一种合作协同差分进化方法和装置与流程
本发明涉及高维优化技术领域,尤其涉及一种合作协同差分进化方法和装置。
背景技术:
差分进化算法(differentialevolution,de)是一种基于实数编码的全局优化算法,因其简单、高效以及具有全局并行性等特点,近年来已成功应用到工业设计和工程优化等领域。研究人员对de算法进行了改进和创新并取得了一些成果。比如brest等人构造了控制参数的自适应性方法并提出了自适应de算法(jde)。wang等人提出了复合de算法(code),其将精心选择的三种变异策略和三组控制参数按照随机的方法进行组合。这些研究成果主要集中于低维问题(30维),然而当面向高维问题(1000维)时,这些de算法的性能将急剧下降,而且搜索时间随着维数成指数增长,求解极为困难,“维灾难”问题依然存在。为了有效求解高维优化问题,学者们提出不同的策略,其中具有代表性的是协同进化(cooperativecoevolution,cc)。研究人员已将cc应用到多个领域,如大规模黑盒优化问题、sca问题、fii算法、ccpso算法、dg2算法,然而它们在求解高维优化问题时,采用串行方式求解,因此,问题求解需要较长的计算时间,很难在有效时间内提供满意的解。近年来云计算已应用到大规模信息处理领域中,获得了成功。因此,有必要将云计算的分布式处理能力与cc的优势相结合,为大规模优化问题的求解提供新方法。
但本发明申请人发现上述现有技术至少存在如下技术问题:
现有技术中的算法不能在有效时间内求解高维优化问题,缺少具有优势的为大规模优化问题进行求解的方法的技术问题。
技术实现要素:
本发明实施例提供了一种合作协同差分进化方法和装置,解决了现有技术中的算法不能在有效时间内求解高维优化问题,缺少具有优势的为大规模优化问题进行求解的方法的技术问题。
鉴于上述问题,提出了本发明实施例提供了一种合作协同差分进化方法和装置。
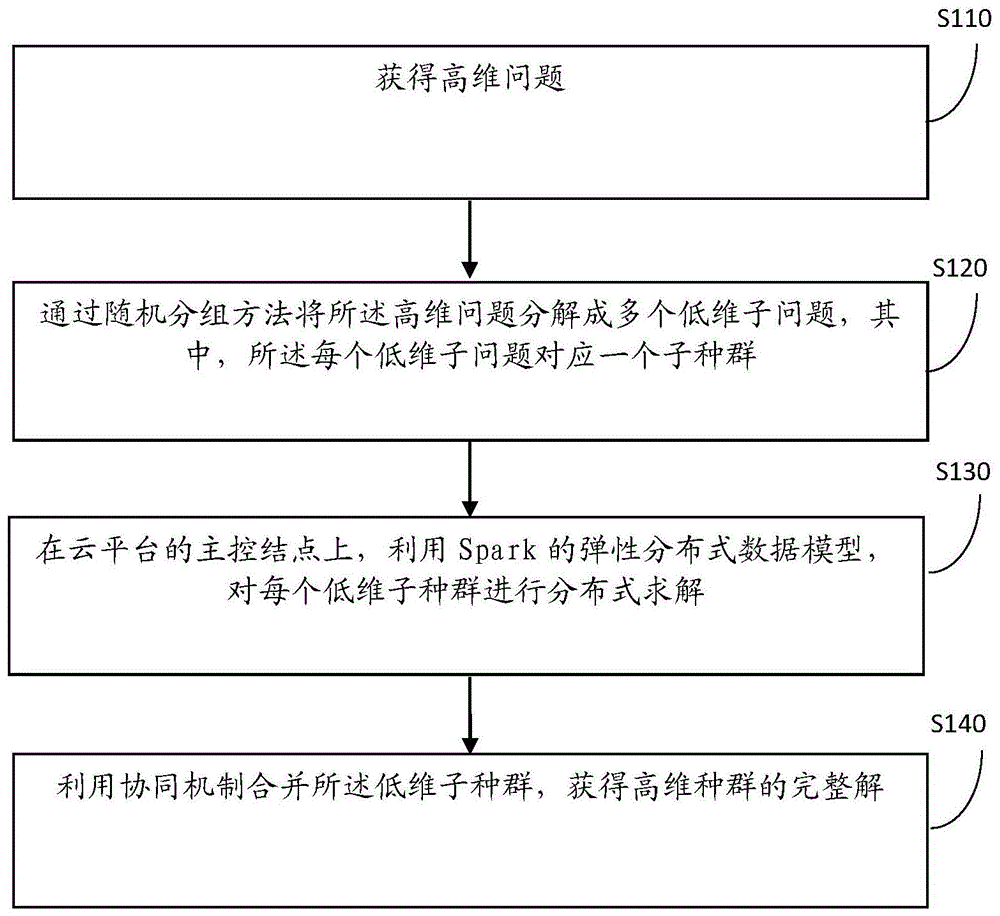
第一方面,本发明提供了一种合作协同差分进化方法,所述方法包括:获得高维问题;通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群;在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解;利用协同机制合并所述低维子种群,获得高维种群的完整解。
优选的,所述在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解,包括:通过parallelize方法对所述子种群进行并行初始化;将并行初始化后的子种群采用“键-值”的方式存放在内存中;根据keyi值将子种群分区保存在不同的主控结点上;利用rdd的并行操作算子对各子种群并行进化。
优选的,所述利用rdd的并行操作算子对各子种群并行进化,包括:每个分区中的子种群并行执行de算法的变异、交叉、选择操作,获得第一轮计算的最优个体;所述子种群在计算个体适应度值时,选取第一轮的最优个体合和所述子种群组成完整的种群并进行局部寻优。
优选的,所述利用协同机制合并所述低维子种群,获得高维种群的完整解,包括:通过collect算子将并行进化后的各子种群合并生成新种群;获得每个所述低维子问题在所述高维问题的位置信息;按照所述位置信息合并成新种群,并通过全局搜索获得高维种群的完整解。
第二方面,本发明提供了一种合作协同差分进化装置,所述装置包括:
第一获得单元,所述第一获得单元用于获得高维问题;
第一求解单元,所述第一求解单元用于在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解;
第二获取单元,所述第四获取单元用于利用协同机制合并所述低维子种群,获得高维种群的完整解。
优选的,所述装置还包括:
第一初始化单元,所述第一初始化单元用于通过parallelize方法对所述子种群进行并行初始化;
第一执行单元,所述第一执行单元用于将并行初始化后的子种群采用“键-值”的方式存放在内存中;
第一保存单元,所述第一保存单元用于根据keyi值将子种群分区保存在不同的主控结点上;
第二执行单元,所述第二执行单元用于利用rdd的并行操作算子对各子种群并行进化。
优选的,所述装置还包括:
第三获得单元,所述第三获得单元用于每个分区中的子种群并行执行de算法的变异、交叉、选择操作,获得第一轮计算的最优个体;
第三执行单元,所述第三执行单元用于所述子种群在计算个体适应度值时,选取第一轮的最优个体合和所述子种群组成完整的种群并进行局部寻优。
优选的,所述装置还包括:
第一合并单元,所述第一合并单元用于通过collect算子将并行进化后的各子种群合并生成新种群;
