一种基于N-gram向量和卷积神经网络的中文文本多分类方法与流程
本发明涉及一种基于n-gram向量和卷积神经网络的中文文本多分类方法,特别涉及一种用于计算n-gram权重的方法和嵌入n-gram向量的初始化cnn卷积核参数的方法,属于文本多分类的技术领域。
背景技术:
传统机器学习的方法中,支持向量机,决策树等方法已经较为成熟并且可以用来解决文本分类问题,由这些方法构建的文本二分类的分类器性能大多也有较好的表现。近年来,神经网络的模型受到了广泛的关注,基于卷积神经网络的模型用于不同的nlp任务也取得了良好的效果。但是,缺乏数据或不恰当的参数设置可能会大大限制泛化。为了提高性能,已经提出了许多改进的方法。金在2014年的emnlp会议上提出一种基于cnn的句子分类模型。本文使用不同尺寸的过滤器对文本矩阵进行卷积,然后使用max-池对每一滤光器提取的向量进行操作,最后每一个过滤器对应一个数字,把这些filter的结果拼接起来,就得到了一个表格中的句子的向量。最后的预测都是基于该句子的向量.kalchbrenner等人(convolutionalneuralnetworkformodelingsentences)则提出了一个基于cnn的句子建模框架,相比yoonkim的模型较为复杂,网络中的卷积层使用了一种称之为宽卷积(wideconvolution)的方式,紧接着是动态的k-max池化层。中间卷积层的输出即特征映射的大小会根据输入句子的长度而变化.hu等人提出一种基于cnn的句子建模,作者认为卷积的作用是从句子中提取出局部的语义组合信息,而多个featuremap则是从多种角度进行提取,也就是保证提取的语义组合的多样性.yin提出了一种叫双cnn-mi的架构,其中的bi-cnn表示两个使用连体框架的cnn模型,mi表示多粒度的交互特征。他提出的模型使用了多种类型的卷积,池化方法,以及针对得到的句子表征的局部进行相应的相似度计算,从而提升性能,但模型较复杂,耗时。提出了一种基于语义聚类和卷积神经网络的短文本建模方法。多尺度语义单元被检测并合并到卷积层,然后进行最大池操作。在这些模型当中,kim的模型虽然简单,但是却有着很好的性能.yezhang等人对这个模型进行了大量的实验,并给出了调参的建议,包括过滤区域大小,正则化参数等等。2017年li等在kimyoon模型的基础上,提出了一种新的权重初始化方法,改善cnn模型。但上述均是针对文本分类(大多都是二分类问题)所提出的,针对文本多分类包括中文文本的多分类的研究很少,目前闻彬,何婷婷,罗乐,等.提出了一种基于语义理解的文本情感分类方法。机器学习的方法针对特征抓取,不如卷积神经网络在这方面具有优势,有些语义特征被分析出来后但在后续利用这些特征的过程中造成特征的“流失”。
技术实现要素:
本发明要解决的技术问题是提供一种基于n-gram向量和卷积神经网络的中文文本多分类方法,根据有效词对文本特征的重要作用,提取有效的n-gram,提高文本分类准确率。
本发明采用的技术方案是:一种基于n-gram向量和卷积神经网络的中文文本多分类方法,包括以下步骤:
步骤1:文本分词:对待分类语料库中的所有中文文本分词,使用现有的中文分词工具,针对中文分词表现效果较好的中科院汉语分词系统。
步骤2:文本去噪:去除文本内容中停用词如:“了”“的”等。建立一个中文停用词词表stopwords.txt,对语料文本中的每个词进行遍历,出现在停用词词表中的词语将其删除,否则保留词语。中文文本去停用词的前提是已经完成了文本分词。
