最优排序键压缩和索引重建的制作方法
在为数据库表维护索引且索引键由表的一列或多列构成的情况下,可能存在某时间点,该时间点时索引由于某种原因丢失或以其他方式不可用。在这样的实例中,将需要重建索引。为了准确地重建索引,索引键应以键值的顺序而排序。重建数据库表索引的一个考虑可能是,对于正确地排序索引键,要保留的最小信息(例如,索引键中的位数)是什么。此最小信息对于确定索引键的正确排序的顺序应是充分的,从该顺序可以重建索引。
在包含数据库复制的一些情况下,主服务器中创建的索引应反映在其他副本中。完成此任务的一种方法是在网络上将索引图像发送到其他副本。然而,此方法引起网络开支,其可能是复制系统的性能瓶颈。另一种索引复制方法可以包含索引创建在副本中的重演,以避免网络开支。一些其他途径可能通过试图确定是否存在可能用来降低副本中的索引创建的成本的一些信息而寻求索引复制或重建上的改善。
在一些背景下,可能存在对在保留系统资源的同时更高效地进行索引重建操作的期望。
附图说明
图1a-1b是索引位的示意性图示;
图2a-2c是索引键值的示例性二进制表示的示意性图示;
图3a-3b是示例性索引键的示意性图示;
图4a-4e是索引树的示意性图示;并且
图5是索引重建过程的示意性图示;
图6是根据一些实施例的示例性数据格式化和处理的示意性图示;并且
图7是根据一些实施例的示例性系统的框图。
具体实施方式
提供以下描述,使任何本领域技术人员能够制造和使用所描述的实施例。然而,各种修改对本领域技术人员将仍是显而易见的。
常规数据库将索引视作持久的结构,并且因此任何索引更新引起运行时磁盘i/o(输入/输出),以写入到持久的更新日志和索引节点页。对于存储器内数据库,可能使用维护存储器内(即,非持久)索引结构的不同途径。更新事务可以例如从此途径受益,因为其消除了与索引更新相关联的运行时磁盘i/o。然而,此途径引起在数据库恢复期间构建索引的成本。本公开提供了系统和方法,其可以显著降低在数据库恢复期间的索引重建的成本。申请人已经认识到(例如,经由实验),使用如本文中所公开的多核心cpu方法和系统的并行索引重建比例如将磁盘驻留的索引图像载入到存储器更快。
本公开包含若干技术创新。本文中,索引键的“区别位”示出为正确地排序索引键所需的最小信息(即,对于确定索引键的正确顺序必要且充分的)。在一个实施例中,其他公开的方面包含仅储存索引键的区别位的排序键压缩方案。此排序键压缩方案提供一种机制,其对于降低重建索引的成本可以是有用的。在区别位是准确地确定索引键的顺序所需和所用的最小可能信息的意义上,本文公开的键压缩方案可以认为是最优的。
在一些实施例中,本文中的键压缩方案的压缩比可以取决于相关联的数据集的特性而变化。申请人已经认识到约2.4∶1至约5∶1的样本数据集的压缩比,其导致在大规模索引的重建期间的显著的存储器空间节省和性能改善。本文公开的排序键压缩可以认为是轻量化方案(例如,要保留的信息量小且从键提取最小位数的成本低)。然而,其在存储器空间节省和性能改善上的益处是显著的。此外,所公开的排序键压缩方案可以在各种不同的应用中使用,包含用比字大小更长的排序键来排序。
在一些实施例中,数据库表的索引键可以短至4字节,但它们在一些商业应用中可能长于30字节。因此,索引树和全部相关算法(例如,排序索引键、构建索引、用查询键来搜索,等等)应能够处理长键以及短键。本文中的排序键压缩和索引重建过程承担此宽范围的索引键大小。在一些实施例中,本文中的排序键压缩方案可以应用于商用存储器内dbms中的索引树。
