一种基于Spark框架的增量式频繁项集挖掘方法与流程
本发明涉及一种基于spark框架的增量式频繁项集挖掘方法。
背景技术:
在大数据时代,数据不再是社会产生的“副产物”,而是可以被二次乃至多次加工的原材料,从中可以探索更大的价值,将其变成生产资料。挖掘大数据的价值类似沙里淘金,从海量数据中挖掘稀有但珍贵的信息是大数据的一个典型特征。目前,各行各业都在利用数据产生的商业价值改变着我们的生活。因此,如何快速准确地从海量数据中获取所需要的信息成为新的研究问题。
数据挖掘即是一种专门研究如何快速高效的从海量数据中发现知识的新兴技术,而频繁项集挖掘是数据挖掘最受关注的领域之一。随着数据集的大小增加,频繁项级算法的效率大大小下降。因此,处理大型数据集,需要引入并行算法来提高算法的处理效率。另外频繁项集挖掘的时效性在处理动态变化的数据集时也尤为重要。随着应用的不断丰富,数据利用的目的更加多元化,频繁项集挖掘apriori算法需要处理的数据不再是静态不变的,而是动态的、不断更新的数据集,如天猫超市的购物记录,银行的交易记录等。每当数据发生改变时,若仍然采用传统的apriori算法反复地处理全量数据集,则每次处理都将会导致大量的运算资源浪费和性能损失。因此,在面对大规模动态数据集时,如何提高apriori算法的性能成为本课题的重点研究问题。
大数据处理涉及的关键技术有海量数据存储与实时处理。在hadoop的体系结构中,mapreduce作为并行编程模型已经成为用于海量数据处理的强大工具。但hadoop的中间数据不能缓存在内存中,使得对于重复使用的数据集需要频繁i/o,因此对于高迭代计算效率较低。很多机器学习算法比如k-means聚类算法和逻辑回归算法都需要对数据进行迭代计算,针对mapreduce中出现的各种不足,伯克利大学推出了全新的统一大数据处理框架apachespark,它创新性的提出了rdd概念(一种新的抽象的弹性数据集)。spark允许将数据缓存在内存中,并应用于多次迭代计算,因此,spark更适合迭代运算较多的机器学习或数据挖掘算法。
技术实现要素:
本发明提出了一种基于spark框架的增量式频繁项集挖掘方法,首先实现一种基于spark的自适应并行apriori算法,使用自适应算法来寻找具有更高精度和效率的频繁模式,在每次迭代之前制定执行计划,采用最合适的计划来最小化时间和空间复杂性。接着,在并行apriori算法的基础上,提出一种增量式apriori算法,利用已有的计算结果,根据新增加的数据对频繁项集进行修改,避免了反复地处理全量数据集。
相关定义:
(1)项目集(项集)
一个项集由多个互不相同的项目(项)组成。项集用t表示,可记作t={i1,i2….,ik},其中ix(x为[1,k]之间的整数])为出现在项集t中的一个项。在t={i1,i2….,ik}中,共有k个项,即|t|=k,因此又称这个t为k元项集。
(2)事务(交易记录)
一个与项集相似的概念,交易记录是一个项集,因此可表示为t={i1,i2….,ik}。交易记录又区别于项集,交易记录是输入数据中实际出现的数据,而项集是多个项目之间任意的数学组合,与是否出现在输入数据中无关。
(3)输入数据集
输入数据表示问题中实际出现的所有交易记录,记作aprioridb={t1,t2….,td}。其中ti为一条实际的交易记录,d表示数据集包含的交易记录总量。
(4)支持度
support(x–>y)=|x交y|/n=集合x与y中的项在一条记录中同时出现的次数/数据记录的次数为支持度。而最小支持度是给定的阈值,表示为min_sup(0<min_sup<1)。
(5)频繁项集
输入数据集表示为db,其交易记录数量为d。db中的项集t的计数记为count(t,db),db中的t的支持度记为sup(t,db)=count(t,db)/d。如果db中的一个项集t的支持度大于或等于频繁项集的最小支持度,则该项集t是一个频繁项集,类似于项集的定义,对于|t|=k的频繁项集,称t为k元频繁项集记作lk。
