基于多层特征融合的全卷积孪生网络的目标跟踪方法及系统与流程
本发明属于数字图像处理、深度学习以及模式识别的交叉领域,更具体地,涉及基于多层特征融合的卷积孪生网络的目标跟踪方法及系统。
背景技术:
目标跟踪在计算机视觉中具有非常重要的地位,然而由于自然场景的复杂性,目标对光照变化的敏感性,跟踪对实时性和鲁棒性的要求,以及遮挡、姿态和尺度变化等因素的存在,使得跟踪问题仍然很困难。传统的目标跟踪方法,无法对目标提取丰富的特征使得严格区别目标与背景,容易出现跟踪漂移现象,因此无法长时间跟踪目标。随着深度学习的兴起,一般的卷积神经网络可以有效提取目标丰富的特征,但是网络参数过多,如果要在线跟踪,无法满足实时性能的要求,实际工程利用价值有限。
由于硬件性能的提高以及gpu等高性能计算器件的普及,跟踪的实时性不再是难以克服的问题,有效的目标外观模型在跟踪过程中才是至关重要的。目标跟踪的本质是一个相似性度量的过程,由于孪生卷积网络的特殊结构,其在相似性度量方面具有天然的优势,而且具有卷积结构,可以提取丰富的特征用于目标跟踪。纯粹的基于孪生卷积网络采用离线训练,在线跟踪,虽然可以在高性能运算设备上实时性满足要求,但是全卷积孪生网络在跟踪过程中只利用了卷积网络高层提取的语义信息,在复杂场景中并不能很好区分与目标相似的背景,导致跟踪漂移和目标丢失问题。
技术实现要素:
针对现有技术的缺陷,本发明的目的在于解决现有技术相似背景干扰导致的跟踪漂移和目标丢失的技术问题。
为实现上述目的,第一方面,本发明实施例提供了基于多层特征融合的卷积孪生网络的目标跟踪方法,该方法包括以下步骤:
(1)根据图像的目标位置和大小,裁剪出图像序列训练集中的所有图像的目标模板图像和搜索区域图像,目标模板图像和搜索区域图像组成的图像对构成训练数据集;
(2)构建基于多层特征融合的卷积孪生网络,所述基于多层特征融合的卷积孪生网络包含2个完全相同的第一分支卷积网络和第二分支卷积网络,所述第一分支卷积网络用于获取搜索区域图像的特征图,所述第二分支卷积网络用于获取目标模板图像的特征图,两分支网络在指定层特征图上有连接,目标模板图像的特征图和搜索区域图像的特征图的对应层分别做互相关运算,得到对应的得分图;
(3)基于所述训练数据集,训练所述基于多层特征融合的卷积孪生网络,获得训练好的基于多层特征融合的卷积孪生网络;
(4)使用训练好的基于多层特征融合的卷积孪生网络计算待测图像序列中图像的得分图,基于得分图进行目标跟踪。
具体地,步骤(1)包括:目标模板图像的裁剪方法为:以目标区域为中心的目标矩形框,以目标区域中心位置代表目标位置,在目标矩形框四边分别扩充p个像素,若矩形框超出图像边界,超出部分用图像均值像素填充,最后将裁剪的目标图像块尺寸缩放至127×127大小;搜索区域图像的裁剪方法为:以目标区域为中心,在目标矩形框四边分别扩充2p个像素,若矩形框超出图像边界,超出部分用图像均值像素填充,最后将裁剪的搜索区域图像块尺寸缩放至255×255大小;其中,p=(w+h)/4,w为目标矩形框宽像素,h为目标矩形框长像素。
具体地,步骤(2)包括:搜索区域图像输入第一分支卷积网络,通过conv1得到第一层特征图sfm1,接着通过pool1、conv2层得到第二层特征图sfm2,最后通过pool2、conv3、conv4、conv5得到第三层特征图sfm3;目标模板图像输入到第二分支卷积网络,通过conv1得到第一层特征图gfm1,接着通过pool1、conv2得到第二层特征图gfm2,最后通过pool2、conv3、conv4、conv5得到第三层特征图gfm3;将目标模板特征图和搜索区域图像特征图对应层分别做互相关运算,得到对应的三张得分图sm1、sm2、sm3,公式如下:
