人脸图像数据库的数据去重方法与系统与流程
本发明涉及人脸识别技术领域,具体而言涉及一种人脸图像数据库的数据去重方法与系统。
背景技术:
对于目前人脸识别模型的训练,理论上来说数据集越大,训练出来的模型精度就会越高,前提是建立在数据集足够干净的情况下,否则即使数据集很大,训练出来的模型精度未必就会更高,就是说在相同大小的数据集下,数据集越干净,训练出的模型精度越高。
目前很多数据集的采集都是部署平台采集的,或者从视频中抓拍的,以及人工拍摄的等等,都不可避免的出现将某个人的照片放到了另外一个人的目录下的情况。当数据量较小的情况下,人工还是可以审核的。当数据集达到几百万,甚至几千万的时候,人工已经无法进行审核。
技术实现要素:
本发明目的在于提供一种人脸图像数据库的数据去重方法与系统,能够将脏数据去除,提高训练模型的精度。
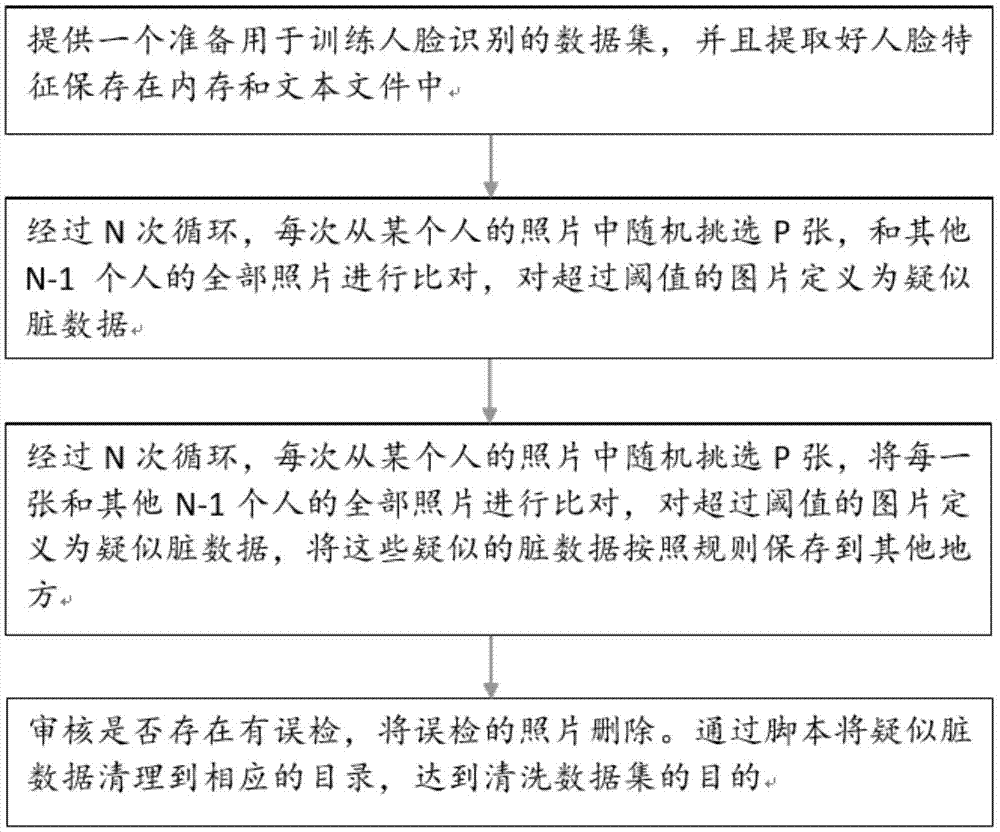
为达成上述目的,本发明提出一种人脸图像数据库的数据去重方法,包括以下步骤:提供一个用于训练人脸识别的数据集,数据集按照每个人一个目录,共n目录,目录中包括对应人的m个照片文件;首先提取所以人脸照片的人脸特征信息保存在文本文件和内存中,从每个人的目录中随机挑选p张照片做为比对照片,将这p张照片中的每一张照片与剩下的n-1(除了被选中的目录)个目录下全部照片进行比对,将超过预先设置好的阈值的照片按照原路径格式拷贝出来并且按照规则从新命名。一共进行n次上述比对,得到疑似的脏数据集。最后确认有没有误检,将脏数据从之前的数据集中清理到相应的目录下,完成去重。
在一些实施例中,人脸图像数据库的数据去重方法具体包括以下步骤:
步骤1、提供一用于训练人脸识别的数据集,所述数据集内包括多个照片,照片按照人进行存储,对应n个人的n个目录,每个目录中包含m张照片,n和m均为大于1的正整数;
步骤2、遍历数据集的目录,对对应照片提取人脸特征,并保存到文本文件中;
步骤3、从1-n的顺序遍历全部的目录,每次从一个目录中随机选择p张照片,将这p张照片分别和剩下的n-1个目录下的全部照片进行比对,得到比对的前y张,同预先配置的第一分数阈值进行比较,如果存在前y张至m张的分数超过预先配置的第一分数阈值,则设置其为疑似重复照片,将其拷贝到result结果目录中,并且按照当前照片所在的目录存储,p≤m,y≤m,;
步骤4、在步骤3执行完后,所有疑似重复照片都保存在result结果目录下,判断result结果目录下的照片数量是否超过设定阈值,如果超过,则更新所述第一分数阈值,重复执行步骤3;如果不超过设定阈值,则进入步骤5;
步骤5、对result结果目录中的疑似重复照片进行审核确认,检验挑选出的疑似重复照片是否真的是重复照片,并对误检的照片进行删除操作,正确的照片保留;
步骤6、根据result结果目录中保留下来的照片,将原先的数据集重新整理:遍历result结果目录下的全部文件,对文件名进行解析,获取到相应的原始照片路径,目标照片路径,将原始照片路径拷贝到目标照片路径下,如果存在相同的文件名照片,则更新照片名称,最后删除原始照片。
根据本发明的公开,还提出一种人脸图像数据库的数据去重系统,包括:
用于输入用以训练人脸识别的数据人脸图像数据库的数据去重系统,其特征在于,包括:集的模块,所述数据集内包括多个照片,照片按照人进行存储,对应n个人的n个目录,每个目录中包含m张照片,n和m均为大于1的正整数;
