一种基于同义词扩充的客服聊天机器人本体半自动构建的方法与流程
本发明属于知识工程领域,具体涉及种基于同义词扩充的客服聊天机器人本体半自动构建的方法。
背景技术:
客服聊天机器人在工作过程中需要处理的问题涉及大量的商品、服务信息,这些信息通常会是客服所负责的某一领域的知识。限定在商家涉及的商务领域内,并且其中的个体相似度较高,一般具有相同的属性,并且属性值通常在一个限定的范围,可以针对性的构建一个相应的本体库来系统的、形式化地描述这些领域知识。
目前为止本体工程仍处发展阶段,构建过程中还存在着很多问题。常用的构建方法根据构建过程中人工参与的程度分为手工构建本体,半自动构建本体和自动构建本体三类。其中使用手工方法构建本体,效率低、时间久,而且需要大量专业人员的参与。而全自动本体构建的方法还不成熟,无法构建合格的本体。而各个领域的半自动构建方法不尽相同,需要根据实际情况制定构建策略。
在实际的应用中,常常会遇到客户提出的领域内问题不能正确的匹配到本体库中知识的情况,这种情况常常由以下两个原因造成的,包括客户输入不规范和存在实例的未记录别名。
技术实现要素:
本发明的发明目的在于:针对上述存在的问题,提供一种基于同义词扩充的客服聊天机器人本体半自动构建的方法,针对客服聊天机器人领域知识的特点,通过使用词相关本体相似度进行同义词扩充的方法增加构建的本体对领域知识的覆盖范围。
本发明的基于同义词扩充的客服聊天机器人本体半自动构建的方法,包括下列步骤:
s1.数据选取和预处理:
s11.提取使用客服聊天机器人的商户网站的骨架结构:根据商户网站所开展的业务及其商品列表对商户的知识体系进行信息骨架提取,获取骨架结构;
s12.根据提取到的商户网站的骨架结构对商户网站中的商品和/或业务的具体信息进行提取保存,将其作为本体实例的构建素材;
s13.选择商户的优质人工客服历史对话记录,即从商户的人工客服历史对话记录中筛选满足预设条件的人工客服历史对话记录作为优质人工客服历史对话记录,例如通过商户记录的服务质量评分等因素从商户的记录中选取合适的人工服务对话记录,作为之后本体实例扩充的素材;
s14.优质人工客服历史对话记录的预处理;通过去除冗余对话、合并同一发言和发言顺序修正三步,将历史对话记录处理为合适的形式,之后对历史对话记录进行分词,并建立包含历史对话记录中所有词的词典w;然后再训练含有语义信息的词向量;
s2.本体概念类的构建;使用s11步骤获得的商户的知识体系,通过本体构建工具人工构建相应的本体概念类以及相应的概念关系;
s21.确定概念范围;根据商户网站以及步骤s13获得的优质人工客服历史对话记录中所涉及的知识确定本体所涉及的知识领域;
s22.提取本体层次结构;基于商户网站结构和商户网页的前端内容,设置本体概念类的结构层次;
s23.确定概念类和概念关系;基于商户网站、商户网页信息分布规则和组织形式,以及优质人工客服历史记录中对相应信息的问答,获取概念类和概念间关系;
s24.构建概念类;根据s21、s22和s23步骤的结果,将确定的本体概念加入本体库,例如将其定义为问答库(qa库);
s3.本体实例的爬取;通过s2步骤构建的本体概念,设置爬虫工具获取实例的标准表达:
s31.选择抓取页面;对商户网站概念类下网页的源码中标题类标签文本进行分析,并使用概念以及属性进行匹配,若标签文本中包含属性的某一种表达方法,则将该链接保留,并记录属性、概念类和该种属性表达方法;
s32.爬取页面内容;根据获取到的链接所在网站的组织形式针对性地设置爬虫工具,通过所述爬虫工具取出对应区块的内容,根据定义的概念和概念间的关系,将抽取的内容组合成“实例-实例属性-属性值”的三元组;
