基于多启发信息蚁群系统的柔性作业车间调度方法与流程
本发明属于智能算法和生产管理领域,涉及基于多启发信息蚁群系统的柔性作业车间调度方法。
背景技术:
柔性作业车间调度问题(flexiblejob-shopschedulingproblem,fjsp)是传统作业车间调度问题(job-shopschedulingproblem,jsp)的扩展,每个工序可以由多个不同机器完成,并且在不同机器上的完成时间不同。具体来说,一个n×m的fjsp描述如下:有n个待加工的工件和m台可用机器,工件集合为{p1,p2,...,pn},机器集合为{m1,m2,...,mm},每个工件包含一道或多道工序,工件i(i=1,2,…,n)的ni道工序由集合opi={opi1,opi2,...,opini}表示。工件的工序加工顺序是确定的,每道工序可以在多台不同的机器上加工,问题的目标是在约束条件限制下,为m台机器中的每台机器找出一个操作序列使得n项作业的完成时间最小。fjsp减少了机器约束,扩大了可行解的搜索范围,增加了问题的复杂度,是非确定多项式(non-deterministicpolynomial,np)难问题。
现有解决fjsp的方法大致分为两类:分层方法与整合方法。分层方法是将fjsp分为机器分配与工序排序两个问题进行求解;整合是将两个问题综合起来进行求解。分层方法可以降低fjsp的复杂度,但是分层方法由于无法综合考虑全局信息,通常无法得到全局最优解。整合方法从理论上可以保证得到全局最优解。尽管如此,大多数现有的整合方法由于fjsp的高复杂度而面临着效率低下的问题。
目前,一些智能算法如遗传算法(geneticalgorithm,ga)、蚁群系统(antcolonysystem,acs)等方法由于其简单高效的特点被广泛应用于fjsp问题。相比于acs,ga不能充分利用大量的启发式信息,而在不同问题实例中,约束条件的侧重点有所不同,所以利用ga解决fjsp具有一定的局限性。acs方法可以在解的构造过程中充分利用多种启发式信息,具有更广泛的适用性,但acs方法存在收剑速度慢、易陷入局部最优的缺点。
技术实现要素:
针对上述现有技术的不足,本发明提出一种基于多启发信息蚁群系统的柔性作业车间调度方法,本发明在蚁群系统中引入六种启发式信息,使算法在不同问题实例中均能取得理想性能,避免陷入局部最优,并且使用一种能够根据待解问题实例和当前搜索状态来自动选择启发式信息及其引导力控制参数的自适应策略,使整个蚁群的启发式信息设计向能产生优质解的当前最优设计收敛,提高收剑速度,提高算法优化效率,提高柔性作业车间调度效率。
设n×m的fjsp问题为:有n个待加工的工件和m台可用机器,工件集合为{p1,p2,...,pn},机器集合为{m1,m2,...,mm},每个工件包含一道或多道工序,工件i(i=1,2,…,n)的ni道工序由集合opi={opi1,opi2,...,opini}表示。本发明的蚁群系统用一个含有m个序列的集合san来表示一个调度方案,即问题的一个解。其中,每个序列
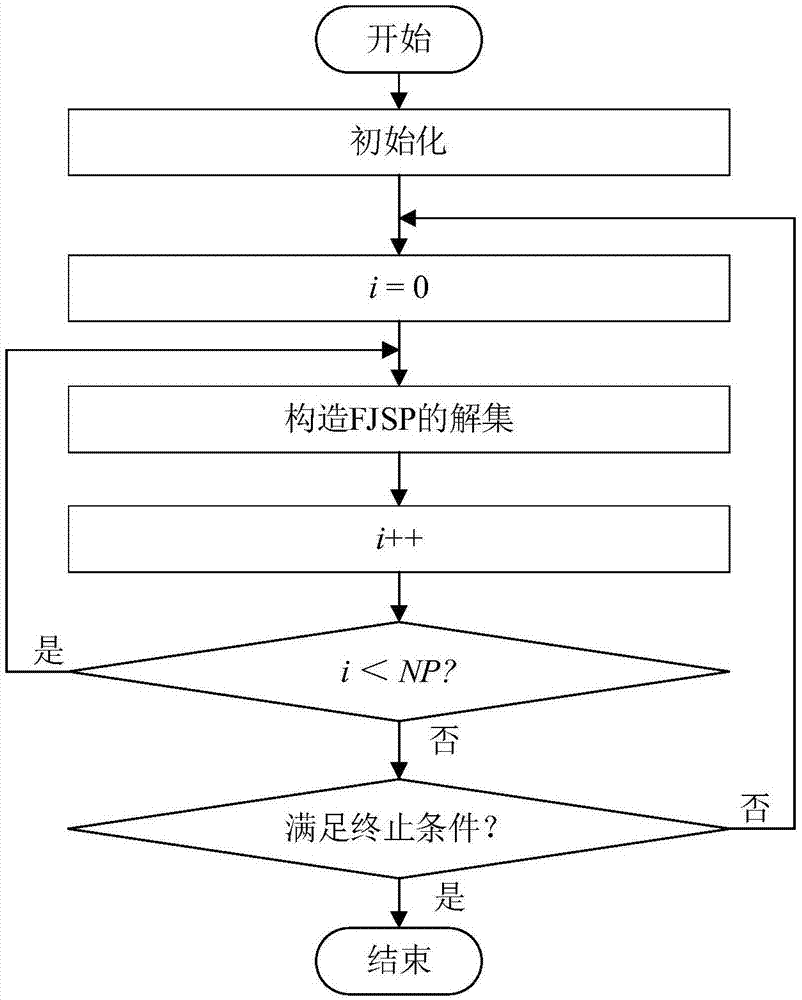
基于多启发信息蚁群系统的柔性作业车间调度方法的基本步骤为:
s1建立析取图模型:析取图也称解的构造图,用来描述解的搜索空间,是一个有向连通图。除了两个分别表示起点(vbegin)和终点(vend)的虚拟结点之外,每个结点表示一道工序到一台机器的可行分配。如果用t表示所有可行分配的数目,则t值为:
更具体地,除了vbegin和vend外,每个结点vs(1<=s<=t)包含了工件ps∈[1,n]、工序
s2初始化:初始化析取图中的信息素分布,即赋予每条有向边一个初始信息素值;并且为每只蚂蚁an初始化一个启发式信息档案ian;
启发式信息档案包括对启发式信息的选择方案yan和对两种引导力控制参数取值q0an和βan,即ian={yan,q0an,βan}。