在一些实施例中,为了加速索引重建过程,可以在从db(数据库)表即时(on-the-fly)在四个阶段中构建索引树中采用多核心处理并行性,四个阶段为:
1.将db表的数据页平均地分布到可用核心。
2.每个核心从数据页提取压缩的键(区别位)。
3.通过并行排序算法来排序压缩的键,该并行排序算法在本文中称为行-列排序。
4.并行地构建索引树。
使用来自tpc-e基准的多种db表和存储器内数据库系统中的一个db表,申请人观察到,对四个数据集平均,本文中的排序键压缩方案的约3.7∶1的压缩比。还观察到,对四个数据集平均,本文公开的键压缩方案将索引重建的时间缩短约40%。对于一个数据集,使用16个核心从db表即时构建索引树的时间为1.76秒。考虑到此索引树的图像为6.74gb,根据本公开的并行索引构建的运行时间远快于仅将索引图像载入到存储器,其对于200mb/秒磁盘i/o消耗33.7秒,并且对于550mb/秒ssd消耗12.3秒。
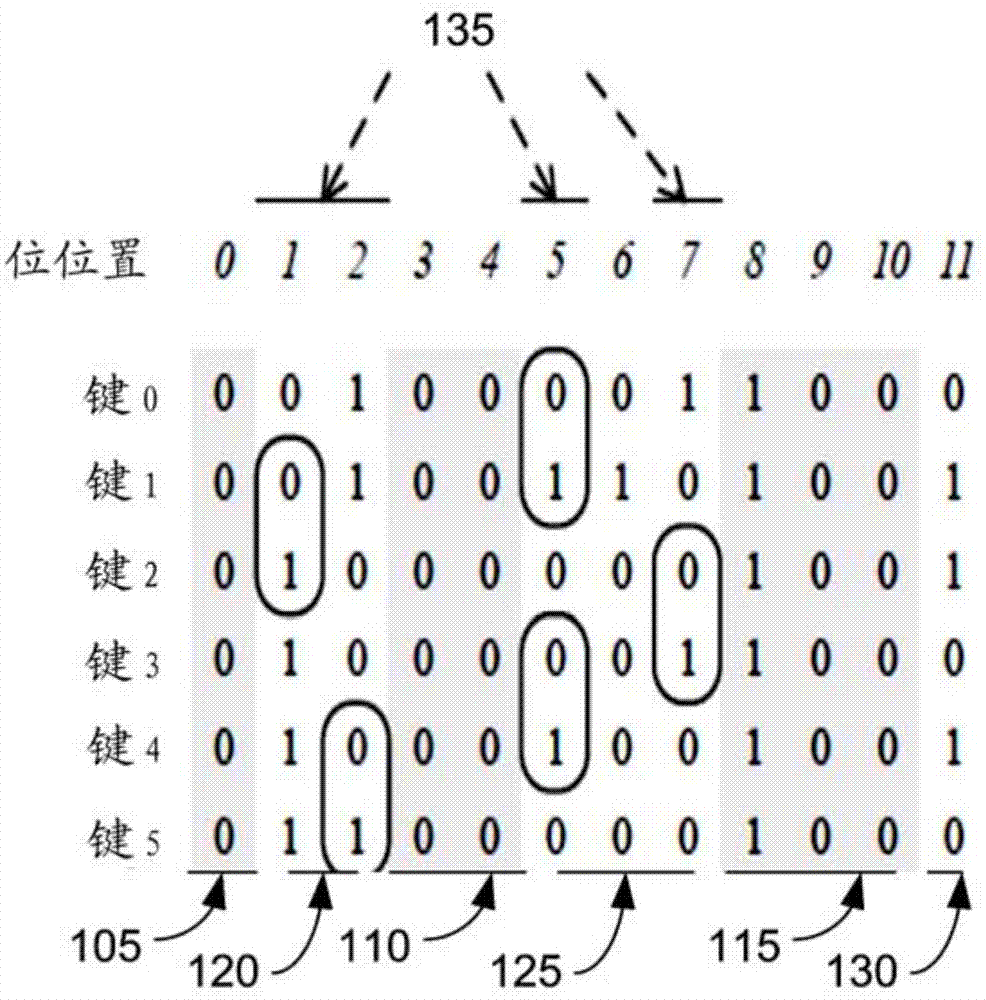
在详细描述排序键压缩方案之前,首先介绍一些术语。全部键值相同处的位位置称为不变位位置,并且这些位置中的位称为不变位。其他位位置称为可变位位置,并且位自身称为可变位。图1a中的每行表示索引键值。在图1a中,位位置0(105);3,4,5(110);以及8,9,10(115)是不变位位置,并且位位置1,2(120);5,6,7(125);以及11(130)是可变位位置。
使键i为以字母顺序的第i键值,即,键0<键1<···<键n。两个键(键i和键j)不同的最高位位置称为两个键的区别位位置,由d-位(键i,键j)指代,并且位自身称为“区别位”。对于1≤i≤n,使di=d-位(键i-1,键i)即,以字母顺序的两个相邻键的区别位位置。引理1表明,对于1≤i≤n,全部可能的键对的n(n+1)/2区别位位置可以由n个区别位位置di表征,其在本文中的排序键压缩方案中是关键事实。
引理1.对于0≤i<j≤n,d-位(键i,键j)=mini<k≤jdk。
我们通过在d=j-i上归纳来证明。当d=1时,引理平凡地成立。为了归纳假说,假设引理对d≥1成立。我们现在对于d+1证明引理。使d=mini<k≤j-1dk。由于(j-1)-i=d,通过归纳假说,d-位(键i,键j-1)=d。考虑d和dj。
如果d>dj,则dj为d-位(键i,键j)且dj=mini<k≤jdk。
如果d<dj,则d为d-位(键i,键j)且d=mini<k≤jdk。
注意到,d不能等于dj,因为我们在位位置中仅有两种可能,0和1。例如,在图1a中,d-位(键0,键2)=1,因为d1=5>d2=1,并且d-位(键1,键3)=1,因为d2=1<d3=7。
通过引理1,全部键的全部可能的区别位位置为di,1≤i≤n。在图1a中,位位置1、2、5以及7为区别位位置135,因为d1=5,d2=1,等等。可见,区别位位置是可变位位置。然而,可以存在不是区别位位置的可变位位置。在图1a中,位位置6和11是这样的位置(即,可变位位置,但不是区别位位置)。
为了在我们的索引树中定义部分键,给定参数p。如本文中所称的,键i的部分键是区别位位置di后面的p位。在图1a中,由于d1=5,当p=4时,键1的部分键是1010。
在上述定义的情况下,为了进一步解释本文中的键压缩,使压缩(键i)为键i在区别位位置中的位的级联。本文中,如图1b中所示,我们将区别位片(或d-位片)定义为全部键的压缩(键i)的合集。区别位片150是压缩(键i)的合集,但不一定由压缩(键i)排序。
