光学伊辛机器以及光学卷积神经网络的制作方法
相关申请的交叉引用
本申请根据35u.s.c.§119(e)要求2017年7月11日提交的标题为“光学伊辛机器以及光学卷积神经网络(opticalisingmachineandopticalconvolutionalneuralnetworks)”的第62/531,217号美国申请的优先权权益,并且所述美国申请全文以引用的方式并入本文中。
政府支持
本发明是在政府支持下用陆军研究处授予的授权号w911nf-13-d-0001拨款作出的。政府在本发明中享有一定权利。
背景技术:
组合优化问题出现在许多领域,包含物理、化学、物流、电子和金融。如今,许多这些问题使用随机过程,例如,使用电子处理器实施的蒙特卡洛方法解决(或试图解决)。例如模拟退火的一些随机技术可以找到非确定性时间(np)难题的近似解,其中可能解的数目呈指数发散。
伊辛问题是一类np难题。所述问题涉及找到描述行为的伊辛模型的基态,其中物理系统中的个别元件修改其行为以符合邻近元件的行为。最初提出伊辛模型来解释关于铁磁性材料的观察结果。从那时起,所述伊辛模型已用于将二元合金和自旋玻璃以及神经网络、群鸟和心肌细胞中的相分离模型化。
在伊辛模型中,元素可以由一组自旋表示σj=±1。对于具有n个元素的伊辛模型,哈密顿量是:
其中k是n×n实对称矩阵,其中kii=0。k是先验地已知的;其值描述伊辛模型中的不同对元素之间的耦合或关系,这是其对角线值为零的原因(kii=0)。对于铁磁系统的伊辛模型,k表示不同铁磁元件之间的耦合。对于神经网络,k是表示神经元之间的耦合的权矩阵。伊辛问题正在解决将给定k的哈密顿量最小化的自旋分布,换句话说,找到伊辛模型的元素之间的给定一组耦合的基态。从优化的角度来看,对于任意矩阵k,找到将此哈密顿量最小化的自旋分布(即,找到伊辛模型的基态)是np难题。
技术实现要素:
本发明人已认识到,可以使用光子处理器解决(或试图解决)伊辛问题。这些光子处理器利用相比于电子域在光域中执行计算的益处。这些益处包含能够通过极少能量消耗并联执行多个高速计算。例如,光子处理器可以在光从光子处理器的输入传播到光子处理器的输出所花费的时间中执行数千次并行计算,所述时间可以约为纳秒级。光子处理器的这些特性使光子处理器尤其适合解决伊辛问题和其它np难题。
本发明技术的实施例包含确定伊辛模型的基态的方法。实例方法包含在多个时步中的每一个处:对光学信号进行编码,其中振幅表示伊辛模型的初始自旋状态;线性地变换所述光学信号以产生线性变换的光学信号;扰动所述线性变换的光学信号以产生扰动信号;非线性地阈值化所述扰动光学信号以产生非线性阈值化信号;以及从多个非线性阈值化信号确定伊辛模型的基态。
对光学信号进行编码可以包含将来自脉冲激光器的脉冲分成n个光学信号,其中n是正整数。随后调制n个光学信号的振幅以表示初始自旋状态。可以将光学信号同步地传输到执行线性变换的线性变换单元。
线性地变换光学信号可以包括在多个时步中的每个时步处执行静态线性变换。伊辛模型可以由哈密顿量表示:
其中k是表示伊辛模型的元素之间的相互作用的耦合矩阵,并且sj表示伊辛模型中的第j个元素的自旋,在此情况下,线性地变换光学信号包括基于耦合矩阵k执行与矩阵j的阵乘法。j可以等于作为k和对角矩阵δ的总和的
必要时,可以在第二时步中将来自第一时步的非线性阈值化信号反馈到光学信号中。并且必要时,可以例如出于监视目的检测每个非线性阈值化信号的一部分。