用于遍历数据集的目录,对对应照片提取人脸特征的模块,所提取的特征保存到文本文件中;
用于进行目录内照片的比对处理获取疑似重复照片的模块,被设置成按照下述方式处理:从1-n的顺序遍历全部的目录,每次从一个目录中随机选择p张照片,将这p张照片分别和剩下的n-1个目录下的全部照片进行比对,得到比对的前y张,同预先配置的第一分数阈值进行比较,如果存在前y张至m张的分数超过预先配置的第一分数阈值,则设置其为疑似重复照片,将其拷贝到result结果目录中,并且按照当前照片所在的目录存储,p≤m,y≤m,;
步骤4、用于判断result结果目录下的照片数量是否超过设定阈值并进行处理的模块,其中,如果超过,则更新所述第一分数阈值,重复获取疑似重复照片;如果不超过设定阈值,则进行审核确认;
用于对result结果目录中的疑似重复照片进行审核确认的模块,被设置成用以检验挑选出的疑似重复照片是否真的是重复照片,并对误检的照片进行删除操作,正确的照片保留;
用于根据result结果目录中保留下来的照片,将原先的数据集重新整理的模块,被设置成按照如下方式进行:遍历result结果目录下的全部文件,对文件名进行解析,获取到相应的原始照片路径,目标照片路径,将原始照片路径拷贝到目标照片路径下,如果存在相同的文件名照片,则更新照片名称,最后删除原始照片。
进一步的,所述第一分数阈值的更新方式按照人脸识别模型的roc曲线提供的推荐分数,并结合当前数据集比对疑似重复照片的结果进行增减,当生成的疑似重复照片超过设定阈值时,增大第一分数阈值,生成的疑似重复照片数量为零或者远小于设定阈值时,减小第一分数阈值。
应当理解,前述构思以及在下面更加详细地描述的额外构思的所有组合只要在这样的构思不相互矛盾的情况下都可以被视为本公开的发明主题的一部分。另外,所要求保护的主题的所有组合都被视为本公开的发明主题的一部分。
结合附图从下面的描述中可以更加全面地理解本发明教导的前述和其他方面、实施例和特征。本发明的其他附加方面例如示例性实施方式的特征和/或有益效果将在下面的描述中显见,或通过根据本发明教导的具体实施方式的实践中得知。
附图说明
附图不意在按比例绘制。在附图中,在各个图中示出的每个相同或近似相同的组成部分可以用相同的标号表示。为了清晰起见,在每个图中,并非每个组成部分均被标记。现在,将通过例子并参考附图来描述本发明的各个方面的实施例,其中:
图1是本发明的一实施例的人脸图像数据库的去重方法的示意图。
具体实施方式
为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
在本公开中参照附图来描述本发明的各方面,附图中示出了许多说明的实施例。本公开的实施例不必定意在包括本发明的所有方面。应当理解,上面介绍的多种构思和实施例,以及下面更加详细地描述的那些构思和实施方式可以以很多方式中任意一种来实施,这是因为本发明所公开的构思和实施例并不限于任何实施方式。另外,本发明公开的一些方面可以单独使用,或者与本发明公开的其他方面的任何适当组合来使用。
根据本发明的公开,结合图1所示的人脸图像数据库的数据去重处理,旨在对人脸图像数据集中的重复数据进行清理,使得用来训练数据模型的人脸识别的数据集相对干净,提高模型训练的精度。本发明的实施例中,具体通过对人脸图像/照片的处理,对数据集中存在不同目录相同人的的情况进行去重,得到相对纯净的数据库。
