一种安防视频智能检索系统及其检索方法与流程
本发明属于视频智能检索技术领域,具体涉及一种安防视频智能检索系统及其检索方法。
背景技术:
安防监控视频是体量最大的数据种类之一。城市视频监控通常都有成千上万监控点,高清视频已越来越普及,1个8mbps码率的高清监控点1个月产生的视频就有2.5tb,1千个监控点所产生的视频就有2.5pb。不同的监控场景,从中提取出的特征文件大小也存在差异,按照的经验,特征文件的大小通常为原始视频的1/2到1/3,也就意味着2.5pb的原始视频所提取的特征文件大约有1pb,要处理如此巨大的数量,采用服务器集群进行并行计算是必然抉择。
传统的安防视频智能检索系统常采用以下集群系统架构,其中解析服务器集群负责视频解码和特征提取,比对服务器集群负责特征存储和特征比对。图像搜索的简单原理就是通过遍历指定范围的特征数据并逐一进行比对,以匹配到相似度阈值以内的目标图片。
从实际测试结果看,早期图像搜索系统存在严重性能瓶颈,原因在于架构设计中将把处理服务器和特定数量的视频通道进行了捆绑(这是安防行业的常见做法,参见dvr/nvr视频录像机,视频编解码服务器等),具体运转时,数十台比对服务器在执行特定检索任务时极有可能只有几台比对服务器参与计算,甚至是只有几块磁盘参与数据吞吐,利用率极低。而且,解析与比对相分离,解析时,比对服务器闲置,比对时,解析服务器闲置,造成了大量浪费。
技术实现要素:
针对现有技术存在的缺陷,本发明提供一种安防视频智能检索系统,尽可能将视频特征文件均匀的分散到所有的比对服务器上,并对解析服务器和比对服务器进行分时复用的有效融合,可有效解决上述问题。
本发明采用的技术方案如下:
本发明提供一种安防视频智能检索系统,包括
用于存储检索视频请求消息队列的mq节点,
用于查询视频特征文件存储位置搜索范围、分割视频特征文件、分配搜索任务的master节点,
和用于视频解码、特征提取、特征存储与提取特征进行比对的worker节点。
优选的,所述worker节点上散列方式均匀的分布有安防监控视频特征;所述worker节点的数量为2个以上;所述安防监控视频特征包括用于存储视频的特征文件。
优选的,所述安防监控视频特征包括视频特征向量数据和视频关键帧图片数据。
一种安防视频智能检索方法,包括如下步骤:
获取检索视频请求,并存储在消息队列中,作为mq节点;
获取mq节点中的检索视频请求,作为master节点;master节点将所述检索视频进行分割,并将分割后的视频进行分配任务;
获取所述分配任务,作为worker节点;用于存储视频的特征文件散列方式均匀的分布在所述worker节点上;所述worker节点将所述分配任务进行提取特征,并将所述提取特征与服务器的存储特征进行比对;若对比结果一致,则反馈给mq节点,完成检索。
优选的,master节点将所述检索视频进行分割为固定大小的特征文件,每个特征文件分配全局唯一的文件名。
进一步优选的,worker节点将所述分配任务进行特征提取,并进行特征存储。
进一步优选的,所述特征文件块中包括搜索时间范围、相机编号信息。
本发明提供的一种安防视频智能检索系统具有以下优点:
(1)本发明将视频检索目标进行特征文件化,便于分布于不同的目标主机进行分布检索,提高工作效率,避免了遍历检索的低效性。
(2)本发明的工作主机既负责解析服务器的视频解码与特征提取,又负责比对服务器的特征存储与特征比对,节省原型系统有限的服务器资源,由此可以先做视频解析,再做特征比对,在时间上与服务器完全错开、互不干扰。
(3)本发明采用特征文件本地化存储,使其尽量平均地散列在不同工作主机上,提高了网络传输的效率。
附图说明
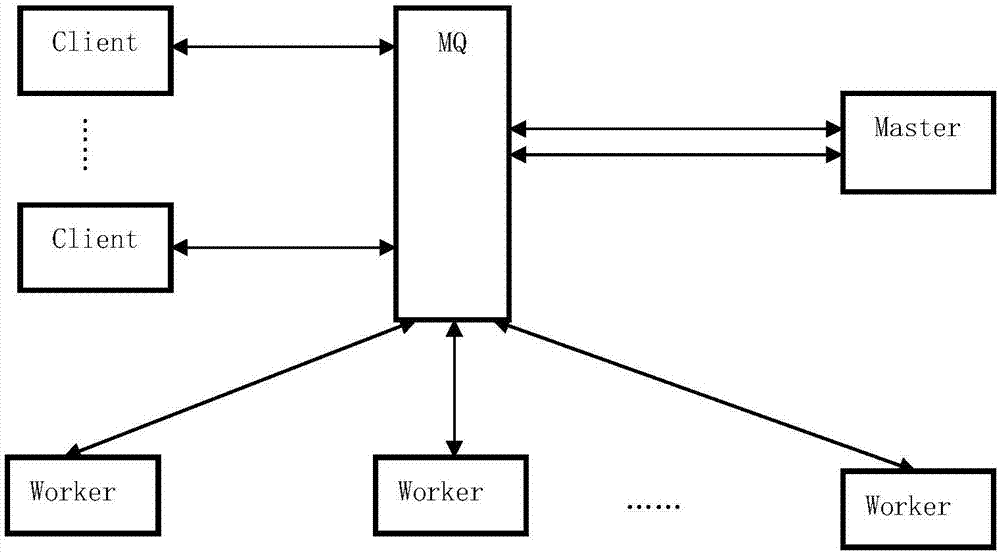
图1为本发明智能检索系统架构图;
图2为本发明特征存储示意图;
图3为本发明特征搜索示意图。
具体实施方式
以下结合附图对本发明进行详细说明:
如图1所示本发明提供一种安防视频智能检索系统,由master节点、mq节点、worker节点和client客户端等构成。master节点可以是单一节点,也可以是互备协调的多个节点;mq节点有两个或两个以上,用以构建分布式mq;worker节点支持横向扩展,从少数几个到成百上千个都有可能;多个客户端能够并发访问本系统。
我们为master、worker、client之间的通信设计了一套通信协议,定义了用户登录、用户注销、特征提取、特征搜索、worker节点加入、worker节点删除、worker节点退出、特征存储位置获取等和业务及管理相关的通信消息。
worker节点既负责解析服务器的视频解码与特征提取,又负责比对服务器的特征存储与特征比对,目的是为了节省原型系统有限的服务器资源,我们可以先做视频解析,再做特征比对,在时间上完全错开、互不干扰。
视频特征被分割为固定大小的特征文件块,特征文件创建的时候,master节点会给每个文件分配全局唯一的文件名。master节点还负责特征文件元数据的管理、特征提取和特征搜索任务的分布式调度worker节点的管理。
消息队列能够简化master、worker、client等众多节点之间复杂的通信,而分布式的消息队列能够进一步提供稳定、可靠的通信环境。
如图2所示,为了搜索时目标特征更均匀地分布在各个worker,特征存储主机也由master来统一分配。视频搜索较常见的搜索条件是相机编号及时间段,针对这种业务需求,特征文件按照相机编号与时间段来组织。首先,需要保证同一特征文件中存储的是同一个相机连续的时间段的数据,其次,同一个相机不同时间段的特征文件需要尽量平均地散列在不同worker上,master按照这种分布原则来分配特征文件的存储位置。worker在开始新特征文件的特征提取时,先向master询问该特征文件应该存储在哪里。特征文件采用固定长度设计,当worker提取特征达到文件大小时,将其传输给目标主机,传输通道关闭后将该文件信息告知master。
如图3所示,分配特征搜索任务时,保证worker比对的特征池存储在本地,能有效减小网络传输,提高搜索效率。当master收到client的特征搜索请求时,根据特征搜索条件,如搜索时间范围、相机编号,从特征文件表格中查询搜索范围内的特征文件,并且将搜索任务分解,分配给特征文件所在的worker。worker读取需要比对的本地特征文件,将目标与其进行特征比对,将相似度达到要求的记录返回给master。
我们在小规模的集群上部署了系统原型:采用开源大数据技术hdfs来实现分布式的master和worker,采用开源消息中间件kafka来实现分布式的mq消息队列,采用图片数据代替视频特征数据,以模拟特征存储的规模,采用sha计算来代替特征比对计算,以模拟比对算法的耗时。此实验环境基本能满足初期验证需求。
模拟实验使用8台pc服务器进行实验,服务器之间使用千兆网络互联进行通信。hadoop使用clouderacdh5.3版本,hdfs数据备份数设置为1,blocksize设置为128m。各软件分布情况如下表所示:
编写程序模拟制造图片与特征数据,存储情况如下:
在上表测试环境下,进行图像搜索实验。实验中worker使用单线程进行特征读取与比对,所得结果如下表所示。
从实验结果来看,当视频搜索的扫描数据量根据不同的时空搜索条件发生变化时,其响应时间也是线性增长的,与输入的搜索时空范围无关,真正摆脱了因服务器捆绑视频通道带来的访问热点问题。当搜索范围小的时候,搜索时间不会由于数据总量很大而耗费过多时间,这主要是由于master能很快定位到搜索范围的特征文件。当搜索范围扩大直至全扫描时,吞吐量也符合我们的预期。如果需要支持更大的吞吐量,只需要扩大集群增加worker即可。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!