基于重采样池的快速集成污水处理故障诊断方法与流程
本发明涉及污水处理故障诊断的
技术领域:
,尤其是指一种基于重采样池的快速集成污水处理故障诊断方法。
背景技术:
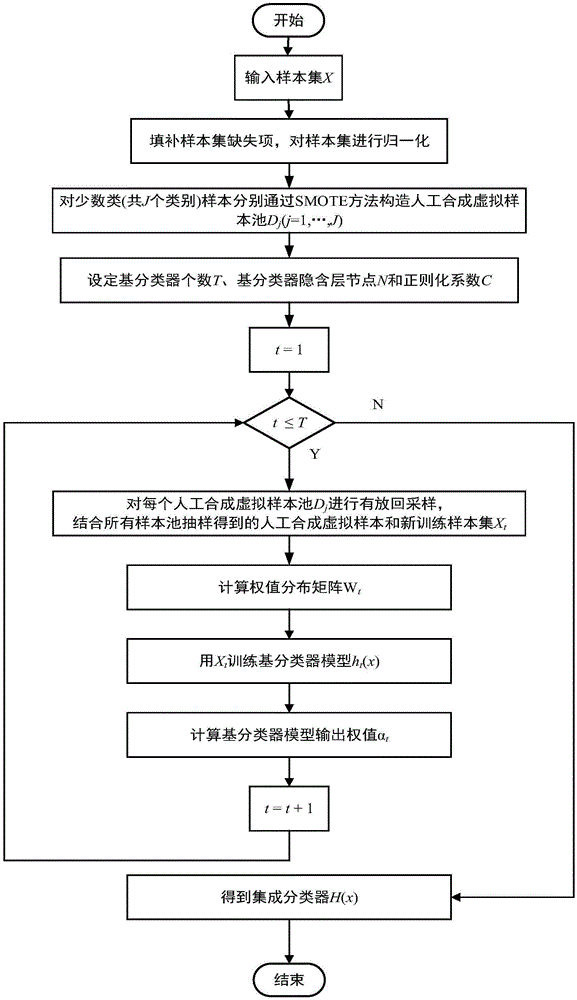
:污水处理是一个复杂的,多变量的生化过程。污水处理厂发生故障容易引发一系列严重的污水污染问题。而污水处理过程的故障诊断可转化为一个模式识别的分类问题。污水数据由定期将污水厂采集到的数据及其当前工作状态组成,一段时间内的污水数据组成污水数据集。由于合格的污水处理厂发生故障的频率很低,采集到的污水数据集中故障状态下的数据往往远少于正常状态下的数据。这就导致污水数据集是分布高度不平衡集,即污水处理过程的故障诊断是一个数据不平衡的分类问题。传统学习算法往往基于总体准确率对参数进行优化,这容易使分类结果更偏向多数类。但在现实应用场合更被看重的是少数类的分类准确率,即在污水处理故障诊断场合,更重要的是准确分类出作为少数类的故障类。准确分类出作为少数类的故障类对及时诊断污水处理厂的运行故障并及时进行处理有巨大的帮助。及时诊断并处理污水故障可稳定出水水质并减少污水对环境的污染,并减少维护费用。因此,应注重研究及时精确少数类的故障类的故障诊断算法。技术实现要素:本发明的目的在于克服现有技术的缺点与不足,提出了一种基于重采样池的快速集成污水处理故障诊断方法,引入人工合成虚拟样本池,在有效地降低了污水数据的不平衡性的同时提高了基分类器间的多样性,通过集成分类提高了对污水处理故障类的分类准确率,进而有效提高了污水处理过程中故障诊断的整体性能。为实现上述目的,本发明所提供的技术方案为:基于重采样池的快速集成污水处理故障诊断方法,包括以下步骤:1)对污水数据进行预处理,对初始训练数据中的少数类样本进行smote过采样处理,对各类少数类样本构造对应的人工合成虚拟样本池dj,j=1,...,j,其中j为少数类的类别个数;2)设定集成分类器的基分类器的个数为t,分别训练t个基分类器,为了增加基分类器的多样性,每次训练基分类器时对步骤1)构造的样本池dj,j=1,...,j分别进行有放回抽样步骤,结合所有样本池抽样得到的人工合成虚拟样本和初始训练数据得到该基分类器的训练样本集xt_new(t=1,…,t);采用加权极限学习机作为基分类器,建立第i个基分类器hi(x);3)定义新的基于不平衡分类性能指标g-mean值的基分类器输出权值计算公式,获得基分类器hi(x)对应的输出权值αi;4)将步骤2)训练得到的t个基分类器基于其对应的输出权值αi进行加权并列集成,建立集成分类器;5)进行参数寻优,需要寻优的参数有基分类器的隐层节点数l及最优正则化系数c,寻优方法为网格法,以寻优得到的最优参数为基础,训练得到最终的集成分类器h(x);6)用步骤1)相同的方法填补污水待测数据的缺失值,并将其归一化到[0,1]区间,将处理后的待测数据输入h(x),得到输出分类结果即为待测数据对应的故障诊断结果。所述步骤1)具体过程如下:1.1)给定含n个污水样本集x={(x1,y1),(x2,y2),...,(xn,yn)},样本共有k个类别,其中有j个少数类,xi表示x的第i个样本,yi为k维列向量,表示其对应的类别标签,xi属第k类,则yi的第k个元素标为1,其余元素标为-1,第1类样本的类别标签写为{1,-1,...,-1};1.2)将x中样本数小于n×0.2的类别视为少数类,对少数类每类分别采用smote方法进行过采样,过采样后用得到的新样本用于构造该类的人工合成虚拟样本池dj,j=1,...,j。