结合图1所示,作为一个示例性实施例的去重方法,包括以下步骤:
步骤1、提供一用于训练人脸识别的数据集,所述数据集内包括多个照片,照片按照人进行存储,对应n个人的n个目录,每个目录中包含m张照片,n和m均为大于1的正整数;
步骤2、遍历数据集的目录,对对应照片提取人脸特征,并保存到文本文件中;
步骤3、从1-n的顺序遍历全部的目录,每次从一个目录中随机选择p张照片,将这p张照片分别和剩下的n-1个目录下的全部照片进行比对,得到比对的前y张,同预先配置的第一分数阈值进行比较,如果存在前y张至m张的分数超过预先配置的第一分数阈值,则设置其为疑似重复照片,将其拷贝到result结果目录中,并且按照当前照片所在的目录存储,p≤m,y≤m,;
步骤4、在步骤3执行完后,所有疑似重复照片都保存在result结果目录下,判断result结果目录下的照片数量是否超过设定阈值,如果超过,则更新所述第一分数阈值,重复执行步骤3;如果不超过设定阈值,则进入步骤5;
步骤5、对result结果目录中的疑似重复照片进行审核确认,检验挑选出的疑似重复照片是否真的是重复照片,并对误检的照片进行删除操作,正确的照片保留;
步骤6、根据result结果目录中保留下来的照片,将原先的数据集重新整理:遍历result结果目录下的全部文件,对文件名进行解析,获取到相应的原始照片路径,目标照片路径,将原始照片路径拷贝到目标照片路径下,如果存在相同的文件名照片,则更新照片名称,最后删除原始照片。
如此,通过不断的筛选、确认和整理,对确定的疑似重复照片进行去重处理,得到确定的且干净的数据集。
优选的,所述步骤2中,文本文件按照每行路径名+特征值数组保存。
步骤3中,文件的名称按照源文件名___疑似重复文件路径名__比对分数.jpg方式保存。在执行过程中,参数y表示比对前多少张,y≥3。
步骤4中,第一分数阈值的更新方式按照人脸识别模型的roc曲线提供的推荐分数,并结合当前数据集比对疑似重复照片的结果进行增减,当生成的疑似重复照片超过设定阈值时,增大第一分数阈值,生成的疑似重复照片数量为零或者远小于设定阈值时,减小第一分数阈值。
为了得到更加纯净的数据,我盟还可以进行多次去重处理,在前述补正基础上,进一步包括下述补正:
修改前述选取的照片参数p,重复q次上述步骤2-6,得到最终去重后的数据集。优选的,参数q,q≥3。
优选的,在前述步骤5,审核处理可以由人工来进行筛选确认,因为这样的疑似数据已经比较少了,通过人工审核能够再短时间、高效率和准确的实现问题照片确认。
在另一些例子中,还可以通过1:1比对的方式,采用更加准确的识别算法进行再一次的判断,以判断结果为依据对误检的照片进行操作。
下面结合具体的示例,来更加具体的描述上述过程的实施。
1、提供计划用于人脸识别模型训练的训练集,当前训练集的构成是:按照人来排列,每个人一个目录,一共n个目录。每个目录中有1-m个当前人的一张或多张照片(可能存在疑似的一个人放在不同的目录中)。
文件名没有影响,可以不同目录下有相同的文件名。
2、训练集准备完成后,开始配置参数,决定去重效果。具体的配置包括:
<imagepath>"./face_detection"</imagepath><!--数据集所在的文件夹-->
<featurepath>"./result/result_feature.txt"</featurepath><!--保存的特征文件列表路径-->
