基于改进CNN的简单学习框架的图像分类方法与流程
本发明涉及神经网络和图像分类领域,尤其涉及一种基于改进cnn的简单学习框架的图像分类方法。
背景技术:
图像分类技术是近年来计算机视觉非常热门的一个方向,它是根据图像的语义信息将图像分为不同的类别,同时也是图像检测、图像分割、物体跟踪等方向的基础任务。图像分类的应用非常广泛,主要包含的场景有安全领域的人脸识别,交通领域的交通场景识别,互联网领域基于内容的图像检索和相册自动归类,医学领域的图像识别等。
图像分类任务是从图像中提取出重要的特征,根据图像的特征信息将图像分为不同的类别。早期对图像分类的研究有基于人工神经网络(ann)做图像的分类。关于人工神经网络的基础研究始于计算机时代。虽然ann已经通过从复杂和不精确的数据中提取高度复杂的模式,证明了其独特的解决问题的能力,但是早期的开发受到基本技术问题和缺乏足够的计算机资源的严重限制。然而,随着计算机资源的并行开发和davidrumelhart、geoffreyhinton、ronaldwilliams在1985提出的反向传播(bp)算法的关键贡献,ann的发展不断扩大。人工神经网络可以执行不同的任务,如图像分类。然而,ann有一些缺点,例如过拟合和网络所需的长训练时间,所述网络可以包括几百万个参数和人工选择的特征集。选择“好”特征是图像分类中的关键步骤,因为下一阶段只看到这些特征并对它们起作用。最近,已经提出了许多方法,如深度学习的方法来解决这些问题。
深度学习是机器学习的一个相对较新的分支,它采用多层计算模型来表示具有多个抽象层次的数据。使用深度学习的方法实现图像分类,监督学习和无监督学习可以实现,这将很好的替代传统人工选择的工作。将卷积神经网络(convolutionneuralnetwork,cnn)应用到深度学习中处理计算机视觉问题,目前已经取得了很好的分类效果。采用将图像输入到cnn中,保留了输入图像的信息,通过一系列的卷积操作提取图像的特征和高层抽象,最终输出分类的结果。这是一种end-to-end的学习方法,并且可以使得最后得到的非常好,在实际任务中的应用非常广泛。
alexnet在2012年被alex提出,证明了cnn可以在图像分类中取得很好的效果,并在当年的isvrc中获得了冠军。alexnet包含8层神经网络:5个卷积层和3个全连接层。为了避免过拟合的问题,alexnet提出了dropout的思想。在这一任务中,alex使用了relu激活函数代替了传统的激活函数(sigmoid),relu的收敛速度更快并且能保持同样的效果,现如今已经广泛地使用在了各种cnn的结构中。caffenet利用对alexnet模型的分析学习caffe的结构,其主要步骤为准备数据集、标记数据集、创建lmdb格式的数据、计算均值、设置网络及求解器、运行求解。种是需要处理的数据,从输入层输入,被各层一次处理,最后到输出层得到输出。caffe存在两种数据流,一种数据是从输入层到输出层,需要被处理的数据。这部分数据存储在net.blobs的data中,同时,还保存着对应的梯度值。另一种数据是记录在各层中的参数,也就是权重weights和偏置bias。
在通过cnn进行图像分类时,如何进一步减少训练时间和存储成本,并且提高分类和识别精度成为了亟待解决的技术问题。
技术实现要素:
针对现有技术之不足,本发明提出了一种基于卷积神经网络的简单学习框架,表示为brief–net,并将其应用于图像分类,减少了训练的时间同时也提高了分类的精度。brief–net包括三个卷积层和最大池化层,接着是三个全连接层。采用softmax分类器来识别图像分类。相应地,本发明的基于改进cnn的简单学习框架的图像分类方法包括以下步骤:
s1)输入一张图像i;
s2)将图像i分为大小为m×m的图像块集合,每一块用ii(i=1,2,…,n)表示;
s3)将ii输入到卷积神经网络中进行训练,其包括:
s3.1)用大小为9×9的卷积核对图像ii做卷积处理;
s3.2)对上一步骤输出的特征图做3×3个单元的池化操作;