smi=gfmi*sfmi
其中,i分别取1、2、3,*为互相关运算。
具体地,步骤(3)中构建的联合损失函数l(y,v)计算公式如下:
l(y,v)=α1l1(y,v1)+α2l2(y,v2)+α3l3(y,v3)
l(y[u],vi[u])=log(1+exp(y[u]×vi[u]))
其中,li为得分图smi的损失函数,l(y[u],vi[u])为得分图smi中每个点的对数损失函数,αi为得分图smi的权重,0<α1<α2<α3≤1,di表示得分图smi的中所有点的集合,u为得分图中的点,ci为得分图smi的中心点,ri是得分图smi的半径,ki为得分图smi的步幅,vi[u]为得分图smi中u点对应的值,||||代表欧氏距离,i=1,2,3。
具体地,步骤(4)包括:
1)根据待测图像序列的第1帧图像的目标位置和大小,裁剪出第1帧图像的目标模板图像,将第1帧图像的目标模板图像输入训练好的多层特征融合的卷积孪生网络的第二分支卷积网络,获得的目标模板图像的特征图m1,t=2;
2)根据待测图像序列的第t-1帧图像的目标位置和大小,裁剪出第t帧图像的搜索区域图像,将第t帧的搜索区域图像输入训练好的多层特征融合的卷积孪生网络的第一分支卷积网络,获得第t帧图像的搜索区域图像特征图;
3)将第t-1帧的目标模板特征图与第t帧的搜索区域图像特征图对应层分别进行互相关运算,得到目标在第t帧的搜索区域图像内的三张得分图,然后采用线性加权的方式融合多张得分图,得到第t帧的最终得分图;
4)根据第t帧的最终得分图计算目标在第t帧图像中的目标位置;
5)根据第t帧图像中的目标位置和大小,裁剪出第t帧图像的目标模板图像,将第t帧图像的目标模板图像输入训练好的多层特征融合的卷积孪生网络的第二分支卷积网络,获得的目标模板图像的特征图记为mt,则第t帧的目标模板图像的特征图为
6)t=t+1,重复步骤2)-5),直至t=n,待测图像序列目标跟踪结束,其中,n为待测图像序列的总帧数。
为实现上述目的,第二方面,本发明实施例提供了基于多层特征融合的卷积孪生网络的目标跟踪系统,该系统包括:
裁剪模块,用于根据图像的目标位置和大小,裁剪出图像序列训练集中的所有图像的目标模板图像和搜索区域图像,目标模板图像和搜索区域图像组成的图像对构成训练数据集;
基于多层特征融合的卷积孪生网络模块,所述基于多层特征融合的卷积孪生网络包含2个完全相同的第一分支卷积网络和第二分支卷积网络,所述第一分支卷积网络用于获取搜索区域图像的特征图,所述第二分支卷积网络用于获取目标模板图像的特征图,两分支网络在指定层特征图上有连接,目标模板图像的特征图和搜索区域图像的特征图的对应层分别做互相关运算,得到对应的得分图;
训练模块,用于基于所述训练数据集,训练所述基于多层特征融合的卷积孪生网络,获得训练好的基于多层特征融合的卷积孪生网络;
目标跟踪模块,用于使用训练好的基于多层特征融合的卷积孪生网络计算待测图像序列中图像的得分图,基于得分图进行目标跟踪。
具体地,其特征在于,目标模板图像的裁剪方法为:以目标区域为中心的目标矩形框,以目标区域中心位置代表目标位置,在目标矩形框四边分别扩充p个像素,若矩形框超出图像边界,超出部分用图像均值像素填充,最后将裁剪的目标图像块尺寸缩放至127×127大小;搜索区域图像的裁剪方法为:以目标区域为中心,在目标矩形框四边分别扩充2p个像素,若矩形框超出图像边界,超出部分用图像均值像素填充,最后将裁剪的搜索区域图像块尺寸缩放至255×255大小;其中,p=(w+h)/4,w为目标矩形框宽像素,h为目标矩形框长像素。
