一种处理监控大数据的实时流计算监控系统及方法与流程
本发明涉及大数据计算技术领域,特别涉及一种处理监控大数据的实时流计算监控系统及方法。
背景技术:
随着云计算大数据技术的日益普及,分布式技术快速发展,业务系统规模日益复杂,机器规模日益庞大,相应产生的监控数据也逐渐成为一种大数据(以下简称“监控大数据”),传统的监控系统在应对监控大数据时显得力不从心,因此迫切需要新的监控系统具有高并发的处理能力。
众所周知,数据价值随着时间的流逝而快速降低,监控大数据对时间的要求更加迫切,如果监控到故障数据后,系统很久才能做出处理,那么系统的可用性及可靠性将大打折扣,因此迫切需要新的监控系统具有实时流计算的处理能力。
监控大数据是一种典型的时间序列数据(以下简称“时序数据”),这是一种以(时间戳,数值)为元组的数据类型,需要特殊数据库存储,而传统的监控系统都是使用关系型数据库存储监控数据,因此迫切需要新的监控系统使用时序数据库存储监控大数据。
监控大数据的展现是监控系统非常重要的一部分,传统的监控系统展现能力比较弱,直接展示原始监控数据时性能比较差,随着前端技术的发展,对监控大数据展现能力的要求也越来越高,因此迫切需要新的监控系统具有很强的前端展现能力。
监控大数据一般涉及到三个时间:监控数据产生的事件时间(eventtime),监控数据到达监控系统的时间(ingestiontime),监控数据被处理的时间(processtime),传统的监控系统只能按照处理时间(processtime)处理监控数据,当有网络延迟时,错误率比较高,因此迫切需要新的监控系统具有同时处理以上三种时间的能力。
现有的zabbix是一个企业级的、开源的、分布式的监控套件,被用来监控it基础设施的可用性和性能,采用pull的方式采集数据,数据存储在关系型数据库mysql中。zabbix采用pull的方式采集数据,不是一种流计算的方式,数据实时性不高;当目标机器量大之后,pull任务会出现积压,采集数据会延迟,因此也不是一种高并发的监控系统;zabbix将监控数据存储在关系型数据库mysql中,而非专业的时序数据库,当数据量大时,数据库会成为瓶颈,性能上会有损耗。
目前也有技术存储层采用关系型数据库mysql,存储层使用html5、css和js库开发,界面风格使用bootstrap3.0开发的大数据平台监控系统。尽管使用了大数据技术,但是存储监控数据的数据库仍是关系型数据库mysql,而非专业的时序数据库,当数据量大时,数据库会成为瓶颈,性能上会有损耗。尽管展现层使用了html5、bootstrap3.0,但只是对聚合的监控数据进行展现,并不能钻取到原始监控数据,易用性差。
另外,也有技术实时任务由sparkstreaming和storm直接读取kafka数据流,进行数据清洗和计算。尽管使用了流计算技术,但是sparkstreaming是一种“微批次”(micro-batch)技术,本质上还是批处理,并非真正的流计算,并且不能基于监控数据产生时间(eventtime)处理数据,错误率比较高。
技术实现要素:
为解决上述技术问题,本发明提供了一种处理监控大数据的实时流计算监控系统及方法,以达到提高采集监控大数据的性能,基于事件时间(eventtime)进行计算保证高并发计算的准确性,通过展现聚合数据并能钻取到原始数据加快展现速度的目的。
为达到上述目的,本发明的技术方案如下:
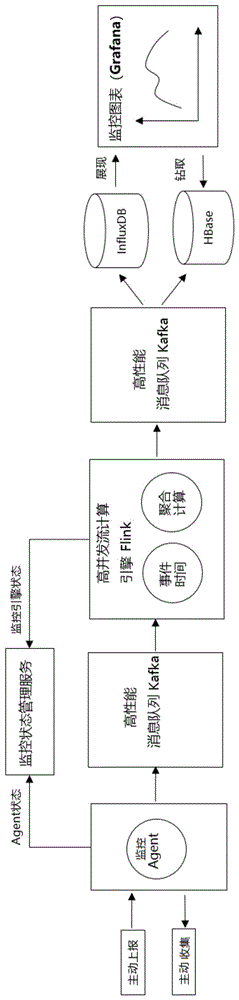
一种处理监控大数据的实时流计算监控系统,包括如下单元:
数据采集单元,采用监控agent,通过主动上报或主动收集的方式获得对应机器上的监控原始数据,并且定时调用监控状态管理服务单元,实现对监控agent状态的实时自监控;
数据缓存单元,包括用于存储监控agent收集到的监控原始数据和存储聚合计算后的监控数据的高性能消息队列kafka;
数据计算单元,基于高并发流计算引擎flink,对原始监控数据进行聚合计算,同时对监控数据划分时间窗口,在每个计算窗口内,按照监控指标进行分组,根据监控数据自身携带的数据采集时间进行聚合计算,处理乱序数据以及延迟到达数据,聚合计算完的监控数据被发送到高性能消息队列kafka中做暂时缓存,并且定时调用监控状态管理服务单元,实现对高并发流计算引擎flink状态的实时自监控;
数据存储单元,包括用于存储聚合计算后的监控数据的时序数据库influxdb,和用于存储监控原始数据的hbase;
数据展现单元,通过grafana展现进行聚合计算后的监控数据,并且通过钻取功能,从hbase中联查到原始的监控数据。
一种处理监控大数据的实时流计算监控方法,采用上述的一种处理监控大数据的实时流计算监控系统,包括如下步骤:
(1)数据采集:数据采集单元利用监控agent,通过主动上报或主动收集的方式获得对应机器上的监控原始数据;
(2)数据缓存:监控agent收集到监控原始数据后,在本地做短时间的内存缓存,然后批量将监控原始数据发送到高性能消息队列kafka,作为所有分布式监控大数据的集中数据缓存;
(3)数据计算:通过高并发流计算引擎flink,从高性能消息队列kafka中实时拉取监控数据进行聚合计算,同时计算时对监控数据划分时间窗口,在每个计算窗口内,按照监控指标进行分组,根据监控数据自身携带的数据采集时间进行聚合计算,处理乱序数据以及延迟到达数据;
(4)数据缓存:高并发流计算引擎flink聚合计算完的监控数据被发送到高性能消息队列kafka中做暂时缓存;
(5)数据存储:存储在高性能消息队列kafka中的监控数据被分类批量写入到不同的存储数据库,聚合计算后的监控数据写入到时序数据库influxdb,用于图表展现;监控原始数据写入到hbase,用于通过聚合数据钻取到原始数据;
(6)数据展现:通过grafana展现进行聚合计算后的监控数据,通过提供的钻取功能,从hbase中联查到原始的监控数据。