第四获得单元,所述第四获得单元用于获得每个所述低维子问题在所述高维问题的位置信息;
第四执行单元,所述第四执行单元用于按照所述位置信息合并成新种群,并通过全局搜索获得高维种群的完整解。
第三方面,本发明提供了一种合作协同差分进化装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现以下步骤:获得高维问题;通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群;在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解;利用协同机制合并所述低维子种群,获得高维种群的完整解。
第四方面,本发明提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:获得高维问题;通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群;在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解;利用协同机制合并所述低维子种群,获得高维种群的完整解。
本申请实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
本发明实施例提供的一种合作协同差分进化方法和装置,通过获得高维问题;通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群,利用cc处理高维问题的优势,对高维问题进行降维处理;再将所述子种群放在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解,实现使cc框架结合云处理,利用云处理的并行性对各子问题进行求解,提高了处理速度;最后利用协同机制将得到的所述低维子种群优化个体进行合并,获得高维种群的完整解,从而实现了有效处理高维大规模优化问题,提高求解速度,避免了处理大规模优化问题时求解计算时间过长的问题,从而解决了现有技术中的算法不能在有效时间内求解高维优化问题,缺少具有优势的为大规模优化问题进行求解的方法的技术问题。达到了针对大规模优化问题,利用cc处理高维问题的优势结合云计算分布式计算优势,提出了一种新的基于spark的合作协同差分进化算法sparkdecc算法,提高了cc框架的收敛速度,具有求解精度高,速度快,可扩展性好的技术效果。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其它目的、特征和优点能够更明显易懂,以下特举本发明的具体实施方式。
附图说明
图1为本发明实施例中一种合作协同差分进化方法的流程示意图;
图2为本发明实施例中的spark的de算法的流程示意图;
图3为本发明实施例中的sparkdecc算法流程示意图;
图4-11为本发明实施例中各算法的收敛曲线走势图;
图12-17为本发明实施例中各算法的加速比曲线走势图;
图18为本发明实施例中一种合作协同差分进化装置的结构示意图;
图19为本发明实施例中另一种合作协同差分进化装置的结构示意图。
附图标记说明:第一获得单元11,第一求解单元12,第一求解单元13,第二获得单元14,总线300,接收器301,处理器302,发送器303,存储器304,总线接口306。
具体实施方式
本发明实施例提供了一种合作协同差分进化方法和装置,用于解决现有技术中的算法不能在有效时间内求解高维优化问题,缺少具有优势的为大规模优化问题进行求解的方法的技术问题。
本发明提供的技术方案总体思路如下:
获得高维问题;通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群;在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解;利用协同机制合并所述低维子种群,获得高维种群的完整解。达到了针对大规模优化问题,利用cc处理高维问题的优势结合云计算分布式计算优势,提出了一种新的基于spark的合作协同差分进化算法sparkdecc算法,提高了cc框架的收敛速度,具有求解精度高,速度快,可扩展性好的技术效果。
