一种基于查询推理的OLAP元数据冲突的自动修复方法与流程
本发明属于数据仓库及olap技术领域,尤其是一种基于查询推理的olap元数据冲突的自动修复方法。
背景技术:
数据仓库技术和olap技术为企业的决策支持提供了重要的支撑,它们使得企业决策者可以创造性地分析和理解业务问题。与数据仓库的目的是存储用于辅助决策过程的大量集成数据不同,olap系统支持对大量多维数据进行动态合成、分析和合并。olap系统使用多维范例并以数据立方体(cube)的形式组织数据,每个数据立方体是单个维度(dimension)的多级别、多维度的组合。通过对汇总后的数据进行预分类和存储,olap系统可以反映静态变量、动态变量、维度以及度量之间的关系。其中每个维度包含一个或多个层次以及属性。olap系统通过对预定义的层次进行处理为两种典型的操作提供了基础,即上卷和下钻。
通过引入面向对象思想的元数据管理,模型驱动的元数据集成方法支持对多维olap数据的元数据进行建模和查询。该模型的基本概念包括对象、类和对象之间的关系并以类的层次结构进行展现,从而可以实现对多维数据对象进行描述和olap操作。
olap元数据的质量显著地影响olap工具的稳定性和可靠性。然而由于元数据通常具有复杂的结构化特征,在olap元数据的建立过程中经常会出现不一致的问题,并且由于olap元数据缺乏形式化的语义,如何自动发现和修复元数据中的冲突是一件棘手的问题。
经检索,未在国际和国内发现借助逻辑学手段来解决olap元数据冲突的发现和修复问题的文献。
技术实现要素:
本发明的目的在于提出一种设计合理且能够准确发现并修复冲突的olap元数据冲突的自动修复方法。
本发明解决其技术问题是采取以下技术方案实现的:
一种基于查询推理的olap元数据冲突的自动修复方法,包括以下步骤:
步骤1、将olap元-元数据转化为描述逻辑知识库的tbox;
步骤2、将olap元数据转化为描述逻辑知识库的abox;
步骤3、olap元数据冲突的发现处理;
步骤4、olap元数据冲突的修复处理。
所述步骤1描述逻辑知识库的tbox的建立方法为:
⑴元类和数据类型:将每个元类和每个数据类型unlimitednatural转换为一个描述逻辑概念,每个数据类型integer和string分别转换为具体域z和string;
⑵元属性:将每个元属性n转换为一个描述逻辑角色并向tbox中加入以下断言:
⑶元关联:假定元类c和c’之间的元关联为assoc,其相应的关联端分别为assocend1和assocend2,则将其转换为描述逻辑概念assoc及角色assocend1和assocend2,角色assocend1的定义域和值域分别为c和c’,assocend2与之相反;为了描述角色和关联端的对应性以及assocend1和assocend2之间的互逆性,向tbox中加入下述三条断言:
⑷元聚合:元聚合的转换方式与元关联基本基本相同,区别在于元聚合规定将包含类作为相关联角色的定义域;
⑸继承:将每个继承关系转换为子集关系。
所述步骤2描述逻辑知识库abox的建立方法为:
⑴如果olap元数据中的元素c是元-元数据中的元类c的实例,则向abox中加入下述断言:c:c;
⑵如果元数据中的元素c1关联到c2,相应的元类c1通过元关联/元聚合关联到元类c2,上述元关联/元聚合被转化为概念a和互逆角色r1和r2,则向abox中加入下述三个断言:a:a;<a,c1>:r1;<a,c2>:r2。
所述步骤3利用nrql作为查询知识库从而发现olap元数据冲突的工具。
所述步骤4采用基于规则的冲突修复方法进行olap元数据冲突的修复处理,该基于规则的冲突修复方法满足如下需求:
⑴冲突修复规则具有如下格式:
if冲突x出现在元数据m中then改变元数据m以便x被修复;
⑵规则的条件是abox查询和用户输入提示的合集;
⑶规则的结论是一系列abox断言;
⑷规则的执行过程是基于abox中的断言。
本发明的优点和积极效果是:
本发明设计合理,其通过将元数据转换为逻辑学的知识库,而后在知识库之上执行查询推理来检测冲突,最后通过知识库修改操作修复冲突,能够准确发现并修复这些冲突,从而自动增强olap元数据的一致性。
附图说明
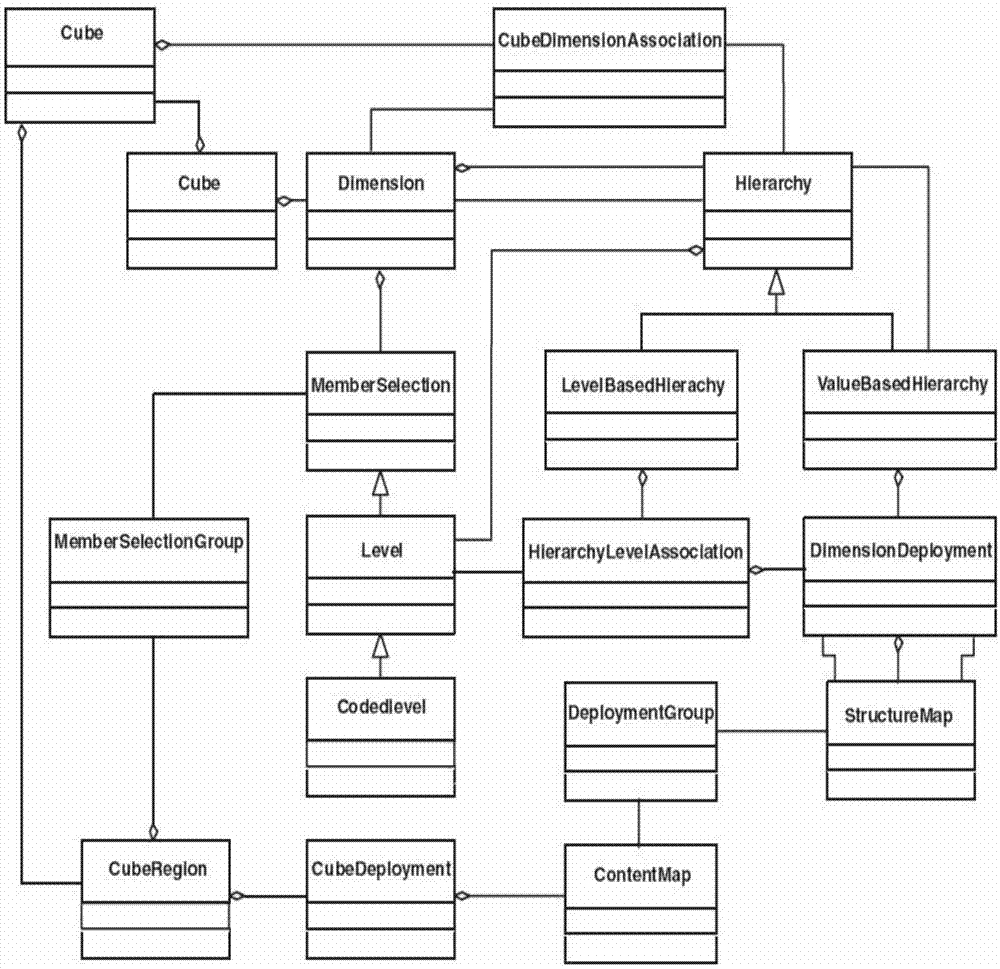
图1是olap元-元数据的结构示例图;
图2是olap元-元数据中的元关联图;
图3是olap元-元数据中的元聚合图;
图4是olap元数据的结构示例图。
具体实施方式
以下结合实施例对本发明做进一步详述。
本发明基于一种静态的形式化机制——描述逻辑,它是一阶谓词逻辑的可判定子集。我们通过将元数据转换为描述逻辑的知识库,而后在知识库之上执行查询推理来检测冲突,最后通过知识库修改操作来修复冲突。
基于以上说明,本发明的一种基于查询推理的olap元数据冲突的自动修复方法,包括以下步骤:
步骤1:将olap元-元数据转化为描述逻辑知识库的tbox。
在模型驱动的元数据集成中,olap元-元数据和元数据之间的关系是类型-实例关系,因此我们将olap元数据转换为知识库的tbox,并将olap元数据转换为abox。为了简明起见,下面的形式化描述均以描述逻辑表达式的形式给出。
(1)元类和数据类型
由于每个元类以及数据类型unlimitednatural均表示一组实例的集合,因此我们将每个元类和每个数据类型unlimitednatural转换为一个描述逻辑概念。每个数据类型integer和string分别转换为具体域z和string。
(2)元属性
由于元属性n表示其所属的元类c和属性类型c’之间的二元关系,因此我们将元类n转换为描述逻辑角色并向tbox中加入以下断言:
(3)元关联
在olap元-元数据中,每个元关联都有一个相应的关联类,并且所有的元关联都是二元的和双向的,比如图2中dimension和hierarchy之间的元关联。假定元类c和c’之间的元关联为assoc,其相应的关联端分别为assocend1和assocend2,则我们将其转换为描述逻辑概念assoc及角色assocend1和assocend2,角色assocend1的定义域和值域分别为c和c’,assocend2与之相反。由于每个角色对应于一个关联端,因此二者是互逆角色。为了表达上述知识,我们向tbox中加入下述三条断言:
(4)元聚合
olap元-元数据中的元聚合(如图3所示)是两个元类之间的二元关系,用于表达部分—整体关系。例如levelbasedhierachy和hierarchylevelassociation之间的元聚合表示每个levelbasedhierachy的实例由一组hierarchylevelassociation的实例构成。元聚合的名字是唯一的,即不存在两个具有相同名字的元聚合。元聚合的转换方式与元关联基本相同,区别在于我们规定将包含类作为相关联角色的定义域。
(5)继承
子元类和父元类之间的继承关系指定每个子元类的实例也是父元类的实例,因此子元类继承了父元类的全部属性,此外它们还可以定义父元类中不存在的属性。继承关系的实质与描述逻辑中的子集关系完全相同,因此我们将每个继承关系转换为子集关系。比如图3中levelbasedhierachy和hierachy之间的继承关系可以转化为下述断言:
步骤2:将olap元数据转化为描述逻辑知识库的abox
olap元数据中的每个元素都是olap元-元数据中相应元素的实例,因此我们将olap元数据转化为知识库中的abox。分两种情况:
(1)如果olap元数据中的元素c是元-元数据中的元类c的实例,则向abox中加入下述断言:c:c;
(2)如果元数据中的元素c1关联到c2,相应的元类c1通过元关联/元聚合关联到元类c2,上述元关联/元聚合被转化为概念a和互逆角色r1和r2,则向abox中加入下述三个断言:a:a;<a,c1>:r1;<a,c2>:r2。
按照上述规则,图4中的olap元数据可转换为:
sales:cube
prodkey:attribute
salesmea:measure
saleskey:cube
prod:cubedimensionassociation
product:dimension
<sales,prodkey>:classifier-feature
<sales,salesmea>:classifier-feature
<sales,saleskey>:cube-cube
<sales,prod>:cube-cubedimensionassociation
...