具体地,所述基于多层特征融合的卷积孪生网络包括:搜索区域图像输入第一分支卷积网络,通过conv1得到第一层特征图sfm1,接着通过pool1、conv2层得到第二层特征图sfm2,最后通过pool2、conv3、conv4、conv5得到第三层特征图sfm3;目标模板图像输入到第二分支卷积网络,通过conv1得到第一层特征图gfm1,接着通过pool1、conv2得到第二层特征图gfm2,最后通过pool2、conv3、conv4、conv5得到第三层特征图gfm3;将目标模板特征图和搜索区域图像特征图对应层分别做互相关运算,得到对应的三张得分图sm1、sm2、sm3,公式如下:
smi=gfmi*sfmi
其中,i分别取1、2、3,*为互相关运算。
具体地,训练模块中构建的联合损失函数l(y,v)计算公式如下:
l(y,v)=α1l1(y,v1)+α2l2(y,v2)+α3l3(y,v3)
l(y[u],vi[u])=log(1+exp(y[u]×vi[u]))
其中,li为得分图smi的损失函数,l(y[u],vi[u])为得分图smi中每个点的对数损失函数,αi为得分图smi的权重,0<α1<α2<α3≤1,di表示得分图smi的中所有点的集合,u为得分图中的点,ci为得分图smi的中心点,ri是得分图smi的半径,ki为得分图smi的步幅,vi[u]为得分图smi中u点对应的值,||||代表欧氏距离,i=1,2,3。
具体地,所述目标跟踪模块经过以下步骤进行目标跟踪:
1)根据待测图像序列的第1帧图像的目标位置和大小,裁剪出第1帧图像的目标模板图像,将第1帧图像的目标模板图像输入训练好的多层特征融合的卷积孪生网络的第二分支卷积网络,获得的目标模板图像的特征图m1,t=2;
2)根据待测图像序列的第t-1帧图像的目标位置和大小,裁剪出第t帧图像的搜索区域图像,将第t帧的搜索区域图像输入训练好的多层特征融合的卷积孪生网络的第一分支卷积网络,获得第t帧图像的搜索区域图像特征图;
3)将第t-1帧的目标模板特征图与第t帧的目搜索区域图像特征图对应层分别进行互相关运算,得到目标在第t帧的搜索区域图像内的三张得分图,然后采用线性加权的方式融合多张得分图,得到第t帧的最终得分图;
4)根据第t帧的最终得分图计算目标在第t帧图像中的目标位置;
5)根据第t帧图像中的目标位置和大小,裁剪出第t帧图像的目标模板图像,将第t帧图像的目标模板图像输入训练好的多层特征融合的卷积孪生网络的第二分支卷积网络,获得的目标模板图像的特征图记为mt,则第t帧的目标模板图像的特征图为
6)t=t+1,重复步骤2)-5),直至t=n,待测图像序列目标跟踪结束,其中,n为待测图像序列的总帧数。
总体而言,通过本发明所构思的以上技术方案与现有技术相比,具有以下有益效果:
(1)本发明在跟踪目标的过程中,融合不同层的得分图,结合高层语义特征与底层细节特征,可以更好的区分相似或同类目标的干扰,防止跟踪过程中的目标漂移和目标丢失问题。
(2)本发明使用多层特征图互相关得到的融合得分图进行监督训练,设计新的联合损失函数,联合损失函数的设计考虑到不同层得分图的作用大小赋予不同的权重,可以防止梯度弥散,加速收敛过程。
附图说明
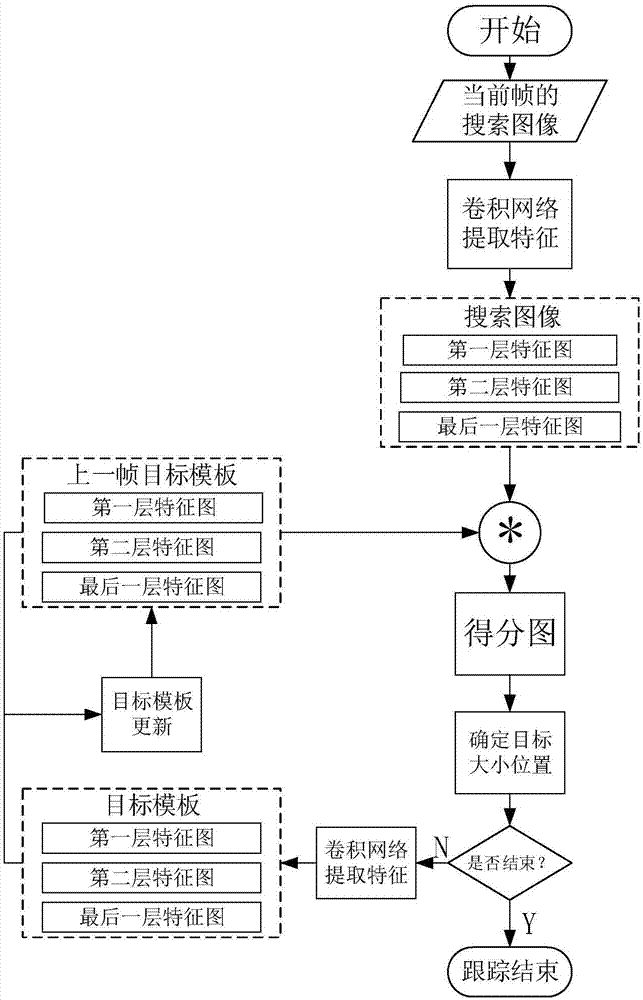
图1为本发明实施例提供的基于多层特征融合的卷积孪生网络的目标跟踪方法流程图;
图2为本发明实施例提供的目标模板图像和搜索区域图像示例图;
图3为本发明实施例提供的基于多层特征融合的卷积孪生网络结构示意图;
图4(a)、图4(b)、图4(c)分别为本发明实施例提供的使用本发明方法对第一视频序列进行目标跟踪的第36帧、第102帧、136帧图像;
图5(a)、图5(b)、图5(c)分别为本发明实施例提供的使用本发明方法对第二视频序列进行目标跟踪的第14帧、第24帧、第470帧图像;