应理解,本发明实施例中spark为计算引擎,spark是ucberkeleyamplab(加州大学伯克利分校的amp实验室)所开源的类hadoopmapreduce的通用并行框架,spark,拥有hadoopmapreduce所具有的优点;但不同于mapreduce的是——job中间输出结果可以保存在内存中,从而不再需要读写hdfs,因此spark能更好地适用于数据挖掘与机器学习等需要迭代的mapreduce的算法。spark是一种与hadoop相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使spark在某些工作负载方面表现得更加优越,换句话说,spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。spark是在scala语言中实现的,它将scala用作其应用程序框架。与hadoop不同,spark和scala够紧密集成,其中的scala可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建spark是为了支持分布式数据集上的迭代作业,但是实际上它是对hadoop的补充,可以在hadoop文件系统中并行运行。通过名为mesos的第三方集群框架可以支持此行为。spark由加州大学伯克利分校amp实验室(algorithms,machines,andpeoplelab)开发,可用来构建大型的、低延迟的数据分析应用程序。
下面通过附图以及具体实施例对本发明技术方案做详细的说明,应当理解本申请实施例以及实施例中的具体特征是对本申请技术方案的详细的说明,而不是对本申请技术方案的限定,在不冲突的情况下,本申请实施例以及实施例中的技术特征可以相互组合。
本文中术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系,例如,a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。
实施例一
图1为本发明实施例中一种合作协同差分进化方法的流程示意图。如图1-3所示,本发明实施例提供了一种合作协同差分进化方法,所述方法包括:
步骤110:获得高维问题。
步骤120:通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群。
具体而言,由于高维问题求解极为困难,首先需要对高维复杂问题进行降维处理,将高维复杂问题随机分解成多个低维简单的子问题,然后对各个子问题进行求解,即利用协同进化cc采用“分而治之”的思想。
步骤130:在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解。
进一步的,所述在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解,包括:通过parallelize方法对所述子种群进行并行初始化;将并行初始化后的子种群采用“键-值”的方式存放在内存中;根据keyi值将子种群分区保存在不同的主控结点上;利用rdd的并行操作算子对各子种群并行进化。
进一步的,所述利用rdd的并行操作算子对各子种群并行进化,包括:每个分区中的子种群并行执行de算法的变异、交叉、选择操作,获得第一轮计算的最优个体;所述子种群在计算个体适应度值时,选取第一轮的最优个体合和所述子种群组成完整的种群并进行局部寻优。
具体而言,将分解完成的多个低维子问题的求解任务部署到云平台的结点上进行,利用了云平台分布式计算的优势。de是一种基于群体的进化算法,具有内在并行性的特点,因此,de能与spark的并行性充分融合。spark在主控结点通过parallelize方法即并行方法,将种群并行初始化,并采用“键-值”的方式存放在内存中,即:[keyi,valuei],i=1,2,...,m,其中m是子种群的数目,keyi是整数,表示第i个子种群的编号,valuei是第i个子种群。de在spark上的具体实现如图2所示。spark将内存中的数据按“键-值”对的方式抽象成rdd,并根据keyi值将子种群分区保存在不同的结点上。利用rdd的并行操作算子对各子种群并行进化若干代,获得个子种群的最优个解,提高了种群的多样性,同时利用并行算法提高了求解的计算时间,有效解决了现有算法采用串行方式求解,问题求解需要较长的计算时间,很难有效时间内提供满意的解的问题。达到了利用cc框架的优势,由于cc框架处理大规模高维优化问题优势明显,但随着种群规模的增加,cc框架所需时间快速增加,需要将cc的处理速度提高,因而本发明实施例将云计算的优势与cc框架相结合,提高了cc框架的收敛速度。
步骤140:利用协同机制合并所述低维子种群,获得高维种群的完整解。
进一步的,所述利用协同机制合并所述低维子种群,获得高维种群的完整解,包括:通过collect算子将并行进化后的各子种群合并生成新种群;获得每个所述低维子问题在所述高维问题的位置信息;按照所述位置信息合并成新种群,并通过全局搜索获得高维种群的完整解。
