基于评论数据的跨平台电商欺诈检测方法和系统与流程
本发明涉及电商大数据挖掘技术领域,尤其涉及一种基于评论数据的跨平台电商欺诈行为检测方法和系统。
背景技术:
如今,电商已经成为消费者和工厂、零售商之间的高效纽带,为消费者提供一个快速、便捷和可靠的购物环境。电商的众多优势导致了越来越多消费者倾向于线上购物,使得电商蓬勃发展,电商零售额也随之快速增长,这给工厂、零售商和电商服务商带来了巨大的经济收益。例如,阿里巴巴年报显示,其电商平台淘宝网2017年交易总额达到22020亿人民币;亚马逊年报显示,其电商平台2016年的交易总额达到9700亿人民币;易贝年报显示,其电商平台2016年交易总额达到6580亿人民币。
自然的,电商在取得巨大经济效益的同时也带来了一些安全问题。例如,为了取得更高的经济收益,一些恶意的第三方零售商会采用灰色的手段来推广他们的商品。在实际的购物场景中,消费者倾向于购买一些销量高、评分高或者好评多的商品。因此,一些恶意的第三方零售商通过虚假购买、虚假评价、虚假评论等手段来推广他们的商品,以获取更高的经济收益,这些非法的推广行为称为电商欺诈。据相关报道,电商欺诈现象普遍存在于各类大规模电商平台中,如亚马网、淘宝网、京东商城等。
电商欺诈会破坏健康的电商环境,造成不公平的商业竞争,例如电商欺诈给消费者提供了一些不准确的购物信息,诱导消费者进行消费。理解和检测电商欺诈,尤其是欺诈商品,对于学术界和工业界而言,仍然是一个挑战。
对于电商服务商而言,他们在某种程度上受到了隐私保护和伦理问题的限制,无法很好地检测欺诈商品。即使某些电商服务商愿意主动地、负责任去维护良性的电商环境,电商服务商之间的相互竞争导致这些服务商无法相互合作,难以检测电商平台外部的欺诈商品。当电商内部数据(如,用户点击数据和用户-商品关联图)不可得的时候,探索欺诈检测变得更为困难。因此,学术界一些现存的方法都不能直接应用到电商欺诈检测中。例如,当内部点击数据不可得时候,基于用户点击的恶意点击检测方法无法直接用于电商欺诈检测。
第三方、跨平台的电商欺诈检测系统可以快速地、公正、有效地检测电商欺诈,它不会偏袒任何一个电商平台并可以扩展和应用于不同平台的电商欺诈检测,是一种基于电商公开数据的欺诈检测方案,可以直接抵抗电商灰黑产。
到目前为止,仅有极为少数的工作从第三方、跨平台的角度理解和检测电商欺诈。
技术实现要素:
本发明提供了一种基于评论数据的跨平台电商欺诈行为检测方法,该跨平台电商欺诈行为检测方法可以利用电商的评论数据,实现多类电商平台中的欺诈商品自动化监测。
本发明提供了如下技术方案:
一种基于评论数据的跨平台电商欺诈行为检测方法,包括以下步骤:
(1)从相关电商网站获取商品的评论数据,并对所述的评论数据对应的商品属性进行人工标注;
(2)对评论数据进行预处理,并从中提取单词级别特征、评论语义特征和评论结构特征,构建训练集;
(3)以单词级别特征、评论语义特征和评论结构特征为输入,利用训练集训练二元分类器;
(4)从相关电商网站获取目标商品的评论数据,提取目标商品评论数据的单词级别特征、评论语义特征和评论结构特征,输入到训练好的二元分类器对目标商品的属性进行识别。
所述的商品属性为正常商品和欺诈商品。欺诈商品是指销售商通过虚假购买、虚假评价、虚假评论等手段来推广该商品,以获取更高的经济收益。
步骤(1)中,从相关电商网站获取商品的评论数据后,先剔除无用评论数据。
若一个商品下的评论数量少于5条或者该商品下所有评论中没有积极词,则该商品下的所有评论为无用评论数据。
剔除无用评论数据可以减少干扰,使得训练的模型识别更准确。
