一种基于MIMO递归神经网络的纳税人行业两层级分类方法与流程
本发明涉及一种基于mimo递归神经网络(multi-inputmulti-outputrnn)的纳税人行业两层级分类方法,用于解决纳税人所属行业在行业大类和行业明细两个层级上的分类问题。
背景技术:
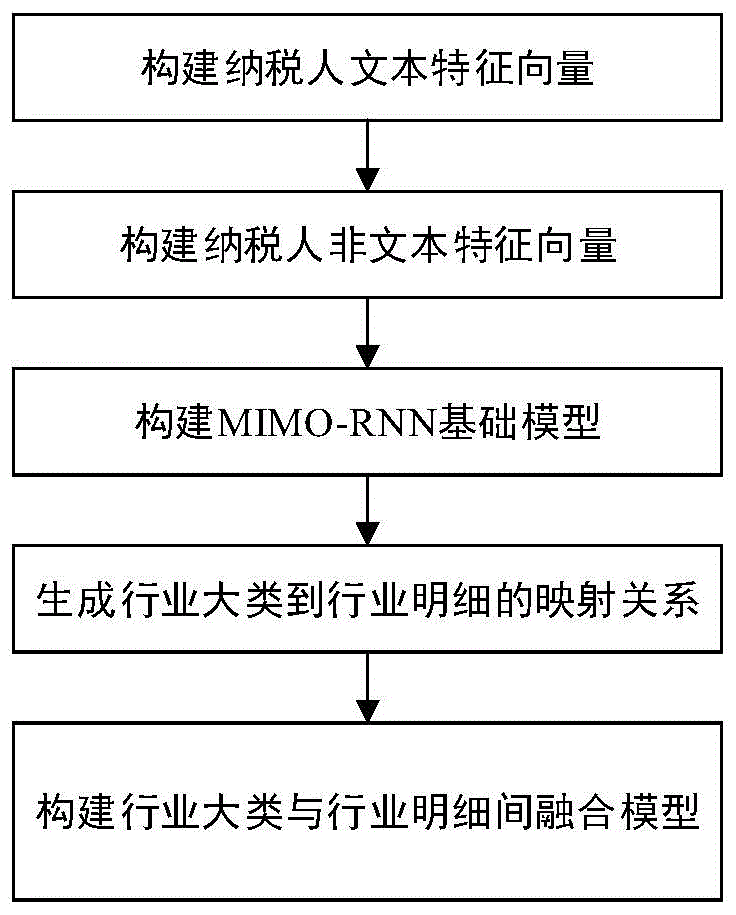
:纳税人行业分类是在统计、计划、财政、税收、工商等国家宏观管理中的重要内容,是经济管理和统计工作的重要基础,有助于国家对各种产业活动的观察和监测。行业分类具有分层次、种类多的特点,2017版行业分类标准中包括行业大类97种,行业明细1380种,其中,行业明细是行业大类根据具体的经济活动细分得来的。实际纳税人不仅具有一种主营行业,还可能有若干附属行业,纳税人在登记注册时,工作人员需根据纳税人的经营范围确定其主营行业明细及附属行业明细。目前纳税人行业两层次分类主要通过工作人员凭借经验根据纳税人的经营范围进行行业划分,在现如今庞大的行业规模下,存在效率低下、主观臆断、考虑信息不全面等问题,如何对纳税人所属行业在多个层次上进行正确高效划分是目前亟待解决的问题。以下文献提供了可参考的旨在对纳税人所属行业在多个层次上进行分类的技术解决方案:1、一种针对发布文本的行业分类方法和系统。(201210076564.4)2、基于自动信息筛选的企业行业分类系统。(201611270135.5)3、一种企业行业分类方法。(201711137533.4)文献1提供了一种针对发布文本的行业分类方法和系统,构建两级类别体系,包括一级行业类别特征词集合挖掘和二级行业分类模型训练,实现对发布文本一级和二级行业分类。文献2提供了一种基于自动信息筛选的企业行业分类系统,结合循环神经网络和门限控制的方法构造行业分类神经网络模型,根据企业的经营范围信息和企业名称信息,实现对企业二级行业的自动分类判断。文献3提供了一种企业行业分类的方法。利用半监督学习的图分裂聚类算法提取了企业的主营业务关键词,并基于梯度提升决策树使用提取的关键词作为特征,训练级联分类器将企业按行业分类。然而以上文献所述方法主要存在以下问题:国民经济行业分类中指出行业分类层次主要有门类、大类、中类、小类。文献1中二级行业的分类方法根据第一级行业特征词集合,筛选出特定一级行业下属二级行业对应的特征词,从而进行二级行业分类,绝对依赖于一级行业分类的正确率,容易忽略有效特征;文献2只关注在行业明细这层级进行行业分类,层次单一;文献3中使用的企业信息与行业分类的数据存在失真现象,依赖人工标注关键词,并且二级行业类别的判断范围隶属于一级行业类别预测结果,同样绝对依赖于一级行业分类的正确率。另外,三篇文献都只关注企业的文本信息,而忽略企业注册时的非文本信息,有一定的局限性。技术实现要素:本发明的目的在于提供一种基于mimo递归神经网络的纳税人行业两层级分类方法。首先,提取纳税人注册登记信息中的纳税人名称和经营范围2维文本特征;其次,提取纳税人注册登记信息中的法人性别、登记注册类型、注册资本、从业人数、合伙人数、办税人_证件号码、总机构标志、国地共管户标志、自然人投资比例、外资投资比例、国有投资比例、外籍人数、固定人数13维的非文本特征;再次,为将文本特征和非文本特征同时作为输入,构建具有多输入多输出结构的gru神经网络,以最小化交叉熵损失函数为优化目标训练神经网络,以此作为基础模型;然后,设计行业大类到行业明细的映射关系;最后,基于二者间的映射关系将基础模型进行分组融合,在隐藏层与另一层级的隐藏层向量进行融合,经sigmoid全连接层输出分类结果,进一步提高多标签分类的准确性,以解决纳税人所属行业在行业大类和行业明细两个层级上的分类问题。