一种移动应用数据处理方法与流程
本发明属于移动应用领域,尤其涉及一种移动应用数据处理方法。
背景技术:
随着移动应用的快速发展,各类移动app日益成为人们日常生活中不可或缺的工具,与传统实体工具不同,移动app的后台服务以及具体操作是不可见的,用户也不能或者仅能在很小的自由度下对自己的需求进行主动获取和分析,这些工作通常是由移动应用后台服务上经过数据获取和分析后主动向使用者进行推送或者利用更新等方式进行改变,这种方式使得用户不需要对移动应用的具体流程以及内部复杂的控制机理进行了解即可被动的获取相应信息或数据,但同时,这种被动的获取方式使得用户在使用移动应用过程中发现或者遇到问题、或者使用异常时不能主动进行改变,也缺乏有效途径能够将上述信息主动直接传递至用途有决策权的管理者层面,在此背景下,随着移动应用的推广而产生的用户体验数据就显得尤为重要,在各类用户体验数据中,由用户直接发表和陈述在接入端(主要是指各应用商场、论坛等信息收集环境)网页上的用户评论具有最直接的参考性。对于一个长期稳定发展并期望获得更多使用者得移动应用而言,收集用户评论,用来评价移动应用的使用效果,分析移动应用的优缺点,并进行针对性改进是一个必要的工作,但由于用户评论的数量庞大,且由于市场竞争以及大量用户无意识的行为,导致有效收集和分析用户评论难以进行。
技术实现要素:
本发明创造的目的在于,提供一种移动应用数据处理方法,以能够快速有效的实现对移动应用评论数据的甄选筛查,以便于提取有效的关键数据为移动应用的评价分析提供依据。
为实现上述目的,本发明创造采用如下技术方案。
一种移动应用数据处理方法,包括如下内容,
一、用于获取移动应用相关数据的步骤,包括获取软件标志数据,所述软件标志数据包括软件名称、软件分类以及软件简介;
二、用于从用户评论数据中获取评论相关的元素数据的步骤,所述元素数据包括用户评论、软件版本、评论端口、评论时间、用户id;具体包括如下步骤:
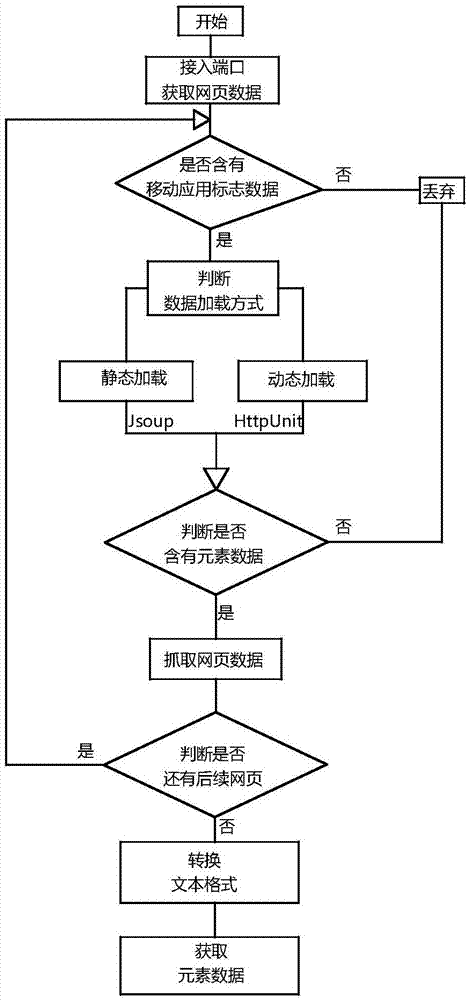
步骤1、接入评论端口,获取网页数据,搜索需要抓取数据的移动应用的标志数据,对标志数据相应的网页进行抓取;在抓取数据时需要对网页的加载方式进行判断,并根据不同加载方式使用不同的分析方法抓取数据,具体是指采用jsoup分析静态加载方式的网页标签数据,采用httpunit抓取动态加载方式的网页标签数据;
步骤2、判断该网页数据是否含有的标志数据相应的移动应用;若有抓取各网页并存入相应数据库;所述数据库是根据各移动应用作为分类因素分别建立的与各移动应用相应的数据库;
步骤3、判断是否还有后续网页,若有则跳转至步骤二,若无则跳转至步骤4;
步骤4、将所有以抓取的网页转换为文本格式,定位和获取评论数据相对应的元素数据;所述定位和获取评论数据相对应的元素数据具体包括,
步骤4.1、,对用户评论数据进行分词和词性标注处理,提取名词n、动词v以及形容词a构成关键词集;定义移动应用对应的第i条用户评论的关键词集ki,ki={w0/f0,w1/f1......,wk/fk},其中,k=0,1,2......k-1,k为第i条评论的分词数,wk为评论中第ki个分词,fk为wk的词性;其中分词工具是指用于进行分词、词性标注、词性识别、字词识别等功能的应用工具;
步骤4.2、提取关键词集ki中仅有形容词a的评论数据,将原关键词集中所有的wk存入优化后的关键词集knewi,其中优化后的关键词集knewi定义为:
