无人机或配送机器人等。
在一实施例中,移动设备在目标环境中行驶时,可以通过自身携带的图像获取装置(如,摄像头等)实时采集目标环境下的视频图像。进一步地,该图像获取装置可以通过有线或无线的方式,将采集的视频图像中的相邻两帧图像发送给移动设备。
在一实施例中,若上述相邻两帧图像中,后采集的一帧图像为图像获取装置当前采集的图像,则下述步骤s104中得到的综合定位结果为移动设备当前的定位结果。
s102:将所述两帧图像中后采集的图像输入到基于视觉定位的第一深度学习模型中,得到所述移动设备的第一定位结果。
在一实施例中,当获取到上述相邻两帧图像后,可以将该两帧图像中后采集的图像输入到基于视觉定位的第一深度学习模型中,得到所述移动设备的第一定位结果。
在一实施例中,上述第一深度学习模型可以为预先训练的用于基于视觉定位的神经网络模型,其模型的输入为单帧图像,输出为移动设备的第一定位结果。
在一实施例中,上述第一深度学习模型的训练方式可以参见下述图2所示实施例,在此先不进行详述。
在一实施例中,上述第一定位结果可以包括移动设备的位置和姿态共六自由度的定位信息,即沿x、y、z三个直角坐标轴方向的移动自由度,以及绕这三个坐标轴的转动自由度以及每个自由度的相应误差。相应地,下述第二定位结果和综合定位结果也可以包括该六自由度的定位信息以及每个自由度的相应误差。
s103:基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果。
值得说明的是,上述步骤s102和步骤s103可以为并列关系,而非先后关系。
在一实施例中,可以在执行步骤s102的同时,根据上述两帧图像确定移动设备行驶动作预估结果,进而再结合移动设备的上次综合定位结果,得到移动设备的第二定位结果。举例来说,可以对上次综合定位结果和当前行驶动作预估结果求和,得出第二定位结果。
在一实施例中,上次综合定位结果可以为基于当前采集的图像的前一帧图像和再前一帧图像确定的移动设备的综合定位结果。
在一实施例中,确定移动设备的第二定位结果的方式还可以参见下述图3所示实施例,在此先不进行详述。
s104:基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果。
在一实施例中,当基于当前采集的图像得到第一定位结果,以及,基于上述相邻两帧图像得到第二定位结果后,可以基于第一定位结果和第二定位结果确定移动设备的综合定位结果。
在一实施例中,可以基于卡尔曼滤波原理,将所述第一定位结果与所述第二定位结果进行融合,得到所述移动设备的综合定位结果。
在一实施例中,上述的第一定位结果和第二定位结果本质上都是一个分布,可以抽象为高斯分布。以1个自由度举例,若一定位结果中包括“位移:1m”,则可以确定:较大概率(如60%)下,位移为1m;小概率(如30%)下,位移偏了10%,即位于0.9m或1.1m;更小的概率(如10%)下,位移偏了50%等,进而可将该高斯分布的均值确定为位移定位结果,方差确定为位移定位结果的误差。
同理,每一个行驶动作预估结果也可以抽象为一个高斯分布。以1个自由度举例,若以行驶动作预估结果中包括“位移变化:+1m”,则可以确定:较大概率(如60%)下,位移变化为+1m;小概率(如30%)下,位移变化偏了10%,即为+0.9m或+1.1m;更小的概率(如10%)下,位移变化偏了50%等,进而可将该高斯分布的均值确定为位移变化结果,方差确定为位移变化结果的误差。
在一实施例中,可以将用于表征所述第一定位结果的第一高斯分布参数和用于表征所述第二定位结果的第二高斯分布参数相乘,得到用于表征综合定位结果的最终高斯分布参数。举例来说,可以采用如下公式(1)、公式(2)计算用于表征综合定位结果的高斯分布参数:
上式中,μ1、σ1为表征第一定位结果的第一高斯分布参数,即第一高斯分布的均值和方差;μ2、σ2为表征所述第二定位结果的第一高斯分布参数,即第二高斯分布的均值和方差;μ、σ为表征综合定位结果的最终高斯分布参数,即最终高斯分布的均值和方差。
显然,σ小于σ1和σ2,即降低了综合定位结果的误差,提高了定位的准确性。