步骤(2)中,所述的预处理包括对所述的评论数据进行分词和词性标注。
步骤(2)中,所述的单词级别特征包括平均积极词数量、平均消极词数量、平均高频n-gram词组含量和平均高频n-gram词组比例。
所述的平均积极词数量是指一个商品下所有评论中每条评论含有积极词的平均数量;所述的平均消极词数量是指一个商品下所有评论中每条评论含有消极词的平均数量。
平均积极词数量和平均消极词数量的提取方法,包括:
(a1)采用爬取的评论数据训练一个word2vec模型;
(a2)采用训练好的的word2vec模型从评论数据中寻找与积极种子词相似的词语,构建积极词库;采用训练好的的word2vec模型从评论数据中寻找与消极种子词相似的词语,构建消极词库;
(a3)统计所述的评论数据中积极词和消极词的数量,计算平均积极词数量和平均消极词数量。
n-gram词组指是连续n个单词的组成的序列,高频n-gram词组指该n-gram词组中含有至少一个高频率词语(例如含有一个出现概率为前1%的词语)。平均高频n-gram词组含量是指一个商品中所有评论中含高频n-gram词组的总和。
平均高频n-gram词组比例是指一个商品中所有评论中含高频n-gram词组的总数和该商品评论中含有的n-gram词组数量的比例。
采用现有技术提取一个商品中每条评论中高频n-gram词组的数量,计算可得到平均高频n-gram词组含量和平均高频n-gram词组比例。
步骤(2)中,所述的评论语义特征包括平均评论情感特征;所述平均评论情感特征的提取方法包括:
(b1)利用情感模型计算商品下每一条评论的情感值;
(b2)对该商品下所有评论的情感值取平均数,得到平均评论情感特征。
若一条评论的情感值接近1,表示该条评论的情感很积极;相反的,若一条评论的情感值接近0,则表示该条评论的情感很消极。
步骤(2)中,所述的评论结构特征包括:平均标点数量、标点总量、平均评论熵、平均评论长度和评论总长度。
所述的标点总量是指一个商品下所有评论中所含有的标点符号的数量总和;所述的平均标点数量是指一个商品下所有评论中平均每条评论所含有的标点符号的数量。
采用现有技术统计单个商品所有评论的标点符号的数量作为标点总量,计算单个商品评论的标点总量和商品评论数量的商作为平均标点数量。
熵是度量事物混乱程度的量。平均评论熵是指一个商品下所有评论中每条评论的熵的平均值。
采用现有技术计算单个商品评论中单词概率熵的平均值作为平均评论熵。
评论总长度是指一个商品下所有评论长度(评论长度以字符个数计算)的总和;平均评论长度是指一个商品下所有评论中每条评论的评论长度的平均值。
采用现有技术统计单个商品中所有评论中中文字符的数量作为评论总长度,该总长度除以评论的数量的商值作为平均评论长度。
步骤(3)中,所述的二元分类器为xgboost分类器。
xgboost分类器具有较好的分类效果。
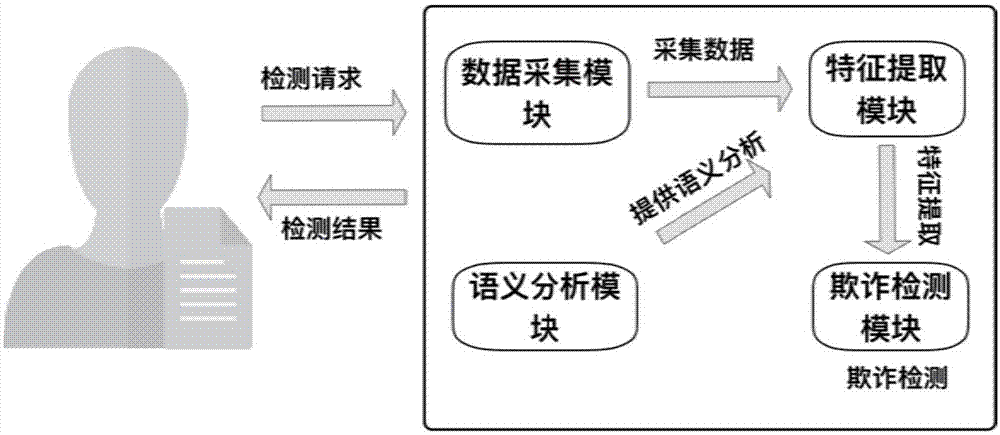
本发明还公开了实现上述检测方法所采用的检测系统,包括:
数据收集模块,从相关电商网站获取商品的评论数据;
语义分析模块,深度分析所述评论数据的语义信息;
特征提取模块,利用评论数据的语义信息,提取评论数据的单词级别特征、评论语义特征和评论结构特征;
欺诈检测模块,基于评论数据的单词级别特征、评论语义特征和评论结构特征,利用二元分类器判别该商品是否属于欺诈商品。
与现有技术相比,本发明的有益效果为:
本发明的检测方法从电商评论的词汇、语义和结构这三个方面提取平台无关的商品特征,基于这些特征来判别商品是否存在欺诈嫌疑,检测结果比较准确,可帮助消费者、电商平台服务提供商以及网络监管部门有效判别欺诈商品。本发明的检测方法不仅适用于电商欺诈检测,还适用于虚假新闻检测、虚假广告检测等。
