一种基于双向长短时记忆网络模型的中文分词方法与流程
本发明涉及一种基于双向长短时记忆网络模型的中文分词方法,属于自然语言处理领域。
背景技术:
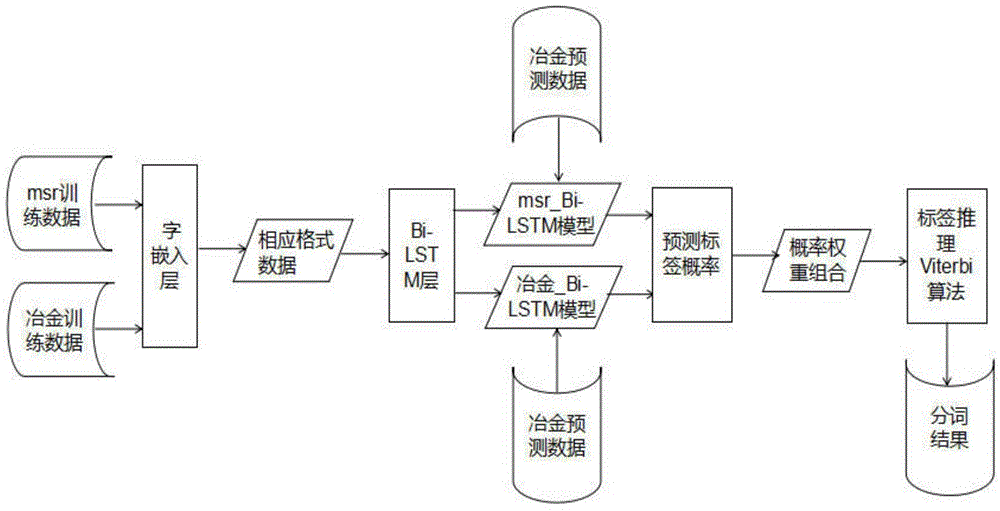
:在中文中,词与词之间不存在分隔符,词本身也缺乏明显的形态标记,因此,中文信息处理的特有问题就是如何将汉语的字串分割为合理的词语序列,即中文分词,因而分词是中文自然语言处理的第一步,这是不同于其他语言的自然语言处理系统的重要特点,也是影响自然语言处理在中文信息处理中应用的重要因素。近年来,国内外众多学者在中文分词领域做了大量研究工作,取得了一定的研究成果。但是,从实用化、效率、功能角度看,其还不能满足实际需求。公知的中文分词主要包括四种方法:1.基于词典的分词方法,如吴春颖(<基于二元语法的n-最大概率中文粗分模型>,2007,27(12):2902-2905);2.基于统计的分词方法,如tsengh(<aconditionalrandomfieldwordsegmenterforsighanbakeoff2005>,2005:168-171);3.基于理解的分词方法,如wua(<wordsegmentationinsentenceanalysis>,1998);4.基于神经网络的分词方法,如zhengx(<deeplearningforchinesewordsegmentationandpostagging>,2013)。其中基于词典的分词方法程序简单易行,分词速度快,但是其分词精度受词典的影响很大,而且不能处理歧义词。基于统计的分词方法只有训练语料规模足够大并且覆盖面足够广的情况下才可以获得较高的分词准确率,其新词识别能力相对较弱。基于理解的分词方法的思想是模拟人对句子的理解,在分词的同时进行句法、语义分析,这种方法需要大量的语言知识做支撑。基于神经网络的分词方法借助神经网络自动学习数据特征,避免了传统的分词方法由于人为设置的局限性,但是神经网络模型受上下文窗口大小的影响比较大,当窗口较大时容易引入过多特征带来的杂质信息并容易出现过拟合问题,而且传统的循环神经网络(如rnn)只是依靠句子顺序上的上文信息,并不能利用句子中的未来文本信息。技术实现要素:本发明的目的在于提供一种基于双向长短时记忆网络模型的中文分词方法,本发明通过对某一领域内的信息训练来学习领域内的信息特征,对领域外的信息(msr)训练来学习领域外的特征,从而分别获得分词模型,通过以上分词模型对某一领域内信息进行分词时可获得较好的分词结果,提高了分词的准确率。本发明的技术方案是:首先获得任一领域的数据集,并将数据集分为训练集和测试集,然后将训练集进行预处理,将预处理后的训练集和微软亚洲研究院的公开数据集msr分别进行字嵌入处理,再把处理好的训练集和数据集msr分别输入到双向长短时记忆神经网络模型即bi-lstm神经网络模型中进行训练,分别得到训练集的模型和msr_bi-lstm模型,训练集的模型记为x_bi-lstm模型,然后分别用x_bi-lstm模型、msr_bi-lstm模型对测试集进行标签预测,并对两种模型的预测概率进行权重组合,得到组合后的各汉字标签的概率,然后利用viterbe算法对组合后的各汉字的各标签概率进行计算得到各汉字属于各标签的最终概率,对比各汉字在各标签下的概率值,将概率最大值所属标签作为各汉字的标签,从而完成中文分词。