基于机器学习算法的工单质检方法和装置与流程
本发明涉及移动通信的网管技术领域,具体地说涉及eoms系统中的工单内容进行质检的方法和装置。
背景技术:
现有eoms系统(electricoperationmaintenancesystem,电子运维系统)中包含了一整套工单流转与处理的流程。客服平台生成的投诉工单流转至eoms系统,监控室投诉处理班组对部分字段根据规则和经验进行判断是否符合。在整个环节中,主要在受理、预处理、报结这3个环节需要人工进行检查。人工检查费时费力,且由于工单量大、人力成本高,通常只能做到抽检,无法对全量工单进行检查。
为了解决人工检查费时费力的问题,现有通常的做法是通过设定固定的质检规则的方式来对工单文本进行判断。这种方式通常需要经验丰富的质检人员设定检测规则、构建检测字典等方式。但是,由于工单内容通常为非结构化文本,通常缺少固定的格式,导致构建能够覆盖全面的规则的难度较大,且构建规则时的判断费时费力,准确率也不高。
技术实现要素:
根据本发明第一方面,提供一种基于机器学习算法的工单质检方法,包括:从待质检工单中抽取出投诉内容、附加报结信息、业务类别三个信息;利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量;基于向量,利用训练模型进行预测,获取预测的业务类别;其中,训练模型是利用业务类别正确的历史工单训练得到;将预测的业务类别与从工单抽取的业务类别进行对比,如果一致则认定该工单的投诉内容、附加报结信息与业务类别一致。
根据本发明第二方面,提供一种基于机器学习算法的工单质检方法,包括:从待质检工单中抽取出附加报结信息、解决情况这两个信息;利用分词词典、停用词词典对附加报结信息进行分词,去除停用词操作;分别对分词后的附加报结信息进行向量化;基于向量,利用训练模型进行预测,获取预测的解决情况;其中,训练模型是利用解决情况正确的历史工单训练得到;将预测的解决情况与从工单抽取的解决情况进行对比,如果一致则认定附加报结信息和解决情况一致。
根据本发明第三方面,提供一种基于机器学习算法的工单质检方法,包括:从待质检工单中抽取出投诉内容、附加报结信息、报结意见三个信息,以及基站小区状态表的数据;利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为第一向量;对工单中的故障地址与基站小区状态表中的地址做模糊匹配,获取故障地址是否已知弱覆盖信息以及场景信息,将弱覆盖信息与场景信息转化为第二向量并与第一向量结果合并为第三向量;基于上述合并后的第三向量,利用训练模型进行预测,获取预测的报结意见;其中,训练模型是利用报结意见正确的历史工单训练得到;将预测的报结意见与从工单抽取的报结意见进行对比,如果一致则返回投诉内容、附加报结信息和报结意见一致。
根据本发明第四方面,提供一种工单质检装置,包括:抽取单元,从待质检工单中抽取出投诉内容、附加报结信息、业务类别三个信息;分词单元,利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;向量化单元,分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量;预测单元,基于向量,利用训练模型进行预测,获取预测的业务类别;其中,训练模型是利用业务类别正确的历史工单训练得到;对比单元,将预测的业务类别与从工单抽取的业务类别进行对比,如果一致则认定该工单的投诉内容、附加报结信息与业务类别一致。
根据本发明第五方面,提供一种工单质检装置,包括:抽取单元,从待质检工单中抽取出附加报结信息、解决情况这两个信息;分词单元,利用分词词典、停用词词典对附加报结信息进行分词,去除停用词操作;向量化单元,分别对分词后的附加报结信息进行向量化;预测单元,基于向量,利用训练模型进行预测,获取预测的解决情况;其中,训练模型是利用解决情况正确的历史工单训练得到;对比单元,将预测的解决情况与从工单抽取的解决情况进行对比,如果一致则认定附加报结信息和解决情况一致。