在步骤1.2)中,所述构造该类的人工合成虚拟样本池的具体过程如下:1.2.1)从x中得到第j类少数类样本,将所有第j类少数类样本组成子数据集xrj,nj为xrj所含的少数类样本数,对xrj的每个样本xri,计算其与xrj中其余所有样本的欧氏距离,设置m为(0,nj]范围内的随机数,得到关于xri含m个少数类样本的k最近邻(k-nearestneighbor,knn)子集si;1.2.2)设定过采样倍率aj,取aj=10;1.2.3)对xrj的每个样本xri,在其对应的si中随机采样一个近邻样本xrr,生成的新样本xnew的每个特征取值为在xrr与xri在该特征空间连线上随机的一点,即:xnew=xri+rand(0,1)×(xri-xrr)(1)其中,rand(0,1)表示0到1之间的一个随机数;1.2.4)重复步骤1.2.3)直至生成aj·nj个新样本为止,最后去除重复的生成样本,去重后的样本即为第j类样本对应的人工合成虚拟样本池dj;1.2.5)重复步骤1.2.1)到1.2.4),直至对每一类少数类的样本集xrj都进行了smote过采样步骤获得相应的人工合成虚拟样本池dj,j=1,...,j。在步骤3)中,所述基分类器hi(x)输出权值αi表示为:αi=0.5×ln(1+gmi)(2)其中,gmi为基分类器hi(x)在验证集中分类得到的g-mean值。在步骤4)中,所述集成分类器表示为:在步骤5)中,所述集成分类器的网格法寻优参数具体如下:设置集成分类器的基分类器个数t,t是(1,20]范围内的整数,然后寻找基分类器的隐含层节点数l、正则化系数c的参数组合以满足算法最优性能,l的寻优范围为{10,15,20,…,500},步长为5;c的寻优范围为{20,21,…,218},其中,步长为1。本发明与现有技术相比,具有如下优点与有益效果:1、本发明方法采用结合重采样样本池的加权集成算法作为整体算法框架,在训练基分类器前通过smote方法对少数类样本进行过采样,以构造人工合成虚拟样本池。2、在初始训练数据集的基础上,加入对人工合成虚拟样本池进行抽样随机获得的人工合成虚拟少数类样本,既实现了对少数类样本的过采样,也通过采用不完全相同的训练集训练每个基分类器保证了基分类器间的多样性。3、在对不平衡数据进行重采样处理的同时,对多个分类器进行加权集成以防止学习过程中的过拟合现象,并降低仅采用单个分类器在分类不平衡数据时可能会出现的偏差,增强算法的稳定性。4、本发明方法将重采样步骤与集成学习进行结合,在加权集成算法的基础上引入了人工合成虚拟样本池,样本池的引入使得一次过采样步骤可以训练多个多样性的多个基学习器,避免重采样步骤大量增加训练的耗时,保证了集成算法训练步骤的快速性。5、更注重不平衡污水数据中的故障类数据的分类性能,本发明采用g-mean值计算基分类器集成后相应的输出权值,定义了基于gmean的基分类器输出权值更新公式,提高了故障诊断类别的识别正确率。6、采用加权极限学习机作为本发明方法的基分类器,利用加权极限学习机的训练时间较短的优势加快集成分类器的学习速度,实现对污水处理状态实时准确的检测。7、通过基于人工合成虚拟样本池的过采样和加权极限学习机引入样本加权矩阵的方法提高了污水故障诊断的整体g-mean值,尤其是故障类别的诊断正确率得到了大幅提高。附图说明图1为本发明方法的训练流程图。图2为本发明方法的故障诊断流程图。具体实施方式为更加清楚地表述本发明实施例的目的、技术方案和优点,下面将结合本发明实施例中的附图来对本发明实施例中的技术方案进行全面的描述。需要指出的是本实施例仅是本发明一部分实施例,并不是全部的实施例。基于本发明中的实施例、本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本文采用加州大学数据(uci)中的污水处理厂数据做为实验仿真的数据。污水测量数据来自西班牙某城市的污水处理厂,该处理厂包括三级处理,一级处理为预处理,二级处理为活性污泥处理,最后进行氯化处理。污水处理厂历时两年通过传感器获取和生化处理之后系统的性能指标计算得到的527个样本。每个样本有38维属性,每个属性的含义如表1所示。将污水处理厂的运行状态分为13种,具体状态类别及其分布情况如表2所示。