knewi={w0,w1......wj},其中j=0,1,2......j-1,j为第i条评论优化后的关键词数,wj为评论优化关键词集中的第j个词;
步骤4.3、提取关键词集ki中含有{n+a}、{v+a}、{n+v}、{n+v+a}的评论数据,将原关键词集中非a的wk相应的词性存入优化关键词集knewi,相应的词性存入优化关键词性集fnewi,其中优化后的关键词集fnewi定义为:
fnewi={f0、f1......fj},其中,fj为评论优化关键词集中的wj的词性;
三、用于提取关键词集和计算关键词集中元素对移动应用评分权重的步骤,其具体步骤包括:
步骤1、对每个移动应用建立属于自己的特征词库,具体是指根据特征词的词性建立特征词库,包括动词特征库、名词特征库、形容词特征库;
步骤2、对每个移动应用抽取关键词集中的关键词wj,wj在对应词性fj的特征库中的频数tj、包含有wj的文本数nj以及文本总数n;
步骤3、根据公式①计算各条用户评论与移动应用评分的权重得分s,并判断其得分是否大于阈值α,若大于阈值则判断为有效评论,否则判定为无用评论;
其中mj是指wj对应词性fj特征库中的平均特征频数,j为第i条评论优化后的关键词数。
1.根据权利要求1所述一种移动应用数据处理方法,所述阈值α是一个用于控制关键词集容量以控制计算量或者用于涮选数据关联度的数值,该值通过统计后人工指定,在计算资源能够有效处理所有数据的情况下。
2.根据权利要求1所述一种移动应用数据处理方法,在计算资源能够有效处理所有数据的情况下,阈值α=1。
根据权利要求1所述一种移动应用数据处理方法,对每一个待评价移动应用而言,获取的用户评论总数应当不小于1000条,评论的获取周期应当不小于30天,所述周期是指数据库中最早发表的和最晚发表的用户评论的时间间隔。
其有益效果在于:本发明的一种移动应用数据处理方法,能够有效处理数据量庞大的评论数据,压缩无效数据,合理且迅速的甄别对移动应用的评价以及分析有用的数据并进行相应处理,本发明充分结合中文的语法特点,针对性地对评论数据进行处理和存储,能够大大加快中文评论数据的收集处理速度,该方法再现方便,工具简单,具有良好的应用前景。
附图说明
图1是本发明实施例中移动应用评论数据抓取方法的流程示意图;
图2是关键词集提取方法的示意图;
图3是本发明实施例中关键词及优化步骤的示意图;
图4是本发明实施例中用户评论有关性分析方法的流程图。
具体实施方式
以下结合具体实施例对本发明创造作详细说明。
本发明中,为实现对移动应用用户评论的涮选评价,需要获取相应移动应用的相关数据以及用户评论数据,移动应用的相关数据主要包括软件标志数据用以对不同移动应用进行分类统计,同时根据移动应用的类型针对性的对用户评论进行甄选,本实施例中软件标志数据具体包括软件名称、软件分类以及软件简介。为实现最终的评价目的,需要针对移动应用的用户评论数据进行分析判断,并根据用户评论对应的软件版本等信息进行分类甄别,为了便于对评论数据进行分类、抽取等工作的进行,需要从用户评论数据中获取评论相关的元素数据,在本实施例中,元素数据具体包括用户评论、软件版本、评论端口、评论时间、用户id,在具有相应分类或分级数据的基础上,还应当包括用户星级,以便于根据需要的情况下,对过于庞大的数据进行压缩、剔除低信用低价值数据,以提高工作效率。