上述方案中,所述步骤(2)中数据计算包括如下四种聚合维度计算方式:
a、全局维度
计算同一监控指标同一时间窗口内的全部数据,得到这些监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数;
b、集群维度
对同一监控指标同一时间窗口内的监控数据,按集群维度进行分组,得到每个集群维度监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数;
c、机器维度
对同一监控指标同一时间窗口内的监控数据,按机器维度进行分组,得到每个机器维度监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数;
d、自定义维度
对同一监控指标同一时间窗口内的监控数据,按每一个自定义维度进行分组,得到每个自定义维度监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数。
通过上述技术方案,本发明提供的处理监控大数据的实时流计算监控系统及方法具有以下优点:
1)用于数据采集的的监控agent可以通过主动上报和主动收集的方式采集监控数据,监控agent可以进行自监控。
2)用于数据计算的高并发流计算引擎flink基于监控数据的采集时间进行聚合计算,聚合计算时的维度有全局维度、集群维度、机器维度以及自定义维度;
3)数据展现的图表展现的是进行聚合计算后的监控数据,可以通过钻取方式联查到监控原始数据,聚合数据存储在时序数据库influxdb中,原始数据存储在hbase中;
因此,本发明提供的处理监控大数据的实时流计算监控系统及方法可以解决传统监控系统在处理监控大数据时采集数据性能差、基于“处理时间”(processtime)计算监控数据导致数据不准确、基于关系数据库存储数据导致性能有瓶颈、直接展示原始监控数据导致展现不流畅的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1为本发明实施例所公开的一种处理监控大数据的实时流计算监控系统及方法示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明提供了一种处理监控大数据的实时流计算监控系统及方法,如图1所示,该系统及方法提高了采集监控大数据的性能,基于事件时间(eventtime)进行计算保证了高并发计算的准确性,通过展现聚合数据并能钻取到原始数据加快了展现速度。
具体实施方式如下:
1、在每个机器上部署本发明专利实现的监控agent,通过主动上报或主动拉取的方式获得对应机器上的监控数据。
本发明专利定义的监控数据格式为:
监控数据采集时间,监控指标,监控值,监控指标所在集群,监控指标所在机器,自定义监控维度。
主动上报是一种推送(push)的方式,指业务程序进行埋点上报的方式,本系统提供客户端sdk,业务程序通过调用该sdk,将监控数据上报到监控agent。
主动收集是一种拉取(pull)的方式,指监控agent主动收集性能计数器中的数据,以及实现了本系统中监控插件的程序。
2、监控agent定时通过调用监控状态管理服务,实现对监控agent状态的实时自监控;监控agent将监控原始数据发送到高性能消息队列kafka,用于缓存监控原始数据,起到数据缓冲作用。
3、基于flink的高并发流计算引擎,基于事件时间(eventtime)对监控大数据进行聚合计算,计算时对监控数据划分时间窗口,可以是分钟级的窗口,也可以是秒级的窗口,在每个计算窗口内,按照监控指标进行分组,根据监控数据自身携带的数据采集时间(即事件时间)进行聚合计算,可以处理乱序数据以及延迟到达数据。基于flink的高并发流计算引擎定时通过调用监控状态管理服务,实现对监控引擎状态的实时自监控。
基于本实施例定义的监控数据格式,则在时间窗口内进行聚合计算时,主要有如下四种聚合维度计算方式,分别计算出相应维度数据的最大值、最小值、平均值、最后值、求和值以及数据个数。
a)全局维度
计算同一监控指标同一时间窗口内的全部数据,得到这些监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数。
b)集群维度
对同一监控指标同一时间窗口内的监控数据,按集群维度进行分组,得到每个集群维度监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数。
c)机器维度
对同一监控指标同一时间窗口内的监控数据,按机器维度进行分组,得到每个机器维度监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数。
d)自定义维度
前面三种维度相当于固定维度,本发明专利定义的监控数据格式还支持用户自定义维度,如果上报的监控数据有自定义维度,则对同一监控指标同一时间窗口内的监控数据,按每一个自定义维度进行分组,得到每个自定义维度监控数据的最大值、最小值、平均值、最后值、求和值以及数据个数。
4、聚合计算完的监控数据再次发送到高性能消息队列kafka,用于缓存计算后的监控数据,起到数据缓冲作用,防止因存储故障导致数据积压在监控引擎,影响计算性能。
5、分类处理高性能消息队列kafka中的监控数据,将计算后的聚合数据写入到时序数据库influxdb,将原始监控数据写入到hbase。
6、监控图表grafana,配置数据源为时序数据库influxdb,通过展现聚合数据加快展现速度,同时通过钻取功能,可以钻取到存储在hbase中的原始数据,既加快了监控数据的展现速度,又可以查看详细的原始监控数据。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!