步骤3:对文本词语进行n元标注:经过n元标注后的文本,就变成了规则的词组,n的取值为:n=1,n=2,n=3。文本中的词语形成unigram、bigram、trigram三种形式的语义特征。
步骤4:计算n-gram权重r:计算每个词在文中的比重r,公式如下公式(1)词条t在该类别中的频率与词条t在其他几个类别中频率之和的比率。
上述公式中,i是指第i类文本,tn是指某类文本集合中的词项,
步骤5:n-gram词向量表达:将步骤4选择得到的n-grams表示为glove词向量。文本中的unigram表示为300维的词向量,bigrams表示为600维的词向量,trigrams表示为900维的词向量;
步骤6:n-gram聚类:把步骤5得到的unigram(300维的词向量),bigrams(600维的词向量),trigrams(900维的词向量)分别进行kmeans聚类。例如:对于搜狗数据集的it、财经、文化、健康和运动这五个类别,设置k=50,那么每个类别的语料进行n-gram聚类后将会得到50个300维的中心词向量,50个600维的词向量和50个900维的词向量。
步骤7:初始化滤波器参数:使用中心词向量初始化cnn参数,训练模型:将步骤6得到的中心词向量作为初始化卷积滤波器的参数。卷积层使用不同尺寸的滤波器,每种尺寸又可以设置多个滤波器,每个滤波器对句子矩阵做卷积运算,得到不同的特征图谱。使用上述得到的n-gram中心词向量嵌入到大小不同的滤波器的不同位置上,初始化滤波器的参数ws。unigram的向量嵌入到长度为3的滤波器的中间位置,bigrams的向量嵌入到长度为4的滤波器的中间位置,trigrams分别嵌入到长度为5的滤波器的中间位置,更新滤波器参数,达到语义嵌入滤波器的目的;
步骤8:卷积层:卷积层的滤波器尺寸为3,4,5三种滤波器,卷积层滤波器参数矩阵维度分别为[(100,1,3,300),(100,1,4,600),(100,1,5,900)],在卷积层获取待分类语料文本中每一个词的向量化表示并组成映射矩阵,卷积层参数矩阵与载入的映射矩阵作二维卷积运算。卷积运算后得到特征featuremaps,设置隐层神经元个数100个,就会得到100个featuremaps。
步骤9:池化层:对步骤8得到的featuremaps(特征图谱)做最大值池化,只记录特征的最大值。
步骤10:全连层:步骤9得到featuremaps的最大值,在全连层形成一维特征向量。
步骤11:输出层:将步骤10输出的一维特征向量输入softmax分类器进行多分类,预测文本的类别标签。
步骤12:性能评估:为了测试本专利提出的模型性能,采用十折交叉验证的方法,每次随机抽取9份作为训练集,1份作为测试集,经过十次epoch和十次交叉,取其十次运算平均的准确率。
本发明的有益效果是:
1、采用本发明提供的一种方法能够得到一系列最能表达文本语义特征的词语,从而能够判断文本的主题,是描述体育类还是描述科技类,在搜狗数据集上测试获得准确率为91.63%,在复旦大学公开分享的中文语料上获得的准确率为92.51%。
2、实现自动文本多分类,达到较好的文本分类效果。
附图说明
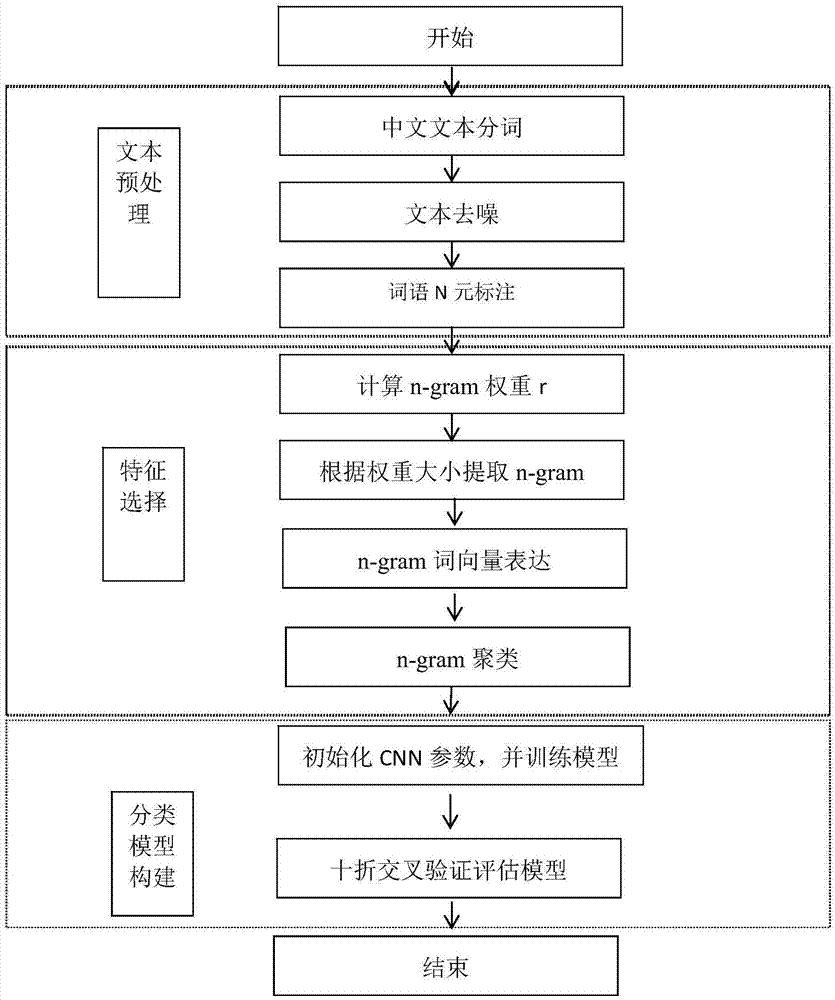
图1是本发明专利进行主题文本多分类的总体流程图;
图2是举例说明在某个数据集上根据n-gramr值选取合适n-gram的示意图;
图3和图4是有效n-gram向量初始化卷积滤波器参数的过程;
图5是本专利提出的方法在搜狗数据集和复旦大学中文语料上的实验结果的折线图,基于unigram标注下的多分类方法,评价方法十折交叉验证,评价标准是测试集准确率。更多标注模型下的结果请参考表格1。
