一种社交网络多信息传播模型的建模方法与流程
本发明属于信息传播模型技术领域,具体涉及一种社交网络多信息传播模型的建模方法。
背景技术:
随着互联网技术的迅猛发展和在线社交网络的出现,信息传播的速度更快,影响范围更广,信息量也更加庞大。研究学者们广泛地利用复杂网络来描述真实世界的传播动态,而网络中的信息传播也是一个复杂的动态过程,被多种因素交互影响,例如网络的拓扑结构、信息发布者的影响力度、用户的兴趣偏好、信息本身的特性等等。理解复杂网络中的传播过程是网络科学领域中的一个核心问题,研究网络中的信息传播对于网络营销和谣言控制、互联网舆情监控等具有重大意义。
现今对于信息传播的研究大多数集中在研究单条消息在网络中的传播情况,但现实网络中存在大量消息共同传播的现象,例如多条谣言、多种疾病在人群中的传播;多种计算机病毒在计算机网络上的扩散。相比于单消息传播,多消息传播更为复杂,因为各个消息之间可能会有多种相互作用的情况。消息之间可能存在着相互竞争的关系,也可能是互相促进的关系。在有关多消息或多疾病传播的研究中,大部分研究是基于经典的传染病模型来重点探讨两种病毒之间的相互影响,鲜少有研究多条消息的传播情况,如newman在文献《thresholdeffectsfortwopathogensspreadingonanetwork》中讨论了两个相互竞争的病原体共同传播的临界值问题;ahn等人在文献《epidemicdynamicsoftwospeciesofinteractingparticlesonscale-freenetworks》中基于sis模型,针对两种病毒提出了新的病毒传播模型。但在真实社交网络的话题传播中,有较多的用户参与其中,从不同的角度、不同的看法来讨论该话题,因此在同一个时间点下可能会产生成百上千条新消息,消息之间相互影响。然而,在以前的研究中,这种同一话题下的多消息传播现象基本上被忽略了。
技术实现要素:
本发明的目的是针对现有技术存在的不足而提供的一种社交网络多消息传播模型的建模方法,该方法一方面考虑用户的记忆衰减,另一方面充分考虑多消息之间的相互影响,模拟多条信息在网络上同时传播的动态过程,更加贴近实际。
实现本发明目的的具体技术方案是:
一种社交网络多消息传播模型的建模方法,特点是:在单消息传播模型的基础上,扩展成多条消息,引入各个消息间的不同关联性和用户的记忆衰减性,得到信息传播最终的演化稳定状态,形成社交网络多消息传播模型;包括以下具体步骤:步骤1:基于社交网络中多条消息间的相互影响构建社交-消息网络,包括:
1)通过爬虫获取的数据构建社交用户关注网络,其中的节点表示社交网络中的用户,连边表示用户之间的关注关系;
2)通过爬虫获取的数据构建消息网络,其中的节点表示社会网络中所传播的各个消息,连边表示消息之间的相互作用,其相互作用的强度由连边的权值体现;
步骤2:用户以概率λ阅读网络中的消息,如果阅读该消息,则在t时刻,对于所阅读到的消息m,用户k以概率pk,m(t)传播该消息,如果未阅读到该消息直接进入步骤3;
步骤3:每一个时刻,如果网络中有新发布的消息,在消息网络中新增加节点表示新发布的消息,并更新各个消息节点之间的连边和连边的权重;
步骤4:重复步骤2和步骤3,直至每一条消息都不再被转发;其中:
步骤3所述更新各个消息节点之间的连边和连边的权重,具体为:
如果同一个用户先后转发了不同的消息即消息m和消息j,则在消息网络中为m节点和j节点之间增加一条连边;如果越来越多的用户先后转发消息m和j,那m和j之间连边的权重也将增加,利用salton余弦来计算连边的权重。
所述利用salton余弦来计算连边的权重,其表达式如下:
其中,nmj表示t时刻同时转发了消息m和消息j的用户数,km表示t时刻转发消息m的用户数,kj表示t时刻转发消息j的用户数,σmj表示消息m和消息j之间的关联性,即消息网络中m和j节点之间连边的权重,nk,t表示用户k在t时刻前所转发的消息总数,
所述用户k以概率pk,m(t)传播该消息,其概率pk,m(t)通过下述方法求得,具体包括:
1)当用户阅读到消息m后,不同时刻消息m对用户产生影响随记忆衰减函数w(t)=ε/t变化,其中ε表示记忆因子;
2)对于每条消息,在不考虑其他消息对其的相互作用时,用户转发消息的概率为:
3)考虑消息间的相互促进作用,得到用户转发消息的概率为:
其中
与现有的技术相比,本发明的优点在于:
1)本发明考虑了多条消息间的相互关联影响性,在建模过程中提出了用户的记忆衰减性,更加贴近社交网络的信息传播实际,并且考虑消息间的相互关联,不断更新消息网络,使得模型更加合理化。
2)本发明更加清晰明确的反应了网络中多消息之间的相互影响,提高预测多信息传播的准确性,给话题预测,舆情监控,多个企业投放宣传广告策略上,优化社交网络的商业行为等不同方面提供了有效模型支撑。
附图说明
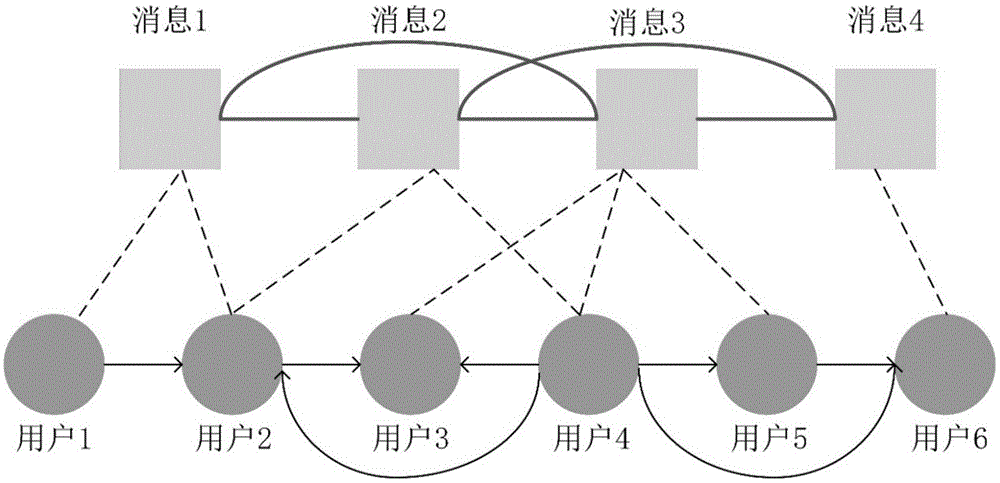
图1社交-消息网络示意图;
图2本发明流程图;
图3记忆因子与参与话题讨论的用户总数的关系图;
图4记忆因子与转发速率之间的关系图;
图5记忆因子、阅读概率和话题转发数量三者之间的关系图;
图6某英超联赛话题下发布的消息数与时间的关系图(不包括转发的消息数目);
图7预测结果与实际传播结果的对比图。
具体实施方式
下面结合附图和实施例,对本发明进行详细、清晰的进一步说明。
消息网络中的消息用网络中的节点来表示,其间的连边及权重表示消息间的相互影响强度。每一个时间步,在传播前需要根据过去时间中所有转发信息来更新消息网络。本发明定义了如下的消息网络更新方式:
如果同一个用户先后转发了不同的消息(消息m和消息j),则在消息网络中为m节点和j节点之间增加一条连边,如果越来越多的用户先后转发消息m和j,那m和j之间连边的权重也将增加,利用salton余弦来计算连边的权重,
得到消息间两两的相互影响值后,对于用户k,他/她在t时刻转发消息m时,需要考虑在t时刻之前,该用户转发的其他所有消息都会对其转发m消息产生共同影响,该共同影响定义为:
其中nk,t表示用户k在t时刻前所转发的消息总数。
如图1所示,矩形节点表示消息网络中的消息节点,黑色的实线连边表示消息之间的相互影响,圆形节点表示社交网络中的用户节点,带有箭头的实线表示用户间的关注关系,矩形节点和圆形节点之间的虚线连边,表示圆形节点转发了所连接的矩形节点。
关于在t时刻,对于阅读到的消息m,用户k转发该消息的概率pk,m(t)通过下述方法求得:
(1)依据用户的记忆具有衰减性,定义记忆衰减函数为w(t)=ε/t,当用户阅读到消息m后,消息m对用户的影响因记忆衰减效应随函数w(t)变化,影响力越来越小直至为0。
(2)对于每条消息,在不考虑其他消息对其的相互影响时,用户转发消息的概率为:
(3)考虑消息间的相互关联性,得到用户对消息m在t时刻的转发概率为:
多消息传播过程,可以看作是在网络上消息随着时间的推移,一方面不断有新的消息产生,另一方面用户的不同转发导致消息间的相互影响值发生变化从而改变转发概率。关于这个过程描述如下:
(1)初始期:基于社交网络中多条消息间的相互影响构建社交-消息网络,通过爬虫获取的数据构建社交用户关注网络,其中的节点表示社交网络中的用户,连边表示用户之间的关注关系;通过爬虫获取的数据构建消息网络,其中的节点表示社会网路中所传播的各个消息,连边表示消息之间的相互作用,其相互作用的强度有连边的权值体现;