由上述描述可知,本实施例通过获取移动设备在行驶过程中采集的目标环境下的相邻两帧图像,并将所述两帧图像中后采集的图像输入到基于视觉定位的第一深度学习模型中,得到所述移动设备的第一定位结果,以及,基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果,进而基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果,由于基于第一深度学习模型对移动设备进行定位,可以实现仅依赖于模型本身,而无需依赖于庞大的特征库进行定位,可以提高定位方案的可行性,并且,由于基于移动设备行驶过程中采集的相邻两帧图像得到移动设备的第二定位结果,进而根据第一定位结果和第二定位结果确定移动设备的综合定位结果,既考虑了每帧图像的定位结果,又考虑了相邻两帧图像的动作变化,因而可以提高定位方案的准确性。
此外,本实施例不需要依赖惯性测量单元imu和gps等设备,仅需图像采集装置即可实施,因而可以降低系统的成本。
图2是本申请又一示例性实施例示出的一种定位方法的流程图;该实施例可以用于移动设备,也可以用于服务端(例如,一台服务器和多台服务器组成的服务器集群等)。如图2所示,该方法包括步骤s201-s207:
s201:获取目标环境的多帧样本图像。
在一实施例中,为了训练基于视觉定位的第一深度学习模型,可以针对目标环境中的不同位置和方向获取多帧样本图像。
在一实施例中,上述目标环境可以由开发人员根据实际配送业务的需要进行选取,例如可以选取配送业务所在的国家、省份、城市或乡镇等,本实施例对此不进行限定。
s202:确定每帧所述样本图像对应的定位结果。
在一实施例中,当获取目标环境的多帧样本图像后,可以对每帧样本图像进行标定,以确定每帧样本图像对应的定位结果。例如,确定每帧样本图像对应的位置和方向。
在一实施例中,可以确定每帧样本图像对应的六自由度的定位结果,即沿x、y、z三个直角坐标轴方向的移动自由度,以及绕这三个坐标轴的转动自由度。
s203:将所述多帧样本图像以及每帧所述样本图像对应的定位结果作为训练集,训练第一深度学习模型。
在一实施例中,当得到上述多帧样本图像以及每帧样本图像对应的定位结果后,可以将所述多帧样本图像以及每帧所述样本图像对应的定位结果作为训练集,训练第一深度学习模型。
在一实施例中,上述第一深度学习模型可以为卷积神经网络cnn模型,也可以由开发人员根据实际业务需要选取其他模型进行训练,本实施例对此不进行限定。
值得说明的是,上述第一深度学习模型的训练过程中虽然也需要较多的样本数据,但是模型训练好后就不再需要上述样本数据了,只保留训练好的模型即可,模型本身记住训练信息,且模型的大小是固定的,不会随着待定位的范围变大而变大,即无需依赖于庞大的特征库进行定位,可以提高定位方案的可行性。
s204:获取移动设备在行驶过程中采集的目标环境下的相邻两帧图像。
s205:将所述两帧图像中后采集的图像输入到基于视觉定位的第一深度学习模型中,得到所述移动设备的第一定位结果;以及,基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果。
s206:基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果。
其中,步骤s204-s206的相关解释和说明可以参见上述实施例,在此不进行赘述。
由上述描述可知,本实施例通过获取目标环境的多帧样本图像,并确定每帧所述样本图像对应的定位结果,进而将所述多帧样本图像以及每帧所述样本图像对应的定位结果作为训练集,训练第一深度学习模型,可以实现后续基于第一深度学习模型确定移动设备的第一定位结果,由于模型训练好后就不再需要样本数据,只保留训练好的模型即可,模型大小不会随着待定位的范围变大而变大,因而可以不依赖于庞大的特征库进行定位,提高定位方案的可行性。
图3是本申请一示例性实施例示出的如何确定移动设备的第二定位结果的流程图;本实施例在上述实施例的基础上,以如何确定移动设备的第二定位结果为例进行示例性说明。如图3所示,步骤s103中所述基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果,可以包括以下步骤s301-s302:
s301:将所述两帧图像输入基于视觉预估动作的第二深度学习模型中,得到所述移动设备的行驶动作预估结果。
在一实施例中,可以预先训练用于基于视觉预估动作的第二深度学习模型,该模型的输入可以为移动设备自动驾驶过程中采集的相邻两帧图像,输出为移动设备的行驶动作预估结果。
在一实施例中,上述第二深度学习模型的训练过程可以参见下述图4所示实施例,在此先不进行详述。
在一实施例中,当获取到移动设备自动驾驶过程中采集的相邻两帧图像后,可以将这两帧图像输入到基于视觉预估动作的第二深度学习模型中,得到所述移动设备的行驶动作预估结果。
在一实施例中,上述行驶动作预估结果例如为“位移变化:+2m;方向变化:+10°”(这里仍以2自由度为例,实际上可以沿用至6自由度)。
s302:基于所述行驶动作预估结果和所述移动设备的上次综合定位结果,确定所述移动设备当前的第二定位结果。
在一实施例中,上次综合定位结果可以为基于当前采集的图像的前一帧图像和再前一帧图像确定的移动设备的综合定位结果。举例来说,若基于上述前一帧图像和再前一帧图像确定的上次综合定位结果为“位移:3m;方向:10°”(为了方便说明,这里以2自由度为例,实际上可以沿用至6自由度),则移动设备可以根据当前采集的图像和前一帧图像计算出当前采集的图像相对于前一帧图像的行驶动作预估结果,如算出“位移变化:+2m;方向变化:+10°”(这里仍以2自由度为例,实际上可以沿用至6自由度),因而可以对上次综合定位结果和当前行驶动作预估结果求和,得出第二定位结果为“位移:5m;方向:20°”。
由上述描述可知,本实施例通过将所述两帧图像输入基于视觉预估动作的第二深度学习模型中,得到所述移动设备的行驶动作预估结果,并基于所述行驶动作预估结果和所述移动设备的上次综合定位结果,确定所述移动设备当前的第二定位结果,由于基于移动设备行驶过程中采集的相邻两帧图像得到移动设备的第二定位结果,进而可以实现后续根据第一定位结果和第二定位结果确定移动设备的综合定位结果,既考虑了每帧图像的定位结果,又考虑了相邻两帧图像的动作变化,因而可以提高定位方案的准确性。
图4是本申请又一示例性实施例示出的如何确定移动设备的第二定位结果的流程图;本实施例在上述实施例的基础上,以如何确定移动设备的第二定位结果为例进行示例性说明。如图4所示,步骤s103中所述基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果,可以包括以下步骤s401-s405:
s401:获取移动设备在行驶过程中采集的目标环境下的连续多帧样本图像。
在一实施例中,为了训练基于视觉预估动作的第二深度学习模型,可以当移动设备在目标环境的不同位置和方向上行驶过程时获取连续多帧样本图像,如视频图像。
在一实施例中,上述目标环境可以由开发人员根据实际配送业务的需要进行选取,例如可以选取配送业务所在的国家、省份、城市或乡镇等,本实施例对此不进行限定。
在一实施例中,上述移动设备可以为本申请实施例中待定位的移动设备,如无人车、无人机或配送机器人等。由于每个移动设备具有各自的行驶特点,因而利用该移动设备在行驶过程中采集的目标环境的连续多帧样本图像来训练第二深度学习模型,可以提高模型的针对性,保证模型预估动作的准确性。
s402:确定所述多帧样本图像中每相邻两帧样本图像对应的动作预估结果。
在一实施例中,当获取上述多帧样本图像后,可以对每相邻两帧样本图像进行标定,以确定每相邻两帧样本图像对应的动作预估结果。例如,确定每相邻两帧样本图像对应的位置改变量和方向改变量。
在一实施例中,可以确定每相邻两帧样本图像对应的六自由度的动作预估结果,即沿x、y、z三个直角坐标轴方向的移动自由度改变量,以及绕这三个坐标轴的转动自由度改变量。
s403:将所述多帧样本图像以及所述每相邻两帧样本图像对应的动作预估结果作为训练集,训练第二深度学习模型。
在一实施例中,当得到上述多帧样本图像以及所述每相邻两帧样本图像对应的动作预估结果后,可以所述多帧样本图像以及所述每相邻两帧样本图像对应的动作预估结果作为训练集,训练第二深度学习模型。
