一种面向高维大数据集的加权量化哈希检索方法与流程
本发明涉及一种数据检索方法,尤其是一种面向高维大数据集的加权量化哈希检索方法。
背景技术:
最近邻查找一直是计算机学科中的一个基础研究问题。一般情况下,哈希检索技术是能够解决大规模高维数据检索的一种有效方法,基于哈希的相似性查询方法具有良好的查询性能以及存储效率,但是现有的大部分哈希方法都认为哈希编码的各维度权重相同,也就是说,直接利用海明距离来对两数据之间的相似性进行度量;然而在实际情况中,不同的映射方向选择能够导致不同的分类效果,对应到哈希编码上,每一个维度都携带有不同的信息,因此编码不同维度对于数据之间相似性的影响也不同。
若采用海明距离作为度量标准,虽然对于数据相似性有一定的判断作用,但不能够充分的说明数据之间的距离远近,有待改进。
技术实现要素:
本发明所要解决的技术问题是提供一种能够有效提高哈希检索方法的检索效率和准确性的面向高维大数据集的加权量化哈希检索方法。
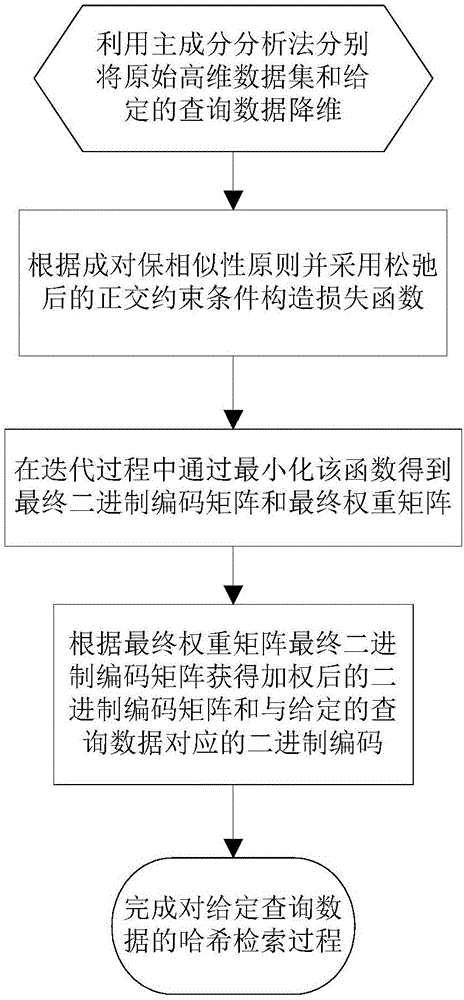
本发明解决上述技术问题所采用的技术方案为:一种面向高维大数据集的加权量化哈希检索方法,包括以下步骤:
①获取由n个原始高维数据组成的原始高维数据集x并给定查询数据q,x为n×d维的矩阵,q为1×d维的向量,使用主成份分析算法对x进行降维,得到与x对应的低维向量集v,
②通过迭代获取最终二进制编码矩阵b″和最终权重矩阵w”,具体过程如下:
②-1设定最大迭代次数,随机给定初始二进制编码矩阵b,b∈{-1,1}n×c,随机给定初始权重矩阵w,w=diag(w1,w2,…wj…,wc),其中,wj表示第j维度的维度权重,diag()表示对角矩阵;
②-2根据哈希函数构造原理中的成对保相似性原则构造损失函数,再引入完全正交约束条件,将完全正交约束条件进行松弛化操作,从而构造出损失函数
②-3开始迭代过程,在当前一次迭代过程中,首先保持w不变,对
再保持b'不变,通过对
②-4判断当前迭代过程的迭代次数是否达到设定的最大迭代次数,若未达到最大迭代次数,则令w=w',b=b′,返回步骤②-3开始下一次迭代过程,同时迭代次数加1,其中w=w'和b=b′中的“=”为赋值符号;若达到最大迭代次数,则将当前一次迭代过程中更新得到的w'作为最终权重矩阵w”,将当前一次迭代过程中更新得到的b′作为最终二进制编码矩阵b″;
③根据w”对b″中每个元素进行加权量化,获得加权后的二进制编码矩阵z;
④根据w”和b″,获取
所述的步骤②-1中设定的最大迭代次数为50次。
与现有技术相比,本发明的优点在于首先利用主成份分析算法分别对原始高维数据降维得到对应的低维向量集,对给定查询数据降维得到对应的低维向量,然后根据成对保相似性原则并采用松弛后的正交约束条件构造损失函数,通过最小化该损失函数得到最终二进制编码矩阵和最终权重矩阵,根据最终权重矩阵对最终二进制编码矩阵中每个元素进行加权量化,获得加权后的二进制编码矩阵,再根据最终二进制编码矩阵和最终权重矩阵获取与给定查询数据对应的二进制编码,在加权后的二进制编码矩阵中查找与给定查询数据对应的二进制编码的加权海明距离最近的行向量数据,将该行向量数据对应的原始高维数据作为最终的最近邻查询结果,完成对给定查询数据的哈希检索过程;通过利用加权海明距离对给定查询数据进行哈希检索,能够更好的挖掘数据集中的数据信息,并且保持数据之间的相似性信息;在构造损失函数时,采用松弛后的正交约束条件,在提高编码的有效性的同时,使哈希方法在投影过程中选择效果较佳的投影方向,从而进一步提高哈希检索方法的检索效率和准确性。
附图说明
图1为本发明的步骤流程图。
具体实施方式
以下结合附图实施例对本发明作进一步详细描述。
一种面向高维大数据集的加权量化哈希检索方法,包括以下步骤:
①获取由n个原始高维数据组成的原始高维数据集x并给定查询数据q,x为n×d维的矩阵,q为1×d维的向量,使用主成份分析算法对x进行降维,得到与x对应的低维向量集v,
②通过迭代获取最终二进制编码矩阵b″和最终权重矩阵w”,具体过程如下:
②-1设定最大迭代次数,随机给定初始二进制编码矩阵b,b∈{-1,1}n×c,随机给定初始权重矩阵w,w=diag(w1,w2,…wj…,wc),其中,wj表示第j维度的维度权重,diag()表示对角矩阵;其中设定的最大迭代次数可为50次。
②-2根据哈希函数构造原理中的成对保相似性原则构造损失函数,再引入完全正交约束条件,将完全正交约束条件进行松弛化操作,从而构造出损失函数
②-3开始迭代过程,在当前一次迭代过程中,首先保持w不变,对
再保持b'不变,通过对
②-4判断当前迭代过程的迭代次数是否达到设定的最大迭代次数,若未达到最大迭代次数,则令w=w',b=b′,返回步骤②-3开始下一次迭代过程,同时迭代次数加1,其中w=w'和b=b′中的“=”为赋值符号;若达到最大迭代次数,则将当前一次迭代过程中更新得到的w'作为最终权重矩阵w”,将当前一次迭代过程中更新得到的b′作为最终二进制编码矩阵b″;
③根据w”对b″中每个元素进行加权量化,获得加权后的二进制编码矩阵z;
④根据w”和b″,获取
- 还没有人留言评论。精彩留言会获得点赞!