基于FD-SOI工艺的二值化卷积神经网络内存内计算加速器的制作方法
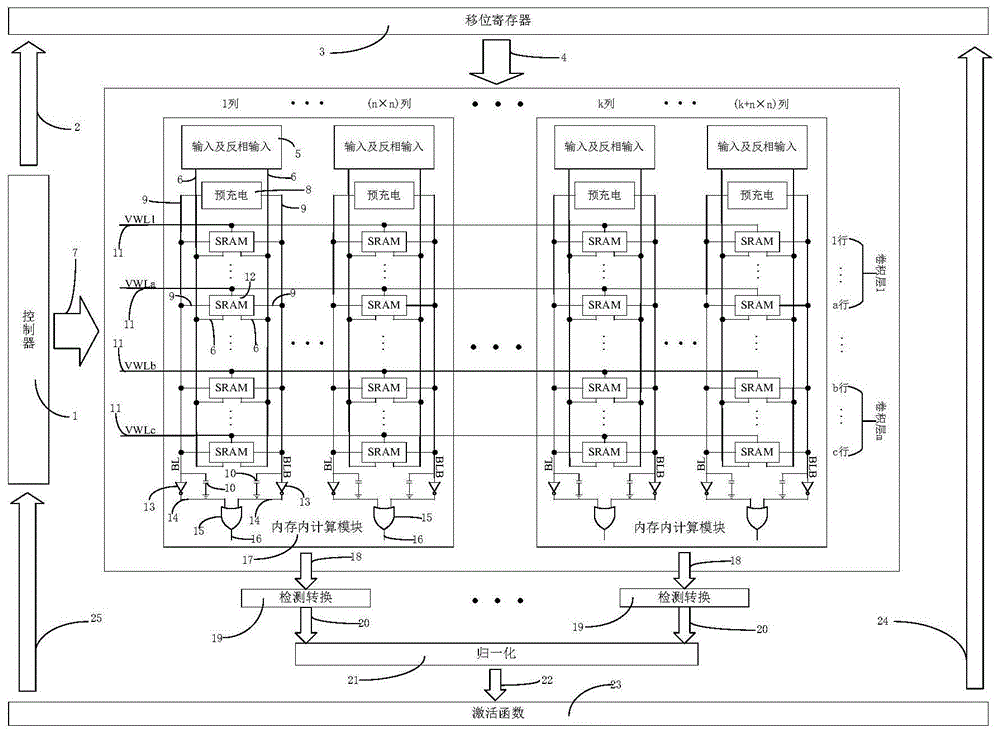
本发明属于神经网络技术领域,涉及一种基于fd-soi工艺的二值化卷积神经网络内存内计算加速器。
背景技术:
卷积神经网络(convolutionalneuralnetwork,cnn)是一种常见的深度学习架构,受生物自然视觉认知机制(动物视觉皮层细胞负责检测光学信号)启发而来,是一种特殊的多层前馈神经网络。它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。cnn的主要组成为卷积层(convolutionallyer)、池化层(poolinglayer)和全连接层(fullconnectionlayer),卷积层的卷积运算的目的是提取输入的不同特征,第一层卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网络能从低级特征中迭代提取更复杂的特征。传统的二值化卷积神经网络是将权值和隐藏层激活值二值化1或-1,通过二值化,使神经网络的参数占用更小的存储空间。
半导体工艺发展到22纳米时,为了满足性能、成本和功耗要求,延伸出了finfet和fd-soi两种工艺技术。fd-soi是一种平面工艺技术,因为此前一直没有形成完整的产业形态,所以应用范围相对较窄。不过fd-soi工艺近年来越来越受业界关注,其生态系统已经逐渐成型,其技术优势和应用前景也越发被看好。
传统的数据存储在磁盘中,进行运算时需要将数据提取到内存中,此过程需要大量的i/o连接。而采用内存内计算,则可以将计算过程发送到数据本地执行,极大地提升了运算速度、节约了存储面积、数据传输以及降低了运算功耗。
目前还没有一种基于fd-soi工艺实现数据的异或处理来提升cnn卷积速度的电路。
技术实现要素:
针对上述问题,本发明提出了一种自主学习脉冲神经网络权值量化方法。
本发明的技术方案为:
本发明提供了一种基于fd-soi工艺的二值化卷积神经网络内存内计算加速器。所述技术方案如下:
一种基于fd-soi工艺的二值化卷积神经网络内存内计算加速器,包括:
存储卷积神经网络卷积核参数并对输入数据完成卷积处理的内存内计算模块;
存储卷积神经网络输入数据且带有移位功能的移位寄存器模块;
对移位寄存器模块和内存内计算模块逻辑控制的控制器模块;
将内存内计算模块的计算结果转换为传统卷积计算结果的检测转换模块;
将不同的卷积核卷积的结果按权相加的归一化模块;
给神经网络加入非线性因素的激活函数模块。
进一步的,所述内存内计算模块由sram模块、输入及反相输入模块和预充电模块等构建而成;
所述sram模块,是采用6个mosfet构建且能存储一位数据的模块,两个p型mosfet和两个n型mosfet构成两个cmos反相器并将其首尾相连,此结构可用于存储一位数据,在两个反相器的输出端各连接一个fd-soi-mosfet,其背栅信号分别连接输入信号和该输入信号的反相信号,由于fd-soi-mosfet背栅信号对其阈值电压有调整作用,利用此调整作用可完成输入信号与存储信号的与非操作;
所述输入及反相输入模块,给sram模块提供输入信号和该输入信号的反相信号;
所述预充电模块,是内存内计算模块进行异或运算前将预充电电容充电。