其它实施例包含用于确定伊辛模型的基态的自旋分布的光子处理器。光子处理器包含:光源;与所述光源进行光子通信的矩阵乘法单元;可操作地耦合到所述矩阵乘法单元的扰动单元;以及可操作地耦合到所述扰动单元的非线性阈值化单元。在操作中,光源产生光学信号,其中振幅表示伊辛模型的初始自旋状态。矩阵乘法单元将光学信号线性地变换成线性变换的光学信号。扰动单元例如通过在光检测期间增加噪声或施加随机光学相位来干扰线性变换的光学信号,以产生扰动信号。并且非线性阈值化单元非线性地阈值化扰动信号,以产生表示伊辛模型的基态的自旋分布的非线性阈值化信号。
在一些情况下,光子处理器可以包含与矩阵乘法单元和非线性阈值化单元进行光子通信的光学波导,以将非线性阈值化信号馈送回矩阵乘法单元的输入中。并且扰动单元可以包含光电检测器,用于经由测量噪声检测和扰动多个线性变换的光学信号。
其它实施例包含光学卷积神经网络(cnn)处理器。实例光学cnn处理器包括:衬底;第一光学干涉单元,所述第一光学干涉单元集成到所述衬底上;光延时线,所述光延时线集成到所述衬底上并与所述第一光学干涉单元进行光子通信;以及第二光学干涉单元,所述第二光学干涉单元集成到所述衬底上并与所述光延时线进行光子通信。第一光学干涉单元可以表示卷积神经网络中的第一层,并且第二光学干涉单元可以表示卷积神经网络中的第二层。
在操作中,第一光学干涉单元在第一时步处对第一多个光学信号执行第一矩阵乘法,并且在所述第一时步之后的第二时步处对第二多个光学信号执行第二矩阵乘法。光延时线产生第一多个光学信号的延时副本。并且第二光学干涉单元对第二多个光学信号以及第一多个光学信号的延时副本执行第三矩阵乘法。
光学处理器还可以包含调制器,所述调制器与第一光学干涉单元进行光子通信以用输入值的阵列调制第一多个光学信号。这些调制器可以由数字逻辑驱动,所述数字逻辑将表示图像的数值解析成输入值的多个阵列。并且光学处理器还可以包含光电检测器,所述光电检测器集成到衬底上以检测光学处理器的输出。
前述概念和下文更详细论述的附加概念的所有组合(假设这些概念不会相互矛盾)是本文所公开的本发明主题的一部分。本公开结尾出现的所要求主题的所有组合是本文中所公开的本发明主题的一部分。还可以出现在通过引用并入的任何公开内容中的本文所使用术语应被赋予与本文所公开概念最一致的含义。
附图说明
本领域技术人员将理解附图主要是用于说明性目的且并非意图限制本文所述的本发明主题的范围。附图未必按比例绘制;在一些情况下,本文公开的本发明主题的各个方面可以在图中夸大或放大地示出以助于理解不同特征。在图式中,类似的参考标号通常指类似的特征(例如,功能上类似和/或结构上类似的元件)。
图1示出计算伊辛问题的概率性解决方案的光子处理器的示意图。
图2示出计算伊辛问题的概率性解决方案的光子处理器的物理实现。
图3是说明用于使用光子处理器解决伊辛问题的一个过程的流程图。
图4a说明用于实施用于辨识图像(此处,编号“3”的图像)的卷积神经网络的过程。
图4b说明图4a的池化和卷积子过程以及重新改组过程。
图5a说明对于一般光学矩阵乘法,来自输入图像(左)的像素如何分组成较小分块,所述分块与第一层(在右侧上描绘)的核心具有相同尺寸。
图5b说明通过重塑图5a的较小分块来计算神经网络的第一层的核点积,所述较小分块被重塑成单列数据(分块输入矢量),所述数据被逐分块地馈送到光学干涉单元中以通过分块输入矢量产生表示第一层核的点积的时间序列。