在一实施例中,上述第二深度学习模型可以为卷积神经网络cnn模型,也可以由开发人员根据实际业务需要选取其他模型进行训练,本实施例对此不进行限定。
值得说明的是,上述第二深度学习模型的训练过程中虽然也需要较多的样本数据,但是模型训练好后就不再需要上述样本数据了,只保留训练好的模型即可,模型本身记住训练信息,且模型的大小是固定的,不会随着待环境范围变大而变大,即无需依赖于庞大的特征库进行动作预估,可以提高动作预估方案的可行性。
s404:将所述两帧图像输入基于视觉预估动作的第二深度学习模型中,得到所述移动设备的行驶动作预估结果。
s405:基于所述行驶动作预估结果和所述移动设备的上次综合定位结果,确定所述移动设备当前的第二定位结果。
其中,步骤s404-s405的相关解释和说明可以参见上述实施例,在此不进行赘述。
由上述描述可知,本实施例通过获取移动设备在行驶过程中采集的目标环境下的连续多帧样本图像,并确定所述多帧样本图像中每相邻两帧样本图像对应的动作预估结果,进而将所述多帧样本图像以及所述每相邻两帧样本图像对应的动作预估结果作为训练集,训练第二深度学习模型,可以实现后续基于第二深度学习模型确定移动设备的行驶动作预估结果,由于模型训练好后就不再需要样本数据,只保留训练好的模型即可,模型大小不会随着环境范围变大而变大,因而可以不依赖于庞大的特征库进行动作预估,提高动作预估方案的可行性。
与前述方法实施例相对应,本申请还提供了相应的装置的实施例。
图5是本申请一示例性实施例示出的一种定位装置的结构图;如图5所示,该装置包括:相邻图像获取模块110、第一结果获取模块120、第二结果确定模块130以及综合结果确定模块140,其中:
相邻图像获取模块110,用于获取移动设备在行驶过程中采集的目标环境下的相邻两帧图像;
第一结果获取模块120,用于将所述两帧图像中后采集的图像输入到基于视觉定位的第一深度学习模型中,得到所述移动设备的第一定位结果;
第二结果确定模块130,用于基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果;
综合结果确定模块140,用于基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果。
由上述描述可知,本实施例通过获取移动设备在行驶过程中采集的目标环境下的相邻两帧图像,并将所述两帧图像中后采集的图像输入到基于视觉定位的第一深度学习模型中,得到所述移动设备的第一定位结果,以及,基于所述两帧图像和所述移动设备的上次综合定位结果,确定所述移动设备的第二定位结果,进而基于所述第一定位结果和所述第二定位结果确定所述移动设备的综合定位结果,由于基于第一深度学习模型对移动设备进行定位,可以实现仅依赖于模型本身,而无需依赖于庞大的特征库进行定位,可以提高定位方案的可行性,并且,由于基于移动设备行驶过程中采集的相邻两帧图像得到移动设备的第二定位结果,进而根据第一定位结果和第二定位结果确定移动设备的综合定位结果,既考虑了每帧图像的定位结果,又考虑了相邻两帧图像的动作变化,因而可以提高定位方案的准确性。此外,本实施例不需要依赖惯性测量单元imu和gps等设备,仅需图像采集装置即可实施,因而可以降低系统的成本。
图6是本申请又一示例性实施例示出的一种定位装置的结构图。其中,相邻图像获取模块230、第一结果获取模块240、第二结果确定模块250以及综合结果确定模块260与前述图5所示实施例中的相邻图像获取模块110、第一结果获取模块120、第二结果确定模块130以及综合结果确定模块140的功能相同,在此不进行赘述。如图6所示,所述装置还可以包括第一模型训练模块210,用于训练基于视觉定位的第一深度学习模型;
第一模型训练模块210可以包括:
第一样本获取单元211,用于获取目标环境的多帧样本图像;
定位结果确定单元212,用于确定每帧所述样本图像对应的定位结果;
第一模型训练单元213,用于将所述多帧样本图像以及每帧所述样本图像对应的定位结果作为训练集,训练第一深度学习模型。