具体实施方式
为了使本发明的目的、技术方案和特定更加清晰明白,以下结合实施例子和附图,对本发明进一步详细说明。
实施例1:如图1-5所示,本发明采用了计算加权选择重要特征的方法,并在卷积神经网络的卷积层进行卷积滤波的时候使用有效词特征的中心词向量代替滤波器随机初始化的参数。本发明具体改进归纳为以下几个方面:1)研究了重要的ngrams对于后续语义特征嵌入的影响;2)结合了unigarm、bigram和trigram分别聚类后的聚类中心向量,嵌入到不同宽度的滤波器中。实验证明,本发明提出的方法在两个公开的中文数据集上的实验结果,与其它方法相比基于n-gram向量和卷积神经网络的中文文本多分类方法在评价指标上有较大优势。
本发明的实施过程可以分为三个大步骤:
步骤1:文本预处理:首先对待分类语料的所有中文进行文本分词、文本去噪;然后进行文本的一元、二元、三元标注,分别得到unigram,bigram,trigram,即ngram;
步骤2:特征选择:计算文本语料中每个ngram在本类别中所占的比重r,对r降序排序,接着对按照特定的挑选规则选择出来的n-gram进行glove词向量的表达;最后对按照特定的挑选规则选择出来的n-gram(已被glove词向量表达)进行kmeans聚类,得到每一类n-gram的中心词向量。
步骤3:将步骤2得到的n-gram的中心词向量载入卷积神经网络层,初始化卷积核参数,训练文本分类模型,最后得出多分类结果,采用十折交叉验证的方法对模型评估。
进一步地,所述的步骤1的具体步骤如下:
步骤1.1:文本分词:对待分类语料的所有中文文本分词,分词工具是中科院汉语分词系统ictclas2014;
步骤1.2:文本去噪:对语料库分好词的文本删除原始文本中标点、符号、“的、这”等这些停用词;
步骤1.3:文本n元标注:遍历经过步骤1.1和步骤1.2处理过的语料库中的所有词,设置n=1,2,3,例如:我是一名研究生。经过分词后的这句话通过n元标注后的就得到:我我是我是一名我研究生我是研究生是是一名是一名研究生一名一名研究生。这样的标注文本。
进一步地,所述的步骤2的具体步骤如下:
步骤2.1:计算n-gram权重r:根据计算权重的公式(1),公式如下所示:
例如:在搜狗新闻数据集中,“比赛”“足球”这样的词语在运动类别的语料中所占的比重大于在it、财经、健康、文化类别的语料中所占的比重。“比赛”、“足球”等属于运动类别的语料中的重要特征。权重数值r通过log函数平滑处理,并根据数值大小对权重降序排序,图2所示的是搜狗新闻数据集5个类别所有n-gram的r值曲线图,选取能够代表此类别文本特征的一些n-gram,通过观察每个类别中n-gram的r曲线图,选择前20%的n-gram作为最能表达文本特征的词语;
步骤2.2:n-gram词向量表达:通过步骤2.1选择出来的n-gram训练出对应的glove词向量,unigram向量维度300维,bigrams是两个词向量的拼接,600维;trigrams,3个词向量的拼接,900维。例如:对于搜狗数据集的it、财经、文化、健康和运动这五个类别,分别得到unigram,bigrams,trigrams三种语义特征。
步骤2.3:ngramkmeans聚类:经过步骤2.2得到有效ngram特征都作为cnn初始化参数的话,计算复杂度提高,那么使用一簇特征向量的中心向量来表示一簇的特征同样能够有效初始化cnn滤波器参数。例如:对于搜狗数据集的it、财经、文化、健康和运动这五个类别,设置k=50,那么每个类别的语料进行n-gram聚类后将会得到50个300维的中心词向量,50个600维的词向量和50个900维的词向量。