本发明方法的具体步骤如下:step1:首先获得任一领域的文本数据集,并将文本数据集分为训练集和测试集,然后将训练集进行预处理,预处理过程具体为利用bmes标注方式对训练集中的汉字进行标注,其中对于多字词,b为多字词中的第一个字的标签,m为多字词中去除第一个字和最后一个字后其他字的标签,e为多字词中最后一个字的标签,s为单字词的标签,数据集msr为已标注完成的数据集,然后将标注后的训练集和数据集msr进行字嵌入处理,具体过程为根据标点符号对标注后的训练集和数据集msr进行切分,并将切分后的结果分别用数组data和label表示,其中data数据组包括每一个汉字,label数据组包括每一个汉字对应的标签,然后将data数据组和label数据组分别进行数字化处理,对data数据组的每一个汉字用该汉字第一次出现的顺序的数字表示,并存储在d[‘x’]中,对label数据组的标签用阿拉伯数字进行表示,并存储在d[‘y’]中,然后利用词向量技术将d[‘x’]和d[‘y’]中的数字进行向量转化,每个汉字转化成长度为n的向量,得到各汉字在1~n维度下的概率;step2:将step1得到的训练集中的各汉字的向量和各汉字对应的标签的数据输入至bi-lstm神经网络模型中进行训练,得到训练集的模型x_bi-lstm模型,将数据集msr中的各数据输入至bi-lstm神经网络模型中进行训练,得到msr_bi-lstm模型;step3:利用step2得到的x_bi-lstm模型和msr_bi-lstm模型分别对测试集中的各汉字的标签进行概率预测,分别得到两种预测概率p1i、p2i,其中p1i表示利用x_bi-lstm模型对测试集中的各汉字预测的各标签的概率,i=b,m,e,s,p2i表示利用msr_bi-lstm模型对测试集中的各汉字预测的各标签的概率,然后将两种模型的预测概率进行权重组合,得到测试集中各汉字的标签综合预测概率p,公式如下:p=a*p1i+b*p2i;step4:利用viterbi算法得出测试集中的各汉字在各标签下的概率,比较该汉字在各标签下的概率,取概率最大值所属标签作为各汉字最终的标签。本发明方法应用在冶金领域,在预测冶金信息分词时,使用bi-lstm网络训练领域外信息和领域内信息分别获得较好的分词模型,通过权重结合领域外模型和领域内模型的预测结果,来解决冶金语料不足导致的模型不理想以及对冶金信息中域外单词分词的问题,实现对冶金信息的较好分词。lstm神经网络模型和bi-lstm神经网络模型的工作原理如下:lstm神经网络模型通过输入门、忘记门和输出门三种门对细胞的行为进行控制,门上的操作基于sigmoid网络层和元素级的逐点乘积组成。通过sigmoid输出介于0到1之间的数值用来表示信息的通过程度,其中1表示信息全部可以通过,0表示信息都不可以通过。通过忘记门的sigmoid层可以使细胞忘记信息,其中σ表示sigmod函数,wf表示遗忘门的权重矩阵,ht-1表示上一层的输出,xt为当前层的输入,bf为遗忘门的偏置项,ft表示遗忘门的输出。ft=σ(wf·(ht-1,xt)+bf)当在细胞中存储信息时,首先通过输入门的sigmoid获取将要更新的信息it,然后通过tanh函数创建新的向量最后用ft乘以旧的细胞状态ct-1实现要遗忘的信息,再与的乘积相加获得细胞状态的更新。wi、bi分别表示激活函数是sigmod函数时输入门的权重矩阵和输入门的偏置项,wc、bc分别表示激活函数是tanh函数时输入门的权重矩阵和输入门的偏置项,ct表示当前细胞状态。it=σ(wi·(ht-1,xt)+bi)通过输出门的sigmoid层决定输出哪些信息。然后用tanh函数处理细胞的状态,最后两部分的乘积即为要输出的值。ot表示输出过程的中间结果,wo表示输出门的权重矩阵,h·表示上一序列的隐藏状态,x·表示本序列数据,bo表示输出门的偏置项,ht表示输出门的输出。ot=σ(wo·(h·,x·)+bo)ht=ot·tanh(ct)双向lstm即bi-lstm神经网络模型借助双向循环网络(bidirectionalrnn,brnn)的思想,通过前向和后向两层分别从句子的前方和后方运行。由于bi-lstm可以同时捕获历史和未来两个方向上的长距离信息,所以分别把数据集msr和训练数据集经过字嵌入后输入bi-lstm神经网络中进行训练得到基于训练数据集的x_bi-lstm分词模型和基于数据集msr的msr_bi-lstm分词模型。