基于时间序列聚类的未成年犯罪地区簇的划分方法与流程
本发明涉及公共安全技术领域,尤其涉及一种基于时间序列聚类的未成年犯罪地区簇的划分方法。
背景技术:
随着大数据时代到来和人工智能技术的发展,利用大数据为基础进行相关分析的技术已经成为未成年犯罪分析技术研究的热点。而为了有效地对全国各地区未成年犯罪特征进行分析,在获取全国各地区未成年犯罪数据后,有关警务部门必须进行快速、准确地分组,判断哪些地区具有相似犯罪特征,采取针对性地干预措施。因此,针对未成年犯罪,将全国各地区进行分组是未成年犯罪研究中的基础工作,对警力分配、犯罪预防、犯罪干预等有重要意义。
聚类(clustering)是对数据进行分类,将相异的数据尽可能地分开,而将相似的数据聚成一个类别(簇),使得同一类别的数据具有尽可能高的同质性(homogeneity),类别之间有尽可能高的异质性(heterogeneity),从而方便从数据中发现隐含的有用信息。聚类主要分为:划分聚类、层次聚类、模糊聚类和基于密度聚类,经典算法有:k-means算法、k-中心点算法、em算法等。聚类典型的应用包含几方面:(1)协同过滤:用于推荐系统和用户细分;(2)动态趋势检测:对流数据进行聚类,检测动态趋势和模式;(3)用于多媒体数据、生物数据、社交网络数据的应用。聚类已广泛应用在不同领域,并取得了良好的应用效果,但在未成年犯罪领域应用较为欠缺。
时间序列(timeseries)是一组按照时间发生先后顺序进行排列的数据点序列。通常一组时间序列的时间间隔为一恒定值(如1秒,5分钟,12小时,7天,1年),因此时间序列可以作为离散时间数据进行分析处理。时间序列广泛应用于数理统计、信号处理、模式识别、计量经济学、数学金融、天气预报、地震预测、脑电图、控制工程、航空学、通信工程以及绝大多数涉及到时间数据测量的应用科学与工程学。
目前我国未成年犯罪预测分析技术多采用简单的统计方法,如通过对两个特定年份未成年犯罪抽样调查资料的比较研究,结合犯罪逻辑学,对我国未成年犯罪数量呈现趋势、种类变化、地区分布等做一个简单的总结。随着犯罪数据的不断增多,数据复杂程度的增加,传统的统计方法具有很大局限性。
本专利采用时间序列分析平滑原始犯罪数据中受噪声干扰的点,还原地区实际的未成年犯罪规律,同时,建立地区犯罪可能性模型,从而方便选取k个质心,针对于k均值聚类中所需的距离,利用动态时间规整算法(dynamictimewarping)来确定。动态时间规整算法最早出现于语音识别中,解决了发音长短不一的问题。本发明将其应用在时间序列中,可以解决时间序列长短不一致的问题。由于全国各地区差异,未成年犯罪的统计存在时间跨度不一致的情况,利用传统的欧式距离效果较差,而dtw算法可以解决这一问题。
本专利方法可以很好地排除噪声对于地区犯罪规律的影响,并且可以解决时间序列长度不一致问题,同时依据建立的地区犯罪可能性模型可以方便选取k均值聚类所需质心,取得良好的未成年犯罪地区分组效果。
技术实现要素:
本发明要解决的问题在于:全国各地区未成年犯罪数据统计具有时间跨度不一致、部分点受噪声影响明显特点,同时单纯时间序列分析无法对地区进行分组。
为了解决上述问题,本发明提供如下方案:
本发明提供了一种基于动态时间规整/规划(dynamictimewarping,dtw)算法的k均值聚类未成年犯罪地区簇的划分方法,k均值聚类中所用的距离采用动态时间规整/规划算法来确定,这是因为由于各地区未成年犯罪统计差异,从而形成时间序列长度不一致的问题,利用传统欧式距离效果较差。
在进行未成年犯罪地区的簇划分前,对各地区未成年犯罪数据进行统计性描述;对于缺失值采用中位数填充;异常值处理,识别错误点,将其删除,避免将其纳入统计;重复值处理,删除重复点;噪声处理,即对明显异于该地区应有犯罪规律的数据点,利用时间序列分析进行平滑处理;特别地,异常值处理是指将地区未成年犯罪事件发生的经纬度绘制在地图上,直观识别不在地区中的点,将其删除。噪声处理,是指利用时间序列分析对距离均值超过三倍标准差的数值进行平滑,这些犯罪数据值虽是真实情况的记录,但是通常由于外部环境突然变化,而出现不符合该地区的犯罪规律,故需要进行平滑处理,排除外部突发条件对该地区应有犯罪特征的影响,从而才可以对地区进行正确分组。
对于k均值聚类算法初始所需的k个质心,依据地区经济发展水平、人口数量、未成年犯罪率等参数,建立地区犯罪线性概率统计模型,输入各地区参数值后进行计算得到犯罪概率值,依据各地区犯罪概率值进行排序,形成一个地区序列,然后从序列中等距的选取k(k具体值依据研究目的而定)个地区作为质心。
附图说明
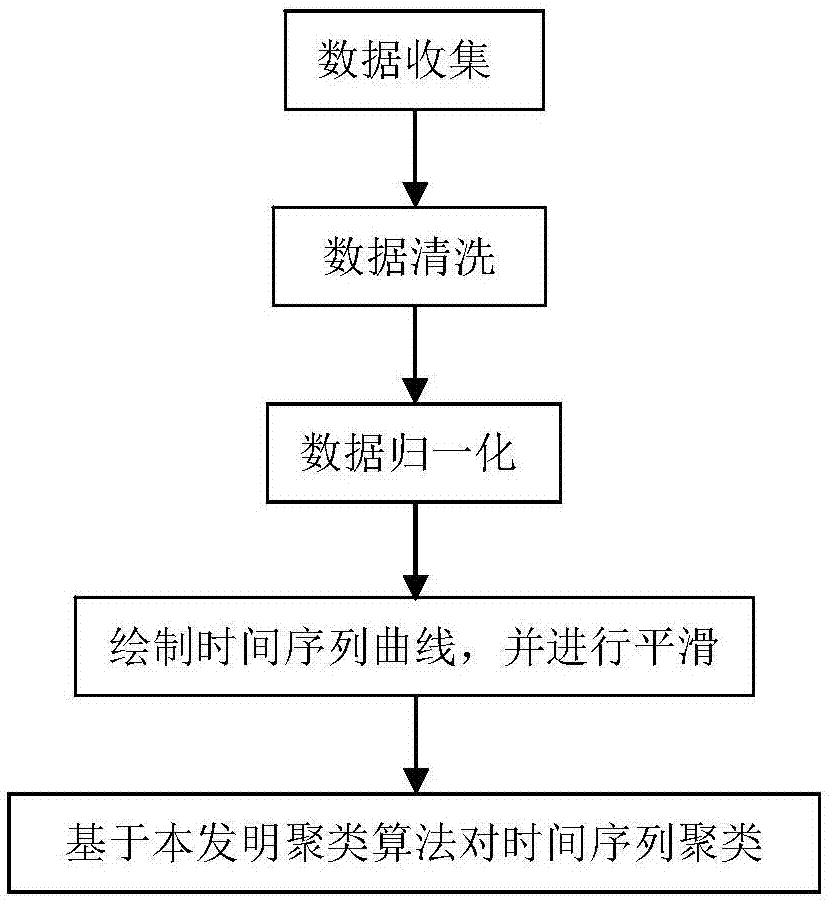
图1:总流程图;
图2:某地区犯罪数量频数分布直方图;
图3:某地区犯罪数量散点图;
图4:对应于正态分布的qq图;
图5:犯罪数据地理分布图;
具体实施方式
步骤1,收集各地区未成年犯罪数据,进行数据清洗,提取所需数据:
步骤1.1:收集各地区近三年的未成年犯罪数据,收集的数据主要包括:时间、经纬度、类型、犯罪年龄等,同时需要收集各地区教育信息、经济发展状况、人口数量、留守儿童比例、地区气候等数据;
步骤1.2:对数据进行描述性统计,查看哪些数据是不合理的,同时也可以获取数据的基本情况。可以通过分析不同地区的犯罪总数、平均数量(以周为单位)、犯罪人年龄层次、不同犯罪类型所占比例等等,了解数据的基本情况。此外,通过绘制直方图(图1)、点图(图2)、q-q图(图3)等方式了解数据的质量,有无异常点;
步骤1.3:利用经纬度信息,将犯罪事件发生地点映射到地图上(图4),可以直观地识别出异常点,同时查找出重复数据,将重复值、异常点删除;
步骤1.4:对数据按周进行汇总,对于周缺失值,利用中位数进行填充;
步骤2,对清洗后的数据归一化,并绘制时间序列曲线,对时间序列曲线进行平滑处理:
步骤2.1:对各地区未成年犯罪数量建立时间序列,时间序列的时间间隔选取为一周,例如地区一为x=(x1,x2,x3...xn),地区二为y=(y1,y2,y3...ym),由于各地区统计差异,m与n可能不相等,同时由于各地区数量差别较大,我们需要取的是地区犯罪规律相似的分组,故需对各地区时间序列进行归一化,利用:
步骤2.2:依据时间序列绘制时间序列曲线,对于距离均值超过三倍方差的数值,视为噪声点,通常是由于外部环境巨变,例如:自然灾害、大型活动、专项整治等事件的发生导致的,利用arima模型对这些点进行平滑,还原该地区应有的未成年犯罪规律。具体方式为:采取df检验判断时间序列是否平稳;若序列非平稳,利用差分的方法,使序列平稳,差分是采用特定瞬间和它前一个瞬间的不同的观察结果,如果一阶差分效果没有达到预期,可采取二阶或三阶差分;得到平稳序列后,利用arima模型,对其进行拟合;最后回滚到原始序列。将原曲线中的噪声点(距离均值超过三倍方差)全部替换为利用arima模型拟合出来的点,对于非噪声点保持不变。