表1污水数据属性的名称和含义表2状态类别及其分布情况由表2可见,正常状态下的样本数远大于其他状态的样本数。其中,第2、3、4、6、7、8、10、12、13类每类样本数最多只有4个。为降低故障诊断过程的复杂性,将样本重新分为4类,分类结果如表3所示。表3527个样本在4分类下的分布情况类别1234原类别1、11592,3,4,6,7,8,10,12,13样本数3321166514在新的分类中,第一类表示正常状态,包括原始数据的第1、11类;第二类为正常状态但某些性能指标超过了平均值,包括原始数据第5类;第三类为正常状态但是进水流量低,包括原始数据第9类;第四类为故障类情况,包括原始数据的第2,3,4,6,7,8,10,12,13类。其中将第一、二类样本视为多数类,而第三、四类为少数类。结合表3各类的样本数容易看出,污水数据属于典型的重度不平衡数据。由于各种现实原因,污水数据有时不能完整的记录某个时刻所有属性的数据。所有属性数据都被完整地记录下来的样本只有380个,其中包括6个第四类样本。直接删去不完整数据样本会损失大量少数类样本的信息。因此对污水数据的缺失数据进行填补。目前存在成熟实用的数据填补方法,常用的数据填补方法有平均值填补法、特殊值填补法和最近邻距离填补法等。本发明采用近邻均值填补法对缺陷数据进行填补。具体做法是取缺陷数据近邻的5个数据的对应属性均值来作为缺陷数据的填补值。使用经过数据填补处理后的527个污水数据进行仿真实验。在进行仿真实验时,传统学习算法采用的总体准确率已无法再作为不平衡数据学习的评价指标。g-mean的中心思想是在使每类的分类准确率都尽可能大的同时,保持每个类别分类准确率之间的平衡。进行不平衡数据学习时,g-mean值在不平衡数据学习场合的性能使更注重评价分类器在少数类样本的分类准确率。本实施例采用g-mean值作为仿真实验结果的评价指标。本实施例是多分类问题。对k类问题,g-mean的混淆矩阵如表4所示:表4k类问题的混淆矩阵predictiveclass1predictiveclass2…predictiveclasskactualclass1n11n12…n1kactualclass2n21n22…n2k……………actualclassknk1nk2…nkk其中,第i类样本正确预测为第i类的样本个数为nii,预测错误的样本个数为nij(i≠j)。ri分别表示对第i类样本的召回率其定义为:g-mean定义为所有类的召回率的几何平均值,计算公式如下:以下称本发明的故障诊断方法为sp-ewelm(smotepool-ensembleweigheedextremelearningmachine),sp-ewelm在本实施例的具体实施过程,如图1和图2所示,包括以下步骤:1)采用加权集成算法作为整体算法框架,设置基分类器数量为t,分别独立训练具有多样性的t个基分类器,生成集成分类器。在具体应用中包括:1.1)在训练基分类器前,先通过smote方法构造少数类样本对应的人工合成虚拟样本池dj,j=1,...,j,其中j为少数类的类别个数。人工合成虚拟样本池dj,j=1,...,j的样本通过使用smote算法对第j类少数类数据进行过采样得到。smote方法是一种通过分析样本特征空间生成虚拟样本的方法来实现对样本的过采样的。smote方法的中心思想是在少数类样本的特征空间中通过线性插值合成得到新的少数类样本。与传统的随机过采样相比,smote可以更有效地避免过采样带来的数据冗余问题,在本实施过程中也是保证基学习器间多样性的关键。有原始训练集x,从x中得到第j类少数类样本,组成子数据集xrj。nj为xrj所含的少数类样本数。其中j在本实施例中有(j=3,4)。第j类少数类样本集xrj通过smote方法构造少数类样本对应的人工合成虚拟样本池dj的具体实现步骤如下:1.1.1)对xrj的每个样本xri(i=1,...,nj),计算其与xrj中其余所有样本的欧氏距离。设置m为(0,nj]范围内的随机数,得到其含m个少数类样本的knn子集si。