(6)候选项集
所有k-1元频繁项集通过取并集操作,生成k元候选项集(candidateitemset),该候选项集的记作ck。
(7)分布式文件系统(hdfs)
hdfs即hadoop分布式文件系统(hadoopdistributedfilesystem),以流式数据访问模式来存储超大文件,运行于商用硬件集群上,是管理网络中跨多台计算机存储的文件系统。
(8)hdfs数据块(block)
hdfs上的文件被划分为块大小的多个分块,作为独立的存储单元,称为数据块,默认大小是64mb。
(9)弹性分布式数据集(rdd)
rdd是spark中一个容错的、并行的数据结构,可以根据用户的要求将数据存储到磁盘和内存中,并且能根据用户的设定设置分区数量。不仅如此,rdd还提供了一组丰富的操作来操作数据集。
(10)工作(job)
一个job对应一个工作任务,它包含了很多的task,每一个task是一个能单独运行的线程。
(11)任务(task)
被driver端送到worker端上的executor上的工作单元,一个task通常会处理一个数据分片。
一种基于spark框架的增量式频繁项集挖掘方法,包括以下几个步骤:
步骤1:获取原始数据集aprioridb的初始一元频繁项集;
依据设定的频繁项集最小支持度,计算原始数据集aprioridb中每个项的支持度,将大于或等于设定的频繁项集最小支持度的项作为初始一元频繁项集;
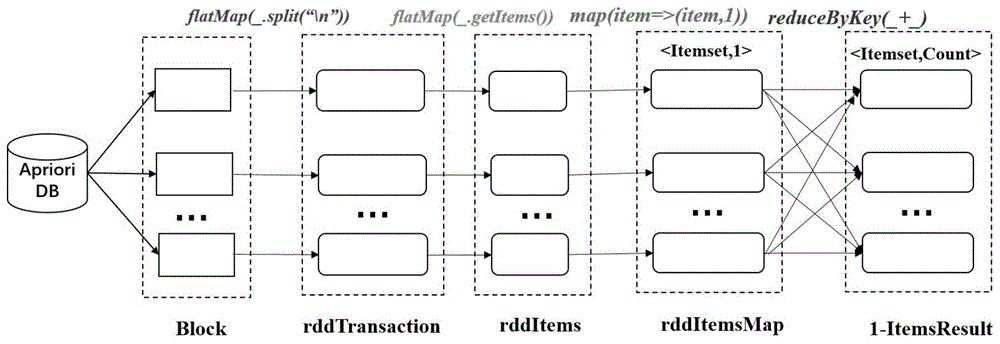
首先,利用flatmap()函数来读取输入的原始数据集中的所有事务,并将所有事务放入事务rdd(事务rdd命名为rddtransaction,rdd是是spark中一个容错的、并行的数据结构,全称为弹性分布式数据集)中;其次,利用flatmap()函数依次从事务rdd中读取每个事务中包含的项;接着,利用map()函数将所有的项转换为<item,1>键/值对(通过键值对中的“值”来计算每个项的支持度);最后,利用reducebykey()函数计算每个项的支持度,并与设定的频繁项集最小支持度进行比较,得到一元频繁项集;
步骤2:利用k-1元频繁项集lk-1迭代生成k元频繁项集lk;
步骤3:按照步骤1-2所述方法,提取新增数据集aprioridb的频繁项集和对应的支持度,aprioridb的频繁项集及其支持度结果记为f;
步骤4:运行任务taskfread读取原始数据集aprioridb的频繁项集及对应的支持度,aprioridb的频繁项集及其支持度结果记为f;
步骤5:运行任务taskclassify读取并合并f和f,依据支持度的合并结果,将所有的频繁项集进行分类,得到三种不同类型的项集,分别是:项集f∩f、项集f-f、f-f;同时运行任务taskdbread和taskdbread读取原始数据集aprioridb和新增数据集aprioridb;
其中,项集f∩f是指两者的交集,且f∩f中项集的支持度在aprioridb和aprioridb中必定是大于或等于设定的频繁项集最小支持度;
项集f-f是指从f中去除f中存在的项集,需要扫描aprioridb,并计算f-f中每一个项集在aprioridb中的支持度;
项集f-f是指从f中去除f中存在的项集,需要扫描aprioridb,计算f-f中每一个项集在aprioridb中的支持度;
步骤6:同时运行三个不同的任务,分别读取并更新项集f∩f、项集f-f、项集f-f中的每个项集的支持度;
其中,项集f∩f中的所有频繁项集记为directf;
项集f-f中的每个项集通过扫描aprioridb计算各项集在整个数据集中的最终支持度;再筛选出支持度小于min_sup×(d×d)的项集,获得所有频繁项集scan_dbf;
项集f-f中的每个项集扫描aprioridb计算各项集在整个数据集中的最终支持度;再过滤出支持度少于min_sup×(d×d)的项集,获得所有频繁项集果scan_dbf;