进一步的,所述内存内计算模块用于存储卷积神经网络的卷积核参数“一维化”处理后的数据,每一行前(n×n)列可用于存储一个n行、n列的卷积核,同理,其之后可存储其他卷积核,每一行可用于存储多个卷积核参数,一个卷积层的卷积核参数可由一行或多行存储,将sram模块的输出信号经过偏斜反相器取反后再进行或处理,即可实现sram模块输入信号和存储信号的异或操作。
进一步的,所述移位寄存器模块用于存储卷积神经网络输入数据,并且能移位输出相应输入数据用于进行内存内计算模块的卷积操作。
进一步的,所述控制器模块控制移位寄存器模块输出相应数据;控制预充电模块的使能与关闭;控制移位寄存器输出数据与内存内计算模块相应行存储的卷积核参数进行异或操作,这部分控制功能由译码器实现。
进一步的,所述检测转换模块,其中“检测”是检测内存内计算模块的输出数据中“1”的个数,“转换”是内存内计算模块的输出数据的位宽减去2乘以“检测”的结果,本文二值化卷积神经网络将权值和隐藏层激活值二值化0或1,经过内存内计算模块和检测转换模块后,实现的功能等同于将权值和隐藏层激活值二值化-1或1的二值化卷积神经网络。
进一步的,所述归一化模块,将不同的卷积核卷积的结果按权相加,得到一个归一化的结果。
进一步的,所述激活函数模块,通过该模块给神经网络加入非线性因素,解决线性模型的表达、分类能力不足的问题。
进一步的,本发明还提出了一种所述基于fd-soi工艺的二值化卷积神经网络内存内计算加速器的卷积过程,包括:
步骤1,控制器模块发出控制指令,控制移位寄存器输出相应数据给内存内计算模块的输入及反相输入模块;
步骤2,输入及反相输入模块向与之同一列的sram模块传输数据;
步骤3,控制器模块控制预充电模块,将预充电模块使能,给预充电电容充电使bl和blb电位处于高电势,之后关闭预充电模块;
步骤4,控制器模块选中vwl1-vwlc中一条信号线使其处于高电势,即使该条信号线连接的sram模块行使能,则步骤2的传输数据与sram模块的存储数据完成与非运算;
步骤5,将sram计算结果传输给偏斜反相器,再将偏斜反相器的计算结果传输给或门,步骤4-5就完成了步骤2的传输数据与sram模块的存储数据的异或运算;
步骤6,将每个内存内计算模块中的或门计算结果传输给检测转换模块,本文二值化卷积神经网络将权值和隐藏层激活值二值化0或1,经过内存内计算模块和检测转换模块后,实现的功能等同于将权值和隐藏层激活值二值化-1或1的二值化卷积神经网络;
步骤7,将所有检测转换模块的输出结果传输给归一化模块;
步骤8,将归一化模块的输出结果传输给激活函数模块;
步骤9,将激活函数模块的输出结果传输给移位寄存器模块进行存储,若卷积操作还未结束,则跳转至步骤1,否则结束。
本发明的有益效果是:
本发明提供的方法核心为利用fd-soi-mosfet的背栅电压对其阈值电压的调整作用来实现数据的异或操作。在采用内存内计算的前提下,而相比于传统的卷积神经网络的卷积过程,运用异或操作完成卷积过程在保持高精度的同时,极大地提高了神经网络的卷积处理速度、节约了神经网络参数存储空间、数据传输以及降低了运算功耗。
附图说明
图1是本发明实例提供的一种基于fd-soi工艺的二值化卷积神经网络内存内计算加速器示意图;
图2是图1中cnn示意图;
图3是图1中sram模块示意图;
图4是图3中fd-soi-mosfet示意图;
图5是图3中fd-soi-mosfet的阈值示意图;
图6是图3中数据完成与非操作时序示意图;
图7是图3中数据完成与非操作真值表示意图;
图8是图1中偏斜反相器示意图;
图9是图1中偏斜反相器曲线示意图;
图10是本发明提出的一种基于fd-soi工艺的二值化卷积神经网络内存内计算加速器的卷积流程图。