定理1.区别位片对于确定键的字母顺序是必要且充分的。
对于充分性,我们证明以下关系成立:对于全部i和j,当且仅当压缩(键i)<压缩(键j)时,键i<键j。使d=d-位(键i,键j)。由于键i和键j的第一d位是相同的,由位位置d中的位确定键i和键j的顺序。通过引理1,位位置d中的位在压缩中(并且因此在区别位片中)。因此,键i与键j之间的顺序与压缩(键i)与压缩(键j)之间的顺序相同。
由于上述关系,可以由压缩来正确地确定键的字母顺序。
在一些方面中,易于得到示例,其中如果区别位片的任何位位置缺失,则无法正确地确定键的字母顺序。
定理1意味着,区别位片是正确地确定键的字母顺序的最小可能信息。
d’-位片在本文中定义为索引键在全部区别位位置中的和在零个或更多个其他位位置中的位。使压缩t(键i)为键i在d’-位片t中的位。在图1a-1b中,全部键在位位置1、2、5、6以及7中的位产生示例性d’-位片。
定理2.d’-位片t可以正确地确定键的字母顺序。
如在定理1的证明中,我们可以示出,对于全部i和j当且仅当压缩t(键i)<压缩t(键j)时,键i<键j。
在一些方面中,当我们维护db表的索引时,可以由数据库操作插入、删除或更新索引键。在这样的情况下,区别位位置可以在运行时改变。例如,如果键3在图1a中被删除,位置7不再是区别位位置,并且其变成可变位位置。如果除键3之外删除键0,区别位位置不改变,但位置7变成不变位位置。作为其他示例,如果插入索引键,则可以添加新的区别位位置。
在一些方面中,当存在许多插入、删除以及更新操作时,精确地在运行时维护区别位位置可能相当昂贵。定理2使得维护区别位位置比定理1远更容易,因为除区别位位置之外,可以准许一些其他位位置,而不影响算法的正确性。即使区别位位置完全未知,我们由定理2可以将全部可变位用作d’-位片。(在一些实施例中,我们将在运行时使用d’-位片并且作为批处理或在背景操作中计算d-位片)。
b+树及其变体在现代dbms中广泛用作索引,以允许用搜索键对数据快速存取。如果在表的列a1,…,ak上定义索引,其键可以表示为(a1,…,ak)形式的列值的元组。元组的排序是字母排序。例如,当k=2时,如以下来确定两个元组(a1,a2)和(b1,b2)的顺序:如果a1<b1或(a1=b1且a2<b2),则(a1,a2)<(b1,b2)。
我们现在下面描述如何从列值的元组产生实际的索引键,从而保持元组的字母顺序。索引的叶节点含有索引键并记录表的id。以下公开首先解释如何从不同的数据类型产生索引键,并且然后解释如何从多个列产生索引键。
对于每种数据类型(例如,整数、小数、浮点、串,等等),定义其索引键格式,使得索引键格式中的字母顺序二进制比较对应于原始数据值的比较。
对于整数,有符号的整数值域被映射到无符号的整数值域。例如,如果有符号的整数使用二进制补码,我们简单地翻转有符号的整数的最高位。然后如图2a中所示,有符号的整数被映射到无符号的整数值域,无符号的整数值域处映射的数的顺序对应于有符号的整数的顺序。
对于小数,小数x由1b数据头(header)和小数部分表示。数据头的最后的位是小数(1代表正)的符号,并且倒数第二位指示条目是否是空值(null)(0代表空值)。小数部分含有对应于「log2(x+1)/81个字节中的x的二进制数。小数点的位置储存在列的元数据中。对于映射,如果符号位是0,则翻转小数部分的全部位;否则,不作为。则,映射的值的顺序对应于小数的顺序。见图2b,其中小数(m,n)意味着m个总位数,其中n位在小数点右边。