s33.构建实例;使用步骤s32获得的三元组,将实例及其属性添加入本体库中;
s4.本体实例的扩充;通过优质人工客服历史对话记录,将客服聊天机器人工作过程中客户可能使用的实例非标准表达加入本体库,从而完善本体库对领域知识的覆盖,对单个实例c的多轮扩充步骤如下:
s41.选出可能的实例同义表达:
查询本体库,将实例c已有的同义词构成同义词集c,计算词典w中每个词w与同义词集c的语义相似度scw;
将语义相似度scw进行排序,根据实际情况选择相似度最高的1到n个词作为可能同义表达集x;
s42.判断实例同义表达,使用词相关本体相似度对x中的每一个词x进行是否增加到同义词集c的判断处理:
查询本体库,获取实例c的同义词构成同义词集c,计算词典w中每个词w与同义词集c的语义相似度scw;
对将语义相似度scw进行排序,选择前n个相似度最高词作为可能同义表达集x,其中n≥1;
s42.使用词相关本体相似度对表达集x中的每一个词x进行是否增加到同义词集c的判断处理:
从本体库中提取词x和词集c的相关本体图gx和gc;
并使用图同构算法对相关本体图gx和gc进行判断,若完全一致(图同构),或者其中一图被另一图所包含(子图同构),则将两者的词相关本体相似度sgx设为1;否则基于编码分解方式计算图gx和gc的相似度sgx;
判断相似度sgx是否大于预设相似度阈值,若是,则x加入同义词集c;否则执行步骤s43,所述相似度阈值小于1;
其中,基于编码分解方式计算图gx和gc的相似度sgx具体为:
s42-1:获取相关本体图gx和gc的更新后的编码序列
对相关本体图的节点进行编码,得到每个节点的标签编码;
对相关本体图进行分解处理,分解得到多个子树结构s1,s2,...,sk,用k表示子树结构数量;
对每个子树结构,对每个子树结构的根节点及其邻接节点的标签编码进行hash运算,生成每个子树结构的根节点的新标签编码
基于所有子树结构的根节点的新标签编码得到相关本体图的更新后的编码序列;
s42-2:根据公式
s43.迭代判断:若经过步骤s42后同义词集c有新词加入且未超过迭代最大轮数,返回步骤s41,若没有新词加入或者超过迭代最大轮数,扩充结束,进行步骤s44;
s44.在当前本体中添加实例的同义表达:完成扩充后,再将获得的实例同义表达加入本体库。
综上所述,由于采用了上述技术方案,本发明的有益效果是:本发明针对客服聊天机器人领域知识的特点,使用了结合词相关本体相似度的同义词扩充算法构建了一套半自动本体构建方法,能够有限减轻客服聊天机器人领域本体构建的成本和时间。
附图说明
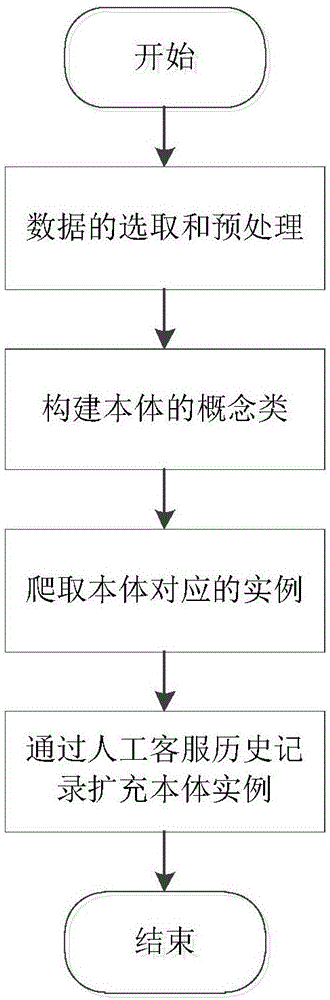
图1为客服领域本体构建流程示意图;
图2为人工客服历史记录预处理示例图;
图3为实例爬取流程示意图;
图4为词相关本体图子树分解及编码示例图;
图5为实例扩充算法流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面结合实施方式和附图,对本发明作进一步地详细描述。
本发明针对客服聊天机器人领域知识的特点,通过使用词相关本体相似度进行同义词扩充的方法增加构建的本体对领域知识的覆盖范围,参见图1,其具体实现步骤如下:
s1.数据选取和预处理。
本步骤输入:所需要的商户信息,如商户网站内容、商户商品信息以及商户的人工客服在工作过程中产生的历史对话记录等等。
本步骤输出:商户知识体系、信息骨架,商户商品、服务信息以及进行处理后的人工客服历史对话记录。