如图1所示为便于数据获取的顺利进行,本发明还包括了抓取移动应用数据的步骤,具体包括:
一、接入评论端口,获取网页数据,搜索需要抓取数据的移动应用的标志数据,对标志数据相应的网页进行抓取;在抓取数据时需要对网页的加载方式进行判断,并根据不同加载方式使用不同的分析方法抓取数据,本实施例中,采用jsoup分析静态加载方式的网页标签数据,采用httpunit抓取动态加载方式的网页标签数据;
二、判断该网页数据是否含有相应元素数据;若有则抓取该网页并存入数据库;特别的,为了实现多应用的综合分析或者对比分析,在存储网页数据的时候需要根据各移动应用分别建立数据库以便于有针对性的快速处理相关数据;
三、判断是否还有后续网页,若有则跳转至步骤一,若无则跳转至步骤四;
四、将网页转换为文本格式,定位和获取评论数据相对应的元素数据。
通过上述步骤,可以获取各评论端口中各移动应用对应的评论数据,但由于评论数据一般是由自然语言组成,电脑无法识别以及处理,为实现相应的判断甄别,需要对用户评论数据进行结构化处理,其重点是指对用户评论中的特征词或者特征词组进行特征词涮选,本实施例中具体包括如下步骤:
步骤一、对用户评论数据进行分词和词性标注处理,提取名词n、动词v以及形容词a构成关键词集;
定义移动应用对应的第i条用户评论的关键词集ki,ki={w0/f0,w1/f1......,wk/fk},其中,k=0,1,2......k-1,k为第i条评论的分词数,wk为评论中第ki个分词,fk为wk的词性;关键词集的提取过程如图2所示;
其中分词工具是指用于进行分词、词性标注、词性识别、字词识别等功能的应用工具,本实施例中具体针对的是中文数据,因此此处使用的是ictclas;
步骤二、提取关键词集ki中仅有a的评论数据,将原关键词集中所有的wk存入优化后的关键词集knewi,其中优化后的关键词集knewi定义为:
knewi={w0,w1......wj},其中j=0,1,2......j-1,j为第i条评论优化后的关键词数,wj为评论优化关键词集中的第j个词;
步骤三、提取关键词集ki中含有{n+a}、{v+a}、{n+v}、{n+v+a}的评论数据,将原关键词集中非a的wk相应的词性存入优化关键词集knewi,相应的词性存入优化关键词性集fnewi,其中优化后的关键词集fnewi定义为:
fnewi={f0、f1......fj},其中,fj为评论优化关键词集中的wj的词性;
上述步骤具体过程示意图如图3所示。
经过上述步骤后我们获取了相应移动应用的用户评论数据,并对评论数据获取了甄选和分离,获得了能够作为评价移动应用的关键数据,包括各类此行对应的关键词,但由于属于自然语言的评论中可能包含大量的重复性词语(在本申请中以高频词代指)以及无意义的词语,上述高频词以及无意义词可能会导致评价工作的受到影响,从统计特性的角度分析,一个关键词词对于相应数据提供的信息含量的大小或者说权重系数,是可以通过在本类数据中出现的频率来表达,同时在其他数据中出现频率较低的关键词对于目标数据的评价来说来说具有更多的可参考性。基于评论数据的文本特性,使用词频统计能够在本发明的方案中作为有效判断或甄别其重要程度的基础,因此本申请中利用词频统计的方法判用户评论数据中关键词与评价结果的重要程度或者关联性。
