一种基于中医药知识图谱和注意力机制的中医典籍古文翻译方法与流程
本发明涉及信息处理领域,特别涉及一种基于中医药知识图谱和注意力机制的中医典籍古文翻译方法。
背景技术:
机器翻译应用非常广泛,传统的机器翻译基于统计的方法,需要耗费大量的人力,且效果不好。目前主流的方法是基于神经网络的神经机器翻译。神经机器翻译分为两大流派,分别是基于seq2seq和基于纯注意力机制的神经翻译方法。seq2seq又称编码器-解码器结构,attention机制又称注意力机制。attention-seq2seq是基于编码器-解码器结构,在解码过程中,让解码器关注待翻译文本的特定文字,使得翻译时可以从待翻译文本中选择对该时刻最重要的子集进行额外关注,以提升翻译效果。纯注意力机制抛弃了seq2seq结构,完全使用注意力机制进行翻译。在中医典籍古文翻译领域,传统的seq2seq、attention-seq2seq、以及基于纯注意力机制的神经翻译方法效果均不好。传统的seq2seq结构将待翻译文本编码成一个定长向量,难以关注待翻译文本中的特定文字,难以生成符合专业中医知识的翻译结果。attention-seq2seq以及基于纯注意力机制的神经翻译方法,由于目前中医古文翻译适用语料很少,在缺乏专业中医知识指导的情况下,难以训练复杂的神经网络模型。本发明为了解决上述问题,提出了一种基于中医药知识图谱和注意力机制的中医典籍古文翻译方法。知识图谱(knowledgegraph)是一种基于图的知识表示与组织方法,它的核心部件是语义网络,其中的节点代表领域概念(实体),边代表概念之间的语义关系。中医药知识图谱目前网上已有相关的服务,包括中医经方知识图谱、中医临床知识图谱、中医特色诊疗技术知识图谱等。中医知识图谱实体涵盖疾病、中药、方剂、中药化学成分等,关系包括层次关系和相关关系两大类,并在语义网络的基础上添加了更多的知识内容。例如,在图谱中搜索“党参”,我们可以得到它的药性、药材基原、炮制方法、药理学等属性以及它的上下位关系(如“党参”的上位概念为“补气药”)和50多种相关关系(如“党参”与其相关花卉、相关生物和相关药品等的相关关系)。本发明在attention-seq2seq的基础上,基于注意力机制,用中医知识图谱给attention-seq2seq提供了专业的中医知识指导,使得神经网络可训练,翻译结果质量高。
技术实现要素:
为了解决现有的技术问题,本发明提供了一种基于中医药知识图谱和注意力机制的中医典籍古文翻译方法,方案如下。
步骤一,基于中医药知识图谱,构造中医药实体词典和关系词典,并初始化实体向量和关系向量。实体类型包括疾病、中药、方剂、中药化学成分等,关系类型包括药味关系、方治关系、证治关系、机证关系等。
步骤二,建立中医古文词表和现代汉语词表,并将中医古文和现代汉语的每个词语都映射为相应的词向量,并将中医古文的词向量拼接,将输入的中医古文映射为一个中医古文矩阵。
步骤三,对中医古文,基于中医药实体词典和中医药知识图谱,得到其相邻的实体-关系对,并编码成图谱向量。
步骤四,编码阶段,使用一个循环神经网络对中医古文矩阵进行编码,将中医古文映射成古文向量。
步骤五,解码阶段,用步骤四编码器得到的古文向量,初始化另一个循环神经网络,拼接特定的开始符和零向量,作为解码器的输入,开始解码。
