信息处理装置以及程序的制作方法
本发明涉及一种信息处理装置以及程序。
背景技术:
历来已知,通过对训练数据进行机器学习来生成辨别模型,并利用该辨别模型对辨别对象数据的标签进行辨别的技术。这种技术可利用于,例如,根据机械设备中设置的感应器的感应器数据,来检测该机械设备的异常。
一般而言,在生成辨别模型时,会进行训练数据的预处理(标准化及数据量调整等)。同样,在对辨别对象数据的标签进行辨别时,进行辨别对象数据的预处理。通过对数据进行预处理,能够提高辨别模型本身的辨别精度,以及实际利用辨别模型进行辨别时的辨别精度。
<现有技术文献>
<专利文献>
专利文献1:日本特开2017-174045号公报
技术实现要素:
<本发明要解决的课题>
数据的恰当预处理方法,因数据而异。因此,预处理以及预处理方法的构建,向来由数据科学家等专业人员进行。其结果,辨别模型的生成、辨别对象数据的标签辨别耗费大量的时间劳力。
本发明鉴于上述课题,其目的在于实现数据预处理的自动化。
<解决上述课题的手段>
一实施方式的信息处理装置包括:对位部,以由序列数据构成的基准数据作为基准,对其他序列数据进行对位;对象数据提取部,作为对象数据提取所述其他序列数据中的与所述基准数据对应的部分。
<发明的效果>
根据本发明的各实施方式,能够实现数据预处理的自动化。
附图说明
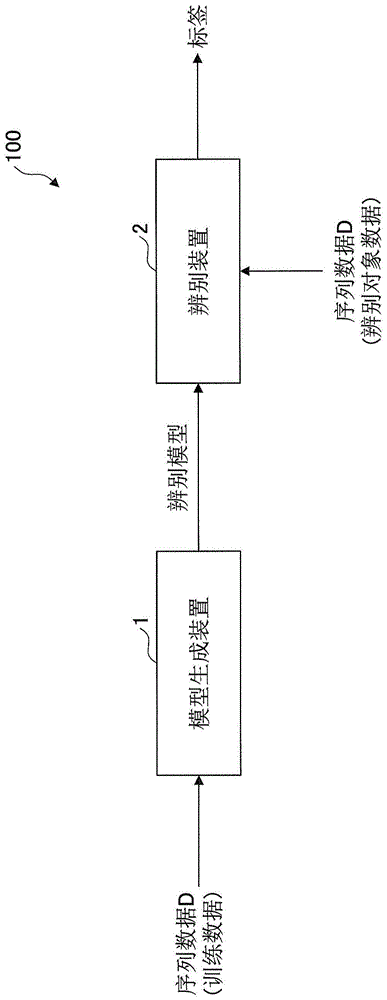
图1是表示辨别系统的概略结构的一例的图。
图2是表示模型生成装置的硬件结构的一例的图。
图3是表示模型生成装置以及辨别装置的功能结构的一例的图。
图4是表示序列数据d的一例的图。
图5是表示对位后的序列数据d的一例的图。
图6是表示从图5的各序列数据d1~d24中提取的对象数据的图。
图7是表示对从图5的序列数据d3(基准数据d0)以及序列数据d4中提取的对象数据进行小波变换的结果的图。
图8是表示模型生成装置的工作的一例的流程图。
图9是表示辨别装置的工作的一例的流程图。
具体实施方式
以下,关于本发明的各实施方式,参照附图进行说明。在此,关于各实施方式所涉及的说明书以及附图的记载内容,对具有实质上相同的功能结构的结构要素,采用相同符号,并省略重复说明。
关于一实施方式的辨别系统100,参照图1~图9进行说明。本实施方式的辨别系统100是通过对训练数据进行机器学习来生成辨别模型,并根据该辨别模型对辨别对象数据的标签进行辨别的系统。
首先,关于辨别系统100的概略结构进行说明。图1是表示辨别系统100的概略结构的一例的图。图1的辨别系统100包括模型生成装置1与辨别装置2。
模型生成装置1是信息处理装置的一个例子,是输入训练数据(添加标签的序列数据d),并根据该训练数据生成用于辨别序列数据d的标签的辨别模型的计算机。模型生成装置1是pc(personalcomputer)、服务器、智能电话、平板终端或微型计算机,但并不限定于这些。序列数据d由包含1个或多个数据的记录(records)按规定顺序排列而成,包括时序数据、被转换成一维排列的图像数据以及文本数据。时序数据包括感应器数据以及语音数据。可对序列数据d添加2种以上的标签。
辨别装置2是信息处理装置的一个例子,是输入辨别对象数据(序列数据d),并利用由模型生成装置1生成的辨别模型来辨别该辨别对象数据的标签的计算机。辨别装置2是pc、服务器、智能电话、平板计算机或微型计算机,但并不限定于这些。对辨别对象数据可添加标签,也可不添加标签。
值得一提的是,在图1的例子中,模型生成装置1以及辨别装置2分别由不同的计算机构成,但也可以由同一个计算机构成。此外,辨别装置2也可以利用与模型生成装置1生成的辨别模型不同的辨别模型,辨别序列数据d的标签。
其次,关于模型生成装置1以及辨别装置2的硬件结构进行说明。图2是表示模型生成装置1的硬件结构的一例的图。图2的模型生成装置1包括cpu(centralprocessingunit)101、rom(readonlymemory)102、ram(randomaccessmemory)103、hdd(harddiskdrive)104、输入装置105、显示装置106、通信界面107以及总线108。