步骤7:运行任务taskunion合并频繁项集结果directf,scan_dbf和scan_dbf以得到最终的频繁项集结果f′。
在步骤2中依据数据处理的时间复杂度,为每次迭代选择不同的计算方法;
其中,m为频繁项集的数量;b为每个事务中的平均项目数;p为map任务的数量;y为事务的数量;i:迭代的次数;
若上式成立,则选择方法1,否则,选择方法2;
方法1:输入文件为存储在hdfs上的数据集aprioridb和存储在bloom过滤器中的上一次迭代后得到的k元频繁项集lk;
首先,map任务接收事务并修剪事务,使它只包含存在bloom过滤器的项;然后,map任务为被修剪的事务生成相应的<key,value>对;随后,reduce任务利用reducebykey()组合所有<key,value>对;
方法2:输入文件为存储在hdfs上的数据集aprioridb和存储在hashtree中的通过lk-1生成的候选项集ck;
首先,map任务接收事务,并且找到每个事务的k项集并生成相应的<key,value>对;随后,reduce任务利用reducebykey()组合所有<key,value>对。
常规的方法需要生成候选集ck并使用hashtree存储。简化的方法不需要并集操作(也就是不需要生成候选集ck,用不到侯选集ck),直接使用bloom过滤器存储频繁项集。常规方法是通过lk-1生成候选项集(ck)并使用hashtree存储ck。简化方法是通过去除ck的生成和使用bloom过滤器存储lk-1来改进迭代的性能。
有益效果
本发明提供了一种基于spark框架的增量式频繁项集挖掘方法,首先实现一种基于spark的自适应并行apriori算法,使用自适应算法来寻找具有更高精度和效率的频繁模式,可以有效解决传统apriori算法在面对大规模数据时处理能力不足的问题。。接着,在并行apriori算法的基础上实现增量式apriori算法,通过高效利用历史频繁项集结果,结合新增数据计算的结果,最后得到全量数据的频繁项集,有效地避免了历史数据重复计算,从而提高了aprior算法的时间性能。
本发明在解决apriori频繁项集挖掘方法在面对大规模数据性能瓶颈问题同时,还提高了apriori频繁项集挖掘方法在处理动态变化的数据集时的时效性。
附图说明
图1为本发明所述方法并行apriori算法第一阶段rdds的lineage图;
图2为本发明所述方法并行apriori算法第二阶段计算二元频繁项集的示例图;
图3为本发明所述方法增量式apriori算法的基本流程图。
具体实施方式
下面将结合附图和实施例对本发明做进一步地说明。
本发明所述方法的优选实例包括两个部分,具体如下:
1、在spark上实现并行apriori算法
记原始输入数据集为aprioridb,其交易记录数量为d,频繁项集及其支持度结果记为f。aprioridb中的项集t的计数记为count(t,aprioridb),aprioridb中的项集t的支持度记为
并行apriori算法基于sparkrdd模型,工作流程主要包含两个阶段:第一阶段生成一元频繁项集(l1);第二阶段使用k-1元频繁项集(lk-1)迭代生成k元频繁项集(lk),并且将计算方法分为常规方法和简化方法。常规方法是通过lk-1生成候选项集(ck)并使用hashtree存储ck。简化方法是通过去除ck的生成和使用bloom过滤器存储lk-1来改进迭代的性能。
1.1第一阶段
将原始输入数据集aprioridb上传到文件系统hdfs中,并划分为n个等大的block,每个block中包含部分互相没有交集的用户交易记录(事务),第j块数据记为blockj。通过客户端向spark集群提交job,将hdfs中的block加载到sparkrdd中。将aprioridb广播到所有执行任务的节点,使得子任务执行时,直接从本地获取该数据。