图6a说明将图5b中产生的时间序列拼接为标记有计算对应核点积的时步的数据立方体。
图6b说明用于将神经网络层(左侧)的输出处的核点积的集合转换成与用于下一神经网络层的核心具有相同大小的输入分块的数据重新改组和重新拼接过程。
图7说明卷积神经网络的一部分,所述卷积神经网络具有用于实施第一核矩阵m1(左)的第一光学干涉单元、用于将核点积的序列改造成新分块以输入第二核矩阵m2(中间)中的光延时线,以及用于实施第二核矩阵m3(右;此处部分地描绘)的第二光学干涉单元。
具体实施方式
光学伊辛机器
光学伊辛机器是计算伊辛问题的概率性解决方案的光子处理器。换句话说,所述光学伊辛机器发现将针对以上等式中的给定k的哈密顿量最小化的自旋分布。此哈密顿量还可以表达为:
其中sj表示第j个元素的自旋并且具有值0或1。此表示适合于光学计算,因为自旋真实且为正,这意味着自旋可以由不同振幅的光束表示。
为了解决给定k的伊辛问题,光学伊辛机器产生其振幅对输入自旋分布进行编码的一组光束。这些光束传播通过将输入自旋分布乘以静态矩阵的静态矩阵乘法单元或线性变换单元。此静态矩阵通过j得出,其中j等于作为k和对角矩阵δ的总和的
矩阵乘法单元的输出受到扰动,例如,在每个时步处添加随机振幅噪声或相移,以经受非线性变换。通过防止自旋状态陷入产生哈密顿量的局部最小值,而不是全局最小值的解决方案,这种扰动减少自相关时间。在下一时步处将结果反馈到矩阵乘法单元的输入中。这将视需要持续多个时步。时步的数目可以提前设定或通过查看输出的聚合确定。在最后一个时步结束时,光子处理器的输出表示其对于由
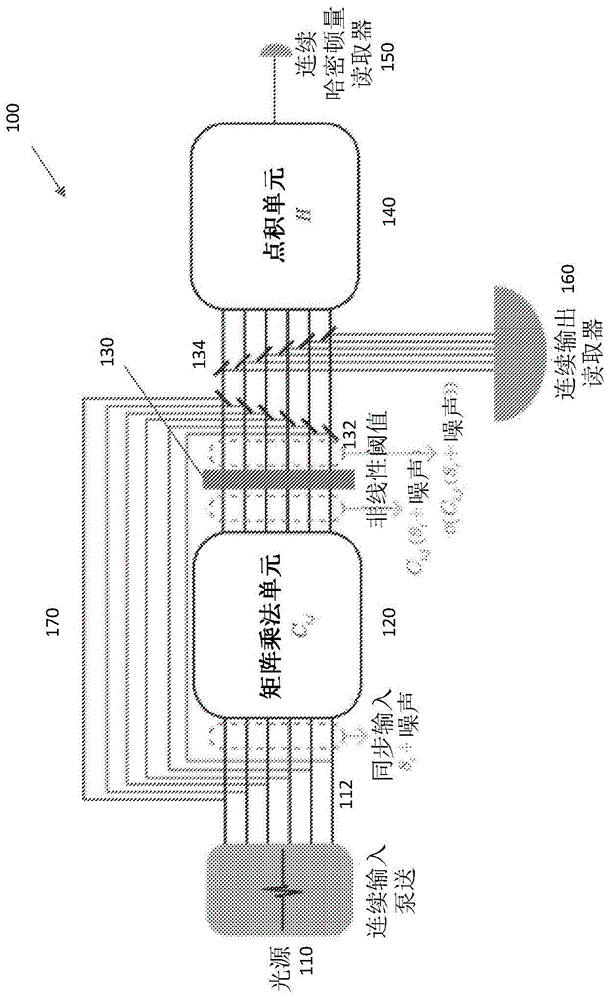
图1a示出可以计算伊辛模型的基态的光子处理器100。换句话说,此光子处理器100是产生上述伊辛问题的概率性解决方案的光学伊辛机器。所述光子处理器可以在半导体衬底上或中实施,并且包含耦合到矩阵乘法单元120的一个或多个光源110,所述矩阵乘法单元的输出又耦合到非线性阈值化单元130。由非线性阈值化单元130发射的光束传播通过第一组分光器132和第二组分光器134,所述第一组分光器将光束的部分引导到连续的输出读取器160,所述第二组分光器将光束的部分耦合回馈送矩阵乘法单元120的波导112。点积单元140接收传播通过分光器132和134的光束的部分。耦合到点积单元140的输出的光电检测器150将光子处理器100的光学输出检测为电子信号,所述电子信号表示将伊辛模型的哈密顿量最小化的自旋分布。这些组件中的每一个可以集成在半导体衬底中或上。
在操作中,光源110发出光束,所述光束的振幅表示伊辛模型的元素的自旋状态。光源110同步地,即同时发出这些光束,使得光束并行地传播通过光子处理器100。光源110可以实施为单个脉冲激光器,所述脉冲激光器的输出被分成n路,其中每个输出由对应振幅调制器调制。所述光源还可以实施为一组相位的时间上同步的脉冲激光器,所述脉冲激光器中的每一个基于所需自旋状态分布进行脉冲或振幅调制。
波导112将光束从光源110引导到矩阵乘法单元120。如上所述,这些波导112可以形成于半导体衬底中或上。矩阵乘法单元120还可以实施为集成到半导体衬底上的一组互连马赫-曾德尔干涉仪(mzi)或环形谐振器。在大量光学器件中,所述矩阵乘法单元可以实施为一对透镜之间的全息图或空间光调制器(slm)。