cpu101通过执行程序,来控制模型生成装置1的各构成部分,实现模型生成装置1的功能。
rom102用于存储包含cpu101执行的程序在内的各种数据。
ram103为cpu101提供工作区。
hdd104用于存储包括cpu101执行的程序在内的各种数据。
输入装置105用于向模型生成装置1输入与用户的操作相应的信息。输入装置105包括键盘、鼠标、触摸屏以及硬件按钮。
显示装置106用于显示与用户的操作相应的画面。显示装置106包括液晶显示器、等离子显示器以及有机el(electroluminescence)显示器。
通信界面107通过有线或无线方式将模型生成装置1连接到互联网或lan(localareanetwork)等网络。模型生成装置1可以通过网络与辨别装置2连接。
总线108使cpu101、rom102、ram103、hdd104、输入装置105、显示装置106以及通信界面107彼此连接。
在此,模型生成装置1的硬件结构并不限定于图2的例子。模型生成装置1可以是具备cpu101、rom102以及ram103的任意结构。此外,辨别装置2的硬件结构与模型生成装置1相同,因此省略说明。
接下来,关于模型生成装置1以及辨别装置2的功能结构进行说明。图3是表示模型生成装置1以及辨别装置2的功能结构的一个例子的图。
首先,关于模型生成装置1的功能结构进行说明。图3的模型生成装置1包括序列数据存储部11、基准数据选择部12、对位部13、对象数据提取部14、特征量提取部15以及模型生成部16。序列数据存储部11由rom102、ram103以及hdd104等实现。通过由cpu101执行程序,来实现基准数据选择部12、对位部13、对象数据提取部14、特征量提取部15以及模型生成部16。
序列数据存储部11存储多个添加有标签的序列数据d(训练数据)。各序列数据d分别作为数据文件被保存。序列数据存储部11中存储的各序列数据d的数据量可相同,亦可不同。
图4是表示序列数据d的一个例子的图。图4的序列数据d是加速度感应器的感应器数据,按测定时间的顺序排列了多个记录。各记录包括x轴方向、y轴方向以及z轴方向的3个数据项目的值(数据)。如上所述,序列数据d中可以包含多个数据项目,也可以包含1个数据项目。将图4所示的序列数据d与标签关联起来存储在序列数据存储部11中。
基准数据选择部12从序列数据存储部11所存储的多个序列数据d中选择基准数据d0。基准数据d0是对位部13进行对位时被用作基准的序列数据d。基准数据选择部12可以随机选择基准数据d0,也可以按照某种算法选择基准数据d0。基准数据d0的选择方法为任意方法。
一般而言,作为学习对象的序列数据d包含特征性模式(pattern)。但并不知道序列数据d中的哪个数据项目包含该模式。若是利用不含特征性模式的数据项目进行机器学习,可能无法生成高精度的辨别模型。
对此,如图4例示,在各序列数据d包含多个数据项目的情况下,基准数据选择部12可以从多个数据项目中选择1个或多个数据项目,作为基准数据d0。优选是,基准数据选择部12选择序列数据d中的相似度最高的数据项目、序列数据d中的相似度为阈值以上的1个或多个数据项目,作为基准数据d0。能够通过互相关(cross-correlation)或动态时间规整法(dynamictimewarping)算出相似度。由此,基准数据选择部12能够选择包含特征性模式的可能性较高的数据项目,作为基准数据d0。
值得一提的是,基准数据选择部12在选择基准数据d0之前,还可以对各序列数据d进行标准化(normalization)等的预处理。