为了达到以上目的,本发明是采取如下技术方案予以实现的:一种基于mimo递归神经网络的纳税人行业两层级分类方法,包括以下步骤:1)构建纳税人文本特征向量查询数据库中的纳税人信息表,提取纳税人注册登记信息中的纳税人名称和经营范围2维文本信息,将纳税人的电子档案号nsrdzdah作为唯一标识;将纳税人名称及经营范围中的不规则元素删除,基于国家行业分类标准构建了包括4480个词语的行业分类专业词典,基于全国省市区县地名大全及四级行政区划地名词库构建停用词词典用以后续去除纳税人名称中的地名;基于ansj分词器对提取出的文本信息进行分词、去停用词、向量化后得到样本的文本特征;2)构建纳税人非文本特征向量纳税人登记注册时的信息包括纳税人名称及经营范围2维文本信息,以及多维的非文本信息;添加非文本信息作为后续模型输入,能够更加全面的考虑纳税人信息,有利于提高纳税人所属行业两层次分类的准确率;查询数据库中的纳税人基本信息表,从中提取以下十四个字段:{nsrdzdah,frxb,bsr_zjhm,djzclx,zjgbz,gdgghbz,zczb,zrrtzbl,wztzbl,gytzbl,cyrs,wjrs,hhrs,gdrs}其中nsrdzdah表示纳税人电子档案号,frxb表示法人性别,bsr_zjhm表示办税人_证件号码,djzclx表示登记注册类型,zjgbz表示总机构标志,gdgghbz表示国地共管户标志,zczb表示注册资本,zrrtzbl表示自然人投资比例,wztzbl表示外资投资比例,gytzbl表示国有投资比例,cyrs表示从业人数,wjrs表示外籍人数,hhrs表示合伙人数,gdrs表示其中固定人数;其中根据办税人_证件号码bsr_zjhm得到法人年龄,将提取结果构建成13维非文本信息,把纳税人识别号nsrdzdah作为唯一标识;对其中的数值型特征进行z-score标准化处理,对类别型特征进行one-hotencoding处理,将处理得到的合并向量表示为snon-t,作为非文本特征的表示向量;3)构建mimo-rnn基础模型首先,进行纳税人行业大类的模型训练,将文本特征转化为词序列作为输入,对该序列进行向前向和后向gru神经网络训练;其次,将前向和后向训练得到的预测向量和非文本特征编码向量相结合,输入到隐藏层神经元的对应组中;然后,再通过sigmoid全连接层进行损失函数的训练,得到多个输出作为纳税人行业大类的多标签分类结果;最后,进行纳税人行业明细的模型训练,重复上述过程得到多个输出作为纳税人行业明细的多标签分类结果;4)生成行业大类到行业明细的映射关系国民经济行业分类规定了行业大类和行业明细的包含关系,根据mimo-rnn模型的训练结果,行业大类与行业明细之间存在对应关系:当纳税人属于某一行业大类的概率较大时,该纳税人属于其对应的行业明细的概率也较大;当纳税人属于某一行业明细的概率较大时,该纳税人属于其对应的行业大类概率也较大,所以行业大类与行业明细之间的存在映射关系;行业明细较行业大类对纳税人行业的划分粒度更细,根据行业大类中具体的经济活动,将每类行业大类又细分为多种行业明细;因此行业大类与行业明细间的映射关系是一对多的;所述行业明细代码到行业大类代码的映射关系,格式表现为:行业大类(2位代码)行业明细(4位代码)行业大类用两位阿拉伯数字表示,从01开始按顺序编码,每组代码表示不同的行业大类;行业明细用四位阿拉伯数字表示,前两位为大类编码,后两位按顺序进行编码,每组编码表示不同的行业明细;5)构建行业大类与行业明细间融合模型基于行业两层级分类模型之间的相互印证关系,通过神经网络模型对行业大类分类模型与行业明细分类模型隐藏层的向量进行融合,查询数据库中的纳税人信息表,根据唯一标识纳税人电子档案号nsdzdah提取该纳税人对应的行业大类和行业明细代码作为标签集{nsdzdah,hydl,hymx},验证融合模型输出结果的准确率。