一种互联网多源异质数据融合的选举预测方法与流程
本发明属于数据挖掘领域,涉及一种互联网多源异质数据融合的选举预测方法。
背景技术:
选举制度设立至今已有百余年的历史,对于大选结果的预测备受社会各界关注,涌现出了多类预测方法和技术。
最初的选举预测依赖民意调查,调查机构一般来自调查组织、各大主流媒体以及大学的研究机构,他们往往基于采样调查理论进行信息收集,辅以专家的意见修正,以民意测验测评政治风向进而得到预测结果。这种基于民调的预测方法优点是:实时性较强,临近选举对民意造成影响的新信息可以包含在结果中。但是,由于调查方法、样本大小以及民调机构政党倾向性等因素的影响,民调结果往往有偏。
后续,有部分学者和公司机构提出了基于宏观变量的预测方法。这类预测方法综合考虑国家层面宏观经济数据,构建预测模型对大选得票率进行预测。该类方法预测模型易得,对选举结果具有较强的解释性。但预测模型往往基于长期历史数据,时效性不强,无法在模型中引入临近选举的最新信息;且在候选人难分伯仲的情况下,很难做出准确预测。
随着互联网技术的迅速发展,信息呈爆炸式增长,选举信息呈现方式也越来越多样化,大数据中蕴含的丰富信息给选举预测带来了新的解决思路。多个国家或地区的选举都证明了诸如facebook和twitter等社交网络在得票率预测中的作用。基于互联网大数据的选举预测方法相较于民调方法和基于宏观变量的预测方法具有更强的实时性,但目前方法多属于事后分析,且仅基于单一社交媒体数据源,没有考虑到用户参与社交媒体平台的多样性。如此,得到的候选人支持率预测结果往往有较大的偏差,难以全面反映选举舆情。
技术实现要素:
为解决上述问题,本发明提出了一种获取选举得票率的预测方法,具体是一种互联网多源异质数据融合的选举预测方法;以参选人支持率为预测对象,通过融合社交媒体、搜索引擎和竞选主页等多源异构大数据,克服单一数据源在揭示民意方面的偏差,以实现实时跟踪以及预测候选人支持率的目标。
所述的互联网多源异质数据融合的选举预测方法,具体步骤如下:
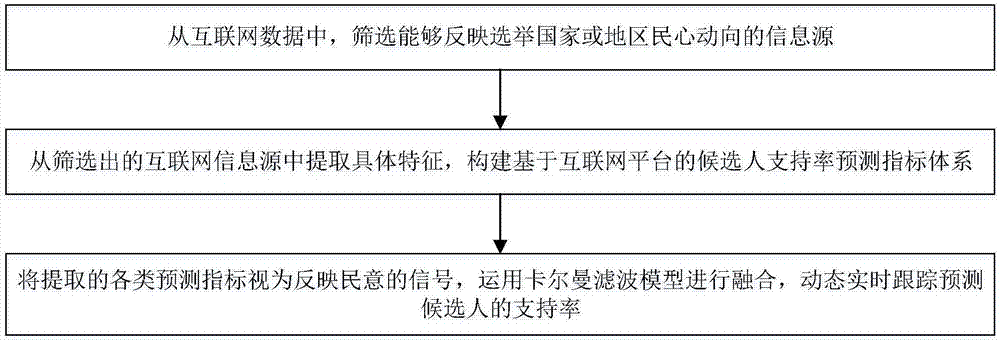
步骤一:从互联网数据中,筛选能够反映选举国家或地区民心动向的信息源。
筛选信息源的步骤具体为:
首先,针对选举国家或地区,查找该国家或地区的互联网管理和服务机构发布的研究报告,从报告中提取出网民广泛使用的互联网平台。
然后,通过对互联网平台的网站进行流量统计,得到该选举国家或地区的网站使用排名,筛选出使用最为频繁的网站。
最后,从使用最为频繁的网站中,保留社交网络类和搜索引擎类等带有用户生成内容的信息源。同时,在候选信息源中加入候选人竞选主页,进而通过流量统计网站,分析民众对于不同候选人竞选网站的关注程度。
步骤二:从筛选出的互联网信息源中提取具体特征,构建基于互联网平台的候选人支持率预测指标体系。
所述的预测指标包括:社交网络预测指标、搜索引擎预测指标和候选人竞选主页预测指标。具体构建过程如下:
(一)从数量和情感两个方面构建社交网络预测指标;
在数量方面,通过社交网络中提及候选人的发帖比例作为预测指标。
具体而言,若第t日在社交网络平台中提及候选人i的帖子数量为
或者以候选人每一日平均每条帖文获得的赞数作为网民对该候选人的支持度。
具体而言,若第t日候选人i在社交网络平台发布了n条帖子,每条帖子j获得赞数为