具体实施方式
下面结合附图对本发明进行详细描述,以便本领域的技术人员能够更好地理解本发明。
对现有的二值化卷积神经网络研究时,发现卷积神经网络在实现卷积过程时会使用乘法和加法,其中乘法计算会极大地消耗存储面积、降低运算速度以及产生较大功耗,这些缺点都极大地降低了二值化卷积神经网络的性能指标。
经过对现有二值化卷积神经网络的计算结构进行分析发现,可以对二值化卷积神经网络的卷积算法进行优化,实现节省存储面积、降低计算功耗和提升计算速度的目的,本发明在现有技术的基础上提出了一种卷积算法并将其用电路实现,实现了用异或等计算实现卷积计算来代替传统的卷积计算。
为实现上诉目的,本发明提出一种基于fd-soi工艺的二值化卷积神经网络内存内计算加速器,包括:
存储卷积神经网络卷积核参数并对输入数据完成卷积处理的内存内计算模块;
存储卷积神经网络输入数据且带有移位功能的移位寄存器模块;
对移位寄存器模块和内存内计算模块逻辑控制的控制器模块;
将内存内计算模块的计算结果转换为传统卷积计算结果的检测转换模块;
将不同的卷积核卷积的结果按权相加的归一化模块;
给神经网络加入非线性因素的激活函数模块。
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图通过具体实施例对本发明进一步地详细说明,应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,内存内计算模块17用于存储卷积神经网络的卷积核参数“一维化”处理后的数据,每一行前(n×n)列可用于存储一个n行、n列的卷积核,同理,其之后可存储其他卷积核,每一行可用于存储多个卷积核参数,一个卷积层的卷积核参数可由一行或多行存储。移位寄存器模块3用于存储卷积神经网络输入数据,并且能移位输出相应输入数据4用于进行内存内计算模块17的卷积操作。控制器模块1控制移位寄存器模块3将cnn的相应输入数据输入到内存内计算模块17中,每一列接收的一个输入数据通过输入及反相输入模块5输出该输入数据6及其反相数据6给sram模块12。在进行数据运算前,需要通过预充电模块8将预充电电容10充电,使bl电位9和blb电位9处于高电位,之后关闭预充电模块8。然后控制器模块1通过控制vwl信号11使能其中一行sram模块12(该部分控制功能由译码器实现)。选中使能的一行sram模块12的输出6通过偏斜反相器13和或门15,即可实现输入数据与存储数据的异或运算。本实例中,电路实现的cnn将权值和隐藏层激活值二值化0或1,而传统的cnn将权值和隐藏层激活值二值化-1或1,将内存内计算模块17的计算结果18输入给检测转换模块19,即可实现本实例中的异或运算等效为传统cnn的卷积过程,从而得到相应卷积核卷积的结果20。归一化模块21将不同的卷积核卷积的结果20按权相加,得到一个归一化的结果22。归一化结果22通过激活函数模块23,给神经网络加入非线性因素,解决线性模型的表达、分类能力不足的问题。
如图2所示,该图展示了一个cnn示例,输入为一张图片,有两个卷积层、两个池化层,并展示了其全连接层。
如图3所示,两个cmos反相器26-27首尾相连,即可存储一位数据b,b’是b的反相数据。将两个反相器26-27的输出分别连接一个fd-soi-mosfet28,其中a和a’分别是输入数据6和其反相数据6,vwl是选择使能信号11,控制fd-soi-mosfet28的导通与关闭,bl电位9和blb电位9是sram模块12的两个输出。利用fd-soi-mosfet背栅信号对其阈值电压的调整作用(参阅图5)可完成输入信号与存储信号的与非操作(参阅图6和图7)。