本发明的检测系统是一种高效的、跨平台的、强健的第三方跨平台电商欺诈检测系统,实现多类电商平台中的欺诈商品自动化监测。
附图说明
图1为本发明的检测系统的结构示意图;
图2为实施例的检测流程示意图。
具体实施方式
下面结合附图和实施例对本发明作进一步详细描述,需要指出的是,以下所述实施例旨在便于对本发明的理解,而对其不起任何限定作用。
本发明的跨平台电商欺诈检测系统架构如图1所示,包括数据收集模块、语义分析模块、特征提取模块和欺诈检测模块。
数据收集模块主要用于电商大数据的采集和预处理;语义分析模块用于深度分析电商数据的语义信息;特征提取模块利用语义等信息,提取电商数据的有效特征;基于提取有效特征,欺诈检测模块利用一个二元分类器判别某个商品是否属于欺诈商品。本发明的检测系统使用的数据来源于各大电商平台提供的公开数据,因此本发明提出的检测系统适用于检测各类别大规模电商平台的欺诈,例如淘宝网、京东商城等。
本发明的跨平台电商欺诈检测系统工作流程如图2所示,主要包括以下几个步骤:
(1)用户选择一个所需要检测的电商平台,输入电商平台的网址。以京东为例子,输入京东商城的网址:www.jingdong.com。
(2)数据采集模块根据用户的请求,采集相关平台的公开电商评论类数据。以京东商城为例,数据采集首先采集京东商城里面第三方店铺的地址类相关信息,然后采集每一个店铺里面的所有商品数据,最后采集每一个商品的所有评论类相关数据,具体流程如图2所示。在采集完数据之后,数据采集模块简单地删除重复的数据。
(3)在采集并对数据简单去重之后,首先为每一个商品的评论进行中文分词,本专利拟利用的分词库为开源软件:jieba。然后,特征提取模块从已经分词之后的数据中提取有效的商品特征。基于评论数据,特征提取模主要从评论单词、评论语义、评论结构这3个层面提取10个维度的特征。具体来说,单词级别特征为平均积极词数量、平均消极词数量、平均高频n-gram词组含量、平均高频n-gram比例;评论语义特征为平均评论情感;评论结构特征为平均标点数量、标点总量、平均评论熵、平均评论长度和评论总长度。
(a)单词级别特征
商品的评论信息是已购买该商品的消费者的直接意见反馈。我们可以直观的感受到:如果一个商品评论中包含大量的积极词汇(例如,好评)会吸引大量潜在消费者购买此商品。据观察,一些不法商家通过向欺诈商品评注入大量积极评论的方法给消费者造成一种热销的假象。因此,欺诈商品的评论数据中含有大量恶意注入的积极词汇,而正常商品的评论数据中积极词、消极词和中性词语占比相对合理。根据这个观察,特征提取模块提取如下的单词级别特征:平均积极词数量、平均消极词数量、平均高频n-gram词组含量和平均高频n-gram比例。
平均积极词数量度量一个商品下所有评论中含有的积极词的平均数;平均积消极数量度量一个商品下所有评论中含有的消极词的平均数。
平均积极词数量和平均消极词数量的提取方法,包括:
(a1)我们在爬取的电商评论大数据上用google提供的tensorflow框架训练一个word2vec模型,这个word2vec模型可以将中文离散单词转换成特征向量;
(a2)采用训练好的的word2vec模型从电商评论数据中寻找与积极种子词相似的词语,构建积极词库;采用训练好的的word2vec模型从电商评论数据中寻找与消极种子词相似的词语,构建消极词库;
(a3)统计所述的评论数据中积极词和消极词的数量,计算平均积极词数量和平均消极词数量。