当通过step3产生每个字对应的标签概率之后,需要通过标签推断层确定当前字最终对应的标签,本发明方法中采用viterbi算法进行计算,具体为:当前字对应某个标签的概率等于前一个字在某个标签下的概率加上标签间的转移概率再加上通过训练得到的模型对其当前字预测得到该标签的概率,由于前一个字在四个标签下都有值,所以计算当前字在每个标签下的概率时会根据不同的转移概率得到多个值,选择最大的作为最终值,然后取每一列中最大概率值的作为当前字所属的标签即最短路径,得到每个字所属的最终标签。本发明的有益效果是:1、本发明通过对某一领域内的信息加入领域外的知识,并使用基于双向长短时记忆(bi-lstm)的深度学习模型对某一领域内的信息训练以学习某一领域内的特征,对领域外的信息(msr)训练以学习领域外的特征,进而分别获得两种分词模型,把领域外模型和领域内模型的预测结果进行权重的结合,再通过viterbi处理解决了语料不足导致的模型不理想以及对信息中域外单词分词的问题。2、本发明可获得较好的分词结果,提高了分词的准确率。3、本发明与公知的分词方法相比,对特定领域的信息分词有针对性,实现较好的分词。附图说明图1为本发明的流程图;图2为本发明实施例1的模型训练过程图;图3为本发明实施例1的模型预测过程图;图4为本发明实施例1中长短时记忆网络模型图;图5为本发明实施例1中双向长短时记忆网络模型图。具体实施方式下面结合附图和具体实施例对本发明作进一步说明。实施例1:如图1所示,为基于双向长短时记忆网络模型在冶金领域的中文分词方法的工作流程,具体步骤为:step1:由于冶金信息领域缺乏权威的语料,所以爬取冶金信息网的数据,获得冶金领域的文本数据集,并将文本数据集分为训练集和测试集,然后将训练集进行预处理,预处理过程具体为利用bmes标注方式对训练集中的汉字进行标注如表1所示,其中对于多字词,b为多字词中的第一个字的标签,m为多字词中去除第一个字和最后一个字后其他字的标签,e为多字词中最后一个字的标签,s为单字词的标签,数据集msr为已标注完成的数据集,然后将标注后的训练集和数据集msr进行字嵌入处理,具体过程为根据标点符号对标注后的训练集和数据集msr进行切分,并将切分后的结果分别用数组data和label表示如表2所示,其中data数据组包括每一个汉字,label数据组包括每一个汉字对应的标签,然后将data数据组和label数据组分别进行数字化处理,对data数据组的每一个汉字用该汉字第一次出现的顺序的数字表示,并存储在d[‘x’]中,对label数据组的标签用阿拉伯数字进行表示,并存储在d[‘y’]中,如表3所示,然后利用词向量技术将d[‘x’]和d[‘y’]中的数字进行向量转化,每个汉字转化成长度为n的向量,得到各汉字在1~n维度下的概率,如表4所示;表1四词位标注形式表2data和label数据形式表3d[‘x’]和d[‘y’]数据形式表4字嵌入step2:将step1得到的训练集中的各汉字的向量和各汉字对应的标签的数据输入至bi-lstm神经网络模型中进行训练,得到训练集的模型x_bi-lstm模型,将数据集msr中的各数据输入至bi-lstm神经网络模型中进行训练,如图2所示,为本实施例模型的训练过程,得到msr_bi-lstm模型;step3:利用step2得到的x_bi-lstm模型和msr_bi-lstm模型分别对测试集中的各汉字的标签进行概率预测,如图3所示,为本实施例发明的模型预测过程,分别得到两种预测概率p1i、p2i,其中p1i表示利用x_bi-lstm模型对测试集中的各汉字预测的各标签的概率,i=b,m,e,s,p2i表示利用msr_bi-lstm模型对测试集中的各汉字预测的各标签的概率,然后将两种模型的预测概率进行权重组合,得到测试集中各汉字的标签综合预测概率p,如表5所示,公式如下:p=a*p1i+b*p2i;表5字对应的标签概率字号8433288361987241163......s0.20.30.30.10.20.20.30.20.20.2......b0.50.10.30.30.30.30.20.10.50.2......m0.10.20.10.10.30.40.40.40.10.4......e0.30.40.30.50.20.10.10.30.30.2......