步骤六,上一时刻解码器的输出通过attention结构得到attention向量,attention向量和步骤三的图谱向量得到指导向量。指导向量和上一时刻的输出共同作为下一个时刻解码器的输入,每个时刻的输出经过一个前向神经网络,并在现代汉语词表上得到翻译结果,直到解码器输出的翻译结果为结束符,解码结束。
附图说明
图1是本发明提供的基于中医药知识图谱和注意力机制的古文翻译模型结构图。
图2为长短期记忆网络单元的内部结构图。
具体实施方式
接下来将对本发明的实施方案作更详细的描述。
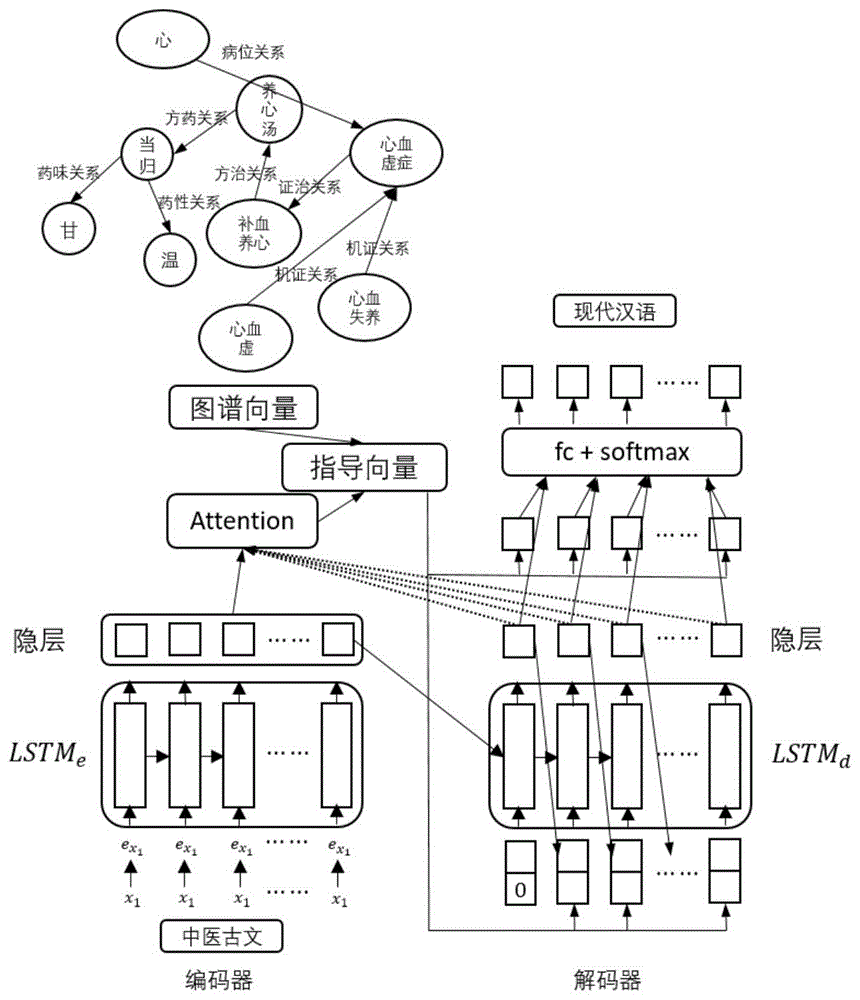
图1是基于中医药知识图谱和注意力机制的古文翻译模型结构图,其中包括:
步骤s1:基于中医药知识图谱,构造中医药实体词典和中医药关系类型词典,初始化中医药实体向量和中医药关系向量;
步骤s2:将中医古文现代汉语分别映射成词向量,拼接中医古文词向量得到编码器输入;
步骤s3:对中医古文,基于中医药知识图谱,将其编码成图谱向量;
步骤s4:编码阶段,用循环神经网络编码中医古文信息;
步骤s5:输入特定的开始符,开始解码;
步骤s6:通过attention结构得到attention向量,结合图谱向量得到指导向量。拼接指导向量和解码器上一时刻的输出得到下一时刻解码器的输入,解码直至输出停止符。
下面对第一部分的每个步骤进行具体的说明:
步骤s1:基于中医药知识图谱,构造中医药实体词典和中医药关系词典,初始化中医药实体向量和中医药关系向量。如图1所示,图中是中医药知识图谱的一部分,该图包含的实体有“心”、“当归”、“甘”、“温”、“养心汤”、“心血虚症”、“心血虚”、“补血养心”和“心血失养”,包含的关系有“药味关系”、“方药关系”、“方治关系”、“证治关系”、“药性关系”和“机证关系”。针对整个中医药知识图谱,构造中医药实体词典和中医药关系词典。假设中医药实体词典共有实体s个,那么中医药实体向量矩阵可以表示为一个s*k的矩阵,其中k表示词向量的维度,每一个中医药实体可以用一个k维的向量进行表示,即fi。同理,每一个中医药关系可以用gi表示。
步骤s2:中医古文和现代汉语分别向量化。本发明首先分别针对中医古文和现代汉语,建立词语到词向量编号的映射字典,将文本中各个词语映射为相应的词语编号。建立词向量矩阵,每一行行号对应相应的词语编号,每一行代表一个词向量。假设中文词语共有n个,那么词向量矩阵可以表示为一个n*d的矩阵,其中d表示词向量的维度,每一个词语都可以用一个d维的向量进行表示。拼接中医古文词向量得到编码器输入。对于中医古文的输入文本,假设该句话中一共有n个词语,将该句中的所有词语的词向量拼接,可以得到编码器的输入矩阵,输入矩阵可以表示为x。
其中,xi表示文本中第i个单词的词向量,n表示文本长度即文本中词语个数,
步骤s3:对中医古文,基于中医药知识图谱,将其编码成图谱向量。针对待翻译的中医古文,基于步骤s1构造的中医药实体词典,提取出待翻译中医古文的实体entity。针对实体entity,基于中医药知识图谱,找到与该entity通过一条邻边相连的所有实体-关系集合。即对与entity相邻实体entityi,entityi与entity之间的关系relationi可以构成entityi-relationi实体-关系对。所有的相邻实体-关系对可以构成大小为n′的实体-关系集合{entity1-relation1,…,entityn′-relationn′}。对特定的实体-关系对entity1-relation1,由s1初始化的中医药实体向量集合和中医药关系向量集合,得到实体向量g1和关系向量f1。将所有实体-关系对对应相乘求和,可以编码得到图谱向量c图谱。
