一种基于文本图像融合识别的网页知识抽取方法与流程
本发明涉及知识抽取、图像识别、文本分析和深度学习技术,尤其涉及一种基于文本图像融合识别的网页知识抽取方法。
背景技术:
近年来,人工智能技术发展迅速,其商业化速度超出预期,人工智能将会给整个社会带来颠覆性的变化,已经成为未来各国重要的发展战略。以深度学习为核心的算法演进,其超强的进化能力,在大数据的支持下,通过训练构建得到类似人脑结构的大规模卷积神经网络,已经可以解决各类问题。而云计算和大数据的发展,特别是海量数据的出现,从大数据中进行深度学习,打破传统方式,对各个领域产生颠覆性的变革。
随着互联网的迅速发展,网络上聚集了海量信息,这些信息涉及各个领域,里面也隐藏着无数商机。例如政府公告的招投标信息,特别是企业涉足领域的信息,对企业而言有巨大的价值。如何在互联网中搜集到海量数据,并在海量数据中找到对于企业有价值的信息成为大家关注的焦点。
网络爬虫作为万维网的数据采集手段已经被广泛的使用,通过网络爬虫可以在短时间内,按照一定的规则,在互联网上自动地抓取大量用户关注的网页。然而现实中通过网络爬虫抓取的网页是纯html代码,其内容格式不固定,并且有些是以非结构化图像方式展示,涉及到的领域会也有专用的术语,并且其分散在不同的网站,而各个网站的可信度也不同。例如在招投标领域,网站公布的招投标信息会以不同的形式公告出来,并且网站的展示格式也不同,而真正对企业客户有价值的是其中的知识点。在这种情况下,如何有效利用深度学习技术,结合文本分析和图像分析,综合考虑各类因素,针对海量领域网页抽取知识成为亟须解决的问题。
技术实现要素:
为了解决以上技术问题,本发明提出了一种基于文本图像融合识别的网页知识抽取方法,保证了爬取数据准确性,提升爬取数据效率。
本发明的技术方案是:
一种基于文本图像融合识别的网页知识抽取方法,将网络爬虫在互联网上爬取网页的网站进行分类评估并设定信任度,利用文本分析方法基于语料库实现语义结构化,提取海量网页的价值数据关键字,同时将爬取网页转换成图片,提取结构化业务知识数据,对比分析两种方法提取的知识,不断学习训练出自动抽取模型,同时将确定的业务知识生成该网页的价值数据指纹,并加入到业务知识基础语料库中,持续更新自动抽取模型和基础语料库。
云端聚集大量计算、网络、存储资源,对外提供网页知识抽取相关的云服务,利用云端的网站信用评估服务对爬取网站进行分类评估,优先选取信用值高的网站执行网络爬虫程序爬取感兴趣的网页,存储到云端;将存储的网页利用云端的文本分析服务,基于语料库进行文本分析,提取网页中感兴趣的价值数据,利用云端图像转换服务将网页转换成图片,再利用云端图像识别服务,抽取网页图片的结构化业务知识数据;通过数据结构化存储服务将网页中提取得到的价值数据,保存到云端存储中,并为其生成价值数据指纹;利用云端价值数据匹配服务基于大数据仓库进行数据匹配,结合知识抽取服务对比同一价值数据指纹的文本分析和图像分析得到的知识,训练自动抽取模型,并将抽取的知识加入到基础语料库。其中,
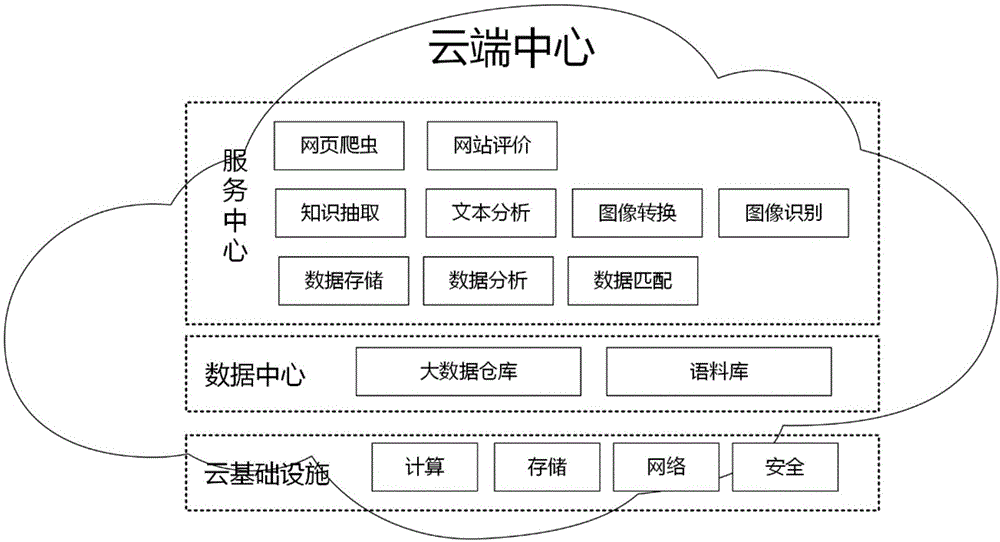
所述的云端中心提供云基础设施,同时提供网页知识抽取相关的云服务,包括网络爬虫、知识抽取、文本分析、图像转换、图像识别、网站评价、语料库、数据结构化存储、价值数据匹配等服务;
所述的网站信用评估服务对爬取网页的网站进行综合评估,充分考虑网站信用、数据准确性、数据时效性等多种因素,得到目标爬取网站的信用值,为网络爬虫提供更好的服务;
所述的网络爬虫服务包含对网页爬取任务的生成、执行、管理等,根据网站评价值采用分布式任务分解方式抓取感兴趣的网页;
所述的文本分析服务将存储的网页基于语料库进行文本分析,提取网页中感兴趣的价值数据文本分析,获取业务知识数据;
所述的图像转换服务通过模拟浏览器展示,将网页转换成图像;所述的图像识别服务识别网页图片的内容,提取其中的结构化业务知识数据;