如图1所示,首先,在aprioridb上应用flatmap()函数来读取所有事务,并将它们放入事务rdd(rddtransaction)。然后在每个事务中应用flatmap()函数从中获取所有的项(命名为rdditems)。当flatmap过程完成后,map()函数将所有项转换为<item,1>键/值对(命名为rdditemsmap)。最后,reducebykey()函数开始计算每个项的支持度,并修剪支持度小于最小支持度的项,所有高于阈值的项都将属一元频繁项集(命名为i-itemsresult)。
1.2第二阶段
在第二阶段,迭代开始之前,首先,并行apriori算法通过自适应算法为每次迭代制定执行计划,来计算每个计划的执行成本,然后为本次迭代选择最佳计算方法。计算每个执行计划的成本有一些开销,但是当处理大型数据集时,这个开销可以忽略不计。自适应算法详见1.3节。
如果常规方法的时间复杂度大于简化方法的时间复杂度,第二阶段则选择执行简化方法。如示例图2(a)所示,输入文件为存储在hdfs上的aprioridb和存储在bloom过滤器中的l1。第一轮中的map任务接收事务(例如,map-1接收事务t1和t2)并修剪事务,使它只包含存在bloom过滤器的项。例如,事务t1(h,m,s)被映射到修剪事务t1(s,h),然后,map任务为被修剪的事务生成相应的<key,value>对。例如,修剪事务t1(s,h)被转换为<sh,1>。随后,reduce任务利用reducebykey()组合所有<key,value>对,并过滤掉小于2的<key,value>对。最后,得到二元频繁项集存储在sparkrdd中。
如果常规方法的时间复杂度小于简化方法的时间复杂度,第二阶段则选择执行常规方法。最初,通过lk-1生成候选项集ck并使用hashtree存储ck。如示例图2(b)所示,输入文件为存储在hdfs上的aprioridb和存储在hashtree中候选项集((sh),(sf),(sz),(hf),(hz),(fz))的。第一轮中的map任务接收事务(例如,map-1接收事务t1和t2),并且找到每个事务的k项集并生成相应的<key,value>对。例如,事务t1(h,m,s)被转换为<sh,1>。随后,reduce任务利用reducebykey()组合所有<key,value>对,并过滤掉小于2的<key,value>对。最后,得到二元频繁项集存储在sparkrdd中。
第二阶段在不断迭代过程中,当没有频繁项集或达到最大迭代限制时,即可停止迭代,得到最终的结果f。可知:
1.3自适应算法
假设有y个事务,p个map任务,在每个事务中平均有b个项,上一次迭代后频繁项集的数量是m个。此外,s是在hashtree中搜索一个项的时间,n是在bloom过滤器中搜索一个项的时间。
对于常规方法,第i次迭代的时间复杂度是生成候选集的时间复杂度和在hashtree中存储候选集的时间复杂度以及map任务处理时间复杂度的总和。
·产生候选集的时间复杂度:
·在hashtree中存储候选集的时间复杂度:
·map任务产生<key,value>对的时间复杂度:
·常规方法的时间复杂度为:
对于简化方法,第i次迭代的时间复杂度是在bloom过滤器中存储频繁项集的时间复杂度和进行修剪事务的时间复杂度以及生成<key,value>对的时间复杂度的总和。
·在bloom过滤器中存储频繁项集的时间复杂度:m;
·修剪事务的时间复杂度:
·在最坏的情况下生成<key,value>对的时间复杂度:
·简化方法的时间复杂度为:
如果常规方法的时间复杂度大于简化方法(常规方法的时间复杂度-简化方法的时间复杂度>0),并行apriori算法的自适应算法将选择执行简化方法。
i、s和n小于10都是常数项,主要小于10,而大数据集的事务数都是以百万计数,因此,它们在复杂性方面的影响几乎可以忽略不计。简化之后的公式为:
上一次迭代的频繁项目集的数量(m)中或候选集合大小(候选集合大小
对于第i次迭代,要使用简化方法,必须满足条件
2、在并行apriori算法的基础上实现增量式apriori算法