c图谱=g1*f1+g2*f2+…+gn′*fn′
步骤s4:编码阶段,用一个循环神经网络编码古文信息,记为lstme。循环神经网络可以很好的提取文本的上下文信息,循环神经网络可以关注到更长时间的依赖关系,更好的捕捉文章的整体信息。传统的循环神经网络会出现梯度消失及梯度爆炸的问题,而长短期记忆网络(lstm)可以很好的解决这个问题。长短期记忆网络中利用输入门,忘记门,输出门可以更有效的控制学习到长距离的依赖关系。
图2给出了一种长短期记忆网络的单元结构,时刻t可以描述为:
it=σ(wi·xt+ui·ht-1+bi)
ft=σ(wf·xt+uf·ht-1+bf)
ot=σ(wo·xt+uo·ht-1+bo)
ht=ot⊙tanh(ct)
其中x是输入的向量,c是记忆单元,i是输入门,f是忘记门,o是输出门。σ是sigmoid激活函数。⊙是数值对位相乘,·是矩阵相乘。w和u分别是输入和隐藏层的权重矩阵,b是偏置。
c古文=hn
步骤s5:输入特定的开始符,开始解码。在步骤s4中我们得到了古文的语义表示向量c古文,该向量蕴含了该古文的所有信息。我们使用如步骤s4相同结构的长短期记忆网络lstmd,作为解码器,并用c古文初始化lstmd。我们设定两个特殊的符号,一个是开始符,另一个是结束符。首先列拼接开始符和全零向量,输入到lstmd,得到第一个时刻的隐状态s1,此时,解码阶段开始。
步骤s6:解码直至输出停止符。对上一时刻解码器lstmd的隐状态si-1和步骤s4得到的所有时刻的隐状态[h1h2…hn],经过attention模块,得到attention向量,该attention向量会选择性的从[h1h2…hn]向量序列中挑选一个子集输入解码器进行进一步处理。这样,在解码器产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。attention模块的具体方法如下,对s4得到的所有时刻隐层输出hj∈[h1h2…hn],算出hj与上一时刻解码器隐状态si-1的分数eij,a是前向神经网络,用来衡量得分。之后使用softmax得到解码器输出si-1在tx输入隐藏状态中的注意力分配向量αij,然后按照αij对[h1h2…hn]向量进行加权,得到attention向量ai。该attention向量蕴含了针对前一刻时刻解码器输出和输入序列的特定信息。
eij=a(si-1,hj)
之后,我们用ai和步骤s3得到的图谱向量c图谱,经过前向神经网络,得到该时刻的指导向量
根据该时刻的指导向量
si=lstmd(xi)
以上结合附图对所提出的一种基于中医药知识图谱和注意力机制的中医典籍古文翻译方法及各模块的具体实施方式进行了阐述。通过以上实施方式的描述,所属领域的一般技术人员可以清楚的了解到本发明可借助软件加必需的通用硬件平台的方式来实现。
依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
以上所述的本发明实施方式,并不构成对发明保护范围的限定。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!