图6(a)、图6(b)、图6(c)分别为本发明实施例提供的使用本发明方法对第三视频序列进行目标跟踪的第39帧、第61帧、第85帧图像;
图7(a)、图7(b)、图7(c)分别为本发明实施例提供的使用本发明方法对第四视频序列进行目标跟踪的第23帧、第239帧、第257帧图像;
图8(a)、图8(b)、图8(c)分别为本发明实施例提供的使用本发明方法对第五视频序列进行目标跟踪的第14帧、第52帧、第98帧图像;
图9(a)、图9(b)、图9(c)分别为本发明实施例提供的使用本发明方法对第六视频序列进行目标跟踪的第23帧、第37帧、第63帧图像。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
图1为本发明实施例提供的基于多层特征融合的卷积孪生网络的目标跟踪方法流程图。如图1所示,该方法包括以下步骤:
(1)根据图像的目标位置和大小,裁剪出图像序列训练集中的所有图像的目标模板图像和搜索区域图像,目标模板图像和搜索区域图像组成的图像对构成训练数据集。
图像序列训练集中是图像和标签图组成的图像对,所述标签图标注了对应图像的目标位置和大小。通过标签图从图像中裁剪出以目标区域为中心的目标模板图像和搜索区域图像。本实施例的训练数据集为4万对训练图像。
目标模板图像的裁剪方法为:以目标区域为中心的目标矩形框,以目标区域中心位置代表目标位置。在目标矩形框四边分别扩充p个像素,得到目标模板图像块的大小为(w+2p)×(h+2p),这里取p=(w+h)/4,w为目标矩形框宽像素,h为目标矩形框长像素。若矩形框超出图像边界,超出部分用图像均值像素填充。最后将裁剪的目标图像块尺寸缩放至127×127大小。
搜索区域图像的裁剪方法为:以目标区域为中心,在目标矩形框四边分别扩充2p个像素,得到搜索区域图像块的大小为(w+4p)×(h+4p),取p=(w+h)/4。若矩形框超出图像边界,超出部分用图像均值像素填充。最后将裁剪的搜索区域图像块尺寸缩放至255×255大小。
图2为本发明实施例提供的目标模板图像和搜索区域图像示例图。如图2所示,第1行为目标模板图像,第2行为对应的搜索区域图像。
(2)构建基于多层特征融合的卷积孪生网络。
图3为本发明实施例提供的基于多层特征融合的卷积孪生网络结构示意图。如图3所示,基于多层特征融合的卷积孪生网络包含2个完全相同的第一分支卷积网络和第二分支卷积网络,第一分支卷积网络用于获取搜索区域图像的特征图,第二分支卷积网络用于获取目标模板图像的特征图。
两分支网络结构和参数完全相同,均包含依次连接的第一卷积层conv1、第一池化层pool1、第二卷积层conv2、第二池化层pool2、第三卷积层conv3、第四卷积层conv4、第五卷积层conv5。具体参数为:conv1卷积核大小为11×11,步长为2,通道数为48;pool1卷积核大小为3×3,步长为2,通道数为48;conv2卷积核大小为5×5,步长为1,通道数为128;pool2卷积核大小为3×3,步长为1,通道数为128;conv3、conv4、conv5卷积核大小均为3×3,步长均为1,conv3、conv4通道数为192,conv5通道数为128。
搜索区域图像输入第一分支卷积网络,通过conv1得到第一层特征图sfm1,大小为123×123×48,接着通过pool1、conv2层得到第二层特征图sfm2,大小为57×57×128,最后通过pool2、conv3、conv4、conv5得到第三层特征图sfm3,大小为22×22×128。