在一实施例中,第二结果确定模块250可以包括:
行驶动作预估单元251,用于将所述两帧图像输入基于视觉预估动作的第二深度学习模型中,得到所述移动设备的行驶动作预估结果;
第二结果获取单元252,用于基于所述行驶动作预估结果和所述移动设备的上次综合定位结果,确定所述移动设备当前的第二定位结果。
在一实施例中,装置还可以包括第二模型训练模块220,用于训练基于视觉预估动作的第二深度学习模型;
第二模型训练模块220可以包括:
第二样本获取单元221,用于获取移动设备在行驶过程中采集的目标环境下的连续多帧样本图像;
预估结果确定单元222,用于确定所述多帧样本图像中每相邻两帧样本图像对应的动作预估结果;
第二模型训练单元223,用于将所述多帧样本图像以及所述每相邻两帧样本图像对应的动作预估结果作为训练集,训练第二深度学习模型。
在一实施例中,综合结果确定模块260还可以包括:
定位结果融合单元261,用于基于卡尔曼滤波原理,将所述第一定位结果与所述第二定位结果进行融合,得到所述移动设备的综合定位结果。
在一实施例中,定位结果融合单元261还可以用于将用于表征所述第一定位结果的第一高斯分布参数和用于表征所述第二定位结果的第二高斯分布参数相乘,得到用于表征综合定位结果的最终高斯分布参数。
在一实施例中,所述第一定位结果可以包括六自由度的定位信息,所述第二定位结果可以包括所述六自由度的定位信息,所述综合定位结果可以包括所述六自由度的定位信息。
值得说明的是,上述所有可选技术方案,可以采用任意结合形成本公开的可选实施例,在此不再一一赘述。
本发明的定位装置的实施例可以应用在网络设备上。装置实施例可以通过软件实现,也可以通过硬件或者软硬件结合的方式实现。以软件实现为例,作为一个逻辑意义上的装置,是通过其所在设备的处理器将非易失性存储器中对应的计算机程序指令读取到内存中运行形成的,其中计算机程序用于执行上述图1~图4所示实施例提供的定位方法。从硬件层面而言,如图7所示,为本发明的定位设备的硬件结构图,除了图7所示的处理器、网络接口、内存以及非易失性存储器之外,所述设备通常还可以包括其他硬件,如负责处理报文的转发芯片等等;从硬件结构上来讲该设备还可能是分布式的设备,可能包括多个接口卡,以便在硬件层面进行报文处理的扩展。另一方面,本申请还提供了一种计算机可读存储介质,存储介质存储有计算机程序,计算机程序用于执行上述图1~图4所示实施例提供的定位方法。
对于装置实施例而言,由于其基本对应于方法实施例,所以相关之处参见方法实施例的部分说明即可。以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本申请方案的目的。本领域普通技术人员在不付出创造性劳动的情况下,即可以理解并实施。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本申请的其它实施方案。本申请旨在涵盖本申请的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本申请的一般性原理并包括本申请未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本申请的真正范围和精神由下面的权利要求指出。
还需要说明的是,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、商品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、商品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个......”限定的要素,并不排除在包括所述要素的过程、方法、商品或者设备中还存在另外的相同要素。
以上所述仅为本申请的较佳实施例而已,并不用以限制本申请,凡在本申请的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本申请保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!