在情感方面,对社交网络中的文本信息进行情感分类,并计算积极情感和消极情感的比例,从而作为网民对候选人的支持率预测指标。
具体而言,若第t日社交网络中关于候选人i的发帖共有
(二)构建搜索引擎预测指标;
首先,选取选举国家或地区使用量最大的搜索引擎;
然后,获取候选人i在第t日的搜索量
(三)构建候选人竞选主页预测指标;
候选人i通过竞选网站在第t日的ip访问量为
步骤三:将提取的各类预测指标视为反映民意的信号,运用卡尔曼滤波模型进行融合,动态实时跟踪预测候选人的支持率。
具体过程如下:
步骤301、运用移动平均法对提取出的各类预测指标进行平滑,得到各预测指标平滑值
当对t+1日候选人i支持率进行预测时,先计算t-l至t日每日的各指标值
步骤302、根据民众对候选人i在t-1日的状态,演变计算该候选人i在第t日的真实状态值
b为控制输入变量系数矩阵;ut-1为控制输入变量;wt-1为过程噪声向量,该噪声向量服从均值为0、协方差矩阵为qt的多元正态分布,wt~n(0,qt)。
步骤303、在每一时刻,将各预测指标平滑值
测量值
步骤304、当第t日观测到测量值
步骤305、运用卡尔曼滤波将第t日的后验状态估计值和状态转移方程进行更新,得到下一日支持率的后验状态估计值。
本发明的优点在于:一种互联网多源异质数据融合的选举预测方法,考虑到用户使用互联网平台的多样性,具有数据源广泛、实时性强等特点,在舆情监控和观点分析等领域具有重要的应用价值。
附图说明
图1是本发明一种互联网多源异质数据融合的选举预测方法的流程图。
图2是本发明将提取的预测指标进行融合后动态实时跟踪预测候选人的支持率的流程图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
鉴于大数据体量巨大、数据类型繁多、价值密度低、处理速度要快等特性,本发明考虑到互联网平台上用户的广泛参与性,提出了针对选举这一类事件,从互联网平台中挖掘民意的方法;同时考虑到用户使用互联网平台的多样性,提出了基于卡尔曼滤波模型的多源异质数据融合的候选人支持率预测方法;该方法首先考虑选举国家或地区互联网使用情况,筛选出能够反映民心动向的互联网平台。进而,从纷杂的互联网平台中筛选出能够反映选举国家或地区民心动向的信息源;进而,针对每个筛选出的信息源本发明提出了民意预测指标提取方法;构建基于互联网平台的候选人支持率预测指标体系。最后,将提取出的指标视为反映民意的信号,运用信号处理模型——卡尔曼滤波模型实时对多源异质预测指标融合,实现候选人得票率的动态跟踪预测。
一种互联网多源异质数据融合的选举预测方法,具体流程如图1所示,实施步骤如下:
步骤一:筛选能够反映选举国家或地区民心动向的信息源。
面对丰富的互联网数据,找到能够反映选举国家或地区民心动向的可靠信源是准确预测选举结果的基础。在筛选信息源方面,主要分为两步:
步骤101,查找选举国家或地区互联网管理和服务机构发布的研究报告。
互联网管理和服务机构每年都会发布针对所在国家或地区的网络使用情况分析报告,通过这些研究报告可以对选举国家或地区的网路使用习惯形成初步了解,进而从报告中提取出选举国家或地区为网民广泛使用的互联网平台。