本发明进一步的改进在于,步骤1)中,所述纳税人信息表为存储纳税人文本及非文本信息的数据表;所述国家行业分类为2017版国家经济行业分类,包括20个门类,97个大类,473个中类,1380个小类;所述全国省市区县地名大全及四级行政区划地名词库选自搜狗输入法词库;所述将纳税人名称及经营范围中的不规则元素删除,是对纳税人文本信息进行预处理,纳税人注册登记信息尚未实现规范化,其中的不规则元素、异常字符能够对分类结果造成影响。本发明进一步的改进在于,为了消除纳税人信息中的不规范元素对分类的影响,进行以下预处理:a.删除特殊符号;b.删除数字及量词;纳税人登记信息中的人名、地名、行业描述、经营范围文本信息往往超过分词工具自带词典的涵盖能力,为了防止纳税人信息分词过程中被分割成语义不完整的单词碎片,基于国家经济行业分类构建行业分类专业词典以及基于全国省市区县地名大全和四级行政区划地名词库构建停用词词典;所述基于国家经济行业分类构建行业分类专业词典,匹配国家经济行业分类中的行业名称及说明,提取出4480个词语用于构建行业分类专业词典,将行业分类专业词典加入到ansj分词器的自定义词典中,使用自定义词典对纳税人名称和经营范围进行分词;所述基于全国省市区县地名大全及四级行政区划地名词库构建停用词词典,提取出省市县区不同层级的地名构成停用词词典,停用词词典包括但不局限于地名词语,将常见停用词,也添加至停用词词典中;将停用词词典加入ansj分词器的自定义词典中,用于去除纳税人名称中的地名信息;所述ansj分词器是基于n-gram+crf+hff的中文分词器,基于ansj分词器对文本特征进行分词具体步骤包括:step1:对文本信息进行原子切分;step2:基于最短路径进行粗切分,根据隐马尔科夫模型和viterbi算法达到最优路径的规划;step3:对划分出的词语进行人名识别并停用;step4:基于用户补充的自定义词典,具体为行业分类专用词典及停用词词典,对分词后的文本信息去停用词;step5:将分词后的文本特征进行向量化处理,便于输入后续模型进行训练。本发明进一步的改进在于,步骤2)中,所述z-score标准化是将原始数据的标准差映射为1,对数值型特征进行z-score标准化的具体步骤为:step1:求出各维度特征的数学期望μ和标准差σ;step2:按照下列公式对各维度特征分别进行标准化处理:其中x*表示标准化后的变量值,x表示实际变量值;step3:将逆指标前的正负号对调;所述one-hotencoding是指使用n位状态寄存器来对n种状态进行编码,每个状态都有独立的寄存器位,并且在任意时候,其中只有一位有效,对类别型特征进行one-hotencoding的具体步骤为:step1:根据不同特征的分类情况,确定需要的bit位,对应bit为1的位置对应原来的特征值;step2:循环step1,得到所有类别型特征的one-hot编码;step3:将每个特征的one-hot编码进行拼接,得到最终的one-hot编码向量,作为后续模型中非文本类别型特征的输入形式。