一种提供隐私保护的数据采集和回归分析方法与流程
本发明涉及一种提供隐私保护的数据采集和回归分析方法,属于数据处理技术领域。
背景技术:
目前,拟合线性模型可能是最基础和最基本的学习任务,具有从统计学到医学以及社会学等多种方面的应用。在许多情况下,从中进行回归学习得到模型的数据不是由执行回归任务的分析师掌握的,而必须从个人中获取。这些场景显然包括医学试验和人口普查,以及挖掘在线行为数据,这是目前大规模发生的一种做法。
如果数据是由个人持有的,这对他们来说必然存在隐私泄露的问题。为激励他们更真实地提供自己的信息,训练得到更准确的回归模型,一方面我们要对他们的隐私提供一定的保护,另一方面要给他们提供适当的报酬。
差分隐私是释放敏感信息的同时保护个人隐私的最先进的模型。本发明采用差分隐私的方法,将拉普拉斯噪声加入到回归模型的训练中,保证回归模型准确性的同时进行了隐私保护。
技术实现要素:
目的:为了克服现有技术中存在的不足,本发明提供一种提供隐私保护的数据采集和回归分析方法。
技术方案:为解决上述技术问题,本发明采用的技术方案为:
一种提供隐私保护的数据采集和回归分析方法,包括如下步骤:
步骤1:假设有n个数据提供者,从数据提供者i处获取d维属性参数向量xi∈rd和个人可操纵的响应变量yi,rd是d维属性参数向量的集合,用x=[xi]i∈[n]∈rn×d表示属性参数矩阵,rn×d表示d维属性参数向量矩阵集合,用y=[yi]i∈[n]∈rn表示响应变量向量,rn表示响应变量向量集合;设训练出的回归模型为yi=θtxi,在损失函数l(θ;x,y)中加入拉普拉斯噪声,并由
作为优选方案,还包括步骤2,所述步骤2:计算除去数据提供者i提供的数据时的回归参数θ-i,与θ*比较,计算两者之间的误差,误差越大,报酬越小。
作为优选方案,所述步骤1具体步骤如下:
步骤1-1:假设数据提供者i∈[n],i={1,2,…n}持有固有属性特征向量xi∈rd,yi是个人可操纵的响应变量,用x=[xi]i∈[n]∈rn×d来表示属性矩阵,用y=[yi]i∈[n]∈rn表示响应变量向量,ti=(xi,yi)∈d表示数据提供者i提供的所有数据记录,其中d是n条记录的集合;训练出一个回归模型,使得预测函数为yi=θtxi;
步骤1-2:由加噪后的损失函数求出最优的θ*;
步骤1-2-1:回归模型中加入正则化项,用岭回归模型代替传统的线性回归模型,表示如下:
步骤1-2-2:将上述的损失函数展开成关于θ的多项式的形式,d是一个d维的向量,记作θ=(θ1,θ2,…θd)t,用
步骤1-2-3:在
步骤1-3:将求得的θ*带入到线性回归的一般公式yi=θtxi里得到yi=θ*txi,即在加入隐私保护的前提下训练出了这组数据的回归模型。
作为优选方案,所述步骤2包括如下步骤:
步骤2-1:步骤1得到由n个数据提供者提供的所有数据训练得到的回归模型,以及θ*;将所有数据除去第i个数据提供者提供的ti,计算出现在的回归模型,并求出回归参数值为θ-i;
步骤2-2:支付给每个数据提供者的报酬πi由θ*与θ-i之间的误差决定,即
有益效果:本发明提供的一种提供隐私保护的数据采集和回归分析方法,首先是回归模型的训练模块。为保护个人隐私,该方法采用差分隐私的方法,在模型中加入拉普拉斯噪声。为了避免差分隐私计算带来的偏差估计,该方法放弃使用传统的线性回归模型而使用岭回归模型,然后,在计算预测函数属性θ时,本方法将损失函数表示成多项式相加的形式,然后在每个多项式前面的系数上加上符合拉普拉斯分布的噪声,求出使损失函数值最小的θ*即得到最优的预测函数;第二部分是报酬分配模块,在这一模块先训练出除去数据提供者i提供的数据得到的回归模型,与整体的回归模型进行比较,根据两者的误差确定给每个数据提供者的报酬,误差越小,报酬就越多。其优点如下:
1、本发明在回归模型中加入拉普拉斯噪声,且将拉普拉斯噪声加在回归模型的参数的系数上,绕开对模型参数灵敏度的分析,减轻复杂度;另一方面加入正则化项,减轻了由于加入噪声产生的偏差估计。
2、本机制摒弃传统的报酬均分的模式,将每个人获得的报酬与他提供的数据的准确性相关联,激励数据提供者提供更为真实的数据。
附图说明
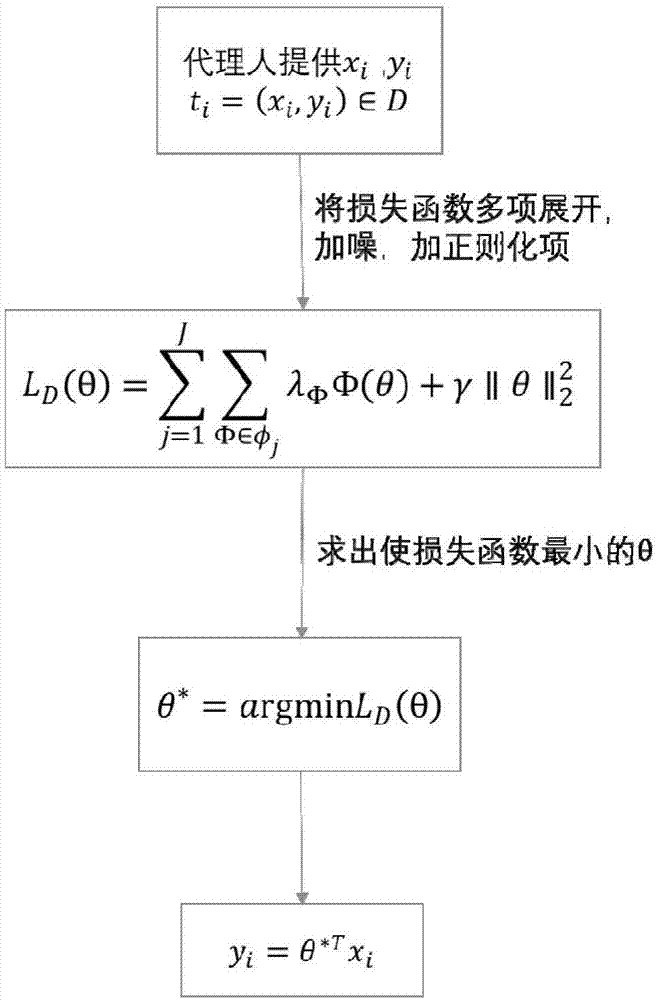
图1为本发明的回归模型流程图。
图2为本发明的实施场景框架图。
具体实施方式
下面结合附图对本发明作更进一步的说明。
如图1所示,将回归模型中的损失函数按多项式展开,将噪声加入到θ前的系数上,再在最后加上正则化项,最后求出使损失函数最小的θ值。
如图2所示,分析师从数据提供者那里获得原始数据,分析出回归模型,与除去每个数据提供者i提供数据时的回归模型作比较,根据两者的误差确定给每个数据提供者的报酬。
一种提供隐私保护的数据采集和回归分析方法,包括步骤如下:
步骤1:假设有n个数据提供者,分析师从数据提供者i处获取d维属性参数向量xi∈rd和个人可操纵的响应变量yi,rd是d维属性参数向量的集合,用x=[xi]i∈[n]∈rn×d表示属性参数矩阵,rn×d表示d维属性参数向量矩阵集合,用y=[yi]i∈[n]∈rn表示响应变量向量,rn表示响应变量向量集合。设训练出的回归模型为yi=θtxi,要求出回归模型系数θ且尽可能保护数据提供者隐私,本发明在损失函数l(θ;x,y)中加入拉普拉斯噪声,并由
步骤1-1:假设数据提供者i∈[n],i={1,2,…n}持有固有属性特征向量xi∈rd,yi是个人可操纵的响应变量,用x=[xi]i∈[n]∈rn×d来表示属性矩阵,用y=[yi]i∈[n]∈rn表示响应变量向量,ti=(xi,yi)∈d表示数据提供者i提供的所有数据记录,其中d是n条记录的集合。本发明训练出一个回归模型,能由输入的xi的值预测出输出yi。因此假设这个模型的输出响应yi与输入属性xi是线性相关的,因此存在一个θ∈rd,使得预测函数为yi=θtxi。下面要做的就是通过数据提供者提供的ti训练得到最优的θ*。
步骤1-2:由加噪后的损失函数求出最优的θ*。
步骤1-2-1:回归模型中,用损失函数(目标函数)来评估预测函数的准确性,为减轻之后加入的拉普拉斯噪声带来的偏差估计,本方法加入正则化项,用岭回归模型代替传统的线性回归模型,表示如下:
步骤1-2-2:将上述的损失函数展开成关于θ的多项式的形式。由上可知,θ是一个d维的向量,记作θ=(θ1,θ2,…θd)t,我们用
步骤1-2-3:在
步骤1-3:将以上求得的θ*带入到线性回归的一般公式yi=θtxi里得到yi=θ*txi,即在加入隐私保护的前提下训练出了这组数据的回归模型。
步骤2:计算除去数据提供者i提供的数据时的回归参数θ-i,与θ*比较,计算两者之间的误差,误差越大,报酬越小。
步骤2-1:步骤1得到由n个数据提供者提供的所有数据训练得到的回归模型,即θ*。依旧用以上的加噪回归模型,除去第i个数据提供者提供的ti,计算出现在的回归模型,即求出回归参数值为θ-i。
步骤2-2:支付给每个数据提供者的报酬πi由θ*与θ-i之间的误差决定,即
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!