如图4所示,该图展示了n型fd-soi-mosfet的剖面图,与常规mosfet相比较,其具有极薄的掺杂区和沟道(硅膜),掺杂区和沟道与背栅之间由隐埋氧化层隔开,通过背栅电压对沟道的调整作用来调整阈值电压。
如图5所示,该图展示了背栅电压对阈值电压的调整作用,展示了背栅电压越大,其阈值电压越小。
如图6所示,内存内计算模块17进行运算之前,先使能预充电模块8,给预充电电容10充电,使其bl电位9和blb电位9处于高电势,之后关闭预充电模块8。然后控制器模块1通过控制vwl信号11使能其中一行sram模块12,对于一个具体的sram模块12,此时两个fd-soi-mosfet28导通,其中a为输入数据6,b为存储数据(参阅图3)。当a=0时,阈值电压较大,a=1时,阈值电压较小,阈值电压较大时,预充电电容放电速度相较于阈值电压较小时的速度慢;当b=0时,预充电电容放电速度快,其电势会降得极低,当b=1时,预充电电容放电速度慢,其电势变化降得较小。最终综合4种情况,预充电电容10的电势bl电位9的变化情况如图所示,可知,在实现翻转电平40后,曲线32-34为“1”,曲线35为“0”。同理可得预充电电容10的电势blb电位9的变化情况,在实现翻转电平40后,曲线36-38为“1”,曲线39为“0”。
如图7所示,结合上文对图6的分析,可得sram模块12的真值表。由真值表可得到图3的sram模块12实现的功能,即bl=(ab’)’,blb=(a’b)’。
如图8所示,该图展示了图1中的偏斜反相器13的电路,它是由两个fd-soi-mosfet41-42组成的cmos反相器,其背栅电压分别是vp和vn。要实现图6的功能,最重要的便是图6所示的翻转电平40的实现。通过调整vp和vn,即可实现偏斜反相器13的翻转电平40,即为图6所示的翻转电平40。
如图9所示,该图展示了图8所示的偏斜反相器13的输入曲线45和输出曲线46,以及它的翻转电平40。
如图10所示,该图是本发明提出的一种基于fd-soi工艺的二值化卷积神经网络内存内计算加速器的卷积流程图,包括:
步骤s1,控制器模块发出控制指令,控制移位寄存器输出相应数据给内存内计算模块的输入及反相输入模块;
步骤s2,输入及反相输入模块向与之同一列的sram模块传输数据;
步骤s3,控制器模块控制预充电模块,将预充电模块使能,给预充电电容充电使bl和blb电位处于高电势,之后关闭预充电模块;
步骤s4,控制器模块选中vwl1-vwlc中一条信号线使其处于高电势,即使该条信号线连接的sram模块行使能,则步骤2的传输数据与sram模块的存储数据完成与非运算;
步骤s5,将sram计算结果传输给偏斜反相器,再将偏斜反相器的计算结果传输给或门,步骤4-5就完成了步骤2的传输数据与sram模块的存储数据的异或运算;
步骤s6,将每个内存内计算模块中的或门计算结果传输给检测转换模块,本文二值化卷积神经网络将权值和隐藏层激活值二值化0或1,经过内存内计算模块和检测转换模块后,实现的功能等同于将权值和隐藏层激活值二值化-1或1的二值化卷积神经网络;
步骤s7,将所有检测转换模块的输出结果传输给归一化模块;
步骤s8,将归一化模块的输出结果传输给激活函数模块;
步骤s9,将激活函数模块的输出结果传输给移位寄存器模块进行存储,若卷积操作还未结束,则跳转至步骤1,否则结束。
- 还没有人留言评论。精彩留言会获得点赞!