对于浮点数,有符号的浮点域被映射到无符号的整数域。例如,假定浮点数表示为符号位、指数以及有效数。如果符号位为0,则将其翻转;否则,翻转全部位。则,所映射的数的顺序对应于有符号的浮点数的顺序,如图2c中所见。
对于固定的串,按原样使用固定大小的串。
对于具有最大长度的可变大小的串,假定空值字符(即,
在每种数据类型中,可以由两个索引键的字母顺序二进制比较确定两个索引键之间的顺序。
现将解释如何从多个列产生索引键。多个列上的索引键定义为来自多个列的索引键的级联。例如,假定在以下五列上定义索引键:part(int)、name(varchar(30))、xxx(int)、yyy(int)以及zzz(varchar(15))。图3a中在表300中示出了一些行中的示例性列值,并且图3b中是三行的索引键。
在这些完整索引键上定义如上所述的区别位位置。如果索引列的数据类型具有固定的长度(例如,整数、小数、浮点以及固定大小的串),则列值在索引键中对齐并且由列值的字母顺序确定索引键之间的顺序。
然而,如图3b中所示,如果索引列的数据类型具有可变的长度(例如,可变大小的串),则列值在索引键中可能不对齐。仍然,在这些完整索引键上定义区别位位置。如果两个行在列中具有不同长度的可变大小的串(如图3b中所示,它们可以具有相同值的之前的列),则区别位位置发生在如上所述的列中,并且由该列中的可变大小的串的字母顺序确定两个索引键之间的顺序。
为了比较两个索引键,进行两个键的二进制比较(通过字大小)。如果一个索引键更短,则在二进制比较中将其用0填充。注意,填充的值不影响两个键的顺序。以此方式,在从多个列衍生的完整索引键上定义区别位和区别位位置。
在一些实施例中,本文公开的排序键压缩方案可以应用于商用存储器内dbms中的索引树,虽然其可以与b+树索引结构的任何变体一起工作。图4a绘示了与本文中的一些实施例兼容的示例性索引树400的结构。索引树的叶节点(例如,图d)含有条目的列表,每个索引键一个,加上去往下一节点的指针。叶节点条目(图4e)由部分键值、区别位位置、索引键长度以及记录id构成。存在记录读取器,其将记录id获取为输入并返回对应于记录id的完整索引键。叶节点的数据头405含有去往该叶节点中的条目的最后的索引键的指针。非叶节点(图4b)含有条目的列表加上去往下一节点的指针。非叶节点条目(4c)由部分键、区别位位置、索引键长度、去往对应于条目的子节点的指针、以及去往子代(child)的后代(descendant)叶中的最后的索引键的指针构成,其中部分键和索引键长度是最后的完整索引键的部分键和长度,并且区别位位置是最后的完整索引键针对之前的条目的最后的完整索引键的位置。
另外,维护(即,保存)每个索引树的以下信息,其在本文中称为ds-info,其中ds代表d-位片。
d’位图:本文中的压缩方案需要区别位位置,其可以由位图表示。位图中的每位的位置表示完整索引键中的位置,其中值0意味着位位置不是区别位位置,并且值1意味着其可能是区别位位置。
可变位图:可变位位置储存在位图中,其中位位置中的值0意味着位位置不是可变位位置,并且值1意味着其可能是可变位位置。
参考键值:为不变位维护参考键值,其可以是任意索引键值,因为不变位对于全部索引键是相同的。
可以维护可变位图和参考键值,以便在重建索引树时获得部分键。如果在索引中不需要部分键,则可变位图和参考键值不是必要的,并且仅需要维护d’位图,其是为高效索引重建要保存的主要信息。
搜索、插入以及删除操作可以用以下描述的索引树和ds-info来进行。