n-gram指是连续n个单词的组成的序列,高频n-gram指这个n-gram中含有至少一个高频率词语(例如含有一个出现概率为前1%的词语)。平均高频n-gram是度量一个商品中所有评论所含高频n-gram的总和;平均高频n-gram词组比例是度量一个商品中所有评论所含高频n-gram的总数和该商品评论中含有的n-gram数量的比例。
我们提取高频n-gram词组含量和平均高频n-gram的步骤如下:首先全量评论分析,得频率最高的前100的n-gram词组;然后根据这100个n-gram词组,提取单个商品的平均高频n-gram词组含量和平均高频n-gram词组比例。
(b)评论语义特征
除了单词级别的特征,我们还发现大部分的欺诈商品的评论都传达出一种强烈的情感:这个商品真的非常值得购买。而正常商品的评论是由正常消费者产生,它评论所表达出的情感并没有如此强烈。通过对部分已经判别的欺诈商品和正常商品的评论情感进行分析比较,我们进一步发现,欺诈商品的情感比正常商品表现得更为积极。基于这个观察,特征提取模块为每一个商品提取平均评论情感特征。
给定一个商品,其平均评论情感特征的提取方法如下。1)利用已有的开源情感模型计算该商品下每一条评论的情感值,情感值接近1表示情感很积极,情感值接近-1表示情感消极;2)对该商品所有评论的情感值取平均数得到平均评论情感特征。
(c)评论结构特征
根据观察欺诈商品和正常商品的评论数据,我们发现下述几个有趣的现象:(1)欺诈商品的评论长度比正常商品长;(2)欺诈商品的评论组织结构相比于正常商品更为复杂;(3)欺诈商品的评论含有更加丰富的标点信息;和(4)欺诈商品的评论含有更多的重复词。基于这些观察,特征提取模块提取下述评论结构特征:平均标点数量、标点总量、平均评论熵、平均评论长度和评论总长度。
平均标点数量是度量一个商品下面所有评论中所含有的标点符号(例如逗号、顿号)的平均值;平均标点数量是度量一个商品下面所有评论中含有的标点符号的总和。
统计单个商品所有评论的标点符号的数量作为标点总量,计算单个商品评论的标点总量和商品评论数量的商作为平均标点数量。
熵是度量事物混乱程度的一个通用方法。平均评论熵度量一个商品下面所有评论熵的平均值。
计算单个商品评论中单词概率熵的平均值作为平均评论熵。
评论总长度度量的是一个商品下所有评论长度的总和;平均评论长度度量一个商品下所有评论长度(评论长度以字符个数计算)的平均值。
统计单个商品中所有评论中中文字符的数量作为评论总长度,该总长度除与评论的数量的商值作为平均评论长度。
(4)欺诈检测模块首先根据一些简单的规则过滤掉部分待检测的商品,例如过滤掉评论数量少于5条的商品,过滤掉没有积极词的商品。然后,基于步骤(3)中提取的特征,欺诈检测模块使用预先训练好的xgboost分类器从过滤后的商品中检测出欺诈商品。
本发明提出的检测系统适用于检测各类别大规模电商平台的欺诈,例如淘宝网、京东商城等。基于各类电商欺诈商品的检测结果,可以作如下的评测:(1)分析各类平台欺诈商品的显著特征,(2)挖掘不同平台欺诈商品之间的共性,(2)挖掘不同平台欺诈商品的差异和(4)分析不同电商平台欺诈商品的共性和差异的产生原因。本发明的欺诈商品评测研究可以提供一些欺诈商品检测的指导方针,帮助消费者、电商平台服务提供商、以及网络监管有效判别欺诈商品。
以上所述的实施例对本发明的技术方案和有益效果进行了详细说明,应理解的是以上所述仅为本发明的具体实施例,并不用于限制本发明,凡在本发明的原则范围内所做的任何修改、补充和等同替换等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!