基于集合型离散粒子群优化的云工作流调度方法与流程
本发明涉及云计算以及智能计算技术领域,具体涉及一种基于集合型离散粒子群优化的云工作流调度方法。
背景技术:
云计算作为一种新兴的资源使用和交付模式,可以让用户随时随地根据自己的需求来使用各种资源,已经逐渐为学界和产业界所认知。它提供了一个弹性的方法来实现一种基于交付模式计算密集型的工作流应用。在云系统中,由于用户越来越关注服务质量(qos)的满意程度,满足用户自定义需求的云工作流动态调度问题已经逐渐变成一个亟待解决而且具有挑战性的难题。
粒子群算法(pso)是一种模拟自然界中鸟群和鱼群捕食的随机搜索算法。虽然pso是一个非常适合于连续领域问题优化的算法,并且已经在很多连续空间领域获得了相当成功的应用,但是还是有很多现实的问题都是定义在离散空间中的,例如典型的离散组合问题就有背包问题,旅行商问题,调度问题等。为了将pso在离散优化空间中拓展,此前已经提出了集合型的粒子群优化算法(s-pso),成功地突破了粒子群优化在离散优化空间的应用瓶颈,在解决如旅行商和多重背包等经典组合优化问题中取得了很好的求解性能。以此为基础,如果能实现基于s-pso的云工作流调度方法,将可以为进一步提高云工作流调度的效率提供新的有效途径。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于集合型离散粒子群优化的云工作流调度方法,提高云工作流调度的性能和效率。
本发明的目的可以通过采取如下技术方案达到:
一种基于集合型离散粒子群优化的云工作流调度方法,所述的调度方法包括下列步骤:
s1、将待优化的云工作流调度问题建立数学模型,过程如下:
s11、将云工作流调度问题所含有的元素的全集记为e,集合e被分为一个n元组(e1,e2,…,en),其中e=e1∪e2∪…∪en;
s12、将云工作流调度问题的一组候选解x∈ps分为一个n元组(x1,x2,…,xn),其中xj,j=1,2,…,n是一个集合并且
s13、当且仅当x满足约束条件ω,将x作为可行解;
s14、将云工作流调度问题的优化目标当成要找到一个合适的解x*使得问题的目标函数f得到最优化;
s2、对建立的数学模型基于集合型离散粒子群优化实现云工作流调度,过程如下:
s21、初始化算法的各个参数,并建立第一代粒子群和初始速度,其中,粒子的编码方式为:
x=(x1,x2,…,xn)
其中xi∈si,si表示能用于执行第i个任务ti的所有云计算服务的集合,由于每个任务只能匹配到一个云计算服务中执行,因此xi仅仅只含一个元素ki,表示任务ti被安排云计算服务
速度的编码方式为:
v=(v1,v2,…,vn)
其中,每一维度是一个带有可能性的集合vj={e/p(e)|e∈sj},表示集合sj中的每一个元素e都关联着一个可能性p(e);
s22、根据粒子当前的位置评估每个粒子的适应度值;
s23、更新每个粒子的个体最优位置;
s24、更新粒子的速度,速度更新公式如下:
其中,下标i表示第i个粒子,上标j表示维度,ω是惯性权重,c是参数,rj是位于[0,1]区间的随机数,
s25、更新粒子的位置;
s26、如果迭代次数超过规定的最大进化代数或此时得到的最优解达到规定的误差要求则停止,否则返回步骤s22继续执行。
进一步地,所述的速度更新公式中相关操作定义如下:
(i)参数×速度:
其中,c是参数,v表示粒子速度,e是该调度问题中所含有的元素,e是元素全集,p(e)表示与e相关联的可能性,pl(e)表示更新后的可能性;
(ii)位置-位置:
其中,a和b表示两个粒子位置,e是该调度问题中所含有的元素;
(iii)参数×(位置-位置):
其中,c是参数,el表示两个粒子位置之差,e是该调度问题中所含有的元素,e是元素全集,pl(e)表示更新后的可能性;