对于搜索操作和给定搜索键值k,如下搜索索引树的k。
在非叶节点中,将k与非叶节点条目中的索引键比较。由于条目具有去往后代叶中的最后的完整的索引键值(例如,a)的指针,对两个完整键值k和a进行二进制比较。
叶节点含有部分键的列表,除了是完整的键的最后一个。因此,将搜索键k与部分键的列表比较。
对于插入操作和给定的插入键值k,如下将k插入到索引树中。
1.用k向下搜索索引树并找到插入的正确位置(即,在两个键a与b之间)。
2.计算区别位位置d-位(a,k)和d-位(k,b)。
3.如下对应于插入而进行索引树上的改变,并更新d’位图和可变位图。对于d’位图,移除位位置d-位(a,b)并添加新的区别位位置d-位(a,k)和d-位(k,b)。然而,由引理1,d-位(a,b)=min(d-位(a,k),d-位(k,b))。由于最小位置已经在d’位图中设定,我们仅需在d’位图中设定max(d-位(a,k),d-位(k,b))(如果其尚未设定)。对于可变位图,我们对k和参考键值按位进行异或(exclusiveor),并且对可变位图和上述按位异或的结果进行按位或。结果将是新的可变位图。注意,d’位图上的实际的写入操作的数目受d’位图中的1的数目限制。因此,在插入期间在d’位图上发生实际的写入操作的机会很低。这对于可变位图是相同的。
对于删除操作和给定的删除键值k,如下从索引树删除k。
在索引树中如平常删除来进行删除k,并且保留d’位图和可变位图没有改变。我们需要示出d’位图在删除k之后是有效的。使a和b分别为之前的键值和k的下一个键值。在删除k之后,应在d’位图中设定d-位(a,b)。再次由引理1,d-位(a,b)=min(d-位(a,k),d-位(k,b))。由于在d’位图中设定了d-位(a,k)和d-位(k,b),d-位(a,b)已经被设定,无论其为d-位(a,k)还是d-位(k,b)。
通过删除操作和之后的插入操作来完成更新操作。
随着db表中的数据改变,如上面所公开地步进地更新ds-info。例如,当发生插入时,最多一个区别位位置被添加到d’位图,并且一些可变位位置可以被添加到可变位图。即使存在删除或回滚,此操作也不会还原,因为实现还原是相当昂贵的。因此,d’位图中可能存在值为1但不是区别位位置的位置。此外,可变位图可能具有值为1但不是可变位位置的位置。然而,如定理2中所示,它们不影响正确性。这些位位置可以通过偶尔扫描索引和计算ds-info来移除。如果重新重建索引,则将不存在这样的位位置。
用当前的ds-info,当索引树和ds-info丢失或不可用时,我们可以重建索引树(如下面将更详细地描述的)和新的ds-info。为区分当前的ds-info和正在计算的新的ds-info,将当前的ds-info称为给定ds-info。即使在重建索引树之后,我们可以将给定ds-info用作ds-info。然而,索引重建是重新计算ds-info的良好时机。为产生新的d’位图,由给定d’位图从索引键提取压缩的键,压缩的键被排序,并且相邻的压缩的键之间的区别位被计算(其中全部三个步骤是索引重建的一部分)。在一些实施例中,来自压缩的键中的任一个被取为参考键值。为产生新的可变位图,可变位图初始地全部为0,并进行以下操作:如上述的插入操作中,逐个取压缩的键(即,k)并对k和参考键值进行按位异或,之后对可变位图进行按位或。(注意,给定可变位图为0的位位置保持为新的可变位图中的不变位位置)。如果我们第一次构建索引树(即,完全不存在ds-info),则我们如以上计算d’位图和可变位图,但使用完整索引键而非压缩的键。