在任何实施方案中,矩阵乘法单元120对输入光束执行静态线性变换。如上文所说明,线性变换与描述由伊辛模型表示的系统的哈密顿量中的耦合矩阵k相关。更具体来说,线性变换是输入自旋分布与j的矩阵相乘,其中
非线性阈值化单元130将非线性阈值施加到矩阵乘法单元的线性变换输出。阈值是耦合矩阵k的线性组合:其等于矩阵元素的总和除以2。对于更多信息,参见例如通过引用并入本文中的p.peretto的“神经网络的集体特性:统计物理学方法”,生物控制论,50(1):第51至62页,1984年中的等式(19)。非线性阈值化操作是通过每次迭代相同的类似于线性变换的非线性变换。所述非线性阈值化操作可以在光域中执行为一组可饱和吸收体,例如(掺杂的)半导体、单层石墨烯,或非线性镜。或者,在已由一个或多个光电检测器转换光学信号之后,所述非线性阈值化操作可以在电子域中执行。
一些分光器132经由波导170将阈值化信号的部分耦合回矩阵乘法单元120的输入,其中所述阈值化信号的部分与输入相干地添加到下一时步/迭代。如果分光器132反馈回少于100%能量,则可以放大光束;如果反馈接近100%电力,则直到最后一次迭代才检测到信号。换句话说,处理器100执行n次迭代,其中n是大数值,并且每次迭代反馈回100%能量。在最后一次迭代结束时,处理器100测量信号。在任一情况下,反馈环路与光源110的脉冲重复率同步,以确保光束相互干扰。
其它分光器134将阈值化信号的部分耦合到连续的输出读取器160,所述连续的输出读取器可以实施为线性光电检测器阵列。连续的输出读取器160监视光束的当前能量状态并且是任选的,例如分光器134。阈值化信号的未利用部分传播到采用输入的点积的点积单元140。因为点积是线性运算,所以点积可以以光学方式实施,例如,通过透镜-空间光调制器(slm)-透镜系统实施,以首先执行矩阵乘法,随后使用slm来执行最终点积,其中输出由光电检测器150检测到。所述点积还可以在已通过阵列中的光电检测器检测到阈值化信号之后在电子域中计算。
检测通过增加呈散粒噪声、热噪声或两者形式的噪声来扰动光学信号。另外,振动和温度漂移可能会改变在信号传播通过处理器100时信号所经历的相对光程长度,从而引起随机相位扰动,这又引起光学输出的随机波动。无论来自散粒噪声、热噪声还是相位扰动,这些扰动设定由光子处理器探测到的分布中探测到的熵水平。从零增加噪声会减少处理器100聚合到解决方案所花费的时间。噪声不足可能会导致处理器100陷入哈密顿量的局部最小值,而噪声太多又会降低性能。
图2示出用于计算伊辛问题的解决方案的集成光学光子处理器200。此光子处理器200在光子域中执行线性操作并且在电子域中执行非线性操作。所述光子处理器包含光源210,所述光源具有脉冲激光器212和n个可编程2×2分光器的阵列214,其中n是由伊辛模型表示的元素的数目。激光器的输出被分成n路并且馈送到分光器阵列214中。此脉冲激光器212(以及处理器200)可以按千兆赫重复率操作。来自每个分光器214的一个输出耦合到矩阵乘法单元220的对应输入。终止其它输出。取决于输入自旋分布,分光器214以0或π/2的相位切换以在耦合到矩阵乘法单元220的输出处产生振幅为“0”或“1”的光束。