记新添加的数据为aprioridb,其交易记录数量为d,频繁项集及其支持度结果记为f。该算法的目的是从原始数据集aprioridb和新添加的数据集aprioridb中查找频繁项集。假设我们已经通过运行并行apriori算法得到并保存了aprioridb上的频繁项集及其支持度,即f。增量式apriori算法过程如图3所示,具体实现步骤如下:
步骤1:利用并行apriori算法处理hdfs上的新增数据集aprioridb,得到频繁项集及其支持度结果f。可知:
步骤2:同时运行任务taskfread以读取原始数据集aprioridb的频繁项集及其支持度结果f。
步骤3:运行任务taskclassify读取并合并f和f,然后分类得到三种不同类型的项集,分别是:项集f∩f、项集f-f、f-f。同时运行任务taskdbread和taskdbread读取原始数据集和新增数据集。项集f∩f中的每个项集在aprioridb和aprioridb中都是频繁项集;项集f-f需要扫描aprioridb,计算f-f中每一个项集在aprioridb中的支持度;项集f-f需要扫描aprioridb,计算f-f中每一个项集在aprioridb中的支持度。在步骤4到步骤6中,我们运行三个任务taskdirect,taskscandb,taskscandb来同时处理这三个项集。
步骤4:运行任务taskdirect来读取项集f∩f,并直接更新每个项集的支持度。然后,任务输出新的频繁项集结果directf。
步骤5:运行任务taskscandb来读取项集f-f,并扫描aprioridb来计算各项集在整个数据集中的最终支持度。该任务筛选出支持度小于min_sup×(d×d)的项集,获得频繁项集结果scan_dbf。
步骤6:运行任务taskscandb来读取项集f-f,并扫描aprioridb来计算各项集在整个数据集中的最终支持度。然后,过滤出支持度少于min_sup×(d×d)的项集,获得频繁项集结果scan_dbf。
步骤7:运行任务taskunion来合并频繁项集结果directf,scan_dbf和scan_dbf以得到最终的频繁项集结果f′。可知:
从式(2.2)f′的定义可知,f′中任意项集t的支持度满足下式(2.3):
count(t,aprioridb∪aprioridb)=count(t,aprioridb)+count(t,aprioridb)≥
min_sup×d+min_sup×d(2.3)
考虑到aprioridb和aprioridb对任意项集t有不同支持度,t的支持度可以表示如下:
·t∈f∩f
count(t,aprioridb)≥d×min_supandcount(t,aprioridb)≥d×min_sup
·
count(t,aprioridb)≥d×min_supandcount(t,aprioridb)<d×min_sup
·
count(t,aprioridb)<d×min_supandcount(t,aprioridb)≥d×min_sup
·
count(t,aprioridb)<d×min_supandcount(t,aprioridb)<d×min_sup
第一种关系,项集t在aprioridb和aprioridb中都是频繁项集,并直接更新项集t的支持度,项集t满足式(2.3)。
第二关系,需要扫描aprioridb,计算f-f中每一个项集在aprioridb中的支持度,以确定它是否是aprioridb∪aprioridb中的频繁项集。
第三关系,需要扫描aprioridb,计算f-f中每一个项集在aprioridb中的支持度,以确定它是否是aprioridb∪aprioridb中的频繁项集。
第四种关系,项集t在aprioridb和aprioridb中的非频繁项集,则计算的过程中不载考虑它们。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!