所述的数据结构化存储服务将网页抽取数据存储到所述的大数据仓库中,同时生成价值数据指纹作为其标识;
所述的数据匹配服务计算网页价值数据指纹,基于大数据仓库进行匹配,确定网页本体;
所述的大数据仓库是根据业务领域分类的行业大数据,提供数据仓库的基本服务;所述的知识抽取服务利用大量的网页数据进行训练学习,同时对比结合同一价值数据指纹的文本分析和图像分析得到的知识,形成自动抽取模型,并将抽取的知识加入到基础语料库;所述的语料库是针对行业的,用于语义分析。
本发明具体操作步骤为:
步骤101、通过所述的云端网页爬虫服务提交网页爬取任务请求,设置爬取任务所属领域及规则;
步骤102、根据所述的网站信用评估服务提供的网页信任度数据,生成网页爬取任务;
步骤103、所述的云端中心将网页爬取任务进行分解,利用云端计算、网络、存储资源爬取目标网站;
步骤104、所述的云端网页爬虫服务将任务目标网站的网页爬取下来,存放在云端;
步骤105、通过所述的文本分析服务将存储的网页进行预处理,将网页数据结构化,基于语料库进行文本分析,提取网页中感兴趣的价值数据;
步骤106、使用所述的图像转换服务通过模拟浏览器展示,将网页转换成图像,并通过图像识别服务识别网页图片的内容,提取其中的结构化业务知识数据;
步骤107、使用所述的数据匹配服务计算网页价值数据指纹,基于大数据仓库进行匹配,确定网页内在价值数据标识;
步骤108、通过所述的知识抽取服务的自动抽取模型对网页价值数据进行提取,对比结合同一价值数据指纹的文本分析和图像分析得到知识,精炼价值数据;
步骤109、将知识数据和价值数据通过所述的结构化存储服务,保存到所述的大数据仓库中,同时生成价值数据指纹作为其标识;
步骤110、所述的知识抽取服务采用lstm等深度学习算法,根据持续收集的海量知识数据确定深度学习网络模型结构,并进行模型训练和学习,得到自动抽取模型;
步骤111、所述的知识抽取服务将得到的知识加入到所述的语料库中;
步骤112、重复执行步骤101至步骤111,持续更新知识抽取网络模型和语料库,提升价值数据和知识抽取质量;
步骤113、结合所述的语料库和所述的大数据仓库收集的数据,可以进行更深层次的语义理解和领域价值洞察分析。
本发明的有益效果是:
本发明将网络爬虫在互联网上爬取网页的网站进行分类评估并设定信任度,优先选取信用值高的网站执行网络爬虫程序爬取感兴趣的网页,这保证了爬取数据准确性,提升爬取数据效率;综合文本分析及图像分析,基于现有基于语料库实现语义结构化,提高了语义结构化的准确性;通过将网页文本转换成图片的方式,消除了html内容展示标签格式的影响,实现了非结构化数据的知识抽取,提高了网页内容识别准确率,而通过图像文本两种抽取方式分析对比,使得抽取的价值数据更加准确;另外,采用深度学习算法持续不断的训练自动抽取模型,提升了抽取模型的时效性,对比传统的人工方式,极大的提升了效率,并且抽取得到的知识将不断丰富语料库,未来可以实现更深程度的语义理解,带来更大的商业价值。
附图说明
图1是网页知识抽取功能组成示意图;
图2是网页知识抽取流程图。
具体实施方式
下面结合附图对本发明的内容进行更加详细的阐述:
如图1所示,云端聚集大量计算、网络、存储资源,对外提供网页知识抽取相关的云服务,利用云端的网站信用评估服务对爬取网站进行分类评估,优先选取信用值高的网站执行网络爬虫程序爬取感兴趣的网页,存储到云端;将存储的网页利用云端的文本分析服务,基于语料库进行文本分析,提取网页中感兴趣的价值数据,利用云端图像转换服务将网页转换成图片,再利用云端图像识别服务,抽取网页图片的结构化业务知识数据;通过数据结构化存储服务将网页中提取得到的价值数据,保存到云端存储中,并为其生成价值数据指纹;利用云端价值数据匹配服务基于大数据仓库进行数据匹配,结合知识抽取服务对比同一价值数据指纹的文本分析和图像分析得到的知识,训练自动抽取模型,并将抽取的知识加入到基础语料库。其中,