1.1.2)根据该少数类样本数与训练集总样本数的比例确定过采样倍率aj。在本实施过程取值为aj=10。1.1.3)对xrj的每个样本xri,在其对应的si中随机采样一个近邻样本xrr。生成的新样本xnew的每个特征取值为在xrr与xri在该特征空间连线上随机的一点。即xnew=xri+rand(0,1)×(xri-xrr)(6)其中rand(0,1)表示0到1之间的一个随机数。1.1.4)重复步骤1.1.3)直至生成aj·nj个新样本为止。1.1.5)去除重复的生成样本。1.1.6)对每个少数类对应的样本集xrj进行上述smote过采样,得到相应的人工合成虚拟样本池dj,j=1,...,j。1.2)对每个基分类器构造对应的新训练数据集xi_new(i=,…,t),训练其对应的基分类器hi(x):本实施例采用加权极限学习机作为基分类器。设输入训练集为x={(x1,y1),(x2,y2),...,(xn,yn)}。训练集共有n个样本,样本含d个特征,被分为k类。其中yi为训练样本xi所对应的类别标签。yi为k维行向量。yi中只有{+1,-1}两种元素,有可以说,加权极限学习机(welm)采用单隐层前馈神经网络(single-hiddenlayerfeedforwardnetworks,slfn)结构作为整体框架。设定隐含层节点个数为l,极限学习机的输出模型可表示为:其中,βi表示第i个隐藏节点其对应输出节点的输出权值,δi表示输入层与第i个隐含节点的输入权值。θi为第i个隐含节点的偏置参数。oj为第j个训练样本下模型对应的输出。g(δi,θi,xj)为每个隐含层的激活函数,本实施例激活函数采用sigmoid函数。在训练过程中期望welm模型的输出无误差的对训练集x进行拟合,有即有激发函数矩阵h写作输出权值矩阵β写作(4)式可写作hβ=y(13)其中加权极限学习机训练目的是求取隐层节点向输出节点输出时的输出权值。为了解决不平衡分类问题将极限学习机(extremelearningmachine,elm)和加权策略进行结合得到的改进算法。根据类别对每个训练样本xi赋予一个权值wi,有其中#ci为训练集中类别正好为训练样本xi的类型ci的样本数。有权值矩阵w写作当激活函数g(δi,θi,xj)无限可微时,参数δi,θi在训练开始时可随机选定,且在训练过程中不需要进行更改。其中δi在(-1,1)范围下随机生成,θi在(0,1)范围下随机生成。这时welm的训练过程可转化为求解式(7)的最小二乘解,即转化为下列优化问题其中ξi为对样本xi分类器的训练误差。通过kkt最优化条件定义lagrange函数来求解式(11)的二次优化问题。定义li为lagrange乘数,将式(20)转化为通过求解式(21)可得hi(x)的隐层输出权值矩阵βi的解为即本步骤具体实施如下:1.2.1)组成组成新的训练样本集xt_new,t=1,...,t。具体过程为:对构造的样本池dj,j=1,...,j分别进行有放回booststrap抽样,获得合成的虚拟少数类样本。将抽样得到的虚拟少数类样本添加到原样本集中,组成新的训练样本集xt_new。1.2.2)根据公式(18)、(19)初始化样本权值矩阵w。1.2.3)随机设定参数δi,θi(i=1,…,l),按照公式(14)求激发函数矩阵h。1.2.4)根据公式(22)或(23)求取隐层输出权值矩阵βi。1.2.5)根据公式(24)获得加权极限学习机的输出模型hi(x)。1.2.6)根据下列公式获得hi(x)的输出权值αi:αi=0.5*ln(1+gmi)(22)其中,gmi为对应xt_new训练得到的hi(x)的g-mean值。1.3)将t个训练完毕的基分类器进行集成,所述集成分类器可表示为:2)输入原始训练数据,设置集成算法的基分类器个数t,基分类器的隐含层节点l,对应的最优正则化系数c,进行网格法参数寻优,输出最优参数组。