具体而言,将云计算的优势与cc框架相结合,提出了基于spark的合作协同进化算法-sparkdecc算法,利用sparkdecc算法的流程图如图3所示。每个分区中的子种群并行执行de算法的变异、交叉、选择等操作后,其中子种群在计算个体适应度值时,选取上一轮的最优个体合作组成完整的种群并进行局部寻优。低维子种群在对应的分区中进化若干代后,再通过collect算子合并生成新的种群。循环结束后通过动作算子reduce获取整个种群的最优值,同时各子种群要按照其位置信息合并成新的完整种群,并通过全局搜索返回最优个体,从而得到了高维复杂问题的优化完整解。达到了针对大规模优化问题,利用cc处理高维问题的优势结合云计算分布式计算优势,提出了一种新的基于spark的合作协同差分进化算法sparkdecc算法,提高了cc框架的收敛速度,具有求解精度高,速度快,可扩展性好的技术效果。
实施例二
为了更好的介绍本发明的一种合作协同差分进化方法的技术特点和用途,下面将结合具体实施例来对本发明的优点进行详细说明,请参考图4-17。
为了测试本发明实施例的算法求解大规模优化问题的性能,选取了13个测试函数进行实验。实验时发明实施例的算法中问题的维度分别为1000和5000,子问题的维度为100,问题规模为100,并分别与当前流行的算法即oxde、code(复合de算法)和jde(自适应de算法)进行比较。四种算法的参数设置一致,各算法独立运行25次,分别取每个算法的平均最优值和标准方差的结果进行对比。为了公平显示每一个采用了wilcoxon秩和检验方法对四种算法的实验结果进行了统计分析,显著性水平为0.05。
sparkdecc与其它三种de算法进行对比,结果表明,sparkdecc在f1,f5,f6,f10,f11,f12,f13共七个函数能快速收敛到最优结果,实验数据优于其它三种算法;sparkdecc算法在f3,f8和f9等三个函数的收敛出现了停滞,实验结果弱于其它算法;在不可分解函数f4上各算法的运行效果相当。
f2要劣于jde,优于oxde和code;带噪声函数f7的实验结果劣于code,优于jde,与oxde相当。函数收敛曲线图主要用来表示算法求解最优值的一种趋势走向,函数曲线下降的越快,收敛性能越好。为了比较四种不同de算法在f1,f3,f5,f6,f9,f10,f11,f13等函数的收敛性能(受篇幅限制,仅选择这8个函数),选取了各算法独立运行20次中的平均收敛数据,收敛曲线图如图3所示。从图4-11各种算法的收敛能力走势图可以看出sparkdecc算法的收敛能力较强,在函数f1,f10,f11上的收敛曲线呈直线下降,收敛性能强;函数f5,f6,f13在进化的前期有很好的收敛速度,但在后期出现了一定程度的局部收敛;函数f3,f9在整个进化过程中处于局部收敛,收敛性能弱,收敛效果要劣于其它算法。
加速比是衡量算法并行性的有效指标,其定义公式为:
通过上述实现数据可见,针对大规模优化问题,本发明实施例的sparkdecc算法结合cc和云计算分布式计算优势,提出了一种新的基于spark的合作协同差分进化算法。为了充分利用云计算分布式处理优势,sparkdecc采用分治思想,首先通过随机分组方法将高维优化问题分解成多个低维子问题,并将子问题的优化求解任务部署到云平台的结点上;利用spark的弹性分布式数据模型,对每个子问题分布式求解;最后利用协同机制得到高维问题的完整解。用1000维的优化问题,实验研究了sparkdecc的性能以及影响其性能的各个因素。
所述sparkdecc算法按随机分组策略将高维问题分解成多个同维的低维子问题,将每个子问题与rdd模型中的分区一一对应,每个子问题并行执行de算法,子问题独立进化若干代后,更新最优个体,提高种群的多样性。利用scala语言在spark云模型上实现了sparkdecc,通过13个标准测试函数的对比实验,结果表明sparkdecc求解精度高,速度快,可扩展性好。此外,选择6个测试函数进行加速比实验,实验结果表明加速比与分区数量几乎是线性的,加速效果良好。
以上所述仅为本发明的实例而已,并不能用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明保护的范围内。
实施例三
基于与前述实施例中一种合作协同差分进化方法同样的发明构思,本发明提供了一种合作协同差分进化装置,如图18所示,所述装置包括:
第一获得单元11,所述第一获得单元11用于获得高维问题;
第一求解单元12,所述第一求解单元12用于通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群;