s3构造fjsp的解集:每只蚂蚁都代表一个解集,一个合法的解集san由m个序列组成,第k(k=1,2,…,m)个序列记为
s4信息素更新:每只蚂蚁每选择一个结点,利用局部信息素更新规则更新相应有向边上的信息素浓度;当所有蚂蚁都完成解的构造后,根据全局信息素更新规则更新所有有向边上的信息素浓度。
s5启发式信息档案更新:每隔g次迭代进行一次启发式信息档案的更新。两次启发式信息档案更新间隔期间,每只蚂蚁构造的调度方案的工期将与该蚂蚁的启发式信息档案共同保存到一个外部档案f。自适应策略选择f中工期最短的λ%个元素的启发式信息档案进行统计,根据统计量对每只蚂蚁an的启发式信息档案进行更新。
s6终止条件检查:当算法对蚂蚁所构造的解集的评估次数达到预先设定的最大次数时,终止算法并输出结果。
进一步地,步骤s3中,一只蚂蚁的解集构造过程如下:
s31初始化:初始化每个
s32为l中的每个结点vs,在
s33利用伪随机过程从l中选择一个结点vs;
s34将s33中选择出来的结点vs紧接着vpre插入到序列
s35如果l为空集,则解集构造完毕;否则返回s32。
进一步地,步骤s4中,每只蚂蚁完成解构造过程后,将根据所构造的解执行局部信息素更新。在一个优选的实施例中,信息素被放置在关联于相同机器的结点之间的弧上。初始时,所有弧上的信息素被统一设置为τ0=(mk0)–1,其中mk0是通过最快操作优先的规则产生的解的完成时间。在解构造过程中,当一只蚂蚁将vs插入
τpre→s=(1-ε)τpre→s+ετ0
其中ε∈(0,1)是一个参数。当所有蚂蚁完成解构造过程后,执行下述全局信息素更新:
其中ρ∈(0,1)是一个参数,mkbest是目前为止最优解sbest的完成时间。
进一步地,步骤s4中,蚂蚁的解构造过程同时受启发式信息与信息素的影响,对于析取图中的每一个结点vs,定义六种类型的启发式信息。其中,前三种类型是静态启发式信息,vs的启发式信息值在搜索过程一开始时被计算并从此保持不变。另外三种类型的启发式信息,vs的启发式信息值必须根据蚂蚁当前构造的部分解来计算。
基于六种启发式信息,yan是一个六维的0/1向量,结点vs的启发式信息值计算如下:
为使算法在不同问题实例上都能取得理想性能,本发明引入一个自适应策略,该策略根据过往的搜索经验来调整蚂蚁的启发式信息档案ian,包括yan和启发式信息的引导力控制参数q0(蚂蚁an在q0上的取值记为
本发明具有以下有益效果:
1、针对柔性作业车间调度问题的特点,考虑到六种启发式信息,设计了一种可以适应不同问题实例的蚁群系统算法,避免陷入局部最优。
2、引入一种启发式信息的自适应设计策略,使得蚁群系统算法能够根据过往的搜索经验自适应地选择启发式信息并调整其引导力控制参数,从而提高算法的优化效率,为高效解决柔性作业车间调度问题提供了一条新的途径。
附图说明
图1为本发明柔性作业车间调度方法的流程图。
具体实施方式
下面通过具体实施方式对本发明作进一步详细的描述,但本发明的实施方式并不限于此。
现有一个n×m的fjsp问题:有n个待加工的工件和m台可用机器,工件集合为{p1,p2,...,pn},机器集合为{m1,m2,...,mm},每个工件包含一道或多道工序,工件i(i=1,2,…,n)的ni道工序由集合
步骤(1):用
步骤(2):为l中的每个结点vs,在
ps=τpre→s(ηs)β
其中:τpre→s表示在有向边(vpre,vs)上的信息素含量,ηs是vs启发式信息的值,β是控制启发式信息影响的参数。
步骤(3):运用伪随机比例规则从l中选择一个结点。具体来说,伪随机比例规则按如下方式实现:
其中:r∈[0,1]是一个标准化的随机数,q0∈(0,1)是算法的一个控制参数,l’是从l中随机选择的一个子集,l’的大小设置为
步骤(4):将步骤(3)中选出的vs插入
步骤(5):如果l非空,返回步骤(2)调度剩余的工序。否则,所有工序已经被调度,一个完整的解构造完毕。