根据本发明第六方面,提供一种工单质检装置,包括:抽取单元,从待质检工单中抽取出投诉内容、附加报结信息、报结意见三个信息,以及基站小区状态表的数据;分词单元,利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;向量化单元,分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为第一向量;弱覆盖信息与场景信息向量化单元和合并单元,对工单中的故障地址与基站小区状态表中的地址做模糊匹配,获取故障地址是否已知弱覆盖信息以及场景信息,将弱覆盖信息与场景信息转化为第二向量并与第一向量合并;预测单元,基于上述合并后的第三向量,利用训练模型进行预测,获取预测的报结意见;其中,训练模型是利用报结意见正确的历史工单训练得到;对比单元,将预测的报结意见与从工单抽取的报结意见进行对比,如果一致则返回投诉内容、附加报结信息和报结意见一致。
采用本发明实施例的技术优点:能够通过增加特征、svm的模型调优等方式来获得效果最优的模型,从而提高结果判断准确率。不需要人工提炼规则,只需要利用历史数据就能对模型进行迭代更新。在未来新增工单内容、新增投诉类别等信息之后也能快速迭代。由于大部分合格工单已经被筛选过滤,所以能够大量减少人工审核工单的数量。
附图说明
图1是根据本发明实施例的基于业务类别分类模型的工单质检方法示意图;
图2是根据本发明实施例的基于解决情况分类模型的工单质检方法示意图;
图3是根据本发明实施例的基于报结意见分类模型的工单质检方法示意图;
图4示意了根据本说明书实施例的可用于实现上述各种技术的设备的详细结构图;
图5是基于业务类别分类模型的工单质检装置的示意图;
图6是基于解决情况分类模型的工单质检装置的示意图;
图7是基于报结意见分类模型的工单质检装置的示意图。
具体实施方式
本发明实施例基于机器学习的文本分类算法自动对工单内容进行分类。利用历史工单数据对模型进行训练和迭代优化。然后通过训练后的模型获得准确的工单类别,并与实际填写的内容进行比对。将比对失败的工单标记为质检不合格并输出。
当前情况下,每月大致有例如15万以上的工单,每个待质检工单中均包含:投诉内容、附加报结信息、投诉业务类别、解决情况、报结意见。在质检时,主要判断投诉业务类别、解决情况、报结意见是否填写正确,是否和投诉内容、附加报结信息相匹配。如果利用人工质检,则费时费力,如果利用规则质检,则准确率不高且规则设定是否困难。
本发明实施例基于机器学习中的tfidf(termfrequency–inversedocumentfrequency词频-逆文本频率指数)和svm(supportvectormachine,支持向量机)算法,基于投诉内容、附加报结信息、投诉业务类别、解决情况、报结意见等字段中的一个或多个分别构建文本分类模型,利用训练后的模型对工单进行质检。
tfidf是一种统计方法,通过计算文本中的词频数和逆向文件频率的乘积来给词赋值,从而对文本进行向量化。一个词在一段文本中出现的次数越多,在所有文本中出现的次数越少,则越能代表该段文本,其tfidf的值越大。
svm算法是机器学习算法中的一种分类模型。它的分类思想是根据正负样本,通过寻找一个超平面对样本进行分割。
在工单质检的流程当中,需要以投诉内容、附加报结信息作为特征,再分别将投诉业务类别、解决情况、报结意见作为标签,构建与优化三个分类模型对类别进行预测。
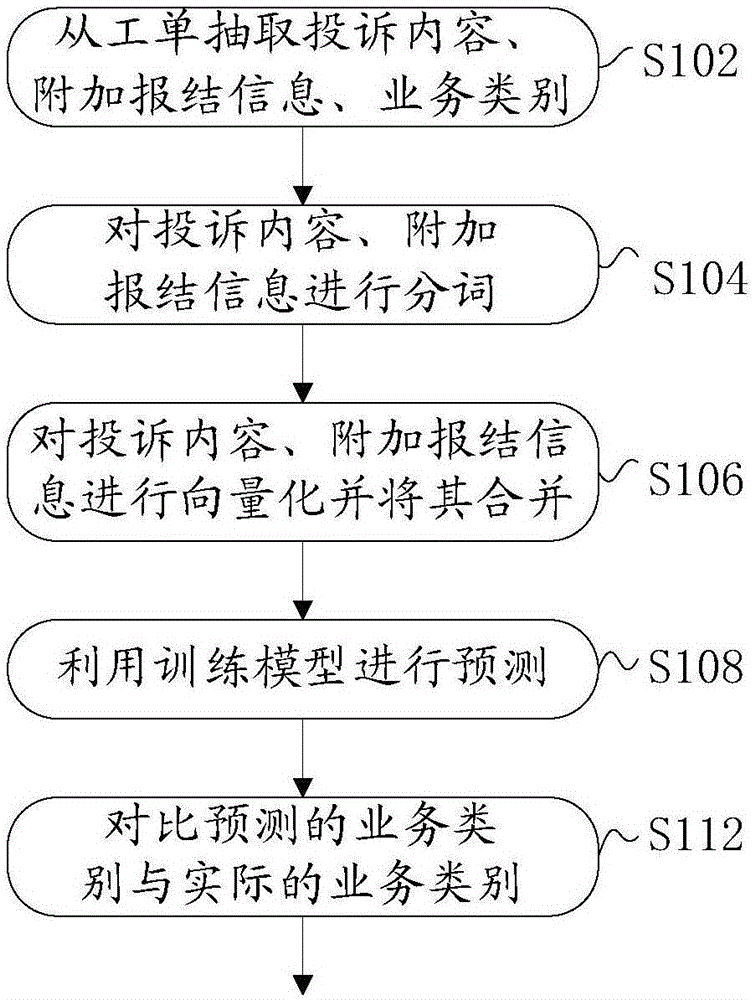
图1是根据本发明实施例的基于业务类别分类模型的工单质检方法示意图。首先,具体介绍业务类别分类模型的训练过程。具体模型训练过程说明如下:
从历史工单中筛选出业务类别正确的工单;
利用人工构造的分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;
利用tfidf分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量;
将向量作为特征、投诉业务类别作为标签,利用svm构建模型并优化。
如图1所示,基于业务类别分类模型的工单质检方法包括如下步骤:
在步骤s102,从待质检工单中抽取出投诉内容、附加报结信息、业务类别三个信息。
在步骤s104,利用人工构造的分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作。
在步骤s106,利用tfidf分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量。
在步骤s108,基于tfidf向量,利用训练后的svm模型进行预测,获取预测结果。
在步骤s112,将预测结果与实际的业务类别进行对比,如果一致则返回正确,不一致则返回预测的业务类别。