矩阵乘法单元220包含由分光器224的一维阵列连接的互连马赫-曾德尔干涉仪(mzi)222和226的两个阵列。第一mzi阵列222将输入乘以矩阵u,并且第二mzi阵列226将第一mzi阵列222的输出乘以矩阵
矩阵乘法单元的输出中的每一个耦合到对应50/50分光器232的输入。分光器的输出以平衡零差检测方案照明检测器阵列230中的对应检测器元件对。检测器阵列230耦合到可以实施于模拟/数字电子装置中的电子反馈系统240。电子反馈系统240包含:相位和强度检测模块242,所述相位和强度检测模块确定每个光束的相位和强度;非线性阈值单元244,所述非线性阈值单元对检测到的信号赋予非线性阈值函数;以及哈密顿量单元246,所述哈密顿量单元在给定由阈值化值表示的自旋状态的情况下计算哈密顿量的值。非线性阈值函数基于如上文相对于图1中的非线性阈值化单元描述的线性变换矩阵。并且哈密顿量单元246监视输出处的能量。将电子反馈单元240的输出反馈为分光器214的控制信号,所述控制信号控制到矩阵乘法单元220的输入的振幅。
图3示出用于使用与图1和2中所示的那些光学伊辛机器类似的光学伊辛机器解决伊辛问题的过程300。过程300包含生成一组光脉冲或其它光学信号,所述光学信号的振幅表示伊辛模型的初始自旋状态(步骤310)。基于伊辛模型的哈密顿量的耦合矩阵通过与静态矩阵的静态矩阵乘法线性地变换这些信号(步骤320)并且扰动这些信号(步骤330)。随后,还基于伊辛模型的哈密顿量的耦合矩阵通过非线性阈值化非线性地变换所述信号(步骤340)。步骤330和340可以在光域或电子域中发生。例如,扰动可以作为随机光学相位波动或作为检测器噪声施加。并且阈值化可以通过可饱和吸收体或在电子装置中施加。如果过程300尚未达到最后一次迭代,则将输出反馈回输入中(步骤350);否则过程结束(步骤360)。
光学卷积神经网络
光子处理器还可以用于实施人工神经网络。电子地实施人工神经网络对于多个机器学习任务具有显著改进的性能。与人工神经网络的最先进电子实施方案相比,与此处所公开的那些全光学神经网络类似的全光学神经网络可以快至少两个数量级并且功率效率高三个数量级。
可以在不需要显式指令的情况下快速地、有效地学习、组合和分析大量信息的计算机是处理大量数据集的强大工具。实际上,“深度学习”过程由于其在图像识别、语言翻译、做出决策问题等方面的实用性而在学术界和工业界都引起极大的兴趣。传统的中央处理单元(cpu)在实施这些算法方面远远不够理想。因此,学术界和工业界可能会加大力度来开发针对人工神经网络和深度学习中的应用定制的新硬件架构。
图形处理单元(gpu)、专用集成电路(asic)和现场可编程门阵列(fpga)提高能源效率并且增加学习任务的速度。并行地,已经示出实施尖峰处理和储存器计算的混合光电系统。然而,通过这些硬件架构实现的计算速度和功率效率仍受电子时钟速率和欧姆损耗的限制。
全光神经网络为微电子和混合光电实施方案提供一种有前景的替代方法。实际上,出于至少三个原因,人工神经网络是有前景的全光计算范式。第一,人工神经网络使用作为线性变换(以及某些非线性变换)的固定矩阵乘法,所述线性变换可以在光子网络中且在一些情况下以最少功率消耗以光速执行并且以超过100ghz的速率检测。第二,人工神经网络对非线性的要求不高,这意味着多个光学非线性可以用于在光学神经网络中实施非线性操作。并且第三,一旦训练了神经网络,架构就可以是无源的,这意味着在没有附加能量输入的情况下对光学信号执行计算。