本发明进一步的改进在于,步骤3)中,所述对词序列进行前向和后向gru神经网络训练,具体包括:step1:构建双向gru神经网络,其由两层gru网络组成,两层网络的输入相同,分别表示为前向输入和后向输入,输入后信息传递方向相反;gru网络是在rnn的基础上引入门机制来控制信息更新的方式,包括重置门和更新门;更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,重置门用于控制忽略前一时刻的状态信息的程度;step2:前向输入的是每一个纳税人的文本特征向量,通过全连接的神经网络生成信息重置门控制向量;step3:通过信息重置门控制向量筛选文本信息向量生成筛选后的文本信息向量;step4:将筛选后的文本信息向量通过更新门控制向量生成n×m1维的预测向量其中n表示纳税人数量,m1表示每位纳税人信息中文本特征的维数;step5:后向输入纳税人的文本信息向量,通过全连接的神经网络进行后向信息反馈;step6:将经过重置门筛选后的文本信息经更新门生成n×m2维的预测向量其中n表示纳税人数量,m2表示每位纳税人信息中非文本特征的维数;step7:将预测向量和进行拼接,生成n×(m1+m2)维的合并向量所述将文本特征的输出结果与非文本特征编码相结合,根据唯一标识的纳税人电子档案号nsrdzdah,将同一纳税人的文本信息和非文本信息进行匹配后合并,文本信息为文本特征训练后的合并向量非文本信息为非文本特征表征后的向量snon-t,二者合并后得到包含纳税人文本信息和非文本信息的向量scomcat;所述进行损失函数的训练,是以减少损失为导向进行参数调整,具体包括:step1:将scomcat作为输入,根据交叉熵函数进行训练,具体表示为其中,yj为第j个样本的真实标签,pj为第j个样本分类概率;step2:不断迭代,取多个输出的交叉熵的平均值,直到达到实际输出收敛;step3:神经网络的多输出集合rdetail_output,集合中的每个值代表一个行业,设定阈值δ,低于该阈值表示纳税人不属于这个行业,高于该阈值表示纳税人属于这个行业;在对行业明细进行多标签分类时,网络结构相同,构建多输入多输出的双向gru神经网络,再通过sigmoid全连接层以最小化交叉熵函数为优化目标进行训练,实现纳税人所属行业明细的预测。本发明进一步的改进在于,步骤5)中,所述行业大类和行业明细间模型融合,具体包括行业明细模型对行业大类模型输出验证和行业大类模型对行业明细模型输出验证;所述行业明细模型对行业大类模型输出验证,根据行业明细的输出结果,赋予不同行业大类不同的权重,进行行业大类的模型训练,从中选取置信度超过指定阈值的类别作为预测结果,具体步骤包括:step1:进行行业明细的模型训练,将模型的多输出集合rdetail_output表示为识别矩阵,具体表示为1×n的列向量:rdetail_output=[p1,p2,...,pk,...,pn]t其中,n表示行业明细的n种类别,pk=pr(k|xu)表示为纳税人u属于行业明细k的置信度;step2:将上述识别矩阵,结合行业大类与行业明细的映射关系,得到矩阵gm=[g1,g2,...,gm,...,gl]t,其中l为行业大类的l种类别,gm=pr(m|xu)表示为纳税人u属于行业大类m的置信度;step3:根据矩阵gm的数值,赋予不同行业大类不同的权重w;step4:进行行业大类的模型训练,将行业大类的隐藏层向量输入到行业明细隐藏层神经元的对应组中,点乘权重w进行合并,作为隐藏层的输出;step5:通过sigmoid全连接层进行行业大类的预测,选取置信度最高的行业大类作为主营行业大类其它超过阈值δ的作为兼营行业大类;所述行业大类模型对行业明细模型的输出验证,由于行业大类与行业明细间为一对多关系,将两种模型的隐藏层向量进行融合,具体步骤包括:step1:进行行业大类的模型训练,模型的多输出集合具体表示为1×l维的列向量:rcategory_output=[g1,g2,...,gm,...,gl]t其中,l为行业大类的l种类别,gm=pr(m|xu)表示为纳税人u属于行业大类m的置信度;step2:根据行业大类到行业明细一对多的映射关系,得到1×n维矩阵,具体表示为:pk=[p1,p2,...,pk,...,pn]t其中,n表示行业明细的n种类别,pk=pr(k|xu)表示为纳税人u属于行业明细k的置信度;step3:根据矩阵pm的数值,赋予不同行业明细不同的权重w,同一行业大类下的行业明细权重相同;step4:进行行业明细的模型训练,将行业明细的隐藏层向量输入到行业大类隐藏层神经元的对应组中,点乘权重w进行合并,作为隐藏层的输出;step5:通过sigmoid全连接层进行行业明细的预测,选取置信度最高的行业明细作为主营行业明细其它超过阈值δ的作为兼营行业明细;所述行业大类的分类概率和行业明细的分类概率进行分组融合,构建三层神经网络,将行业明细向量与隐藏层输出进行合并,再通过sigmoid全连接层进行行业明细的预测;所述验证融合模型输出结果的准确率,对比融合模型输出结果和标签集{nsdzdah,hydl,hymx},根据唯一标识纳税人电子档案号nsdzdah将结果与标签集一一对应,计算每个纳税人行业多标签分类的准确率,取所有纳税人分类准确率的平均值作为最终结果。与现有技术相比,本发明具有如下有益的技术效果:1、本发明不局限于纳税人登记信息中的纳税人名称和经验范围2维文本特征,还考虑到法人性别、登记注册类型、总机构标志、注册资本、办证人_证件号码、国地共管户标志、自然人投资比例、外资投资比例、国有投资比例、从业人数、外籍人数、合伙人数、固定人数13维非文本特征,二者结合充分考虑纳税人信息,修改双向gru神经网络模型为多输入多输出结构,便于同时输入文本及非文本特征。2、本发明根据行业明细到行业大类的映射关系,对两层行业模型进行融合,分别进行行业大类和行业明细在隐藏层的向量融合,然后经sigmoid全连接层输出多类别标签,不绝对依赖于任一层级的分类结果,进一步提高了分类效果。综上所述,本发明提供的一种基于mimo递归神经网络的纳税人行业两层级分类方法,构建具有多输入多输出结构的双向gru神经网络,便于同时输入文本及非文本特征,并在隐藏层分别进行行业大类和行业明细向量融合,然后经sigmoid全连接层输出多类别标签,不绝对依赖于任一层级的分类结果,以此解决纳税人所属行业在行业大类和行业明细两个层级上的分类问题。附图说明图1是本发明方法的整体流程示意图。图2是纳税人文本特征向量构建的流程示意图。图3是纳税人非文本特征向量构建的流程示意图。图4是mimo-rnn基础模型构建的流程示意图。图5是行业大类与行业明细之间融合模型构建的流程示意图。具体实施方式以下参照附图,结合具体实施例对本发明一种基于mimo递归神经网络的纳税人行业两层级分类方法作进一步说明。如图1所示,本发明实施例中,对纳税人行业两层次分类过程包括:步骤1:构建纳税人文本特征向量。构建过程包含以下步骤:基于国家经济行业分类标准构建行业分类专业词典,基于全国省市区县地名大全及四级行政区划地名词库构建停用词词典,对纳税人文本信息进行预处理,将特殊符号、数字、量词从文本信息中删除,基于ansj分词器进行分词。本实施例中,选取纳税人名称为“陕西省西安市碑林区α律动ktv有限公司”,经过步骤1后,陕西省西安市碑林区作为地名被检测出从文本信息中删除(图2步骤202),α作为特殊符号被检测出从文本信息中删除(图2步骤203),经分词后,变为“律动、ktv、有限、公司”文本信息(图2步骤204)。