classifiervstructfea:classifiervstructfea
<classifiervstructfea,saleskey>:classifiervstructfea-classifier
<classifiervstructfea,prodkey>:classifiervstructfea-structfea
cubedimassovdim:cubedimassovdim
<cubedimassovdim,prod>:cubedimassovdim-cubedimasso
<cubedimassovdim,product>:cubedimassovdim-dim
步骤3:olap元数据冲突的发现
知识库建立以后,利用推理工具的查询推理机制就可以对元数据进行查询及推理从而发现各种不一致信息。由于推理引擎racer提供了表达能力很强的查询语言nrql,它提供了对查询体和多种查询原子的支持,因此我们选择nrql作为查询知识库从而发现olap元数据冲突的工具。
下面给出检测维度引用冲突的例子,该冲突发生于一个cube引用的维度在元数据的其它部分并不作为度量类型出现的情形。
为了检测该类冲突,可以定义下面两个nrql查询。在执行这两个查询之前须给定度量类型mt和其所在的元数据范围meta-context-1。第一个查询如下:
该查询根据给定的度量类型mt及其所在的元数据范围meta-context-1检索知识库,查找在meta-context-1中以该类型作为维度的cube。其结果集合为meta-context-1中的以mt对应的维度dim作为边的cube2构成的集合。如果meta-context-1中不存在这样的cube,则结果集合为空。因此执行完该查询之后需判断结果集合是否为空,若为空则说明元数据中存在维度引用冲突。
执行第一个查询后若发现维度引用冲突,则执行如下的第二个查询:
该查询首先根据元数据的演化轨迹找到meta-context-1的相关区域meta-context-2,然后查找在meta-context-2中是否有以该度量类型作为维度的cube,如果成功,则返回所有满足条件的meta-context-2构成的集合,从而为追踪维度引用冲突产生的原因提供进一步的参考。
步骤4:olap元数据冲突的修复
在本发明中,我们借鉴了软件工程的冲突管理领域的研究思想,将如何消解冲突的问题称为冲突修复,而将消解冲突的过程称为修复活动。
我们采用了基于规则的冲突修复方法,主要基于以下几点原因:
(1)一个特定的冲突可以有多种修复方法,分别对应不同的修复活动,选择哪一种修复活动依赖于冲突的成因。例如对于维度引用冲突,可能的修复活动有:(a)将度量类型所引用的维度添加进元数据的相关部分;(b)将cube的度量类型替换为元数据中已存在的类型;(c)删除维度的度量类型属性。发生的可能原因有:度量类型所引用的维度或其所在的cube已被删除;或者该类型或其所在的cube还未被加入到元数据中等等,冲突的成因不同,修复活动也不同。然而有时冲突的成因是很难判定的,因此在这些情况下还需要由用户决定执行哪些修复活动。而基于规则的推理将冲突的发现和修复活动封装在一起。每个冲突可以被不同的方法修复。冲突的修复方法的选择可以依赖于元数据的特定状态,也可以依靠用户的主观判断。很好地解决了以上问题。
(2)如果一个特定的冲突被发现,修复该冲突归结为改变该冲突涉及到的元类和元关联的实例。我们将修复活动分为三种原子修复活动:(a)添加元数据元素,即一个元类的实例化;(b)删除元数据元素,即某个元类的一个实例的删除;(c)改变元数据元素,即通过改变元数据元素的属性之一(即它所引用的其它元数据元素),而改变该元数据元素。冲突修复机制必须允许上述的修复活动的组合。而基于规则的推理将冲突的发现和修复活动进行封装,并允许修复活动的自由组合。
(3)修复活动的执行可能会引起新的冲突。例如一个修复活动是将某一度量类型的维度的描述删除,而没有及时删除将该维度作为边的cube的引用描述,就会产生维度引用冲突,即该冲突是由于其它冲突的修复活动的执行而产生的新的冲突。对于一个特定的冲突,它对应的不同修复活动可能导致的新的冲突是不同的。冲突修复机制必须能够处理由于修复活动执行而产生的新的冲突的情形。在非基于规则的编程语言中考虑冲突之间的依赖将会使程序变得非常复杂并且难以维护。而在基于规则的系统中,规则仅需定义一次并且可以反复激活,因此基于规则的方法为规则的重用提供了很好的支持,解决了上述问题。