对位部13以基准数据选择部12选择的基准数据d0作为基准,对序列数据存储部11中存储的其他序列数据d进行对位。在基准数据选择部12从多个数据项目中选择了1个或多个数据项目作为基准数据d0的情况下,对位部13以基准数据d0作为基准,对其他序列数据d中的、由基准数据选择部12选择的数据项目进行对位。
一般而言,作为学习对象的序列数据d包含特征性模式。然而,包含该模式的位置因序列数据d而异。因此,若是在各序列数据d的起点一致的状态下进行机器学习,由于各序列数据d中的特征性模式的偏位,而会导致无法生成高精度的辨别模型。
对此,对位部13以使各序列数据d中包含的特征性模式的位置与基准数据d0中包含的特征性模式的位置相一致的方式,对各序列数据d进行对位。具体而言,对位部13以提高基准数据d0与其他序列数据d的相似度的方式,以基准数据d0作为基准,使其他序列数据d的起点移动。此时,对位部13可根据需要进行数据的插值(interpolation)及细化(thinning)。可通过互相关或动态时间规整法算出相似度。优选是,对位部13以使基准数据d0与其他序列数据d的相似度成为最大的方式,使其他序列数据d的起点移动。由此,对位部13能够使各序列数据d中的特征性模式的位置与基准数据d0中包含的特征性模式的位置一致。
图5是表示对位后的序列数据d的一个例子的图。图5的例子中,以序列数据d3(基准数据d0)作为基准,对添加有“ok”或“ng”标签的24个序列数据d1~d24进行了对位。从图5可看出,通过使其他序列数据d1、d2、d4~d24相对于基准数据d0进行相对移动,进行了对位。
对象数据提取部14,将对位部13进行对位后的其他序列数据d中的与基准数据d0对应(重复)部分作为对象数据,进行提取。对象数据是在后续处理中作为利用对象的数据。由对象数据提取部14提取的对象数据即相当于在用于生成辨别模型的机器学习中被利用的数据。
此外,对象数据提取部14从各序列数据d提取相同部分,作为对象数据。并且,对象数据提取部14从基准数据d0中,提取与各序列数据d中提取的对象数据相同的部分,作为对象数据。
其结果,作为对象数据,从基准数据d0以及其他序列数据d中分别提取全部序列数据d中重复的部分。全部序列数据d中重复的部分相当于,从对位后的序列数据d中的起点位于最后的序列数据d的起点开始,到对位后的序列数据d中的终点位于最前的序列数据d的终点为止的部分。
例如,在图5的例子中,对位后的序列数据d中的起点位于最后的序列数据d是序列数据d10,对位后的序列数据d中的终点位于最前的序列数据d是序列数据d9。因此,在各序列数据d1~d24中,从序列数据d10的起点至序列数据d9的终点为止的部分(图5中实线圈围部分)被作为对象数据提取。
图6是表示从图5的各序列数据d1~d24中提取的对象数据的图。从图6可看出,对象数据为量相同的数据。对象数据是以特征性模式对位的各序列数据d的重复部分,因此其中包含该模式。后续过程中利用该对象数据进行处理。
如上所述,根据本实施方式,通过基准数据选择部12以及对位部13,能够从序列数据存储部11中存储的、量及特征性模式的位置不齐的多个序列数据d(训练数据)中,自动提取数据量相同且特征性模式位置对齐的多个对象数据。模型生成装置1利用该对象数据生成辨别模型,因此能够生成高精度的辨别模型。
特征量提取部15从对象数据提取部14提取的多个对象数据中,分别提取特征量。特征量提取部15例如能够通过小波变换、快速傅里叶变换、低通滤波器、高通滤波器等方法,提取特征量。特征量的提取方法为任意方法。
图7是表示对从图5的序列数据d3(基准数据d0)以及序列数据d4中提取的对象数据进行小波变换的结果的图。根据图7,可知2个对象数据中包含类似的模式。通过小波变换,能够将这种模式作为特征量提取。
模型生成部16,通过对特征量提取部15提取的多个特征量与添加在提取该特征量的序列数据d的标签之间关系进行机器学习,生成用于辨别序列数据d的标签的辨别模型。具体而言,模型生成部16通过预先准备的多个学习算法,分别生成辨别模型,并通过交叉验证(crossvalidation),计算采用各学习算法生成的辨别模型的辨别精度。然后,模型生成部16将辨别精度最高的辨别模型作为序列数据d的标签的辨别模型输出。由此,能够自动生成辨别精度高的辨别模型。