步骤2:构建纳税人非文本特征向量,构建过程包含以下步骤:查询数据库中纳税人基本信息表,提取法人性别、登记注册类型、注册资本、从业人数、合伙人数、办税人_证件号码、总机构标志、国地共管户标志、自然人投资比例、外资投资比例、国有投资比例、外籍人数、固定人数13维非文本特征,对其中的数值型特征进行z-score进行标准化处理,对其中的类别型特征进行one-hotencoding处理。本实施例中,根据国家行业分类标准(2017版)的应用时间,选取陕西国税中2017年至2018年登记注册的纳税人,从中选取23个行业大类,86个行业明细的样本数据,共计271116个纳税人记录,对其中的数值型特征进行z-score进行标准化处理,对其中的类别型特征进行one-hotencoding处理,得到271116×13维的向量结果。选取纳税人电子档案号为610016022933024774的纳税人信息进行展示,在数据库中提取的原始十三维非文本特征数据为{610016022933024774,女,37,06,null,null,500000,1,0,0,3,0,null,null}(图3步骤301),经过计算转化为{0.32145213,1,0.345,0,0,0.6784,0.1412,0,0,0.1413,0,0,0}(图3步骤303、304)。步骤3:构建mimo-rnn基础模型。如图4所示,mimo-rnn基础模型的构建过程包含以下步骤:将步骤1和步骤2得到的词向量序列按8:1:1的比例分为训练集(stext-train和snontext-train)、验证集(stext-validation和snontext-validation)、测试集(stext-test和snontext-test)。首先进行纳税人行业大类的多标签分类。将训练集stext-train和验证集stext-validation输入到gru神经网络模型中,分别完成前向运算和后向运算,这个过程中模型会自动修正神经网络中的权重参数。完成双向运算后,将两次输出进行合并与非文本特征向量进行合并得到scomcat,输入交叉熵损失函数进行训练,损失函数具体表示为:其中,yj为第j个样本的真实标签,pj为第j个样本分类概率。进行网络训练时,记录训练集和验证集的损失值,当达到设定的损失函数阈值,认为模型已经收敛并停止模型的训练。模型实现纳税人所属行业大类的向量输出,每种输出对应一个行业,用于表示纳税人行业大类的多标签分类结果,设定阈值δ=0.5,当输出结果小于δ时表示纳税人不属于该行业大类,输出结果大于δ时表示纳税人属于该行业大类。其次,进行纳税人行业明细的多标签分类,重复上述过程,得到纳税人所属行业明细的多标签分类结果。在本实施例中,选取纳税人电子档案号为610016022933024xxx的纳税人信息,首先将该纳税人的文本特征向量stext输入到mimo-rnn模型后进行行业大类分类后的得到多输出结果为{0,0,0,0,0,1,…,1,0,0,…,0,0,0}23维的纳税人多标签向量,说明经mimo-rnn模型划分该纳税人所属行业大类为06、12,通过到mimo-rnn模型后进行行业明细分类后的得到多输出结果为{0,0,0,0,0,1,1,0…,1,0,0,…,0,1,0}86维的纳税人多标签向量,说明经mimo-rnn模型划分该纳税人所属行业明细为0610、0690、1200、2211。步骤4:生成行业大类到行业明细的映射关系。在本实例中,根据纳税人所属行业大类到行业明细的映射关系,存在以下记录:行业大类行业明细060610、0620、0690121200222211、2212、2221、2222、2223、2231、2239根据上述映射关系,可知代码为0610、0690的行业明细属于代码为06的行业大类,代码为1200的行业明细属于代码为12的行业大类,代码为2211的行业明细属于代码为22的行业大类。