其中,arima模型有三个参数:p,d,q。
p--代表预测模型中采用的时序数据本身的滞后数(lags),也叫做ar/auto-regressive项;
d--代表时序数据需要进行几阶差分化,才是稳定的,也叫integrated项;
q--代表预测模型中采用的预测误差的滞后数(lags),也叫做ma/movingaverage项;
arima用数学形式表示为:
其中,φ表示ar的系数,θ表示ma的系数;
步骤3,基于本发明聚类算法对时间序列进行聚类:
步骤3.1:动态时间规整/规划(dynamictimewarping,dtw)算法确定k均值聚类所需距离,假设给定两个地区未成年犯罪序列,地区一x=(x1,x2,x3...xn)和地区二y=(y1,y2,y3...ym),同时序列中点到点的距离确定为欧式距离,dtw的核心在于确定点点之间的对应关系。记:
φ(k)=(φx(k),φy(k))(2)
其中φx(k),的可能值为1,2…n,φy(k)可能值为1,2…m,k=1,2…t。也就是说,求出t个从x序列中点到y序列中点的对应关系。确定了φ(k)后,就可以求解两个序列的累积距离,记:
dtw最终需要寻找一条最合适的φ(k)扭曲曲线,使得累计距离最小,即:
具体来讲,dtw首先确定地区一和地区二序列点之间的欧式距离,获取一个序列距离矩阵m(n行m列),然后依据m生成累积距离矩阵mc,其生成方式:
第一行第一列元素为m的第一行第一列元素;
其他位置元素mc(i,j)=min(mc(i-1,j-1),mc(i-1,j),mc(i,j-1))+m(i,j);(5)
那么mc(n,m)即为地区一和地区二的距离;
步骤3.2:建立地区犯罪线性概率统计模型,确定k均值聚类中所需的初始k个质心。实际上,全国各地区教育信息、经济发展状况、人口数量、未成年犯罪率、留守儿童比例、气候等有着较大区别,这些因素可以作为衡量地区未成年犯罪风险的因子,建立如下犯罪线性概率统计模型:
p=w1f1+w2f2+w3f3+...(6)
p为衡量该地区未成年犯罪风险的一个数值,wi为权重,fi为衡量该地区未成年犯罪风险的因子。依据统计数据,可以将fi量化,针对每个fi,例如经济发展状况,可将地区划分为发达地区、次发达地区、欠发达地区、贫困地区四个等级,然后依据等级进行赋值。需要确定每个fi对p产生的影响,即wi的大小,为了获取wi的大小,可采用训练分类器的方式,该分类器用来判断某一时间段内未成年犯罪数量上升还是下降:
1)在已有未成年犯罪数据集d下,分别训练缺少某个因子fi的分类器;
2)在测试集下分别测试n(n为因子数目)个分类器的效果,并统计错误分类个数分别表示n个因子下的错误分类数;
3)对2)中求出的做归一化处理,即可得到权重值;
依据各个地区的p值,对地区进行排序,从该排序中等距选取k个地区作为初始k个质心;步骤4,输出划分的簇:
得到划分的簇,可以为进一步分析未成年犯罪提供有力支撑,同时也给有关警务部门制定预警策略提供科学的依据。
- 还没有人留言评论。精彩留言会获得点赞!