一种用于信用预测评估的信用评分卡自动化分箱方法与流程
本发明涉及一种用于信用预测评估的信用评分卡自动化分箱方法。
背景技术:
随着大数据和机器学习技术在金融业的应用,普惠金融获得了较快的发展。传统的金融机构,大多青睐国有企业、大型企业和高净值人群,主要服务“三高”群体,即高学历、高收入、高稳定性。数量更多的“蓝领”人群难以享受银行的金融服务,而这一群体有着巨大的需求和消费潜力。导致这一现象的主要原因在于,银行难以评估这部分客户的风险,客户成本过高,收益难以覆盖成本。银行对小额信贷进行逐一审批的成本与大额贷款相差无几,而收益悬殊,因此不得不放弃这部分业务。大数据和机器学习带来的技术突破,使客户分类和批量化处理成为可能,从而产生规模效应,降低单个客户的平均成本,使得大规模的小额收益能够覆盖成本,从而推动了普惠金融的发展。
对普惠金融来说,主要的风险类型是信用风险,又称违约风险,是指借款人不能履约所造成的损失,主要有两方面的原因,一是借款人没有足够的还款能力,一是借款人无还款意愿。对信用风险进行提前识别和预警,是风险控制的目标。普惠金融业务面对的客户数量庞大,需要处理的业务请求非常巨大,无法依靠人工进行逐一辨别,标准化和自动化是必然选择。大数据、云计算、机器学习等前沿技术的发展、通过构建风控模型,对申请者的信用进行自动化评估,对普惠金融的发展有着重要的意义。
当前金融机构的信用评估模型,主要采用评分卡的方式,涉及到数据分箱,数据分箱通常采用等频分箱、等距分箱方式。
等频分箱:区间的边界值要经过选择,使得每个区间包含大致相等的实例数量。如果分箱数量为10,每个区间应该包含大约10%的实例。
等距分箱:从最小值到最大值之间,均分为n等份,这样,如果a为最小值,b为最大值,则每个区间的长度为w=(b−a)/n,区间边界值为a+w,a+2*w,……,a+(n−1)*w。这里只考虑区域的边界,每个等份里面的实例数量可能不等。
卡方分箱:它依赖于卡方检验,将具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
等频分箱和等距分箱的不足之处在于:忽略了实例所属的类型,落在正确区间里的偶然性很大。分箱数量主要靠主观经验,未必是合适的数量。分箱后,每个区间的合理性,缺乏科学的评估和调整。
常规的卡方分箱,分完箱之后,某些箱区间里,正样本或者负样本分布比例极不均匀,极端时,会出现正样本或者负样本的数量直接为0,会影响模型的稳定性和准确性。
技术实现要素:
本发明的发明目的在于提供一种用于信用预测评估的信用评分卡自动化分箱方法,能够有效提高用户预测评估的准确性。
实现本发明目的的技术方案:
一种用于信用预测评估的信用评分卡自动化分箱方法,其特征在于,包括如下步骤:
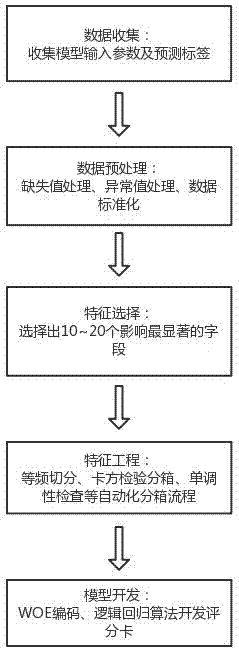
步骤1:收集数据,并对数据进行预处理;
步骤2:特征选择,筛选出对逾期状态影响最显著的数据字段;
步骤3:针对特征变量,进行自动化分箱;
步骤4:根据分箱后的特征变量,进行评分卡评估。
进一步地,步骤3中,自动化分箱通过如下方法实现:
步骤3.1:将数据等频切分为p个区间,设定最大的分箱个数n,n<p,
步骤3.2:计算每一相邻区间的卡方值,公式如下:
其中,aij是第i区间第j类实例的数量,eij是aij的期望值;
步骤3.3:将卡方值最小的一对区间合并;
步骤3.4:统计现存的数据区间数量q,如果q>n,重复步骤3.2至步骤3.3,直至q≤n。