合计1111111111本实施例的长短时记忆网络模型图如图4所示;本实施例的双向长短时记忆网络模型图如图5所示;step4:利用viterbi算法得出测试集中的各汉字在各标签下的概率,比较该汉字在各标签下的概率,如表6所示,取概率最大值所属标签作为各汉字最终的标签。表6最终字对应的标签概率字号8433288361987241163......s0.10.30.10.30.20.10.20.10.10.1......b0.50.20.50.10.50.20.10.20.50.2......m0.20.10.20.20.20.60.50.10.30.6......e0.20.40.20.40.10.10.20.60.10.1......通过表6可以得出,字号8的标签为b,字号43的标签为e,字号32的标签为b,字号88的标签为e,字号36的标签为b,字号198的标签为m,字号7的标签为m,字号2的标签为e,字号41的标签为b,字号163的标签为m,等等,通过本发明方法对本冶金领域的中文数据完成了分词,且分词效果好,准确率高。实施例2:本实施例方法同实施例1,不同之处在于,本实施例应用在非冶金领域,对选取的文本利用四词位(bems)标注,得到结果如表7所示:表7四词位标注形式根据标点符号对标注数据进行切分,并将切分后的结果分别用数组data和label表示如表8所示:表8data和label数据形式其中data数据组包括每一个汉字,label数据组包括每一个汉字对应的标签,然后将data数据组和label数据组分别进行数字化处理,对data数据组的每一个汉字用该汉字第一次出现的顺序的数字表示,并存储在d[‘x’]中,对label数据组的标签用阿拉伯数字进行表示,并存储在d[‘y’]中,如表9所示,然后利用词向量技术将d[‘x’]和d[‘y’]中的数字进行向量转化,每个汉字转化成长度为n的向量,得到各汉字在1~n维度下的概率,如表10所示;表9d[‘x’]和d[‘y’]数据形式表10字嵌入字号563208016195662......第1维概率0.010.050.050.110.120.160.040.13......第2维概率0.230.130.110.050.050.090.210.05......第3维概率0.090.120.160.060.150.020.160.05......第4维概率0.060.010.030.170.040.040.040.13......第i维概率..............................第n维概率0.110.060.020.040.060.150.080.05......利用得到的x_bi-lstm模型和msr_bi-lstm模型分别对测试集中的各汉字的标签进行概率预测,并将预测概率进行权重组合,结果如表11所示:表11字对应的标签概率利用viterbi算法得出测试集中的各汉字在各标签下的概率,比较该汉字在各标签下的概率,如表12所示,取概率最大值所属标签作为各汉字最终的标签。表12最终字对应的标签概率字号5632080161956626337......s0.10.20.40.50.30.20.70.60.40.1......b0.60.20.20.10.40.10.10.20.20.6......m0.10.10.20.10.20.20.10.10.30.1......e0.20.50.20.30.10.50.10.10.10.2......通过表12可以得出,字号5的标签为b,字号6的标签为e,字号320的标签为s,字号80的标签为s,字号16的标签为b,字号19的标签为e,字号56的标签为s,字号62的标签为s,字号63的标签为s,字号67的标签为b。上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1