(iv)速度+速度:
v1+v2={e/max(p1(e),p2(e))|e∈e}。
其中,v1和v2表示两个粒子速度,e是该调度问题中所含有的元素,e是元素全集,p1(e)和p2(e)分别表示两个粒子与元素e相关联的可能性。
进一步地,所述的步骤s25、更新粒子的位置包括:
s251、将速度矢量vi的每一个维度vij都用来生成另一个确定的集合cutα(vij)={e|e/p(e)∈vijandp(e)≥α};
s252、第i个粒子开始建立新的位置,由一个空集开始,粒子从cutα(vij)中采用基于启发信息的选择方式选择一个可行元素加到新的位置;
s253、如果cutα(vij)中无可行解,并且新位置的构造未结束,则从当前的位置
s254、如果
进一步地,所述的基于启发信息的选择方式具体如下:
每次进行选择之前都从{时间优先启发式,费用优先启发式,可靠性优先启发式,性价比启发式,随机启发式}这五类启发信息中随机选择一种启发信息,并按照这种启发信息选出候选元素中具有最优启发信息值的元素添加到新的位置,其中,所述的时间优先启发式是指执行时间越短的计算服务越优先被选择,所述的费用优先启发式是指费用越低的计算服务越被优先选择,所述的可靠性优先启发式是指可靠性越高的计算服务越被优先选择,所述的性价比启发式是指时间与费用的乘积值越小的计算服务越被优先选择,所述的随机启发式是指每个候选的元素都被赋以均匀分布于(0,1)区间的随机数,随机数值越大的元素越被优先选择。
进一步地,所述的数学模型中根据云工作流调度优化需要考虑各种不同的约束条件,定义如下三种不同的适应度函数,分别为:
(1)对于给定完成期限deadline、费用预算budget、优化可靠性的问题,其适应度函数为:
其中,k.makespan表示调度k的工期,k.cost表示调度k的总体花费,min_reliability和max_reliability表示所有可用的云计算服务中可靠性最小和最大的服务的可靠性,k.reliability表示调度k的可靠性;
(2)对于给定费用预算budget约束、最小化完成时间的问题,其适应度函数为:
其中,k.makespan表示调度k的工期,k.cost表示调度k的总体花费,min_makespan和max_makespan分别表示把所有任务都分配到完成时间最短或最长的云计算服务时工作流执行所需的完成时间;
(3)对于给定完成期限deadline约束、最小化费用的问题,其适应度函数为:
其中,k.cost表示调度k的总体花费,k.makespan表示调度k的工期,min_cost和max_cost分别表示把所有任务都分配到费用最小或最大的云计算服务时工作流执行所需的费用。
进一步地,所述的步骤s21中,在初始化xi时,采用完全随机的方式生成。
进一步地,所述的步骤s21中,在初始化速度时,首先随机从sj里面选择一个元素,并且分配一个随机的可能性p(e)∈(0,1]给这个元素,其它所有未选的元素的可能性都设置为0。
本发明相对于现有技术具有如下的优点及效果:
本发明所采用的基于集合型离散粒子群优化算法解决了传统粒子群算法不能直接用于求解离散优化问题缺陷,将粒子的速度、位置和相关的更新操作在离散的集合空间下进行重定义。通过将其应用于实际的云工作流调度问题中,能够提高调度效率,优化服务质量。
附图说明
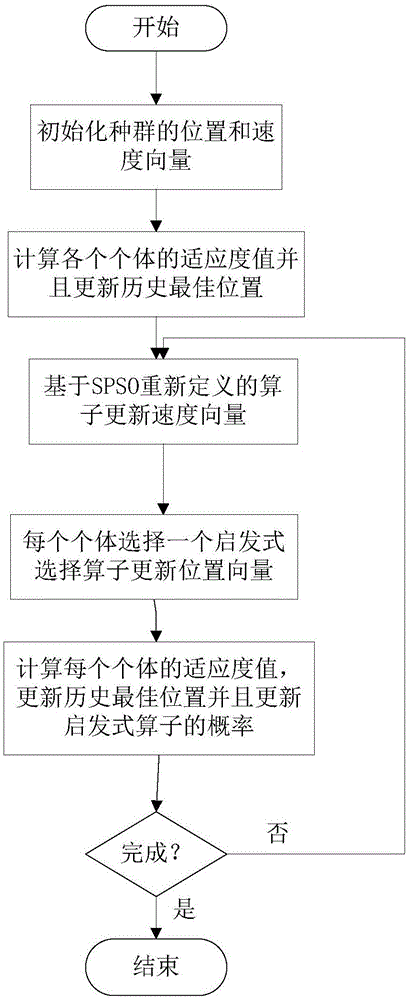
图1是本发明中基于集合型离散粒子群优化的云工作流调度方法的流程图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