现以下描述的是如何通过使用ds-info从db表即时构建索引树的示例。在一些实施例中,我们仅从索引键值提取在d’位图中设定的位置中的位,其在本文中称为排序键压缩。排序键压缩是本文中使用较小空间和加速索引构建的主要原因。
图5是根据本文的一些示例性实施例的并行索引构建的总体过程示意性图示。特别地,为并行地收集索引键,目标表505的数据页被平均地分布到核心(图5中未示出),如由分布到不同的核心的页510和515的分组所示。每个核心扫描分配的数据页并提取压缩的键和对应的记录id(rid)。包含压缩的键和对应的记录id的一对产生排序键。在图5中在520和525处示出了本示例的键-rid对。在图5的530和535处通过并行排序算法将压缩的键-rid对排序。基于排序的压缩的键-rid对,通过合并来自多个核心的树540和545以自底而上的方式来构建索引树550。
在一些方面中,可以通过在d’位图中提取具有值1的位置中的位来进行排序键压缩。现在描述的是如何从索引键得到压缩的键。图6以大端(bigendian)格式图示了示例,虽然实际的实现方式可以使用特定处理器的小端(littleendian)格式。
对于完整键605,从d’位图610计算8字节长的掩码615、620和625。第一掩码开始自位图中含有第一个1的字节并且其为8字节长。第二掩码开始自在第一掩码之后含有第一个1的字节,并且其为8字节长,等等。在图6的示例中,从d’位图610获得三个掩码。
如图6中在630处所示,通过例如bmi指令pext(其将所选的位从源复制到目的地的连续低阶(low-order)位),从索引键提取位于掩码具有值1的位置中的位。图6的过程继续,将提取的位与移位和按位或操作级联。如图6中所示,由于图6中存在三个掩码(例如,掩码615、620和625),通过每个步骤中的移位(635)和按位或(640)将提取的位在三个步骤(i)、(ii)和(iii)中级联。在图6中,645中的位串是从完整键605提取的压缩的键。
一旦以键顺序将压缩的索引键和记录id的对排序,可以以自底而上的方式构建索引树。首先,可以从排序的压缩的键和记录id构建叶节点。为计算区别位位置,我们从d’位图产生阵列d’-位移[i],其储存d’位图中的第i个1的位置。则,键i和键i+1的区别位位置为d’-位移[d-位(压缩(键i),压缩(键i+1))]。接下来,我们以自底而上的方式构建非叶节点。对于非叶节点中对应于键i和键j的两个相邻条目,区别位位置为d’-位移[d-位(压缩(键i),压缩(键j))]。
在本示例的索引树的情况下,叶节点和非叶节点含有预定长度p的部分键。部分键的位移与键值的区别位位置相同。给定部分键的位移和预定部分键长度p,如下确定部分键的位。
1.如果部分键的位位置被包含在压缩的键中,则可以直接从压缩的键复制位值。
2.如果位位置是可变位图中具有值0的位置(即,不变位位置),则可以从参考键值复制位值。
3.否则(即,具有d’位图中的值0和可变位图中的值1的位位置),我们有两个选项。
a.将部分键构造所需的位(区别位位置之后p个位)添加到压缩的键,并在此将它们用于索引构造。
b.由于排序键中也含有记录id,可以从记录复制必要位,对其需要解非关联化(dereferencing)。