基于上述考虑,我们选择了基于规则的olap元数据冲突的修复方法。针对元数据中冲突的特点和上述形式化方法及冲突发现方法,下面分析用于元数据冲突修复的描述逻辑规则语言应满足的需求。
冲突修复规则应该具有如下格式:
if冲突x出现在元数据m中
then改变元数据m以便x被修复
对于一个特定的冲突来说通常有多种修复方法,每种方法由一个规则给出。因此,和某一冲突x相关的所有规则在条件中拥有相同的表达式:冲突x出现在元数据m中。
此外,还应满足以下需求:
(1)规则的条件是abox查询和用户输入提示的合集。abox查询用于发现冲突并检索额外的信息以便修复冲突。用户输入提示有两个作用:如果对于一个冲突有多个规则被激活,它们让用户决定选择哪种修复方法;如果需要,它们提示用户附加的输入。
(2)规则的结论是一系列abox断言,它们对应一个或一组修复活动。这些断言修复已发现的冲突,并且仅仅可以使用在规则的条件中返回的变量或常量。
(3)规则的执行过程是基于abox中的断言。
racer提供的nrql不仅是一种查询语言,也提供了规则机制允许用户对abox进行修改。nrql规则拥有条件和结论。条件是一个nrql查询体。nrql规则的结论是一组abox断言,这些断言可以引用在规则的前提中返回的变量,对它们进行删除和修改,也可以建立新的abox个体,从而对abox进行扩充。nrql规则仅考虑abox中明确陈述的知识。尽管nrql规则的条件不允许包含提示用户输入的表达式,我们可以采用其它方法来替代,即将描述用户选择的特定个体人为植入到abox中,然后通过查询来获得用户的选择。经过这样处理,nrql符合上述所有需求,可以利用nrql来修复元数据冲突。
举例来说,我们可以用下面的nrql规则来修复维度引用冲突,采用的修复方法是删除维度的度量类型属性:
其中and表达式是规则的条件,而后三个表达式是规则的结论,它包含三个修复活动的组合。
下面对本发明的有效性进行说明:
在模型驱动的元数据集成中,olap元-元数据以元模型的形式提供。以本专利所处理的元数据模型为例进行说明,如图1所示。其中schema元类容纳了包括dimension元类和cube元类在内的olap模型的全部元素。每个dimension表示维度上顺序位置的成员的集合。因此,维度实际上标识了其成员的属性,通过每个成员所属的维度可以标识单个成员。memberselection元类和memberselectiongroup元类用于限制当前查看的维度的范围。维度也可以包含成员的多个层次结构(通过聚合hierarchy元类来实现),包括支持按层次的属性值(valuebasedhierarchy元类)和层次的级别(levelbasedhierarchy元类)对成员进行排序的两种特定层次结构。
每个cube是由同一组维度所描述的值的集合。从直观上说,每个维度表示cube的一个边。cube还可以进一步细分为一组cuberegion的集合,每个cuberegion定义了大cube的一个子集并用于在实现olap的过程中对数据的物理存储位置进行限制。最后,cubedeployment元类和dimensiondeployment元类用于在实现olap的过程中将cube映射到具体的部署策略。
以上述元-元数据为基础,我们对其进行实例化得到了olap元数据,而后验证本发明的有效性。元数据冲突采用人工植入的方式,它们涵盖了olap元数据冲突的各个方面,如与维度层次的改变有关的冲突、与cube的建立删除和修改有关的冲突、与层次的属性和级别的改变有关的冲突、与schema的建立和删除有关的冲突、与部署的改变有关的冲突等等,实验结果表明,本方法均能够准确发现并修复这些冲突。
需要强调的是,本发明所述的实施例是说明性的,而不是限定性的,因此本发明包括并不限于具体实施方式中所述的实施例,凡是由本领域技术人员根据本发明的技术方案得出的其他实施方式,同样属于本发明保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!