每只蚂蚁完成解构造过程后,将根据所构造的解执行局部信息素更新。本实施例中,信息素被放置在关联于相同机器的结点之间的弧上。初始时,所有弧上的信息素被统一设置为τ0=(mk0)–1,其中mk0是通过最快操作优先的规则产生的解的完成时间。在解构造过程中,当一只蚂蚁将vs插入
τpre→s=(1-ε)τpre→s+ετ0
其中ε∈(0,1)是一个参数。当所有蚂蚁完成解构造过程后,执行下述全局信息素更新:
其中ρ∈(0,1)是一个参数,mkbest是目前为止最优解sbest的完成时间。
蚂蚁的解构造过程同时受启发式信息与信息素的影响,对于析取图中的每一个结点vs,本发明方法中定义六种类型的启发式信息。其中,前三种类型是静态启发式信息,vs的启发式信息值在搜索过程一开始时被计算并从此保持不变。另外三种类型的启发式信息,vs的启发式信息值必须根据蚂蚁当前构造的部分解来计算。关于上述六种启发式信息的具体定义如下:
※静态启发式信息
(1)基于工序完成时间的启发式信息:该启发式信息依据将一道工序分配给使用最少时间完成它的机器的思想定义。假设在机器mk上完成工序opij所花费的时间为
其中:
(2)基于工件剩余工序的启发式信息:该启发式信息依据优先选择具有较多剩余工序的工件的思想定义,结点vs基于工件剩余工序的启发信息值计算为:
其中,ns是每个任务剩余工序的数量。
(3)基于工件可用机器数目的启发式信息:该启发式信息依据优先选择可用机器较少的工序的思想定义,结点vs基于工件可用机器数目的启发信息值计算为:
其中,
※动态启发式信息
(4)基于开始时间的启发式信息:该启发式信息为了优先选择具有较早开始时间的工序而定义,给定一个结点vs,与之关联的工序ops的开始时间stats确定为:
其中:
(5)基于工序完成时间的启发式信息:该启发式信息为了优先选择具有较早完成时间的工序,结点vs基于工序完成时间的启发信息值计算为:
其中:exets等于stats与
(6)基于机器现有工作量的启发式信息:该启发式信息基于把工序分配给具有最小工作量的机器的思想,机器的工作量可以用它的可用时间来衡量,因此,结点vs基于机器现有工作量的启发信息值计算为:
其中:
注意到三种动态启发式信息对vs有意义仅当ops变成可执行的时候,ops是否可执行根据目前构造的部分解判断,即是否存在vs∈l。每只蚂蚁an根据自身启发式信息档案ian中的启发式信息定义yan来计算一个结点的启发式信息值。基于上述六种启发式信息,yan是一个六维的0/1向量,结点vs的启发式信息值计算如下:
为使算法在不同问题实例上都能取得理想性能,本发明引入一个自适应策略,该策略根据过往的搜索经验来调整蚂蚁的启发式信息档案ian,包括yan和启发式信息的引导力控制参数q0(蚂蚁an在q0上的取值记为
算法初始化时,随机产生每只蚂蚁的启发式信息档案。具体而言,yan的每个元素
算法每隔g次迭代进行一次启发式信息档案的调整,两次启发式信息档案的调整间隔期间,蚂蚁的启发式信息档案保持不变,并且每只蚂蚁构造的调度方案的工期将与该蚂蚁的启发式信息档案共同保存到一个外部档案f。假设蚁群的规模为m,g次迭代后档案中将保存有mg个元素。自适应策略选择f中工期最短的λ%个元素的启发式信息档案进行统计,并根据统计量对每只蚂蚁an的启发式信息档案进行如下调整:
βan=c(θβ,αβ)
其中,r是一个(0,1)间的标准化随机数,b表示f中工期最短的λ%个元素的子集,c(θ,α)表示柯西分布的密度函数,
从上述过程可以看出,本发明提出的自适应策略驱使蚂蚁从历史上产生较优解的启发式信息档案中学习,通过调整各个蚂蚁的启发式信息档案使整个蚁群的启发式信息设计向能产生优质解的当前最优设计收敛,从而促进算法优化效率的提高。
在fjsp标准测试库上的实验结果如表1所示,本发明公开的柔性作业车间调度方法能够高效地找到工期最短或接近最短的调度方案。
表1fjsp标准测试库实验结果
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!