s11.提取使用客服聊天机器人的商户网站的骨架结构;根据商户网站所开展的业务及其商品列表等对商户的知识体系进行提取。这个结构包括网站的组织结构和相关网页的组织结构,网站的结构通常是网站包含的主要内容在网站导航中的显示结构,当前导航为知识结构的一层,导航指向的目标页面为对应的下一层知识。将商户网掌中的所有相关结构抽取后,即可组成相应的信息骨架,即得到商户网站的骨架结构(也称商户知识体系)。
s12.根据提取到的商户网站的骨架结构将商户网站的中商品或者业务的具体信息进行提取保存,将其作为本体实例的构建素材。实例的构建素材包括商品、服务等的具体信息,如产地、功效、使用方式等等信息。
s13.选择商户的优质人工客服历史对话记录;通过商户记录的服务质量评分等因素从商户的记录中选取合适的对话记录,作为之后本体实例扩充的素材,一般选择与商家知识相关度高、客服回复简洁准确、客户问题较为清晰明确的记录。
s14.优质人工客服历史记录的预处理;通过去除冗余对话、合并同一发言和发言顺序修正三步将历史对话记录处理为合适的形式。冗余信息一般包括四类,第一类是客服端自动发送的广告;二类是客户和人工客服礼貌性的发言如“谢谢你”、“你好”等;第三类是对无关问题的询问如“???人呢”等;第四类是记录里没有回答的问题。在网络聊天情景下,有时候会出现一句完整的话分为多次发送的情况这时需要合并发言,而在网络延迟或其他原因造成人工客服回复不及时的情况下,会出现客户连续提出问题后客服才一一回答的情况,这时需要调整发言顺序,图2展示了合并同义发言以及对问答顺序调整的例子。之后使用hanlp、斯坦福分词器、ansj、中科院分词器nlpir等分词工具对对话记录进行分词,并建立包含记录中所有词的词典w。之后使用word2vec(产生词向量的相关模、工具)训练含有语义信息的词向量。
s2.本体概念类的构建;使用s11步骤获得的商户知识体系,通过本体构建工具人工构建相应的本体概念类以及相应的概念关系。
本步骤输入:商户知识体系、信息骨架。
本步骤输出:使用protégé(本体构建工具)构建的owl(网络本体语言)本体概念类,owl是一种编程语言,全称为webontologylanguage,用于对本体进行语义描述。
s21.确定概念范围;根据商户网站以及步骤s13获得的商家客服历史记录中所涉及的知识确定本体所涉及的知识领域。
s22.提取本体层次结构;通过分析商户网站结构和其网页的前端内容,结合其领域知识的特点,获得本体概念类的结构层次。例如房产信网站中包括房产的所在地,分为大洲、国家、城市,这些信息可以很直观的确定层次关系,而对于房产的具体信息,则可以表示房产项目、房产信息的层次结构。
s23.确定概念类和概念关系;通过分析商户网站设计、网页信息分布规则和组织形式,以及人工客服历史记录中对相应信息的问答,从中得到概念类和概念间关系,关系有两种,一种为对象类型关系,其连接的是两个概念类;另一种是数据类型关系,其连接的两者一是概念类,另一个是概念类对应实例的具体数值描述。
s24.构建概念类;根据s21、s22和s23步骤的结果,使用protégé工具将确定的本体概念加入本体库。
s3.本体实例的爬取;通过s2步骤构建的本体概念,设计爬虫等工具获得实例的标准表达。
本步骤输入:商户商品、服务信息,本体概念类。
本步骤输出:加入实例的owl本体。
s31.选择抓取页面;对商户网站概念类下网页的源码中标题类标签文本进行分析,并使用概念以及属性进行匹配,若标签文本中包含属性的某一种表达方法,则将该链接保留,并记录属性、概念类和该种属性表达方法。