进一步地,步骤3中还包括以下步骤:
步骤3.5:统计每个分箱的坏样本率,计算坏样本率的单调性,如果非单调,重复步骤3.2至步骤3.4,直至单调。
进一步地,步骤3.1中,p为50~200的整数,n≤5。
进一步地,步骤2中,选择的特征个数为10~20个。
进一步地,步骤1中,对数据进行预处理包括数据清洗、缺失值处理、异常值处理。
进一步地,步骤1中,收集数据包括两类数据,一类是模型输入参数,一类是预测标签。
进一步地,所说模型输入参数包括金融数据、运营商数据、互联网数据。
进一步地,所说预测标签为是否逾期的信息。
本发明具有的有益效果:
本发明筛选出对逾期状态影响最显著的数据字段;针对特征变量,进行自动化分箱;根据分箱后的特征变量,再进行评分卡评估。自动化分箱实现方法为,将数据等频切分为p个区间,设定最大的分箱个数n,计算每一相邻区间的卡方值,将卡方值最小的一对区间合并;统计现存的数据区间数量q,如果q>n,重复执行计算,直至q≤n。本发明通过优化自动化分箱方法,有效提高了用户信用预测评估的准确率。本发明提高了评分卡的稳健性:避免了特征中的无意义波动对模型带来的不利影响;增强了模型的泛化能力:增加了模型的适应范围以及在未知数据集上的表现能力;将所有的变量变换到相似的尺度上。
本发明统计每个分箱的坏样本率,计算坏样本率的单调性,如果非单调,重复计算分箱直至单调,进一步保证了用户信用预测评估的准确率。
本发明p为50~200的整数,n≤5,选择的特征个数为10~20个,通过上述参数的选择,进一步保证了用户信用预测评估的准确率。本发明对数据进行预处理包括数据清洗、缺失值处理、异常值处理,其中对缺失值处理,可以将缺失值作为一个独立的箱带入到模型中去,进一步保证了用户信用预测评估的准确率。
附图说明
图1是本发明用于信用预测评估的信用评分卡自动化分箱方法的流程图;
图2是本发明自动化分箱方法的流程图。
具体实施方式
如图1所示,本发明一种用于信用预测评估的信用评分卡自动化分箱方法,其特征在于,包括如下步骤:
步骤1:收集数据,并对数据进行预处理。
根据样本总体的数据情况,比如缺失值情况、异常值情况、平均值、中位数、最大值、最小值、分布情况等,开展数据预处理工作,主要包括数据清洗、缺失值处理、异常值处理,将原始数据转化为可用作模型开发的格式化数据。
收集数据包括两类数据,一类是模型输入参数,一类是预测标签。所说模型输入参数包括金融数据、运营商数据、互联网数据。所说预测标签为是否逾期的信息。
步骤2:特征选择,筛选出对逾期状态影响最显著的数据字段。
选择的特征个数为10~20个。
步骤3:针对特征变量,进行自动化分箱(特征工程)。
如图2所示,自动化分箱通过如下方法实现:
步骤3.1:将数据等频切分为p个区间,设定最大的分箱个数n,n<p。实施时,p为50~200的整数,n≤5。
步骤3.2:计算每一相邻区间的卡方值,公式如下:
其中,aij是第i区间第j类实例的数量,eij是aij的期望值;
步骤3.3:将卡方值最小的一对区间合并;
步骤3.4:统计现存的数据区间数量q,如果q>n,重复步骤3.2至步骤3.3,直至q≤n。
步骤3.5:统计每个分箱的坏样本率,计算坏样本率的单调性,如果非单调,重复步骤3.2至步骤3.4,直至单调。
步骤4:根据分箱后的特征变量,进行评分卡评估。
对分箱后的变量进行woe编码,使用逻辑回归算法开发评分卡模型。
- 还没有人留言评论。精彩留言会获得点赞!