目前,国际范围内互联网管理和服务机构主要有:国际电信联盟(itu)、国际互联网协会(isoc)、国际互联网络信息中心(internic)等。亚太地区的互联网管理和服务机构主要有:亚太地区互联网协会(apia)、亚太地区互联网团体(apng)、亚太互联网络信息中心(apnic)、中国互联网络信息中心(cnnic)、日本网络信息中心(jpnic)、韩国网络信息中心(krnic)、马来西亚域名注册管理机构(mimos)等。美洲地区的机构主要包括:美洲地区ip地址管理及分配机构(arin)、美国域名注册管理机构(neustar)、加拿大互联网络注册局(cira)等。欧洲地区的机构主要有:欧洲国家顶级域名注册管理机构委员会(centr)、德国互联网络信息中心(denic)、英国互联网络信息中心(nominet)、欧洲地区ip地址管理及分配机构(ripe)。非洲地区主要有:非洲互联网络信息中心(afrinic)等。澳洲地区主要包括:澳大利亚域名注册管理机构(auda)等。
步骤102,查阅选举国家或地区的调查公司发布的网络使用调研报告。例如,alexa等网站流量统计网站可以给出各个国家或地区的网站使用排名。根据网站排名,筛选选举国家或地区使用最为频繁的网站。
在前两步的基础上,可以筛选出一批选举国家或地区使用量大的网站。由于使用频繁、民众广泛参与,这些网站更可能揭示出民心动向。
步骤103,考虑到预测指标应该尽可能揭示民众的观点,只保留访问量高的网站中社交网络类和搜索引擎类等这些带有用户生成内容的信息源。同时,考虑到大选话题的特殊性还应在候选信息源中加入候选人竞选主页,进而通过alexa等流量统计网站分析民众对于不同候选人竞选网站的关注程度。由此,可初步筛选出能够反映民心动向的互联网信息源。
步骤二:从筛选出的互联网信息源中提取具体特征,构建基于互联网平台的候选人支持率预测指标体系。
预测指标包括:社交网络预测指标、搜索引擎预测指标和候选人竞选主页预测指标。构建全面科学的指标体系是选情预测的关键。结合信息源具体特征,各渠道预测指标具体构建过程如下:
(一)从数量和情感两个方面构建社交网络预测指标;
社交网络因其交互性和及时性已成为民众获取信息、发表意见的主要平台。诸如facebook、twitter等社交媒体受到越来越多用户的青睐。这些社交媒体平台中允许网民通过点赞、评论等行为表达对大选候选人的看法。在挖掘这些用户生成内容中民众对候选人的倾向性时,可以从数量和情感两个方面构建预测指标。
在数量方面,facebook、twitter中讨论候选人的帖子数量反映了民众对于候选人的关注度。因此,可以通过社交网络中提及候选人的发帖比例作为预测指标。具体而言,若第t日在社交网络平台中提及候选人i的帖子数量为
此外,除了社交网络平台中候选人的提及可以反映民众支持度之外,许多社交网站还提供了点赞等功能。点赞可以认为是网民对于候选人言乱的强烈认同。因此,可以以候选人每一日平均每条帖文获得的赞数作为网民对候选人的支持度。具体而言,若第t日候选人i社交网络平台发布了n条帖子,每条帖子j获得赞数为
在情感方面,社交网络中提及候选人的发帖以及候选人个人主页中的评论体现了网民丰富的观点。为了挖掘这些文本信息中蕴含的情感倾向,可以对社交网络中的文本信息进行情感分类,并计算积极情感和消极情感的比例,从而可以作为网民对候选人的支持率预测指标。具体而言,若第t日社交网络中关于候选人i的发帖共有