根据行业大类和行业明细间的映射关系,可以辅助验证mimo-rnn模型分类的准确率。步骤5:构建行业大类和行业明细间融合模型。如图5所示,基于行业大类和行业明细之间的从属关系进行模型融合,根据行业两层次模型间的相互印证关系,通过神经网络模型对行业大类分类模型与行业明细分类模型的隐藏层向量进行融合,行业大类分类概率和行业明细分类概率进行分组融合。行业大类和行业明细间模型融合,具体包括行业明细模型对行业大类模型输出验证和行业大类模型对行业明细模型输出验证。本实施例中,行业明细模型对行业大类模型输出验证,具体为将步骤103中纳税人电子档案号为610016022933024xxx的行业大类的合并向量scomcat作为输入,将模型的多输出集合rdetail_output={0.1,0.123,…,0.895,0.687,0.21,0.885,0.789,…,0.154,0.08}表示为1×n维识别矩阵,rdetail_output=[p1,p2,...,pk,...,pn]t,其中pk=pr(k|xu)表示为纳税人u属于行业明细k的置信度。结合行业大类与行业明细的映射关系,得到1×l维矩阵gm=[g1,g2,...,gm,...,gl]t,其中gm=pr(m|xu)表示为纳税人u属于行业大类m的置信度。根据矩阵gm的数值,赋予不同行业大类不同的权重w。进行行业大类的模型训练,将行业大类的隐藏层向量输入到行业明细的隐藏层神经元的对应组中,点乘权重w进行合并,作为隐藏层的输出。通过sigmoid全连接层进行行业大类的预测。选取置信度最高的行业大类作为主营行业大类具体为将代码06的行业大类作为主营行业大类,其它超过阈值δ的作为兼营行业大类,具体表示为将代码12的行业大类作为兼营行业大类。行业大类模型对行业明细模型输出验证,具体为将步骤103中纳税人电子档案号为610016022933024xxx的行业明细的合并向量scomcat,模型的多输出集合为rcategory_output=[g1,g2,...,gm,...,gl]t=[0.155,0.023,…,0.685,0.877,0.11,0.845,0.949,…,0.151,0.07],其中gm=pr(m|xu)表示为纳税人u属于行业大类m的置信度。根据行业大类到行业明细一对多的映射关系,得到1×n矩阵pk=[p1,p2,...,pk,...,pn]t,其中pk=pr(k|xu)表示为纳税人u属于行业明细k的置信度。根据矩阵pm的数值,赋予不同行业明细不同的权重w,同一行业大类下的行业明细权重相同。进行行业明细的模型训练,将行业明细的隐藏层向量输入到行业大类的隐藏层神经元的对应组中,点乘权重w进行合并,作为隐藏层的输出。通过sigmoid全连接层进行行业明细的预测。选取置信度最高的行业明细作为主营行业明细具体为将代码0690的行业明细作为主营行业明细,其它超过阈值δ的作为兼营行业明细,具体表示为将代码0610、1200的行业明细作为兼营行业明细。与只经行业明细得到的结果{0610,0690,1200,2211}进行对比,经模型融合后的分类结果将2211这个行业明细的分类结果删除,得到结果为{0610,0690,1200},进一步地提高了模型的分类结果。本领域的技术人员容易理解,以上所述仅为本发明的方法实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1