s3.3)用大小为5×5的卷积核做卷积处理;
s3.4)对上一步骤输出的特征图做3×3个单元的池化操作;
s3.5)用大小为3×3的卷积核做卷积处理;
s3.6)对上一步骤输出的特征图做3×3个单元的池化操作;
s4)经过多次提取特征,最后通过三层全连接层,得到一维的矩阵;同时使用dropout正则化操作,以避免过拟合;
s5)将神经网络中的输出结果输入到分类器里,输出得到分类结果。
根据一个优选实施方式,在步骤s3.1中,用大小为9×9,步数为4,
输出为96的卷积核对图像ii做卷积处理,每个卷积层的输出通过relu
激活函数,relu函数如下表示:
f(x)=max(0,x),(1)
当输入信号小于0时,输出为0,当输入信号大于0时,输出等于输入。relu的收敛速度大于其它激活函数的收敛速度。relu只需要一个阈值来获得激活值,并且计算复杂度较低。
根据一个优选实施方式,在步骤s3.2中,对步骤s3.1输出的特征图做3×3个单元,步数为2,输出为96的池化操作,采用重叠池化采样以避免过拟合。在常规实践中,由相邻池化单元汇总的邻域不重叠。汇集层可以被认为是由间隔在步数s像素之外的汇集单元的网格组成,每一个汇总一个大小为z×z的邻域,集中在池单元的位置。如果设置s=z,就得到了cnns常用的局部池。如果设置s<z,则得到重叠池。在目前的工作中,本发明在整个网络中采用s=2和z=3。所采用的重叠池化采样提供了一种不易过拟合的网络。
根据一个优选实施方式,在步骤s5中,采用softmax函数作为目标函数完成图像分类。brief–net模型采用softmax函数作为目标函数完成图像分类。softmax函数是基于softmax回归,它是一种监督学习算法,将logistic回归推广到多个类的情况。
本发明具有以下有益技术效果:
本发明提出了一种基于卷积神经网络的简单学习框架,表示为brief–net,并将其应用于图像分类,减少了训练的时间同时也提高了分类的精度。brief–net包括三个卷积层和最大池化层,接着是三个全连接层。采用softmax分类器来识别图像分类。本发明采用非常有效的gpu运算,极大地缩短了训练的时间。此外,使用相对较小的第一层卷积核和重叠池化采样,使用较小的卷积核可以提取细节的变化,采用重叠池化采样能够有效避免过拟合。本发明的网络结构更加精简,与两个相关方法caffenet和alexnet相比,本发明的方法提供了更高的识别精度。
附图说明
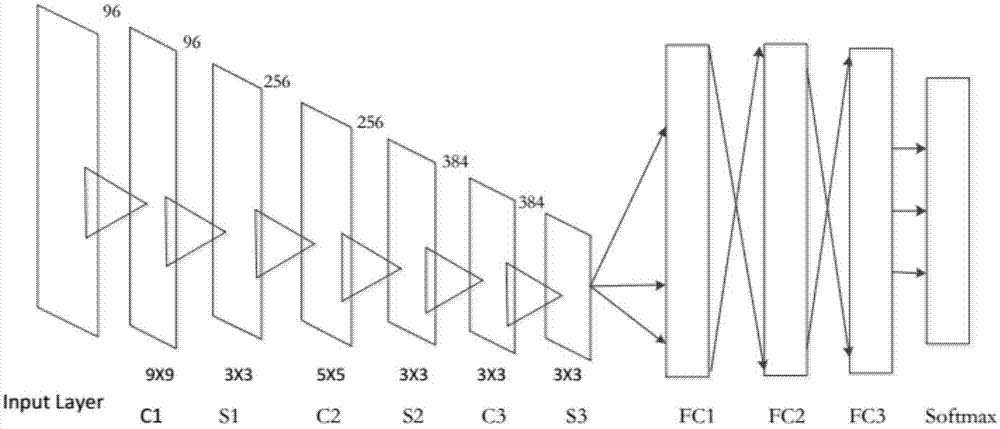
图1示出了基于改进cnn的brief–net框架的图像分类示意图;
图2示出了基于改进cnn的brief–net的图像分类流程图;
图3示出了通过改变第一层卷积核大小在两个数据集ro-5和flower
图像分类的精确度比较。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
如图1所示,本发明提出了一种基于卷积神经网络的简单学习框架,表示为brief–net,并将其应用于图像分类,减少了训练的时间同时也提高了分类的精度。brief–net包括三个卷积层和最大池化层,接着是三个全连接层。采用softmax分类器来识别图像分类。
如图2所示,本发明的基于改进cnn的简单学习框架的图像分类方法包括:
s1)输入一张图像i;
s2)将图像i分为大小为m×m的图像块集合,每一块用ii(i=1,2,…,n)表示;
s3)将ii输入到卷积神经网络中进行训练,其包括:
s3.1)用大小为9×9的卷积核对图像ii做卷积处理;
s3.2)对上一步骤输出的特征图做3×3个单元的池化操作;
s3.3)用大小为5×5的卷积核做卷积处理;
s3.4)对上一步骤输出的特征图做3×3个单元的池化操作;
s3.5)用大小为3×3的卷积核做卷积处理;
s3.6)对上一步骤输出的特征图做3×3个单元的池化操作;
s4)经过多次提取特征,最后通过三层全连接层,得到一维的矩阵;同时使用dropoutregularization操作,以避免过拟合;