(2)转发期:用户以概率λ阅读网络中的消息,因为每个时刻,网络中都会产生数以万计的新消息,用户在浏览网络时,不可避免的有些消息无法被阅读到。然后在t时刻,对于所阅读到的消息m,用户k以概率pk,m(t)传播该消息。
(3)消息网络更新期:根据上述所定义的更新方式,不断更新消息网络。
(1)初始期、(2)传播期、(3)消息网络更新期,刚开始进行传播时,为一轮完整的传播过程,接着反复进行(2)-(3)过程,直至每一条消息不再被转发,从而得到多消息的传播结果以及反复更新后的消息网络。该流程如图2所示。
实施例
数值模拟与实证结果
在仿真模拟阶段,本实施例构建了一个消息网络含有20个节点,社交网络为含有n=1000个节点的ba网络,每次节点加入网络新增加的连边数m=6,平均度<k>=5.989。
(1)初始期,构建了含有20个节点的消息网络和含有1000个节点的社交网络,从社交网络中随机选择20个节点,每个节点传播一条不同的消息,在网络中这20条消息同时传播。
(2)传播期,用户分别以概率λ阅读网络中这20条消息,对于阅读到的消息,用户采用概率
(3)消息网络更新期,统计此时所有用户的转发情况,当同一个用户转发不同消息时,更新消息间的连边和连边的权重。
不断重复(2)-(3)过程,得到每个时刻,多个消息的传播情况。
在实验中,对实验结果进行了50次平均,得到了如图3、图4和图5的实验结果。其中图3,表示在阅读概率为0.1和0.6的情况下,记忆因子ε与参与话题讨论的用户总数的关系图,随着记忆因子ε的增加,参与话题讨论的用户总数不断增加,且传播速度也略有提升。不同时刻消息m对用户产生影响随记忆衰减函数w(t)=ε/t发生变化,记忆因子较大时,表明用户对该话题的记忆强度更大,兴趣更浓,用户更容易被该消息影响,更容易在阅读到该话题后,选择转发,因此在用户间该话题会更快更广的传播开来。
图4展现了在阅读概率为0.1和0.6的情况下,记忆因子与转发速率之间的关系图,很清晰的看出,记忆因子越大传播速率越快。因为记忆因子越大意味着接收到的消息对用户产生的影响更大,即用户对该消息更感兴趣,所以针对该条消息用户的转发概率也会随之增大,每个时间步的转发概率都有所增加,则消息的传播速率加快。
图5呈现了不同记忆因子和不同阅读概率的情况下,话题的转发数量。话题的转发总量随着记忆因子的增大而增多;当记忆因子较小(如ε<0.2),阅读概率λ的改变对话题转发总量的影响不大,且阅读概率λ到达一定程度后,对话题转发总量造成的影响降低。
在实证阶段,所需数据集是twitter网络数据,是有关arsenalfc对阵manchestercityfc的一场英超联赛,整个话题从2015年12月14日持续到2015年12月23日,包含了4911个用户,和210条由不同用户不同时刻发布的不同消息。如图6所示,数据集中用户发布的消息数随时间变化的关系图。
(1)初始期:构建一个含有4911个节点的用户网络,用户间的关注关系从数据集中获取,在2015年12月14日前,网络中有关该话题的消息数为3条,因此构建了一个含有3个节点的消息网络;
(2)传播期:每个用户分别以概率λ阅读到网络中的三条消息,然后在此时,对于所阅读到的消息m,用户k以概率
(3)消息网络更新期,统计此时所有用户的转发情况,当同一个用户转发不同消息时,更新消息间的连边和连边的权重。统计下一个时刻网络中新发布的消息数,在消息网络中增加节点来表示。
不断重复(2)(3)过程,直至每一条消息不再被转发。实验结果如图7所示,将模型的预测结果与数据集中消息的传播实际情况相对比。
以上对本发明进行了实例性描述,并不用以限制本发明,凡是对本发明所做的任何修改、或是直接使用、改进、等同替换等,均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!