云工作流可以以有向无环图(dag)g=(v,a)的形式来描述。在该模型中,令n为工作流中任务的数量,节点的集合v={t1,t2,…,tn}对应工作流中的任务。箭线的集合a表示任务之间的优先次序关系。工作流中的每个任务在云系统里面都能被一些云计算服务实现,即每个任务ti(1≤i≤n)都具有一个可执行该任务的云计算服务集合
为了给用户提供一种在云系统里面弹性管理工作流的qos,本发明所考虑的云工作流调度模型允许用户自己定义各种各样的qos约束。根据上面所提到的三个qos参数,用户可以定义三种类型的约束:
(1)执行时间约束(完成期限deadline):工作流的执行时间必须小于或者等于用户自定义的执行时间;
(2)费用预算约束(费用预算budget):工作流产生的所有服务实例的总价格必须小于或者等于用户自定义的预算价格;
(3)可靠性约束:工作流中每个服务实例的储存的历史可靠性必须要大于用户自定义的最低可靠性。
另外,云工作流调度模型还允许用户指定一个qos参数作为优化主体。换句话说,用户可以从下面的三种qos优化方式中选择一种方式进行优化:执行时间最小化、费用预算最小化、可靠性最大化。
pso是一种模拟自然界中鸟群和鱼群捕食的随机搜索算法。算法要求每个个体(粒子)在进化过程中维持两个向量,即速度向量和位置向量。粒子的速度决定了其运动方向和速率,而位置则体现了粒子所代表的解在解空间中的位置。每个粒子各自维持着一个自身的历史最优位置向量,而整个群体则维护着一个全局最优位置向量。在每一代中,每个粒子通过速度更新和位置更新,生成新的解,从而不断使待解问题得到优化。
由于原始的粒子群算法的速度和位置的更新公式都是定义在n维的实向量空间,所以它们不能被直接应用到离散空间的优化问题里面。在此,本发明使用s-pso方法。这个方法将待优化的问题按照如下方式建立数学模型:
(1)问题所含有的元素的全集记为e。集合e可以被分为一个n元组(e1,e2,…,en),其中e=e1∪e2∪…∪en,可以把e1,e2,…,en看成问题的n维。
(2)问题的一组候选解x∈ps也可以被分为一个n元组(x1,x2,…,xn),其中xj(j=1,2,…,n)是一个集合并且
(3)x是可行解当且仅当x满足约束条件ω。
(4)问题的优化目标就是要找到一个合适的解x*使得问题的目标函数f得到最优化。
基于这一定义,基于集合型离散粒子群优化的云工作流调度方法的具体执行步骤如下:
(1)初始化算法的各个参数,并建立第一代粒子群和初始速度。粒子的编码方式为:
x=(x1,x2,…,xn)
其中xi∈si,si表示能用于执行第i个任务ti的所有云计算服务的集合。事实上,由于每个任务只能匹配到一个云计算服务中执行,因此xi仅仅只含一个元素ki,表示任务ti被安排云计算服务
速度的编码方式为:
v=(v1,v2,…,vn)
其中,每一维度是一个带有可能性的集合vj={e/p(e)|e∈sj},表示集合sj中的每一个元素e都关联着一个可能性p(e)。在初始化速度时,首先随机从sj里面选择一个元素,并且分配一个随机的可能性p(e)∈(0,1]给这个元素,其它所有未选的元素的可能性都设置为0。
(2)根据粒子当前的位置评估每个粒子的适应度值。由于云工作流调度优化需要考虑各种不同的约束条件,模型定义了三种不同的评价函数,分别为:
对于给定完成期限deadline和费用预算budget,优化可靠性的问题,其评价函数(即适应度函数)为:
其中,k.makespan表示调度k的工期,k.cost表示调度k的总体花费,min_reliability和max_reliability表示所有可用的云计算服务中可靠性最小和最大的服务的可靠性,k.reliability表示调度k的可靠性。
对于给定费用预算budget约束,最小化完成时间的问题,其评价函数(即适应度函数)为:
其中,k.makespan表示调度k的工期,k.cost表示调度k的总体花费,min_makespan和max_makespan分别表示把所有任务都分配到完成时间最短或最长的云计算服务时工作流执行所需的完成时间。
对于给定完成时间deadline约束,最小化费用的问题,其评价函数(即适应度函数)为:
其中,k.cost表示调度k的总体花费,k.makespan表示调度k的工期,min_cost和max_cost分别表示把所有任务都分配到费用最小或最大的云计算服务时工作流执行所需的费用。
(3)更新每个粒子的个体最优位置。
(4)更新粒子的速度,公式为:
其中,下标i表示第i个粒子,上标j表示维度,ω是惯性权重,c是参数,rj是位于[0,1]区间的随机数,
在这个更新公式中,由于速度和位置的定义已经不再在连续的实数空间中定义,而是在离散的集合空间中定义,因此更新公式的相关操作也需要重新定义:
(i)参数×速度:
其中,c是参数,v表示粒子速度,e是该调度问题中所含有的元素,e是元素全集,p(e)表示与e相关联的可能性,pl(e)表示更新后的可能性。
(ii)位置-位置:
其中,a和b表示两个粒子位置,e是该调度问题中所含有的元素。
(iii)参数×(位置-位置):
其中,c是参数,el表示两个粒子位置之差,e是该调度问题中所含有的元素,e是元素全集,pl(e)表示更新后的可能性。
(iv)速度+速度:
v1+v2={e/max(p1(e),p2(e))|e∈e}。
其中,v1和v2表示两个粒子速度,e是该调度问题中所含有的元素,e是元素全集,p1(e)和p2(e)分别表示两个粒子与元素e相关联的可能性。
(5)更新粒子的位置。在重新定义的离散空间里不能简单由速度加位置来更新粒子的位置,故采用如下4步来更新粒子的位置:
(i)速度矢量vi的每一个维度vij都用来生成另一个确定的集合cutα(vij)={e|e/p(e)∈vijandp(e)≥α}。
(ii)第i个粒子开始建立新的位置,由一个空集开始,粒子从cutα(vij)里面选择一个可行元素加到新的位置里面。
(iii)如果cutα(vij)里面没有可行解,并且新位置的构造还没有结束,则从当前的位置
(iv)如果
更新种群位置操作时的第(ii)(iii)(iv)步都有一个选择操作。这里将采用基于启发信息的选择方式,即每次进行选择之前都从{时间优先启发式,费用优先启发式,可靠性优先启发式,性价比启发式,随机启发式}这五类启发信息中随机选择一种启发信息,并按照这种启发信息选出候选元素中具有最优启发信息值的元素添加到新的位置里面。时间优先启发式是指执行时间越短的计算服务越优先被选择;费用优先启发式是指费用越低的计算服务越被优先选择;可靠性优先启发式是指可靠性越高的计算服务越被优先选择;性价比启发式是指时间与费用的乘积值越小的计算服务越被优先选择;随机启发式是指每个候选的元素都被赋以均匀分布于(0,1)区间的随机数,随机数值越大的元素越被优先选择。如果两个或多个元素具有等优的启发式信息值,则算法随机地从中选择一个添加到新的位置里面。
(6)如果达到迭代次数超过规定的最大进化代数或此时得到的最优解满足一定的误差要求(如误差小于5%)则停止,否则返回步骤(2)继续执行。
综上所述,本发明公开的基于集合型离散粒子群优化的云工作流调度方法,针对带有不同服务质量qos需求的云工作流调度问题,采用了一类新型的集合型粒子群优化算法,通过将粒子群优化的速度、位置和相关的更新操作在离散的集合空间重定义,从而能够满足对离散空间的云工作流调度优化问题的应用需求,提高了云工作流调度的效率。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!