一种基于深度特征的大规模人脸检索方法和设备与流程
本发明实施例涉及图像检索技术领域,更具体地,涉及一种基于深度特征的大规模人脸检索方法和设备。
背景技术:
人脸检索是一项融合了计算机图像处理知识以及生物统计学知识的新兴生物识别技术,目前具有广阔的应用前景,例如时下人脸检索技术在诸如公园、工厂、广场、会议中心、体育场馆、学校、医院、商业街、酒店、餐饮娱乐场所、办公楼、电梯等场所均有应用。
人脸检索融合了计算机图像处理以及人物识别技术,在公共安全领域有着广阔的应用前景。快速增加的监控摄像头渐渐覆盖了城市的每个角落,网络上的视频数据也日益增加。这些网站和设备提供了安全和便利的同时,也带来了海量的视频数据,快速准确地从如此规模视频数据中快速识别人物身份,追踪其踪迹,是一件非常有挑战的任务也是检索领域的热门研究主题。
人脸的图像检索本质上是基于特征的检索,两张人脸图像的比较需要经过特征提取,特征向量相似度计算等步骤。传统的人脸检索算法是在大规模数据集上,直接遍历整个数据库的所有特征值进行计算,其计算任务会变得更加繁重,直接导致检索速度和准确性的急骤下降。
技术实现要素:
本发明实施例提供一种克服上述问题或者至少部分地解决上述问题的一种基于深度特征的大规模人脸检索方法和设备。
第一方面,本发明实施例提供了一种基于深度特征的大规模人脸检索方法,包括:
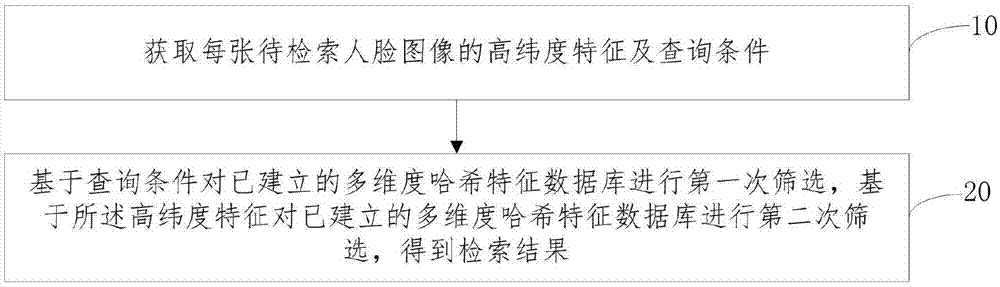
获取每张待检索人脸图像的高纬度特征及查询条件;
基于查询条件对已建立的多维度哈希特征数据库进行第一次筛选,基于所述高纬度特征对已建立的多维度哈希特征数据库进行第二次筛选,得到检索结果。
作为优选的,获取每张待检索人脸图像的高纬度特征及查询条件前,还包括:
获取人脸数据集中每个人脸图像的高纬度特征,将所述高纬度特征进行文本化输入到消息队列中,并基于二进制数据压缩方法进行压缩;
获取每张人脸图像的高纬度特征的哈希值,并基于人脸图像id、所述哈希值、压缩后的特征值及当前时间戳建立多维度哈希索引文件;
将所述多维度哈希索引文件批量刷写到磁盘,并对已经刷写到磁盘上行的多维度哈希索引文件实时建立高速缓存。
作为优选的,获取人脸数据集中每个人脸图像的高纬度特征,具体包括:
人脸图像以及对应的水平旋转镜像图像输入到深度网络模型中,得到第一高维度特征向量和第二高维度特征向量,所述第一高维度特征向量和第二高维度特征向量的维度相同;
将所述第一高维度特征向量、第二高维度特征向量融合,得到人脸图像的高纬度特征。
作为优选的,并基于二进制数据压缩方法对所述消息队列进行压缩,具体包括:
对消息队列中的每一条消息,基于二进制串f将其中的高纬度特征转化为二进制字节组;
其中,所述二进制串f的子串为:fi,j(1≤i,j≤n),n为二进制串f的长度,对于前缀二进制子串f1,j,记
式中,si为最长匹配的i值;用(s,h,c)表示二进制串的最长匹配结果,其中,s表示最长匹配时,字典中字节开始的位置;h为最长匹配字符串的长度,c表示最长匹配结束时的下一个字节。
作为优选的,获取每张待检索人脸图像的高纬度特征及查询条件,具体包括:
基于检索请求,获取待检索人脸图像及查询条件,对单张待检索人脸图像,通过深度网络模型获取待检测人脸图像的高纬度特征。
作为优选的,基于所述高纬度特征对已建立的多维度哈希特征数据库特征数据库进行第二次筛选,具体包括:
对高速缓存和刷写到磁盘中的高纬度特征进行解压缩,分批与待检索人脸图像的高纬度特征进行对比,并基于快速排序算法归并各批次的对比结果,并进行排序,将排序结果以文本方式返回。
作为优选的,并基于快速排序算法归并各批次的对比结果,并进行排序,具体包括:
基于当前数据规模m和期望检索结果数量k,为每个用于计算的线程平均分配任务量;
每个线程独立处理数据,并以大小为k的最小堆进行排序;
将各线程计算得到的结果进行归并,得到当前数据规模为m的情况下,topk的结果。