s5)将神经网络中的输出结果输入到分类器里,输出得到分类结果。
具体地,本发明方法的一个优选实施方式包括以下步骤:
(1)输入一张图像i。
(2)利用图1所示的brief–net结构框架对图像i进行分类。该步骤具体为:
a.将图像i分为大小为m×m的图像块集合,每一块用ii(i=1,2,…,n)表示。
b.将ii输入到卷积神经网络中进行训练。
c.用大小为9×9,步数为4,输出为96的卷积核对图像ii做卷积处理。每个卷积层的输出通过relu激活函数,relu函数如下表示:
f(x)=max(0,x),(1)
当输入信号小于0时,输出为0,当输入信号大于0时,输出等于输入。relu的收敛速度大于其它激活函数的收敛速度。relu只需要一个阈值来获得激活值,并且计算复杂度较低。
d.对上一步骤输出的特征图做3×3个单元,步数为2,输出为96的池化操作。在常规实践中,由相邻池化单元汇总的邻域不重叠。汇集层可以被认为是由间隔在步数s像素之外的汇集单元的网格组成,每一个汇总一个大小为z×z的邻域,集中在池单元的位置。如果设置s=z,我们就得到了cnns常用的局部池。如果设置s<z,则得到重叠池。在本发明中,我们在整个网络中采用s=2和z=3。所采用的重叠池化采样提供了一种不易过拟合的网络.
e.用大小为5×5,步数为2,输出为256的卷积核做卷积处理。
f.对上一步骤输出的特征图做3×3个单元,步数为2,输出为256的池化操作。
g.用大小为3×3,步数为2,输出为384的卷积核做卷积处理。
h.对上一步骤输出的特征图做3×3个单元,步数为2,输出为384的池化操作。
(3)经过多次提取特征,最后通过三层全连接层,得到一维的矩阵。同时还使用了dropoutregularization操作,避免过拟合。dropoutregularization即dropout正则化,其用于有效地减少过拟合。
(4)将神经网络中的输出结果输入到分类器里,得到图像的分类结果。brief–net模型采用softmax函数作为目标函数完成图像分类。softmax函数是基于softmax回归,它是一种监督学习算法,将logistic回归推广到多个类的情况。假设有m个训练样本{(x(1),y(1)),…,(x(i),y(i)),…(x(m),y(m))},x(i)代表第i个训练样本,y(i)代表与之对应的类标签。在多级别训练中,y(i)可以有k个值。例如,y(i)∈{1,2,…,k}。softmax的公式为:
i{.}表示指标函数,指示x(i)是否是j类。即1{真语句}=1和1{false语句}=0。y(i)的k个值可能值被累加。x(i)是j类的公式表示为:
采用梯度下降法最小化j(θ),这是一个迭代优化算法。利用导数可以看出梯度是:
本发明基于神经网络的模型supplementcnn,通过使用leakyrelu激活函数代替传统神经网络中使用的relu激活函数,解决了负值特征信息被丢弃的问题,从而提高了图像分类的效果。图3示出了通过改变第一层卷积核大小在ro-5数据集和flower数据集图像分类的精确度,从两个数据集的实验结果可以看出本发明方法的有效性和效率。此外,与两个相关的现有方法caffenet和alexnet相比,本发明的方法提供了更高的识别精度。
本发明提出了一种基于卷积神经网络的简单学习框架,表示为brief–net,并将其应用于图像分类,减少了训练的时间同时也提高了分类的精度。本发明具有很好的泛化能力,能在不同的数据集上表现出很好的分类效果。另外,本发明比传统的cnn更具有稳定性,具有将其运用到大型网络中的前景。
需要注意的是,上述具体实施例是示例性的,本领域技术人员可以在本发明公开内容的启发下想出各种解决方案,而这些解决方案也都属于本发明的公开范围并落入本发明的保护范围之内。本领域技术人员应该明白,本发明说明书及其附图均为说明性而并非构成对权利要求的限制。本发明的保护范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!