图2是根据本发明实施例的基于解决情况分类模型的工单质检方法示意图。首先,对解决情况分类模型的具体模型训练过程说明如下:
从历史工单中筛选出解决情况正确的工单;
利用人工构造的分词词典、停用词词典对附加报结信息进行分词,去除停用词操作;
利用tfidf分别对分词后的附加报结信息进行向量化;
将向量作为特征、解决情况作为标签,利用svm构建模型并优化。
如图2所示,基于解决情况分类模型的工单质检方法包括如下步骤:
在步骤s202,从待质检工单中抽取出附加报结信息、解决情况这两个信息。
在步骤s204,利用人工构造的分词词典、停用词词典对附加报结信息进行分词,去除停用词操作;
在步骤s206,利用tfidf分别对分词后的附加报结信息进行向量化;
在步骤s208,基于tfidf向量,利用训练后的svm模型进行预测,获取预测结果。
在步骤s212,将预测结果与实际的解决情况进行对比,如果一致则返回正确,不一致则返回预测的解决情况。
图3是根据本发明实施例的基于报结意见分类模型的工单质检方法示意图。首先,对报结意见分类模型的具体模型训练过程说明如下:
从历史工单中筛选出报结意见正确的工单,再取集中小区状态表的数据。
利用人工构造的分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作。
利用tfidf分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量。
利用莱温斯坦算法对投诉工单中的故障地址与基站小区状态表中的地址做模糊匹配,获取故障地址是否已知弱覆盖信息以及场景信息(乡村、城镇等),将弱覆盖信息与场景信息转化为onehot向量并与tfidf的向量结果合并。
将上一步生成的向量作为特征、报结意见作为标签,利用svm构建模型并优化。
如图3所示,基于报结意见分类模型的工单质检方法包括如下步骤:
在步骤s302,从待质检工单中抽取出投诉内容、附加报结信息、报结意见三个信息,以及基站小区状态表的数据。
在步骤s304,利用人工构造的分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作。
在步骤s306,利用tfidf分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量。
在步骤s308,利用莱温斯坦算法对投诉工单中的故障地址与基站小区状态表中的地址做模糊匹配,获取故障地址是否已知弱覆盖信息以及场景信息(乡村、城镇等),将弱覆盖信息与场景信息转化为onehot向量并与tfidf的向量结果合并。当然,向量合并也可以采取一步完成。
在步骤s310,基于上一步生成的向量,利用训练后的svm模型进行预测,获取预测结果。
在步骤s312,将预测结果与实际的报结意见进行对比,如果一致则返回正确,不一致则返回预测的报结意见。
在一个例子中,可以将三个质检均返回正确的工单认为是质检通过工单,其余工单则需人工再次确认。
图4示意了根据本说明书实施例的可用于实现上述各种技术的设备的详细结构图。该结构图示意了可实现图1-3所示方法流程的硬件基础。如图4所示,设备可包括处理器402,该处理器用于控制设备的总体操作的微处理器或控制器411。数据总线415可用于在存储装置440、处理器402和控制器417等之间进行数据传输。控制器511可用于通过设备控制总线417与不同设备进行交互并对其进行控制。设备还可包括耦接至数据链路412的网络/总线接口414。在无线连接的情况下,网络/总线接口414可包括无线收发器。
设备还包括存储装置440。该存储装置存储有软件;在运行时,软件自ram440中加载于ram420中,并且由此控制处理器402执行相应操作。
在一个例子中,操作包括:从待质检工单中抽取出投诉内容、附加报结信息、业务类别三个信息;利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量;基于向量,利用训练模型进行预测,获取预测的业务类别;其中,训练模型是利用业务类别正确的历史工单训练得到;将预测的业务类别与从工单抽取的业务类别进行对比,如果一致则认定该工单的投诉内容、附加报结信息与业务类别一致。
在另一个例子中,操作包括:从待质检工单中抽取出附加报结信息、解决情况这两个信息;利用分词词典、停用词词典对附加报结信息进行分词,去除停用词操作;分别对分词后的附加报结信息进行向量化;基于向量,利用训练模型进行预测,获取预测的解决情况;其中,训练模型是利用解决情况正确的历史工单训练得到;将预测的解决情况与从工单抽取的解决情况进行对比,如果一致则认定附加报结信息和解决情况一致。