第二方面,本发明实施例提供了一种基于深度特征的大规模人脸检索设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如本发明实施例第一方面所述基于深度特征的大规模人脸检索方法的步骤。
本发明实施例提出一种基于深度特征的大规模人脸检索方法和设备,通过深度特征提取,缓冲消息队列构建,二进制特征压缩,建立多维度信息索引,并进行磁盘数据备份以及高速缓存;通过多维度特征索引以及基于内存的高速缓存进行精准过滤,使得大规模人脸图像数据集检索耗时大幅度降低,并且能够快速准确的得到匹配结果,实时性强,准确性高。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为根据本发明实施例的基于深度特征的大规模人脸检索方法示意图;
图2为根据本发明实施例的多维度信息索引建立示意图;
图3为根据本发明实施例的多维度哈希索引文件存储结构示意图;
图4为根据本发明实施例的检索过程示意图;
图5为根据本发明实施例的实时建立索引和检索流程示意图;
图6为根据本发明实施例的高速缓存在内存中的存储结构示意图;
图7为根据本发明实施例的排序和归并过程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
人脸识别技术经历了可见光图像人脸识别、三维图像人脸识别/热成像人脸识别、基于主动近红外图像的多光源人脸识别三层进化过程,再到如今的基于深度模型的人脸识别技术,算法不断精准演化,准确率能够达到99.7%,人脸识别技术逐渐进入越来越多新的应用领域。在公共安全领域,可以用于追踪通缉罪犯;在日常生活领域,人们可以刷脸支付,刷脸签到,刷脸门禁,刷脸取票等。因此,在大规模人脸数据,准确快速的人物识别具有极高的现实意义。
传统的人脸检索算法是在大规模数据集上,直接遍历整个数据库的所有特征值进行计算,其计算任务会变得更加繁重,直接导致检索速度和准确性的急骤下降。
针对现有技术中的上述缺陷,本发明是实施例通过多维度特征索引以及基于内存的高速缓存进行精准过滤,使得大规模人脸图像数据集检索耗时大幅度降低,并且能够快速准确的得到匹配结果。以下将通过多个实施例进行展开说明和介绍。
本发明实施例提供了一种基于深度特征的大规模人脸检索方法,如图1所示,包括:
步骤10、获取每张待检索人脸图像的高纬度特征及查询条件;
步骤20、基于查询条件对已建立的多维度哈希特征数据库进行第一次筛选,基于所述高纬度特征对已建立的多维度哈希特征数据库进行第二次筛选,得到检索结果。通过预先建立多维度哈希特征数据库,即多维度哈希索引文件的集合,获取人脸数据集中每个人脸图像的高纬度特征,将所述高纬度特征进行文本化输入到消息队列中,并基于二进制数据压缩方法进行压缩;获取每张人脸图像的高纬度特征的哈希值,并基于人脸图像id、所述哈希值、压缩后的特征值及当前时间戳建立多维度哈希索引文件;将所述多维度哈希索引文件批量刷写到磁盘,并对已经刷写到磁盘上行的多维度哈希索引文件实时建立高速缓存。
在本实施例中,通过预先建立多维度哈希特征数据库存储,通过建立高维度信息索引,再根据检索任务,以及基于内存的高速缓存进行精准过滤,使得大规模人脸图像数据集检索耗时大幅度降低,并且能够快速准确的得到匹配结果。
在上述实施例的基础上,获取每张待检索人脸图像的高纬度特征及查询条件前,还包括:
获取人脸数据集中每个人脸图像的高纬度特征,将所述高纬度特征进行文本化输入到消息队列中,并基于二进制数据压缩方法进行压缩;消息队列技术,能够保证所有的数据至少被处理一次,并且拥有消息备份机制,保证数据不会丢失。
获取每张人脸图像的高纬度特征的哈希值,并基于人脸图像id、所述哈希值、压缩后的特征值及当前时间戳建立多维度哈希索引文件;
将所述多维度哈希索引文件批量刷写到磁盘,并对已经刷写到磁盘上行的多维度哈希索引文件实时建立高速缓存。
在本实施例中,通过上述步骤建立高维度信息索引,包括深度特征提取,缓冲消息队列构建,二进制特征压缩,多维度信息索引建立,磁盘数据备份以及高速缓存建立,如图2所示,具体步骤为:
步骤01、依次将人脸数据集中的图像输入到深度神经网络,先进行人脸检测,然后提取人脸的高维度特征;
步骤02、对步骤01得到的高维度特征进行文本化输入到消息队列中;
步骤03、从步骤02消息队列中消费接收到的特征,并使用二进制数据压缩算法对其进行压缩;
步骤04、计算步骤03获取的高维度特征的哈希值,并且与压缩后的特征值以及当前时间戳共同建立成多维度哈希索引文件,如图3所示;
步骤05、将步骤04建立好的多维度哈希索引文件批量刷写到磁盘。
步骤06、对步骤05已经刷写到磁盘上行的文件实时建立高速缓存。
在本实施例中,哈希索引(hashindex):索引用做内存优化表的入口点。能够快速定位到需要的数据。哈希索引使用特定的哈希函数去计算请求数据并得到哈希码,通过这个哈希码能够使得类似数据映射到一起,可以用于数据的初步过滤。
在上述实施例的基础上,获取人脸数据集中每个人脸图像的高纬度特征,具体包括:
人脸图像以及对应的水平旋转镜像图像输入到深度网络模型中,得到第一高维度特征向量和第二高维度特征向量,所述第一高维度特征向量和第二高维度特征向量的维度相同;
将所述第一高维度特征向量、第二高维度特征向量融合,得到人脸图像的高纬度特征。
在本实施例中,高纬度特征即人脸的深度特征,深度特征(deepfeature):图像的深层次特征,图像特征是对图像信息的集中简化表达,深度特征是利用深度学习去处理图像,经过层层传递、不断抽象,获取到的能够更好的描述隐藏在图像内部本质的特征信息。
具体的,步骤01:依次将人脸数据集中的图像输入到深度神经网络,先进行人脸检测,然后提取人脸的高维度特征。人脸检测方法就是根据下式所示:
conv=σ(imgmat·w+b)
上式中,“σ”表示激活层函数,“imgmat”表示灰度图像矩阵,“w”表示卷积核,“·”表示卷积操作,“b”表示偏置值。计算过程首先用sobel-gx卷积核来对图像做卷积,即imgmat·w,然后对计算结果(一个矩阵)的每个元素都加上b(偏置值),并将所得结果(矩阵)中的每个元素都输入到激活函数,这里去sigmoid函数如下式表示:
f(x)=1/(1+e-x)
上述计算之后会得到人脸图像以及人脸旋转之后图像的实值特征向量,将两个特征向量融合并降维的结果作为人脸的实值特征。
将人脸图像以及水平旋转镜像图像输入到深度网络模型中,得到两个高维度特征向量,并通过特征融合函数融合成一个新的特征向量,具体的融合函数如下:
gx=max(ax,bx),x=1,2,…,n
上式中,x表示第x维,n是正向量的维数。
在上述各实施例的基础上,并基于二进制数据压缩方法对所述消息队列进行压缩,具体包括:
对消息队列中的每一条消息,基于二进制串f将其中的高纬度特征转化为二进制字节组;
其中,所述二进制串f的子串为:fi,j(1≤i,j≤n),n为二进制串f的长度,对于前缀二进制子串f1,j,记
式中,si为最长匹配的i值;用(s,h,c)表示二进制串的最长匹配结果,其中,s表示最长匹配时,字典中字节开始的位置;h为最长匹配字符串的长度,c表示最长匹配结束时的下一个字节。
在本实施例中,步骤02:对步骤01得到的高维度特征进行文本化输入到消息队列中。由于本发明实施例方法提取人脸图像文件的索引实时建立的,每秒数据量能够达到数百张,所以为了保证各个模块之间和稳定和低耦合以及数据的可靠性传输,在处理层和发送曾引入了消息队列,消息队列可以使用kafka。当客户端通过消息队列的producer传入消息,消息队列会对消息做多级备份,当某条消息的处理结果超时没有收到或者收到consumer端发送消息处理失败的请求,那么消息队列就会从备份的数据里重新发送该条消息。单条消息的内容以及格式如下表1所示:
表1单条消息的内容格式
步骤03:从步骤02消息队列中消费接收到的特征,并使用二进制数据压缩算法对其进行压缩。从消息队列中接收到的消息内容以及格式如上表,每收到一条消息,将其中的特征(由浮点数组成的数组)转化成字节(二进制)数组,然后经过如下步骤进行压缩。