<score>89</score><!--去重配置的阈值分数-->
<topn>5</topn><!--比对前多少条-->以5为例进行说明
<threadmaxnum>1</threadmaxnum><!--最大同时检测线程数,最大16个-->
比对score分数(即第一分数阈值)的配置可以参照当前人脸识别模型的roc曲线提供的参考阈值分数来设置。在可选的实施例中,如果要清洗的是同一个人,所以配置的阈值分数会比这个推荐的分数高一些,比如:roc曲线推荐阈值85,可以设置成88-89。
topn的配置,即参数p的配置,是指选取前几张照片进行比对,优选基本配置3-5。一般的去重都是个别的文件有问题,如果很多的话,就要用合并数据集了,然后在进行去重操作。
threadmaxnum的配置和运行去重的机器配置有关系,如果机器配置很高,线程数可以配置多些,否则可以配置少些。一般配置是线程数为逻辑核数。
3、执行程序开始提取特征文件,保存到配置的featurepath路径下。文件特征值保存在result_feature.txt文件中,考虑到图片文件会有很多,所以保存的文件会有多个一次为result_feature.txt、result_feature_1.txt、result_feature_2.txt.......result_feature_n.txt。为了保证一个文件不要太大,以及保证读取时的速度。特征文件按照一行一个文件路径+一个人脸特征的方式存储,例如:./2018_select/0000001/1.jpg0.108315,-0.0217341,-0.0288338....等等。方便在调整阈值之后进行重试时可以不用重新提取特征。因为重新提取特征需要浪费非常长的时间。
4、数据准备好之后,开始执行清洗程序。首先遍历整个目录文件夹1-n。在选择某个一文件夹时,从其中随机的选择1-m个文件,作为比较文件。将这m个文件,分别和该目录之外的所以图片做1:n的特征值比对。当得到的topn的结果和配置文件中的<topn>比对,大于<topn>中的结果的,作为疑似重复照片,将疑似照片保存在result目录中。并且按照当前图片所在的目录存储。文件的名称按照“源文件名___疑似重复文件路径名___比对分数.jpg”方式保存。
5、查看result目录下的结果是否可以进行人工审核,例如生成的文件在几十或者几百个左右,那么这个结果就是可以接受的范围。如果生成的文件有几千,甚至几万的时候,我们认为这个结果是人工无法审核的。需要修改相应的阈值进行重新的执行步骤4,直到结果达到人工审核的情况为止。
步骤6、审核比对成功的两个文件是否为同一个人,同一个人即正确的结果,保存。否则为误检,删除该文件和比对文件。
7、对审核完的result目录下的结果进行合并和删除操作。遍历result目录下的全部文件,对文件名进行解析,可以获取到相应的原始图片路径,目标图片路径。将原始图片路径拷贝到目标图片路径下,如果存在相同的文件名图片,则更新图片名称(原名称_数字),最后删除原始图片。
步骤8、完成上述步骤之后,一次清洗就完成了。
由于p张照片是随机选出的,因此需要多做几次,保证其已经清洗干净。
使用清洗过的数据集再进行模型训练,对于精度会有大幅的提升。
虽然本发明已以较佳实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!