目标模板图像输入到第二分支卷积网络,通过conv1得到第一层特征图gfm1,大小为59×59×48,接着通过pool1、conv2得到第二层特征图gfm2,大小为25×25×128,最后通过pool2、conv3、conv4、conv5得到第三层特征图gfm3,大小为6×6×128。
两分支网络在指定层特征图上有连接,目标模板图像的特征图和搜索区域图像的特征图的对应层分别做互相关运算,得到对应的得分图。
将目标模板特征图和搜索区域图像特征图对应层分别做互相关运算,得到对应的三张得分图sm1、sm2、sm3,大小分别为65×65、33×33、17×17,公式如下:smi=gfmi*sfmi,其中,i分别取1、2、3,*为互相关运算。
(3)基于所述训练数据集,训练所述基于多层特征融合的卷积孪生网络,获得训练好的基于多层特征融合的卷积孪生网络。
构建联合损失函数。对于得分图中每个点u∈d都有一个真实的标签y[u]∈{+1,-1},同时由于目标在得分图的中心,所以设定得分图的中心为圆心,在半径r内(考虑网络的步幅k)认为得分图中的元素属于正样本,反之为负样本,公式化如下:
其中:c是得分图的中心点,||||代表欧氏距离。
训练中使用的损失函数是基于对数损失函数,对于单张得分图的整体损失,采用全部点的损失的均值。本发明构建的联合损失函数l(y,v)为:
l(y,v)=α1l1(y,v1)+α2l2(y,v2)+α3l3(y,v3)
l(y[u],vi[u])=log(1+exp(y[u]×vi[u]))
其中,li为得分图smi的损失函数,l(y[u],vi[u])为得分图smi中每个点的对数损失函数,αi为得分图smi的权重,0<α1<α2<α3≤1,di表示得分图smi的中所有点的集合,u为得分图中的点,ci为得分图smi的中心点,ri是得分图smi的半径,ki为得分图smi的步幅,vi[u]为得分图smi中u点对应的值,||||代表欧氏距离,i=1,2,3。
具体地,α1、α2、α3分别取0.3、0.6、1,对于得分图1、得分图2和得分图3来说,步幅k对应的取值分别是2、4和8。
以联合损失函数最小化为目标函数,采用反向传播算法学习多层特征融合的卷积孪生网络的网络参数w。
本实施例训练40次,每一次迭代5000次,每次迭代使用8对训练图像。在网络训练过程中,随着网络参数的收敛,设置随机梯度下降法中的学习率依次从10-2缩减至10-5,即每训练10次后,梯度下降法的学习率减少10倍。
(4)使用训练好的基于多层特征融合的卷积孪生网络计算待测图像序列中图像的得分图,基于得分图进行目标跟踪。
1)根据待测图像序列的第1帧图像的目标位置和大小,裁剪出第1帧图像的目标模板图像,将第1帧图像的目标模板图像输入训练好的多层特征融合的卷积孪生网络的第二分支卷积网络,获得的目标模板图像的特征图m1,t=2;
待测图像序列的初始帧图像中目标位置和目标大小是已知的。根据待测图像序列的第1帧图像的目标位置和大小,裁剪出第1帧图像的目标模板图像。
2)根据待测图像序列的第t-1帧图像的目标位置和大小,裁剪出第t帧图像的搜索区域图像,将第t帧的搜索区域图像输入训练好的多层特征融合的卷积孪生网络的第一分支卷积网络,获得第t帧图像的搜索区域图像特征图;
待测图像序列的初始帧图像中目标位置和目标大小是已知的。根据待测图像序列的第1帧图像的目标位置和大小,裁剪出第2帧图像的搜索区域图像。
3)将第t-1帧的目标模板特征图与第t帧的搜索区域图像特征图对应层分别进行互相关运算,得到目标在第t帧的搜索区域图像内的三张得分图,然后采用线性加权的方式融合多张得分图,得到第t帧的最终得分图;
将大小为17×17的sm3双三次插值上采样为大小65×65的得分图
其中,
4)根据第t帧的最终得分图计算目标在第t帧图像中的目标位置;