第一求解单元13,所述第一求解单元13用于在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解;
第二获取单元14,所述第四获取单元14用于利用协同机制合并所述低维子种群,获得高维种群的完整解。
进一步的,所述装置还包括:
第一初始化单元,所述第一初始化单元用于通过parallelize方法对所述子种群进行并行初始化;
第一执行单元,所述第一执行单元用于将并行初始化后的子种群采用“键-值”的方式存放在内存中;
第一保存单元,所述第一保存单元用于根据keyi值将子种群分区保存在不同的主控结点上;
第二执行单元,所述第二执行单元用于利用rdd的并行操作算子对各子种群并行进化。
进一步的,所述装置还包括:
第三获得单元,所述第三获得单元用于每个分区中的子种群并行执行de算法的变异、交叉、选择操作,获得第一轮计算的最优个体;
第三执行单元,所述第三执行单元用于所述子种群在计算个体适应度值时,选取第一轮的最优个体合和所述子种群组成完整的种群并进行局部寻优。
进一步的,所述装置还包括:
第一合并单元,所述第一合并单元用于通过collect算子将并行进化后的各子种群合并生成新种群;
第四获得单元,所述第四获得单元用于获得每个所述低维子问题在所述高维问题的位置信息;
第四执行单元,所述第四执行单元用于按照所述位置信息合并成新种群,并通过全局搜索获得高维种群的完整解。
前述图1实施例一中的一种合作协同差分进化方法的各种变化方式和具体实例同样适用于本实施例的一种合作协同差分进化装置,通过前述对一种合作协同差分进化方法的详细描述,本领域技术人员可以清楚的知道本实施例中一种合作协同差分进化装置的实施方法,所以为了说明书的简洁,在此不再详述。
实施例四
基于与前述实施例中一种合作协同差分进化方法同样的发明构思,本发明还提供一种合作协同差分进化装置,其上存储有计算机程序,该程序被处理器执行时实现前文所述一种合作协同差分进化方法的任一方法的步骤。
其中,在图19中,总线架构(用总线300来代表),总线300可以包括任意数量的互联的总线和桥,总线300将包括由处理器302代表的一个或多个处理器和存储器304代表的存储器的各种电路链接在一起。总线300还可以将诸如外围设备、稳压器和功率管理电路等之类的各种其他电路链接在一起,这些都是本领域所公知的,因此,本文不再对其进行进一步描述。总线接口306在总线300和接收器301和发送器303之间提供接口。接收器301和发送器303可以是同一个元件,即收发机,提供用于在传输介质上与各种其他装置通信的单元。
处理器302负责管理总线300和通常的处理,而存储器304可以被用于存储处理器302在执行操作时所使用的数据。
实施例五
基于与前述实施例中一种合作协同差分进化方法同样的发明构思,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现以下步骤:
获得高维问题;通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群;在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解;利用协同机制合并所述低维子种群,获得高维种群的完整解。
在具体实施过程中,该程序被处理器执行时,还可以实现实施例一中的任一方法步骤。
本申请实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
本发明实施例提供的一种合作协同差分进化方法和装置,通过获得高维问题;通过随机分组方法将所述高维问题分解成多个低维子问题,其中,所述每个低维子问题对应一个子种群,利用cc处理高维问题的优势,对高维问题进行降维处理;再将所述子种群放在云平台的主控结点上,利用spark的弹性分布式数据模型,对每个低维子种群进行分布式求解,实现使cc框架结合云处理,利用云处理的并行性对各子问题进行求解,提高了处理速度;最后利用协同机制将得到的所述低维子种群优化个体进行合并,获得高维种群的完整解,从而实现了有效处理高维大规模优化问题,提高求解速度,避免了处理大规模优化问题时求解计算时间过长的问题,从而解决了现有技术中的算法不能在有效时间内求解高维优化问题,缺少具有优势的为大规模优化问题进行求解的方法的技术问题。达到了针对大规模优化问题,利用cc处理高维问题的优势结合云计算分布式计算优势,提出了一种新的基于spark的合作协同差分进化算法sparkdecc算法,提高了cc框架的收敛速度,具有求解精度高,速度快,可扩展性好的技术效果。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!