在再一个例子中,操作包括:从待质检工单中抽取出投诉内容、附加报结信息、报结意见三个信息,以及基站小区状态表的数据;利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为第一向量;对工单中的故障地址与基站小区状态表中的地址做模糊匹配,获取故障地址是否已知弱覆盖信息以及场景信息,将弱覆盖信息与场景信息转化为第二向量并与第一向量合并为第三向量;基于上述合并后的第三向量,利用训练模型进行预测,获取预测的报结意见;其中,训练模型是利用报结意见正确的历史工单训练得到;将预测的报结意见与从工单抽取的报结意见进行对比,如果一致则返回投诉内容、附加报结信息和报结意见一致。
应当理解,这里描述的设备在很多方面可以利用前面描述的方法实施例或与之结合。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本说明书各实施例所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。根据另一方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行结合图1-图3所描述的方法。
图5-图7示意了本说明书各实施例所描述的功能采用硬件、固件或者其组合或者与软件组合时的一些可能的方案。
具体地,图5是基于业务类别分类模型的工单质检装置的示意图,该工单质检装置包括:抽取单元502,从待质检工单中抽取出投诉内容、附加报结信息、业务类别三个信息;分词单元504,利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;向量化单元506,分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为一个向量;预测单元508,基于向量,利用训练模型进行预测,获取预测的业务类别;其中,训练模型是利用业务类别正确的历史工单训练得到;对比单元510,将预测的业务类别与从工单抽取的业务类别进行对比,如果一致则认定该工单的投诉内容、附加报结信息与业务类别一致。
图6是基于解决情况分类模型的工单质检装置的示意图,该工单质检装置包括:抽取单元602,从待质检工单中抽取出附加报结信息、解决情况这两个信息;分词单元604,利用分词词典、停用词词典对附加报结信息进行分词,去除停用词操作;向量化单606元,分别对分词后的附加报结信息进行向量化;预测单元608,基于向量,利用训练模型进行预测,获取预测的解决情况;其中,训练模型是利用解决情况正确的历史工单训练得到;对比单元610,将预测的解决情况与从工单抽取的解决情况进行对比,如果一致则认定附加报结信息和解决情况一致。
图7是基于报结意见分类模型的工单质检装置的示意图,该工单质检装置包括:抽取单元702,从待质检工单中抽取出投诉内容、附加报结信息、报结意见三个信息,以及基站小区状态表的数据;分词单元704,利用分词词典、停用词词典对投诉内容、附加报结信息进行分词,去除停用词操作;向量化单元706,分别对分词后的投诉内容、附加报结信息进行向量化并将其合并为第一向量;弱覆盖信息与场景信息向量化单元和合并单元708,对工单中的故障地址与基站小区状态表中的地址做模糊匹配,获取故障地址是否已知弱覆盖信息以及场景信息,将弱覆盖信息与场景信息转化为onehot向量,即第二向量并与第一向量合并成为第三向量;预测单元710,基于上述第三向量,利用训练模型进行预测,获取预测的报结意见;其中,训练模型是利用报结意见正确的历史工单训练得到;对比单元712,将预测的报结意见与从工单抽取的报结意见进行对比,如果一致则返回投诉内容、附加报结信息和报结意见一致。
应当理解,这里描述的多声道响度均衡设备在很多方面可以利用前面描述的方法实施例或与之结合。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
虽然上文结合tfidf和svm算法对本发明的实施例做了说明,但是,很显然,除tfidf以外的其它统计方法,以及除svm算法的其它分类方法也是可行的。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!