人工神经网络架构含有输入层、至少一个隐藏层以及输出层。在每一层中,信息通过线性组合(例如,矩阵乘法)传播通过神经网络,随后非线性激活函数应用于从线性组合产生的结果。在训练人工神经网络模型时,将数据馈送到输入层中,并且通过一系列前向传播步骤计算输出。随后通过反向传播优化参数。
人工神经网络可以以光学方式实施为三个光学处理单元和各种其它组件的组合,包含用于供应光学信号的至少一个光源以及用于将光学输出转换成电子信号的至少一个检测器。光学处理单元包含光学干涉单元、光学放大单元,以及光学非线性单元。通过这三个单元,原则上,光学神经网络可以通过与传统人工神经网络执行计算的方式在数学上等效的方式来执行计算。
光学干涉单元例如使用马赫-曾德尔干涉仪的网络对输入光学信号执行任意酉矩阵乘法。(在数学上,可以严格地证明任何任意酉矩阵可以由马赫-曾德尔干涉仪的网络表示。)光学放大单元将酉矩阵一般化为任意矩阵运算。一般来说,可以通过单一值分解(svd)使用光学干涉和线性放大产生任何任意矩阵。光学非线性单元应用非线性激活函数。许多材料对外部光信号的响应与光强度呈非线性关系。一种常见的光学非线性是可饱和吸收。
一种类型的人工神经网络是倾向于专门表示图像分类的卷积神经网络(cnn)。类似于其它人工神经网络,cnn具有一系列互连层并且在训练过程中学习每一层的权重和偏差。并且类似于其它人工神经网络的光学实施方案,cnn的光学实施方案往往非常快并且功率消耗相对较小。
典型的cnn架构包含输入层、卷积层、修正线性单元(relu)层、池化层,以及全连接(fc)层。输入层保存由尺寸为w×h×3的矩阵表示的彩色图像,其中w和h分别是像素中的宽度和高度,并且存在三个颜色通道(例如,红色、绿色和蓝色)。卷积层计算k个滤波器和输入的点积,从而产生尺寸为w×h×k的阵列。relu层应用不会改变矩阵的体积的逐元素激活函数。池化层沿着矩阵的宽度和高度尺寸执行下采样操作,从而产生尺寸w/2nxh/2nxk的阵列。矩阵维度还可以通过偶尔在卷积层中获取更大步幅来减小,从而去除或减少池化层的数目。fc层计算类别评分,从而产生尺寸1×1×c的阵列,其中c是可用于cnn对输入图像进行分类的种类数目。任何fc层可以转换成卷积层,且反之亦然。
cnn中的卷积层可以如下使用矩阵乘法实施。首先,3d输入阵列转换成2d输入矩阵,其中3d输入阵列中的每个“分块”映射到2d输入矩阵中的行。接下来,在1d列中“展开”滤波核心,所述滤波核心并排布置以形成2d滤波器矩阵。将2d输入矩阵和2d滤波器矩阵相乘等效于3d输入阵列与滤波核心的卷积。如下文所说明,可以以光学方式实施此过程。
图4a和4b示出cnn如何识别输入图像401中的编号(此处,编号“3”)或其它特征。图4a示出输入图像401通过其传播通过cnn的过程400。输入图像400传播通过一系列级,其中图4a中示出两个级410和420。每个级410、420包含图4b中更详细示出的卷积和池化层412、422;非线性单元414、424;以及重新改组层416、426。最后一级420连接到fc层430,其产生表示输入图像401落入训练cnn的类别中的一个的可能性的评分。