首先,定义特征向量转化的二进制串为f,其长度为n,二进制串f的子串为fi,j(1≤i,j≤n),n为二进制串f的长度,对于前缀二进制子串f1,j,记
定义si为所有情况下的最长匹配的i值,即:
用(s,h,c)表示二进制串的最长匹配结果,其中,s表示最长匹配时,字典中字节开始的位置;h为最长匹配字符串的长度,c表示最长匹配结束时的下一个字节。
在上述实施例的基础上,步骤04具体包括:计算步骤03获取的高维度特征的哈希值,并且与压缩后的特征值以及当前时间戳共同建立成多维度哈希索引文件。如图3所示,索引文件的构造说明如下:
索引信息存储都在文档(document)数据结构中,构建结束后经过分析器(analyser)进行封装,最后通过索引生成器(indexwriter)将文件刷写到磁盘中。
具体的,步骤04中哈希索引文件包括四个域,分别如下:高维度特征向量经过哈希函数计算所得哈希索引、压缩后的高维度特征索引、人脸图像的唯一id、人脸图像处理的时间戳;
其中哈希值的计算使用的是汉明距离下的lsh哈希函数,其定义如下:
其中r是一个从1到d'之间产生服从均匀分布的随机整数;对于函数h(p),当p,d的曼哈顿距离为d的时候,他们被哈希成相同哈希值的概率为:
在上述实施例的基础上,步骤05中索引文件会被存储到本地磁盘中,并且按照索引文件中存储时间戳的域进行归类,按照日期进行存储,且所有的图像索引文件都已经被刷写在磁盘中,因此不用担心计算机断电导致的内存数据丢失。
步骤06:对已经刷写到磁盘上行的文件实时建立高速缓存。将索引文件记录在磁盘上能够保证数据不会丢失,但是查询的时候由于磁盘的随机读写机制,会导致查询效率特别低。高速缓存基于内存高速io的特性,能够保证在一秒内遍历百万张人脸图片,且能够利用内存的高速io特性来提高检索速度的。
在索引文件刷写到磁盘中的同时,把索引文件中的内容缓存到内存中,使用的是hashmap数据结构,用图片的唯一id作为hashmap的key,value中存储图片的特征、时间戳以及存储地址。hashmap在内存中存储结构图3。
实时建立索引的同时,支持实时进行人脸检测和查询。检索请求需要包含的信息如下表所示:
表2检索请求信息
表中,url和threshold为必填项。如果指定starttime和endtime会过滤该时间范围内的索引,如果没有指定starttime和endtime则会返回所有符合条件的结果。如果指定top,那么则会按照相似度从小到大的顺序返回指定数量的结果,如果没有指定top,则会返回所有相似度大于threshold的结果。
在上述各实施例的基础上,基于所述高纬度特征对已建立的多维度哈希特征数据库特征数据库进行第二次筛选,具体包括:
对高速缓存和刷写到磁盘中的高纬度特征进行解压缩,分批与待检索人脸图像的高纬度特征进行对比,并基于快速排序算法归并各批次的对比结果,并进行排序,将排序结果以文本方式返回。
在本实施例中,如图4、图5所示,步骤20具体包括:
步骤21、处理检索请求,分析获取图像以及查询条件。
步骤22、将单张待请求的人脸图像经过步骤01所使用的方法提取人脸的高维度特征。
步骤23、使用步骤21中解析到的查询条件对缓存和磁盘中的索引数据进行初步过滤。
步骤24、对缓存和磁盘中的特征进行解压缩,分批与步骤22中提取的特征进行比对。
步骤25、对步骤24得到的结果进行归并并且进行快速排序求取topk,得到排序结果后以文本的方式返回。
具体的,经过步骤23,对步骤21接收到的请求条件(时间等)初步过滤之后,需要对压缩后的深度特征进行解压缩,解压缩过程需要依靠以上步骤13压缩时建立的字典表(s,h,c),一共有三类情况:
s等于0并且h等于0,直接解码c;
s大于等于h,解码为字典的s位置到s+h+1位置;
s小于h,会出现循环编码,需要从左到右循环拼接。
步骤s25中,如图6所示,当待检索的数据量特别庞大的时候,根据当前cpu和内存空余资源计算,可以支配的用于计算的线程数,然后为每个线程平均分配任务量。