为构建索引,维护两个参数:最大扇出和填充因数。每个(叶或非叶)节点具有256b大小,并且其具有数据头(24b)和去往下一个节点的指针(8b)。由于叶节点中的每个条目占用16b,叶节点中的最大扇出(即,条目的最大数目)为14。由于非叶节点中的每个条目占用24b,非叶节点中的最大扇出为9。对于每个索引在索引构建期间定义填充因数,并且叶节点和非叶节点填充上至最大扇出×填充因数。此示例中的填充因数的默认值是0.9。对于给定数目的记录、填充因数以及最大扇出,索引树的高度可以确定。
可以通过将排序的索引键和记录id的对划分并并行地构造子树来并行化索引构造。即,n个排序键分为p个块且每个
已经通过若干示例性实施例和应用以及对应的附图阐述了本公开的各方面。然而,本公开不限于具体的示例性实施例。本文公开的技术和有用的排序键压缩特征(例如,维护的信息量相对小的意义上的轻量化(即,来自排序键的最小位数)连同性能和存储器改善)可以应用于可以在初始或首次排序操作之后在没有瞬态数据集的情况下将数据重排序的任何应用。
图7图示了示例性系统图,以进行本文中所描述的过程。设备700包含可操作地耦接到通信装置720的处理器705、数据储存装置730、一个或多个输入装置715、一个或多个输出装置725以及存储器710。处理器705可以包含多核心处理器,多核心处理器能够由其中的多个核心同时执行多个线程。通信装置720可以便于与诸如报告客户端或数据储存装置的外部装置通信。(多个)输入装置715可以包括例如键盘、小键盘、鼠标或其他指向装置、麦克风、旋钮或开关、红外(ir)端口、扩展坞(dockingstation)、和/或触摸屏。(多个)输入装置715可以用来例如将信息输入到设备700中。(多个)输出装置725可以包括例如显示器(例如,显示幕)扬声器、和/或打印机。
数据储存装置730可以包括任意适当持久储存装置,包含磁储存装置(例如,磁带、硬盘驱动器以及闪速存储器)、光学储存装置、只读存储器(rom)装置等等的组合,而存储器710可以包括随机存取存储器(ram)、储存级存储器(scm)或任意其他快速存取存储器。
数据库引擎735可以包括由处理器705执行的逻辑装置,以使设备700进行本文中所描述的过程中的任意一个或多个(例如,索引重建和排序键压缩过程)。实施例不限于由单个设备执行这些过程。
数据740(或被缓存或完整数据库)可以储存在诸如存储器725的易失性存储器中。数据储存装置730还可以储存数据和其他程序代码和指令,其用于提供附加的功能和/或对设备700的操作是必要的,诸如装置驱动器、操作系统文件等等。
前述图示表示描述根据一些实施例的过程的逻辑架构,并且实际的实现方式可以包含以其他方式布置的更多的或不同的部件。其他的平台、框架以及架构可以与其他实施例结合使用。此外,本文中描述的每个部件或装置可以通过经由任意数目的其他公共和/或私密网络通信的任意数目的装置实现。两个或更多个这样的计算装置可以位于彼此远程并经由任意已知方式的(多个)网络和/或专用连接彼此通信。每个部件或装置可以包括适于提供本文中所描述的功能以及任意其他功能的任意数目的硬件和/或软件元件。例如,根据一些实施例的系统的实现方式中的任何计算装置可以包含处理器,以执行程序代码,使得计算装置如本文中所描述的运行。
本文中所讨论的全部系统和过程可以实施为储存在一个或多个非暂时性计算机可读介质上的程序代码。这样的介质可以包含例如软磁盘、cd-rom、dvd-rom、闪速驱动器、磁带以及固态随机存取存储器(ram)或只读存储器(rom)储存单元。实施例因此不限于硬件和软件的任何具体组合。
本文中所描述的实施例仅出于说明目的。本领域技术人员将认识到,可以以对上述示例的修改和变化来实践其他实施例。
- 还没有人留言评论。精彩留言会获得点赞!