图5a和5b示出用于通过cnn中的卷积层中的每一个进行光学矩阵乘法的拼接过程。在图5a中,在左侧上的输入图像的像素(此处,每个21×21×3个颜色)被分组成较小分块,所述分块与第一卷积层的核心(在图5a的右侧上描绘)具有相同尺寸。在图5b中,每个分块被重塑成单列数据。将这些数据列依序地逐分块馈送到光学干涉单元中。通过光学干涉单元传播光学数据列,这通过分块输入矢量实施第一层核心的点积。结果是光学信号的时间序列,所述光学信号的振幅与分块和核心的点积成比例。光学干涉单元的每个输出端口提供与给定核心相关联的点积的单独时间序列。
图6a说明例如使用光延时线将图5b中产生的时间序列拼接为标记有计算对应核点积的时步的数据立方体。换句话说,来自图4b中的第一层的输出核点积在图5a中的左侧描绘为立方体。每个立方体标记有计算对应核点积的时步。
图6b说明用于将神经网络层(左侧)的输出处的核点积的集合转换成与用于下一神经网络层的核心具有相同大小的输入分块的数据重新改组和重新拼接过程。光延时线被设计成使得可以及时重新改组一系列核点积,以形成与下一层的核心具有相同大小的新分块。重新改组过程仅在特定采样时间产生有效分块。t=6ps处的灰色部分指示无效采样间隔。
图7示出具有通过光延时线740连接的两个光学干涉单元730和750的光学cnn实施方案700。此cnn实施方案可以集成到半导体衬底702上,每个组件(波导、分光器、光电检测器等)也可以集成到所述半导体衬底上。第一光学干涉单元730用于实施核心矩阵m1。在核心矩阵m1的输出处的较厚区段表示光学非线性(例如,以提供图4a的非线性单元414)。光延时线740将核点积的序列适当地改造成用于输入到第二核心矩阵m2的新分块。第二光学干涉单元750实施第二核心矩阵m2(此处部分地描绘)。为了清晰起见,已经减少输入和输出的实际数目,并且已从图7省略衰减器级以及后续的附加光学干涉单元。
传播通过光学干涉单元和光延时线的光学信号可以通过激光器710产生,所述激光器通过分光器712和波导连接到一组电光调制器720,所述电光调制器中的每一个用将输入数据(例如,输入图像)解析成分块的数字逻辑790调制。(激光器710可以是通过光纤耦合到芯片的片上激光器或片外激光器。)可以通过将激光器710连接到第一光学干涉单元730的输入(左侧)端口中的任一个来产生光学信号,并且马赫-曾德尔干涉仪(mzi)阵列将数据编码到光学信号上。在光学信号一直传播通过光学干涉单元和光延时线之后,耦合到最后一个光学干涉单元的输出的片上光电检测器760感测到所述光学信号。
结论
虽然本文中已经描述和说明了多个发明性实施例,但是本领域普通技术人员将容易设想用于执行本文所述的功能和/或获得本文所述的结果和/或本文所述的优点中的一个或多个的多种其它构件和/或结构,并且此类变化形式和/或修改中的每一个被认为在本文所述的发明性实施例的范围内。更一般而言,本领域的技术人员将容易了解,本文所描述的所有参数、尺寸、材料以及配置都意指示例性的,并且实际参数、尺寸、材料和/或配置将取决于使用本发明教示的特定应用。本领域的技术人员顶多使用常规实验即可认识到或能够确定本文所描述的特定发明性实施例的许多等效物。因此,应理解,前述实施例仅借助于实例呈现,并且在所附权利要求书和其等效物的范围内,可以用与具体描述和要求的不同的方式实践发明性实施例。本公开的发明性实施例涉及本文所述的每一单独特征、系统、物品、材料、套件和/或方法。另外,两个或更多个此类特征、系统、物品、材料、套件和/或方法(如果此类特征、系统、物品、材料、套件和/或方法并非互不一致)的任何组合包含在本公开的发明性范围内。