s32.爬取页面内容;根据获取到的链接所在网站的组织形式针对性地设计爬虫,取出对应区块的内容,根据定义的概念和概念间的关系,将抽取的内容组合成“实例-实例属性-属性值”的rdf三元组。
s33.构建实例;使用步骤s32获得的三元组,使用相应工具将实例及其属性添加入本体库中。
s4.本体实例的扩充;通过人工客服历史记录,将客服聊天机器人工作过程中客户可能使用的实例非标准表达加入本体库,完善本体库对领域知识的覆盖。
本步骤输入:处理后的人工客服历史对话记录,构建的owl本体。
本步骤输出:扩充实例后的owl本体。
设定最对迭代3轮,对单个实例c的扩充步骤如下:
s41.选出可能的实例同义表达。查询本体,将实例c已有的同义词构成同义词集c,使用下式计算词典w中每个词w与同义词集c的语义相似度scw为:
s42.判断实例同义表达。设步骤s41获得的可能同义表达集为x,使用词相关本体相似度对x中的每一个x进行判断。将xi的相关本体概念从问答库中提取出来,构建词相关本体图gx={s,v},其中s为概念类和实例的集合,v为概念关系的集合。同理,从本体库中获取实例的相关本体图g。
然后使用vf等图同构算法对两者进行图同构判断,若完全一致(图同构),或者其中一图被另一图所包含(子图同构)时将其词相关本体相似度sgx设为1。
若两图不同构,将图进行编码(对每个节点编码),再基于图的节点对其进行分解处理,分解出的子树结构为f(g)={s1,s2,...,sn},原始结点的编码为l={l1,l2,...,ln},图4为包含“x1产地类型”的一个图分解子树的编码示例。其中,分解方式可采用任一惯用方式,本发明不做具体限定。之后使用hash运算利用根节点与其邻接节点的标签编码生成新的编码,并将该根节点的标签编码替换,全部更新后获得新的节点编码序列,并且可以根据实际情况迭代多次来整合更多的信息。编码计算公式为:
将两图分解为两个更新后的编码序列lnew和
之后设定阈值判断图是否相似,若sgx超过阈值,则将x加入同义词集c。
s43.迭代判断。若经过步骤s42后同义词集c有新词加入且未超过迭代最大轮数,返回步骤s41,若没有新词加入或者超过迭代最大轮数,扩充结束。
s44.在本体中添加实例的同义表达:扩充完毕后,使用protégé工具将获得的实例同义表达加入本体库。
s4步骤的流程如图5所示,其具体步骤如下:
步骤1:查询本体,将实例c已有的同义词构成同义词集c;
步骤2:计算词典中词与同义词集c的语义相似度scw,根据scw排序,选择其中相似度较高前三个词设为x;
步骤3:取出x中的词xi,从问答库中获取c和xi的相关本体图gc和gxi
步骤4:使用vf2(子图同构)算法判断gc和gxi是否同构,若同构则将相似度sgxi设为1,并跳至步骤:7;
步骤5:若gc和gxi不同构,计算gc和gxi的两图相似性,得到相似度sgxi;
步骤6:判断相似度sgxi是否超过阈值,若是,则执行步骤7;否则执行步骤8;
步骤7:将xi加入同义词集c;
步骤8:若同义词集c有新词加入且未超过迭代最大轮数,返回步骤2,若没有新词加入或者超过迭代最大轮数,扩充结束
以上所述,仅为本发明的具体实施方式,本说明书中所公开的任一特征,除非特别叙述,均可被其他等效或具有类似目的的替代特征加以替换;所公开的所有特征、或所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以任何方式组合。
- 还没有人留言评论。精彩留言会获得点赞!