模型生成部16能够利用随机森林(randomforest)、支持向量机(supportvectormachine)、逻辑回归、深度学习等任意的学习算法。另外,在利用深度学习之类能够提取特征量的学习算法的情况下,模型生成部16可以通过对对象数据提取部14提取的多个对象数据与添加在提取该特征量的序列数据d的标签之间的关系进行机器学习,生成用于辨别序列数据d的标签的辨别模型。此种情况下不需要特征量提取部15。另外,模型生成部16可以并用根据特征量生成辨别模型的学习算法和根据对象数据生成辨别模型的学习算法。
其次,关于辨别装置2的功能结构进行说明。图3的辨别装置2包括序列数据存储部21、辨别模型存储部22、对位部23、对象数据提取部24、特征量提取部25以及辨别部26。序列数据存储部21以及辨别模型存储部22由辨别装置2的rom、ram以及hdd等实现。通过由辨别装置2的cpu执行程序,来实现对位部23、对象数据提取部24、特征量提取部25以及辨别部26。
序列数据存储部21存储1个或多个序列数据d(辨别对象数据)。各序列数据d分别作为数据文件被保存。序列数据存储部21中存储的各序列数据d的数据量可相同,亦可不同。另外,序列数据d中可以包含多个数据项目,也可以包含1个数据项目。另外,可以对序列数据d添加标签,也可以不添加标签。通过将无标签的序列数据d利用为辨别对象数据,能够对标签未知的序列数据d的标签进行辨别。此外,通过将有标签的序列数据d利用为辨别对象数据,能够验证辨别模型的辨别精度。
辨别模型存储部22存储用于辨别序列数据d的标签的辨别模型。辨别模型存储部22中可以存储由模型生成装置1生成的辨别模型,也可以存储与模型生成装置1生成的辨别模型不同的辨别模型。
此外,辨别模型存储部22存储基准数据d0。基准数据d0是对位部23进行对位时作为基准的序列数据d。基准数据d0包含特征性模式,并且优选是与特征性模式无关的部分较少(数据量较小)的序列数据d。因此,辨别模型存储部22中,作为基准数据d0,优选存储由对象数据提取部14从基准数据d0提取的对象数据。值得一提的是,辨别模型存储部22中,作为基准数据d0,也可以存储由对象数据提取部14从其他序列数据d提取的对象数据,也可以存储序列数据存储部11中存储的任意序列数据d。
对位部23,以辨别模型存储部22中存储的基准数据d0作为基准,对序列数据存储部21中存储的序列数据d进行对位。在基准数据d0中包含的数据项目与序列数据d中包含的数据项目不同的情况下,对位部23以基准数据d0作为基准,对序列数据d中的与基准数据d0共同的数据项目进行对位。
对位部23,以使各序列数据d中包含的特征性模式的位置与基准数据d0中包含的特征性模式的位置一致的方式,对各序列数据d进行对位。具体而言,对位部23,以提高基准数据d0与序列数据d的相似度的方式,以基准数据d0作为基准,使序列数据d的起点移动。此时,对位部13可根据需要进行数据的插值或细化。可通过互相关或动态时间规整法,算出相似度。对位部23优选以使基准数据d0与序列数据d的相似度成为最大的方式,移动序列数据d的起点。由此,对位部23能够使序列数据d中的特征性模式的位置与基准数据d0中包含的特征性模式的位置一致。
此外,对位部23在对序列数据d进行对位之前,可以对序列数据d进行标准化等的预处理。
对象数据提取部24提取对位部23进行对位后的序列数据d中的与基准数据d0对应(重复)的部分,作为对象数据。对象数据是在后续处理中作为利用对象的数据。由对象数据提取部24提取的对象数据即相当于用于辨别序列数据d的标签的数据。