进一步地,所述的步骤3的具体步骤如下:
步骤3.1:初始化cnn滤波器参数:将步骤2.3得到的n-gram中心向量去更新卷积核参数w,卷积核参数原本是随机初始化的,现在我们通过将n-gram词向量根据图3和图4的方法嵌入到滤波器的相应位置,其余位置上的参数仍然是随机初始化的即卷积核大小设为3,4,5,嵌入过程中,unigram的中心词向量只嵌入到卷积核为3的cnn模板中对其初始化,bigrams的中心词向量只嵌入到卷积核为4的cnn模板中对其初始化,trigrams词向量嵌入到卷积核5的cnn模板中对其初始化;
步骤3.2:卷积层:卷积层的滤波器尺寸可以设置为多个,例如3,4,5三种尺寸的滤波器,卷积层滤波器参数矩阵维度分别为[(100,1,3,300),(100,1,4,600),(100,1,5,900)],在卷积层获取待分类语料文本中每一个词的向量化表示并组成映射矩阵,映射矩阵为一个三维的张量(文本句子,整个语料库文本数,词向量维度),卷积层参数矩阵与载入的映射矩阵作二维卷积运算。卷积运算后得到特征featuremaps,设置隐层神经元个数100个,就会得到100个featuremaps。
步骤3.3:池化层:只记录特征的最大值。卷积操作以后对卷积层特征进行池化操作,一般使用k-maxpooling算法对step3.2得到的featuremaps进行下采样。
步骤3.4:全连层,对步骤3.3得到的最大值特征进行特征向量连接,形成一维特征向量。
步骤3.5:输出层:把步骤3.4的全连接层特征接入softmax分类器,对文本类别进行预测。
步骤3.6:性能评估:最后使用十折交叉验证法验证模型的性能。基于2个中文数据集,其评估结果如图5所示,表示本专利提出的模型在2个数据集上的效果,评价标准是测试集准确率;图5指本专利提出的方法基于基础数据集实验,评价标准为测试集准确率。与其他模型的结果对比请参考表格1。表格1是基于基础数据集的本专利方法和其他方法对比汇总表,评价标准是测试集准确率。
表格1各个模型在中文语料上的测试集准确率
本发明首先进行文本预处理:包括中文分词、去除停用词,对文本特征进行一元标注、二元标注、三元标注等;然后选择ngrams:计算语料中每个ngram的权重r,挑选每个类别中有效的n-gram,如:跑步、打篮球、利率、存折、坦克、战利品等主题表达明显的词语;接着对选择的ngram进行glove向量表达,将ngram特征进行词向量化后,并将词向量化后的ngram进行kmeans聚类,每一类别(汽车/运动/财经等)语料分别得到k个ngram(unigram、bigram、trigram)词向量的中心词向量;最后初始化滤波器参数:把所有ngram词向量的中心词向量作为卷积神经网络的初始值初始化滤波器参数,卷积模板能很好地捕捉特征,对主题文本进行准确地分类。
本发明一种基于加权n-gram向量模型和卷积神经网络结合的方法,在保证提取重要ngram后能够使用卷积神经网络的模板充分提取文本语义特征的方法,该方法改变传统的机器学习方法,采用卷积神经网络结构充分提取特征,并在文本处理过程中找出能够高效识别能够表达文本特征的词语,并使用词性列表进一步提高词语的精度。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以再不脱离本发明宗旨前提下做出各种措施进行改变。
- 还没有人留言评论。精彩留言会获得点赞!