所述的云端中心提供云基础设施,同时提供网页知识抽取相关的云服务,包括网络爬虫、知识抽取、文本分析、图像转换、图像识别、网站评价、语料库、数据结构化存储、价值数据匹配等服务;所述的网站信用评估服务对爬取网页的网站进行综合评估,充分考虑网站信用、数据准确性、数据时效性等多种因素,得到目标爬取网站的信用值,为网络爬虫提供更好的服务;所述的网络爬虫服务包含对网页爬取任务的生成、执行、管理等,根据网站评价值采用分布式任务分解方式抓取感兴趣的网页;所述的文本分析服务将存储的网页基于语料库进行文本分析,提取网页中感兴趣的价值数据文本分析,获取业务知识数据;所述的图像转换服务通过模拟浏览器展示,将网页转换成图像;所述的图像识别服务识别网页图片的内容,提取其中的结构化业务知识数据;所述的数据结构化存储服务将网页抽取数据存储到所述的大数据仓库中,同时生成价值数据指纹作为其标识;所述的数据匹配服务计算网页价值数据指纹,基于大数据仓库进行匹配,确定网页本体;所述的大数据仓库是根据业务领域分类的行业大数据,提供数据仓库的基本服务;所述的知识抽取服务利用大量的网页数据进行训练学习,同时对比结合同一价值数据指纹的文本分析和图像分析得到的知识,形成自动抽取模型,并将抽取的知识加入到基础语料库;所述的语料库是针对行业的,用于语义分析。
为了描述清楚,以下选择招投标领域,招标信息将在网站中进行公告,其中招标信息包括了招标企业、招标产品、招标方式、招标类型、招标名称、联系电话、截止时间、企业要求、中标结果、采购数量等要素点;这些信息会以结构化或者非结构化的方式呈现出来,以下案例将使用网络爬虫爬取这些信息所在的网页。以下实例中的图像识别算法采用r-cnn,文本分析主要是基于lstm长短期记忆网络来实现。本领域技术人员将理解的是,除了使用以上算法和领域之外,根据本发明的实施方式的构造也能够应用于其他算法和领域之上。
如图2所示,网页的知识抽取包括以下步骤:
步骤101、通过所述的云端网页爬虫服务提交网页爬取任务请求,设置爬取任务所属领域及规则;
步骤102、根据所述的网站信用评估服务提供的网页信任度数据,生成网页爬取任务;
步骤103、所述的云端中心将网页爬取任务进行分解,利用云端计算、网络、存储资源爬取目标网站;
步骤104、所述的云端网页爬虫服务将任务目标网站的网页爬取下来,存放在云端;
步骤105、通过所述的文本分析服务将存储的网页进行预处理,将网页数据结构化,基于语料库进行文本分析,提取网页中感兴趣的价值数据;
步骤106、使用所述的图像转换服务通过模拟浏览器展示,将网页转换成图像,并通过图像识别服务识别网页图片的内容,提取其中的结构化业务知识数据;
步骤107、使用所述的数据匹配服务计算网页价值数据指纹,基于大数据仓库进行匹配,确定网页内在价值数据标识;
步骤108、通过所述的知识抽取服务的自动抽取模型对网页价值数据进行提取,对比结合同一价值数据指纹的文本分析和图像分析得到知识,精炼价值数据;
步骤109、将知识数据和价值数据通过所述的结构化存储服务,保存到所述的大数据仓库中,同时生成价值数据指纹作为其标识;
步骤110、所述的知识抽取服务采用lstm等深度学习算法,根据持续收集的海量知识数据确定深度学习网络模型结构,并进行模型训练和学习,得到自动抽取模型;
步骤111、所述的知识抽取服务将得到的知识加入到所述的语料库中;
步骤112、重复执行步骤101至步骤111,持续更新知识抽取网络模型和语料库,提升价值数据和知识抽取质量;
步骤113、结合所述的语料库和所述的大数据仓库收集的数据,可以进行更深层次的语义理解和领域价值洞察分析。
以上所述的实施例,只是本发明具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!