序列数据d与基准数据d0对应(重复)的部分相当于,从基准数据d0以及对位后的序列数据d中的起点位于后方的一者的起点开始,到基准数据d0以及对位后的序列数据d中的终点位于前方的一者的终点为止的部分。在后续处理中,利用该对象数据进行处理。
如上所述,根据本实施方式,通过对位部23,能够从序列数据存储部21中存储的、数据量和特征性模式的位置不齐的序列数据d(辨别对象数据)中,自动提取数据量相同、特征性模式对位的对象数据。辨别装置2利用该对象数据来辨别序列数据d的标签,因此能够高精度地辨别标签。
特征量提取部25从对象数据提取部24所提取的对象数据中提取特征量。特征量提取部25能够通过小波变换、快速傅里叶变换、低通滤波器、高通滤波器等的方法,提取特征量。特征量的提取方法为任意方法。
辨别部26通过将特征量提取部25提取的特征量输入到辨别模型存储部22中存储的辨别模型,来辨别序列数据d的标签。
以下,关于模型生成装置1以及辨别装置2的工作进行说明。
首先,关于模型生成装置1的工作进行说明。图8是表示模型生成装置1的工作的一例的流程图。模型生成装置1的用户向模型生成装置1输入多个训练数据(添加标签的序列数据d)后,开始图8的工作。
首先,序列数据存储部11存储由用户输入的训练数据(步骤s101)。训练数据,可由用户端末通过网络输入,也可以从cd-rom等存储媒体输入。
其次,基准数据选择部12从序列数据存储部11读取序列数据d(训练数据),并从读取的序列数据d中选择基准数据d0(步骤s102)。基准数据选择部12可定期执行基准数据d0的选择,也可以根据来自用户的辨别模型生成要求执行,还可以在每次有新的训练数据被追加到序列数据存储部11时执行。基准数据选择部12向对位部13通知序列数据d以及选择结果(表示被选为基准数据d0的序列数据d的信息)。
对位部13从基准数据选择部12接到选择结果的通知后,以基准数据d0作为基准,对其他序列数据d进行对位(步骤s103)。对位部13向对象数据提取部14通知序列数据d以及对位结果(表示对位后的其他序列数据d的起点相对于基准数据d0的起点的相对位置的信息)。
对象数据提取部14接到对位结果通知之后,从基准数据d0以及其他序列数据d中,分别提取对象数据(步骤s104)。对象数据提取部14向特征量提取部15通知序列数据d以及提取结果(表示各序列数据d中的对象数据的起点以及终点的信息)。另外,对象数据提取部14将从基准数据d0中提取的对象数据发送给辨别装置2。辨别装置2的辨别模型存储部22接到对象数据之后,将该对象数据作为新的基准数据d0并进行存储。
特征量提取部15从对象数据提取部14接到提取结果的通知后,从各对象数据中提取特征量(步骤s105)。特征量提取部15向模型生成部16通知序列数据d以及提取结果(从各对象数据提取的特征量)。
模型生成部16从特征量提取部15接到提取结果的通知后,从序列数据存储部11读取各序列数据d的标签,并对各序列数据d的特征量与标签的关系进行机器学习,生成辨别模型(步骤s106)。模型生成部16将生成的辨别模型发送给辨别装置2。辨别装置2的辨别模型存储部22接到辨别模型后,将该辨别模型作为新的辨别模型进行存储。
模型生成装置1通过以上的处理,能够自动生成辨别模型。在此,模型生成装置1将各工序中获得的结果显示在显示装置106,以便模型生成装置1的用户能够进行确认。例如,可以在显示装置106上显示训练数据的输入画面、如图5所示的对位结果、如图6所示的对象数据的提取结果、生成的辨别模型、辨别模型的辨别精度等。
接下来,关于辨别装置2的工作进行说明。图9是表示辨别装置2的工作的一例的流程图。辨别装置2的用户向辨别装置2输入辨别对象数据(序列数据d)后,开始图9的工作。
首先,序列数据存储部21存储有用户输入的辨别对象数据(步骤s201)。辨别对象数据可从用户端末通过网络输入,也可以从cd-rom等存储媒体输入。