在此实施例中设置sp-ewelm的基分类器个数t=7,寻找基分类器的隐含层节点数l、正则化系数c的参数组合以满足算法最优性能。隐含层节点l的寻优范围为{10,15,20,…,500},步长为5;c的寻优范围为{20,21,…,218},其中,步长为1。本发明在此实现例中的最优参数为:l=130;c=83)输入测试数据,设置集成算法的基分类器个数t,步骤2)寻优得到的基分类器的隐含层节点l和对应的最优正则化系数c以步骤1)训练得到h(x),待测数据输入h(x),得到输出分类结果即为待测数据对应的故障诊断结果。根据以上步骤,采用经过数据填补及归一化处理的污水样本集进行仿真实验。实验环境为intelcorei7处理器、12gb内存、windows7平台下的matlab2014a软件;采用5折交叉验证法,取支持向量机(supportvectormachine,svm)、c4.5、反向传播神经网络(backpropagationneuralnetworks,bpnn)、welm、基于加权极限学习机的bagging集成算法(bagging_welm)作对比算法。其中svm使用径向基核,由matlab自动寻优得到核函数的比例值,并对预测指标进行标准化。c4.5采用网格法对节点数进行寻优,寻优范围为[10,60],步长为2。bp采用网格法对节点数进行寻优,隐含层节点的寻优范围为{10,15,20,…,200},步长为5;学习率的寻优范围为{0.1,0.2,…,1},其中,步长为0.1。welm与bagging_welm采用本发明相同的样本权值赋值法,用网格法寻优,寻找基分类器的隐含层节点数l、正则化系数c和隐含层节点l的寻优范围及其对应寻优步长与本发明寻优过程设置相同,隐含层节点l的寻优范围为{10,15,20,…,500},步长为5;c的寻优范围为{20,21,…,218},其中,步长为1。实验结果如表5所示。表5仿真实验结果algorithmstraintimeaccg-meanr1r2r3r4sp-ewelm0.5600.8070.8120.8050.7830.8480.84welm0.0290.7580.7370.7680.6940.8350.707bagging_welm0.5100.7700.7180.7860.7040.8340.660svm0.1540.8100.6670.9380.6350.5250.667c451.7640.7290.3540.8840.4000.6380.333bpnn2.3220.6920.2160.7970.6270.3910.247表5给出了本实施例下进行的对比仿真实验结果,同时列出了本发明所用算法(sp-ewelm)及其对比模型bpnn、svm、c4.5、elm、bagging_welm的实验结果。其中r1、r2、r3、r4分别表示污水数据四大类对应的每一类的分类准确率。从表中可知,虽然sp-ewelm对于第一类样本(正常类)的分类准确率较其他对比算法略低,但是在其他三类的分类准确率中较其他算法取得较高的准确率。尤其在重要性最高的第四类(故障类)的分类准确率上,sp-ewelm的分类准确率比其他对比算法要高。同时,sp-ewelm在对比实验中取得了最高的整体g-mean值。由此可知,本发明所采用的算法比较适合应用于污水不平衡数据的分类诊断问题。综上所述,本发明针对污水处理厂的故障诊断问题,重点研究了基于基于重采样池的集成污水处理故障诊断方法。该方法利用加权集成算法作为整体集成算法框架,结合smote对原始少数类样本进行过采样构建重采样池,采用加权极限学习机作为集成算法的基分类器。一方面提高了污水故障诊断过程中少数类的分类准确率,另一方面利用极限学习机学习过程中对调参的要求较低、算法训练时间等优势,可保证故障诊断的时效性,值得推广。上述实施例为本发明效果较好的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1