为了加速排序过程,降低时间复杂度,引入了mapreduce的思想,能够充分利用cpu的计算资源,占用内存少,时间复杂度为o(nlogn),排序和归并过程如图7所示,基于分治思想,假设当前数据规模为n,需要的检索结果数量为k,则排序过程如下:
当待检索的数据量特别庞大的时候,根据当前cpu和内存空余资源计算,可以支配的用于计算的线程数,然后为每个线程平均分配任务量;
每个线程独立处理自己的数据,并且使用大小为k的最小堆进行排序,排序算法表达式如下:
将各部分线程计算得到的结果进行归并,得到当前数据规模为n的情况下,topk的结果。
将各线程计算得到的结果进行归并,得到当前数据规模为m的情况下,topk的结果。
本发明实施例提供了一种基于深度特征的大规模人脸检索设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如本发明上述各实施例所述基于深度特征的大规模人脸检索方法的步骤,例如包括:
获取每张待检索人脸图像的高纬度特征及查询条件;
基于查询条件对已建立的多维度哈希特征数据库进行第一次筛选,基于所述高纬度特征对已建立的多维度哈希特征数据库进行第二次筛选,得到检索结果。通过预先建立多维度哈希特征数据库,即多维度哈希索引文件的集合,获取人脸数据集中每个人脸图像的高纬度特征,将所述高纬度特征进行文本化输入到消息队列中,并基于二进制数据压缩方法进行压缩;获取每张人脸图像的高纬度特征的哈希值,并基于人脸图像id、所述哈希值、压缩后的特征值及当前时间戳建立多维度哈希索引文件;将所述多维度哈希索引文件批量刷写到磁盘,并对已经刷写到磁盘上行的多维度哈希索引文件实时建立高速缓存。
本实施例公开一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法实施例所述的基于深度特征的大规模人脸检索方法的步骤,例如包括:
获取每张待检索人脸图像的高纬度特征及查询条件;
基于查询条件对已建立的多维度哈希特征数据库进行第一次筛选,基于所述高纬度特征对已建立的多维度哈希特征数据库进行第二次筛选,得到检索结果。通过预先建立多维度哈希特征数据库,即多维度哈希索引文件的集合,获取人脸数据集中每个人脸图像的高纬度特征,将所述高纬度特征进行文本化输入到消息队列中,并基于二进制数据压缩方法进行压缩;获取每张人脸图像的高纬度特征的哈希值,并基于人脸图像id、所述哈希值、压缩后的特征值及当前时间戳建立多维度哈希索引文件;将所述多维度哈希索引文件批量刷写到磁盘,并对已经刷写到磁盘上行的多维度哈希索引文件实时建立高速缓存。
本实施例中还提供了一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行上述各方法实施例所述的基于深度特征的大规模人脸检索方法的步骤,例如包括:
获取每张待检索人脸图像的高纬度特征及查询条件;
基于查询条件对已建立的多维度哈希特征数据库进行第一次筛选,基于所述高纬度特征对已建立的多维度哈希特征数据库进行第二次筛选,得到检索结果。通过预先建立多维度哈希特征数据库,即多维度哈希索引文件的集合,获取人脸数据集中每个人脸图像的高纬度特征,将所述高纬度特征进行文本化输入到消息队列中,并基于二进制数据压缩方法进行压缩;获取每张人脸图像的高纬度特征的哈希值,并基于人脸图像id、所述哈希值、压缩后的特征值及当前时间戳建立多维度哈希索引文件;将所述多维度哈希索引文件批量刷写到磁盘,并对已经刷写到磁盘上行的多维度哈希索引文件实时建立高速缓存。
综上所述,本发明实施例提出一种基于深度特征的大规模人脸检索方法和设备,通过深度特征提取,缓冲消息队列构建,二进制特征压缩,建立多维度信息索引,并进行磁盘数据备份以及高速缓存;通过多维度特征索引以及基于内存的高速缓存进行精准过滤,使得大规模人脸图像数据集检索耗时大幅度降低,并且能够快速准确的得到匹配结果,实时性强,准确性高。
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!