此外,各种发明概念可以实施为一个或多个方法,已提供所述一个或多个方法的实例。作为方法的一部分执行的动作可以用任何合适的方式排序。因此,可以构造按不同于所说明的次序执行动作的实施例,其可以包含同时执行一些动作,即使在说明性实施例中展示为依序的动作也是如此。
应理解,如本文中定义和使用的所有定义都优先于字典定义、以引用的方式并入的文档中的定义和/或定义的术语的普通含义。
如本文在说明书和权利要求中所使用的不定冠词“一”和“一个”除非明确相反指示,否则应理解为意味着“至少一个”。
如本文在说明书和权利要求书中所用,短语“和/或”应理解为意指如此结合的元素中的“任一种或两种”,即,元素在一些情况下结合存在并且在其它情况下分开存在。用“和/或”列出的多种元素应该按照相同方式解释,即,如此结合的元素中的“一个或多个”。除通过“和/或”从句具体标识的元素之外,可以任选地存在其它元素,无论是否与具体标识的那些元素相关。因此,作为非限制性实例,当结合开放式语言(例如“包括”)使用时,提及“a和/或b”在一个实施例中可以仅指a(任选地包含除b之外的元素);在另一个实施例中仅指b(任选地包含除a之外的元素);在又一个实施例中,兼指a和b(任选地包含其它元素);等。
如本文在本说明书和权利要求书中所用,“或”应理解为具有与如上所定义的“和/或”相同的含义。举例来说,当分离列表中的项目时,“或”或“和/或”应被解释为包含性的,即包含多个或列表元素中的至少一个,但也包括多个或列表元素中的多于一个,以及任选地额外未列出的项目。只有明确相反指示的术语,如“仅仅……中的一个”或“恰好……中的一个”或当在权利要求书时使用时“由……组成”将指包含多个元素或元素列表中的恰好一个元素。一般来说,如本文中所用的术语“或”当前面是例如“任一”、“……中的一个”、“仅……中的一个”或“恰好……中的一个”的排它性术语时,仅应解释为指示排它性替代方案(即“一个或另一个但并非两者”)。“基本上由……组成”当在权利要求书中使用时,应具有如其在专利法领域中所用的普通含义。
如本文在本说明书和权利要求书中所用,提及一个或多个元素的列表,短语“至少一个”应理解为意指选自元素列表中的任何一个或多个元素中的至少一个元素,但不一定包括元素列表内具体列出的每一个元素中的至少一个,并且不排除元素列表中的元素的任何组合。此定义还允许除了元素列表内具体识别的短语“至少一个”所指的元素之外的元素可任选地存在,无论其是否与具体识别的那些元素相关。因此,作为非限制性实例,在一个实施例中,“a和b中的至少一个”(或,等效地,“a或b中的至少一个”或,等效地“a和/或b中的至少一个”)可以指代至少一个,任选地包含多于一个a,不存在b(并且任选地包含除了b之外的元素);在另一个实施例中,可以指代至少一个,任选地包含多于一个b,不存在a(并且任选地包含除了a之外的元素);在又一实施例中,可以指代至少一个,任选地包含多于一个a,和至少一个,任选地包含多于一个b(并且任选地包含其它元素);等。
在权利要求书中以及在上述说明书中,例如“包括”、“包含”、“带有”、“具有”、“含有”、“涉及”、“容纳”、“由……组成”等所有连接词应理解为是开放的,即,意指包含但不限于。如美国专利局专利审查手册第2111.03节所述,只有过渡短语“由……组成”和“基本上由……组成”应分别是封闭式或半封闭式过渡性短语。
- 还没有人留言评论。精彩留言会获得点赞!