其次,对位部23从序列数据存储部21读取序列数据d(辨别对象数据),从辨别模型存储部22读取基准数据d0,并以基准数据d0作为基准,对序列数据d进行对位(步骤s202)。对位部23可定期执行序列数据d的对位,也可以根据来自用户的标签辨别要求执行,还可以在每次有新的辨别对象数据被追加到序列数据存储部21时执行。对位部23向对象数据提取部24通知序列数据d以及对位结果(表示对位后的序列数据d的起点相对于基准数据d0的起点的相对位置的信息)。
对象数据提取部24接到对位结果后,从序列数据d中提取对象数据(步骤s203)。对象数据提取部24向特征量提取部25通知提取结果(表示序列数据d中的对象数据的起点以及终点的信息)。
特征量提取部25从对象数据提取部24接到提取结果的通知后,从对象数据中提取特征量(步骤s204)。特征量提取部25向辨别部26通知提取结果(从对象数据中提取的特征量)。
辨别部26从特征量提取部25接到提取结果的通知后,从辨别模型存储部22读取辨别模型,并将特征量输入到该辨别模型,来辨别序列数据d的标签(步骤s205)。
辨别装置2通过以上的工作,能够自动辨别序列数据d的标签。此外,辨别装置2可以将各工序中获得的结果显示在显示装置,以便辨别装置2的用户能够进行确认。例如,可以在显示装置显示辨别对象数据的输入画面、如图5所示的对位结果、如图6所示的对象数据的提取结果、序列数据d的标签的辨别结果(序列数据d的标签)等。
如上所述,根据本实施方式,能够实现数据量以及特征性模式的位置不齐的序列数据d的预处理(对位以及数据量调整)的自动化。另外,能够根据多个训练数据自动生成高精度的辨别模型。另外,能够对辨别对象数据的标签进行高精度的自动辨别。
例如,可举出利用本实施方式的辨别系统100对设置在工厂等的机械设备进行异常检测的情况进行探讨。在此情况下,首先,辨别系统100的用户将用于检测机械设备的异常的感应器(加速度感应器或温度感应器等)设置在机械设备中,收集机械设备正常时的感应器数据和机械设备异常时的感应器数据。其次,用户对正常时收集到的感应器数据添加“正常”的标签,对异常时收集到的感应器数据添加“异常”的标签,并作为训练数据输入到模型生成装置1。如上所述,感应器数据(训练数据)被输入到模型生成装置1后,自动生成用于辨别感应器数据的标签是“正常”还是“异常”的辨别模型。即,用户即使不进行感应器数据的预处理,也能容易地获得辨别模型。在此,可以直接或通过网络连接感应器与模型生成装置1,感应器数据将从感应器被自动输入到模型生成装置1。在此情况下,用户可以预先设定应该对输入的感应器数据添加的标签。此外,模型生成部16还可以利用k-means法等可进行非监督学习的学习算法,生成辨别模型。
然后,用户将感应器数据作为辨别对象数据定期输入到辨别装置2。如上所述,辨别装置2在感应器数据(辨别对象数据)被输入后,根据辨别模型自动辨别感应器数据的标签是“正常”还是“异常”。即,用户即使不进行感应器数据的预处理,也能够实时简单地辨别出感应器数据的标签(机械设备的状态)。在此,可直接或通过网络连接感应器与辨别装置2,将感应器数据从感应器自动输入到辨别装置2。
如上所述,根据本实施方式,能够节省生成辨别模型及对辨别对象数据的标签进行辨别所需的时间劳力,因此能够削减制造模型生成装置1及辨别装置2所需的时间及成本。其结果,能够促进感应器数据等序列数据d的利用。
此外,本发明并不限定于上記实施方式中举出的结构等,与其他要素的组合等,在此提供的结构。就上述点而言,可以在不脱离本发明主旨的范围进行变更,根据其应用形态适当定决。
另外,本国际申请根据2017年11月16日向日本国专利厅提出的专利申请第2017-221038号请求优先权,并在本国际申请中引用上述申请的全部内容。
符号说明
1模型生成装置
2辨别装置
11序列数据存储部
12基准数据选择部
13对位部
14对象数据提取部
15特征量提取部
16模型生成部
21序列数据存储部
22辨别模型存储部
23对位部
24对象数据提取部
25特征量提取部
26辨别部
100辨别系统
- 还没有人留言评论。精彩留言会获得点赞!