本发明中,为了能够实现用户评论中的关键词与移动应用的权重判断判断,需要获取优化后的关键词集knewi中的wj对应的词性fj特征库中的频数tj、包含有wj的文本数nj以及文本总数n等。并根据所有wj的tj、nj、n求解相应词集中元素对移动应用评分的权重系数,同时为反馈高频词对用户评论的影响,关键词的频率也必须纳入到计算方案中。
为实现上述目的,我们需要进行以下内容,包括如下步骤:
步骤一、对每个移动应用建立属于自己的特征词库,具体是指根据特征词的词性建立特征词库,包括动词特征库、名词特征库、形容词特征库;
步骤二、对每个移动应用抽取关键词集中的关键词wj,wj在对应词性fj的特征库中的频数tj、包含有wj的文本数nj以及文本总数n;
步骤三、根据公式①计算各条用户评论与移动应用评分的权重得分s,并判断其得分是否大于阈值α,若大于阈值则判断为有效评论,否则判定为无用评论;
其中mj是指wj对应词性fj特征库中的平均特征频数,j为第i条评论优化后的关键词数;公式①中引入了拉普拉斯平滑算法以避免零概率事件出现;
其具体方法流程如图4所示;
上述方案流程实现了一次的用户评论涮选工作,而在一个完整的用户评论判断过程中,通常会涉及到多端口多阶段的连续采集判断,因此,特征词库中会进行持续更新以修正数据,提高准确度,更新时,按照情况不同进行不同处置,包括:
若更新的特征词全部或者达到某一较高比例(该较高比例大于等于80%)均是形容词,则将特征词存入形容词特征词库并增加频数,否则存入对应特征词库并增加频数;若特征词在特征词库中不存在,则将该特征词加入特征词库,并将其频数设置为1。
基于上述基本方案,通过对某一移动应用a进行模拟评价分析我们得到了其相关的各特征词库如下表1、表2、表3所示,
表1某移动应用a动词特征词库
表2某移动应用a名词特征词库
表3某移动应用a形容词特征词库
同理,按照上述相同步骤,以几款移动应用a、b、c、d、e中的用户评论为例,去阈值为1,选取特定特征词计算用户评论的有关性得分并判断是否有关,并于人工标记进行对比,得到下表4
表4有关性得分计算(选取)
由表4中可知,由于第三条评论中具有更多的关键特征词,相应的评论得分更高。也更容易被系统识别,以移动应用a为例,从不同接入端抓取用户评论进行有关性判断,在评论条数小于110时,准确率呈现较大的随机性,直至超过110以上时,准确率才趋于平稳直至稳定在某一个稳定值,同时在实际应用过程中,由于移动应用短期内故障、接入端氛围影响甚至人为控制等突出状况的影响,会导致时间段内特定属性用户评论的集中出现,对于移动应用的评价来说,如果在选取时不进行相应处理,则可能会对评价的有效性造成很大影响同时大大加重了数据处理的难度,因此,在具体实施过程中,用户评论的获取方案中应当遵循以下原则,包括:从多个接入端获取用户评论数据,在各接入端之间以及接入端内部采取分时间段或者随机获取等方案,在必要时,对大量突发的异常数据进行剔除处理。
针对常用的移动应用评价,获取的用户评论总数应当不小于1000条,评论的获取周期应当不小于30天。以避免群发出现的异常数据以及短期的集中评论。
最后应当说明的是,以上实施例仅用以说明本发明创造的技术方案,而非对本发明创造保护范围的限制,尽管参照较佳实施例对本发明创造作了详细地说明,本领域的普通技术人员应当理解,可以对本发明创造的技术方案进行修改或者等同替换,而不脱离本发明创造技术方案的实质和范围。
- 还没有人留言评论。精彩留言会获得点赞!