在得到三个得分图按权重叠加之后的最终得分图sm123之后,sm123通过双三次插值到255×255大小。得分图中最大得分点所在位置记为位置pt。
为了使跟踪过程更体现连续性,采用线性插值位置pt来确定目标在第t帧图像中的目标位置
其中,γ为平滑因子。
本实施例γ取为0.35。
5)根据第t帧图像中的目标位置和大小,裁剪出第t帧图像的目标模板图像,将第t帧图像的目标模板图像输入训练好的多层特征融合的卷积孪生网络的第二分支卷积网络,获得的目标模板图像的特征图记为mt,则第t帧的目标模板图像的特征图为
本实施例η取0.01。
6)t=t+1,重复步骤2)-5),直至t=n,待测图像序列目标跟踪结束,其中,n为待测图像序列的总帧数。
图4(a)为本发明实施例提供的使用本发明方法对第一视频序列进行目标跟踪的第36帧图像;图4(b)为本发明实施例提供的使用本发明方法对第一视频序列进行目标跟踪的第102帧图像;图4(c)为本发明实施例提供的使用本发明方法对第一视频序列进行目标跟踪的第136帧图像。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有目标快速运动、姿态变化,遮挡和相似背景干扰的目标。
图5(a)为本发明实施例提供的使用本发明方法对第二视频序列进行目标跟踪的第14帧图像;图5(b)为本发明实施例提供的使用本发明方法对第二视频序列进行目标跟踪的第24帧图像;图5(c)为本发明实施例提供的使用本发明方法对第二视频序列进行目标跟踪的第470帧图像。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有姿态变化,遮挡和相似背景干扰的目标。
图6(a)为本发明实施例提供的使用本发明方法对第三视频序列进行目标跟踪的第39帧图像;图6(b)为本发明实施例提供的使用本发明方法对第三视频序列进行目标跟踪的第61帧图像;图6(c)为本发明实施例提供的使用本发明方法对第三视频序列进行目标跟踪的第85帧图像。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有姿态变化,遮挡,运动模糊的目标。
图7(a)为本发明实施例提供的使用本发明方法对第四视频序列进行目标跟踪的第23帧图像;图7(b)为本发明实施例提供的使用本发明方法对第四视频序列进行目标跟踪的第239帧图像;图7(c)为本发明实施例提供的使用本发明方法对第四视频序列进行目标跟踪的第257帧图像。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有光照变化,遮挡的目标。
图8(a)为本发明实施例提供的使用本发明方法对第五视频序列进行目标跟踪的第14帧图像;图8(b)为本发明实施例提供的使用本发明方法对第五视频序列进行目标跟踪的第52帧图像;图8(c)为本发明实施例提供的使用本发明方法对第五视频序列进行目标跟踪的第98帧图像。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有姿态变化,以及有相似背景干扰的目标。
图9(a)为本发明实施例提供的使用本发明方法对第六视频序列进行目标跟踪的第23帧图像;图9(b)为本发明实施例提供的使用本发明方法对第六视频序列进行目标跟踪的第37帧图像;图9(c)为本发明实施例提供的使用本发明方法对第六视频序列进行目标跟踪的第63帧图像。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有光照变化的目标。
以上,仅为本申请较佳的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!