(二)构建搜索引擎预测指标;
每一个用户在搜索引擎中的检索行为都是主动意愿的展示。为了帮助用户了解网民关注热点,多家搜索引擎提供了关键词搜索指数查询服务,例如谷歌趋势。这些指数以海量网民行为数据为基础,能够提供某个关键词在搜索引擎中的搜索规模,通常按日度更新。针对本发明考虑的情景,选取选举国家或地区使用量最大的搜索引擎,然后获取候选人i在第t日的搜索量
(三)构建候选人竞选主页预测指标;
竞选人为了宣传自己的执政主张、拉拢选票,通常会设立竞选主页。通过竞选网站,候选人一方面展示近期竞选活动与言论;另一方面通常会设立募捐页面,以获得开展竞选活动的资金支持。候选人竞选主页的ip访问量反映了民众对于候选人言行的关注。为了帮助网站调整优化,诸如alexa、seo综合查询站长工具等流量统计机构可以给出指定网站的每日ip访问量。若候选人i竞选网站在第t日的ip访问量为
步骤三:将提取的各类预测指标视为反映民意的信号,运用卡尔曼滤波模型进行融合,动态实时跟踪预测候选人的支持率。
步骤二中提取出的五类预测指标从不同角度反映了民众对候选人的关注。由于用户使用互联网平台的多样性以及有偏性,仅依赖于上述某一个指标做出的预测可能有偏。因此,需要一种能够融合多源异质指标,综合反映候选人支持度的方法。本发明将步骤二中提取出的五类预测指标视为民意反映的信号,运用信号处理方法——卡尔曼滤波模型融合多源异质信号。具体而言,实现方式包括以下步骤:
步骤301,预测指标平滑。为了反映候选人获得的支持率趋势,同时为了防止各个预测指标波动性对于预测结果的影响,首先要对提取出的五类预测指标进行平滑。本发明使用的方法为移动平均法。具体而言,在对t+1日候选人i支持率预测时,首先计算t-l至t时刻每日预测指标值
步骤302,卡尔曼滤波模型融合预测指标。卡尔曼滤波是一种利用线性系统状态方程,通过带有噪声的观测数据,对系统状态进行最优估计的算法。在本发明中,以线上多源数据中算得的各预测指标
其中,b为控制输入变量系数矩阵;ut-1为控制输入变量;wt-1为过程噪声向量,该噪声向量服从均值为0、协方差矩阵为qt的多元正态分布,wt~n(0,qt)。
步骤303,在每一时刻,构建测量值
其中,ht为状态值到测量值的映射矩阵;vt为测量噪声,且假设为高斯白噪声,vt~n(0,rt)。假设状态演变过程中,初始状态
步骤304,卡尔曼滤波包括两个阶段:预测和更新。首先在预测阶段,卡尔曼滤波根据上一时刻的后验状态预测出当前时刻的状态值
其中,kt为卡尔曼增益系数,用以衡量先验状态估计值和测量值在融合过程中的权重。记后验状态估计错误为
后验状态估计错误的协方差矩阵为
为了使得后验状态估计值和真实状态值尽可能接近,最小化后验状态估计错误,即等价于最小化
由此,可根据每日候选人支持率的先验状态估计值和各渠道支持率的观测值,运用卡尔曼增益系数加权融合得到当日的后验状态估计值。
步骤305,卡尔曼滤波的更新阶段,由当日的后验状态估计值和状态转移方程,得到下一日支持率的后验状态估计值:
本发明考虑到用户使用互联网平台的多样性,具有数据源广泛、实时性强等特点,克服了单一数据源在揭示民意方面的偏差,在未来具有广阔的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!