一种用于视频去模糊的无监督学习方法与流程
运动模糊是计算机视觉中的基本问题,因为它影响图像质量并阻碍推理。传统的去模糊算法利用图像形成模型的物理特性,并使用手工制作的先验作为参考点。这些算法通常会产生准确反映底层场景的结果,但会有伪影。最近基于学习的方法隐含地从输入中直接提取自然图像的分布并使用它来合成合理的图像。虽然这些方法有时会产生令人印象深刻的清晰输出,但它们可能并不总是忠实地再现潜像的内容。
技术实现要素:
公开了一种方法,当基于后续帧之间的光流重新模糊时,通过强制输出清晰帧以自监督方式微调去模糊神经网络,在最小误差距离内匹配输入模糊帧。
附图说明
为了容易地识别对任何特定元素或动作的讨论,附图标记中的一个或更多个最高有效位数字指代首先引入该元素的图号。
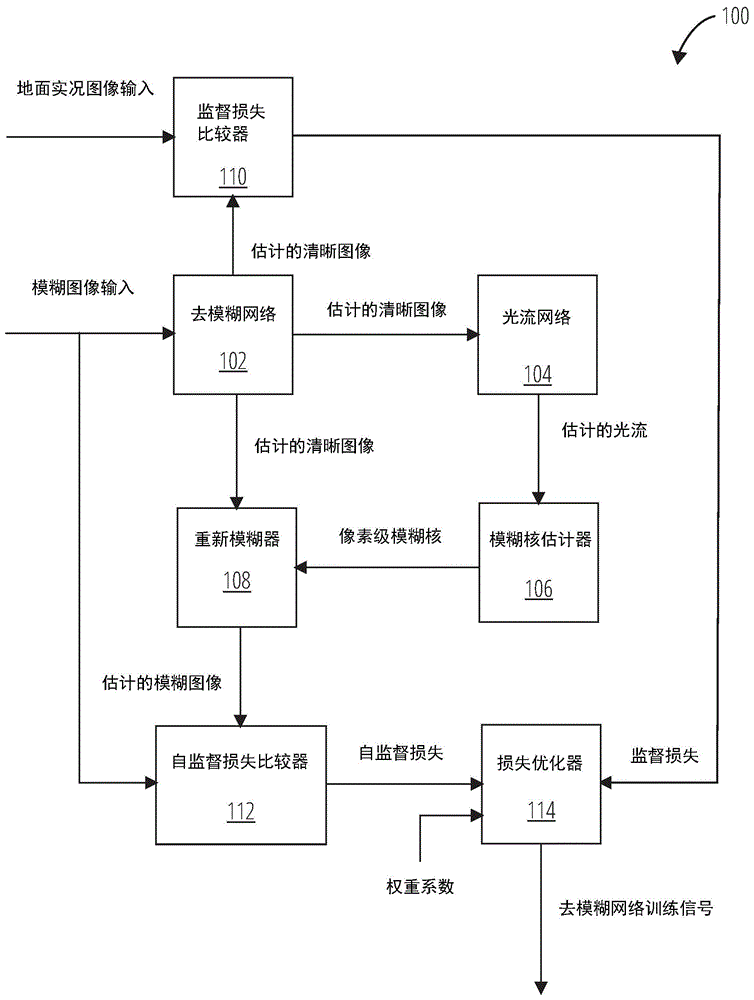
图1示出了去模糊训练系统100的实施例。
图2示出了去模糊训练过程200的实施例。
图3示出了像素级模糊核估计过程300的实施例。
图4是计算系统400的框图,在该计算系统400内可以包含或执行本文介绍的gpu或方法。
具体实施方式
参考图1,图像去模糊训练系统100包括去模糊网络102、光流网络104、模糊核估计器106、重新模糊单元108、监督损失比较器110、自监督损失比较器112和损失优化器114。
去模糊网络102接收模糊图像输入。去模糊网络102将模糊图像输入变换为估计的清晰图像,并将估计的清晰图像发送到光流网络104、监督损失比较器110和自监督损失比较器112。
光流网络104从去模糊网络102接收估计的清晰图像。光流网络104利用估计的清晰图像来确定估计的光流并将估计的光流发送到模糊核估计器106。
模糊核估计器106从光流网络104接收估计的光流。模糊核估计器106从估计的光流生成像素级模糊核,并将像素级模糊核发送到重新模糊单元108。
重新模糊单元108从模糊网络102接收估计的清晰图像,并从模糊核估计器106接收像素级模糊核。重新模糊单元108从估计的清晰图像和像素级模糊核生成估计的模糊图像,并将估计的模糊图像发送到自监督损失比较器112。
监督损失比较器110从去模糊网络102接收地面实况图像输入和估计的清晰图像。监督损失比较器110比较地面实况图像输入和估计的清晰图像以确定监督损失,并将监督损失发送到损失优化器114。
自监督损失比较器112从重新模糊单元108接收模糊图像输入和估计的模糊图像。自监督损失比较器112比较模糊图像输入和估计的模糊图像,以确定自监督损失并将自监督损失发送至损失优化器114。
损失优化器114从监督损失比较器110接收监督损失并且从自监督损失比较器112接收自监督损失。损失优化器114还可以接收权重系数以均衡监督损失和自监督损失。损失优化器114生成去模糊网络训练信号以改变去模糊网络。可以利用该改变来最小化经均衡的监督损失和自监督损失的混合损失。去模糊网络训练信号可以改变与去模糊网络102相关联的权重。光流网络104和模糊核估计器106也可以由去模糊网络训练信号改变。
在一些实施例中,未使用监督损失比较器110。损失优化器114可以接收自监督损失并生成没有监督损失的去模糊网络训练信号,但是使用监督损失和无监督损失来训练网络可以实现更好的结果。
可以根据图2中描绘的过程来操作去模糊训练系统100。参考图2,去模糊训练过程200接收输入模糊图像(框202)。输入模糊图像可以包括(例如)根据方程式1的三个时间上连续的图像。
然后将输入模糊图像去模糊为估计的清晰图像(框204)。根据方程式2可以进行去模糊过程。
其中,θd是去模糊网络的权重。可以使用诸如dvd或deblurgan的去模糊网络。可以为三个连续的模糊图像输入中的每一个产生估计的清晰图像。
然后估计光流(框206)。可以分别根据方程式3和4针对当前图像的先前图像和当前图像的随后图像二者从估计的清晰图像估计光流。
其中θf是光流网络的权重。可以使用诸如flownets的光流网络。可以将去模糊网络和光流网络视为相同整个网络的两个子网络,并且整体地训练整个网络,而不是分别训练两个子网络。
然后根据方程式5利用光流来生成像素级模糊核(框208)。
k(p)=k(ft-1→t(p),ft+1→t(p))方程式5
在优选实施例中,方程式5是可微分的。还可以利用图3中描绘的过程来估计像素级模糊核,因为这种估计是可微分的并且因此可以在神经网络中训练。根据方程式6,通过利用像素级模糊核来重新模糊当前清晰图像来生成估计的模糊图像(框210)。
距离函数(诸如均方误差(mse))用于将估计的模糊图像与输入模糊图像进行比较,并且根据方程式7来确定损失(框212)。
其中,
距离函数(诸如mse)用于将估计的清晰图像与地面实况图像进行比较,并且根据方程式8来确定损失(框214)。
其中,
s={ib;is}
根据方程式9确定混合损失(框216)。
l(θd)=ls(θd)+αlu(θd)方程式9
可以接收权重系数α以均衡损失的贡献。权重系数可以设置为0.1。然后所确定的损失改变去模糊网络d(框218)。可以利用该过程改变去模糊网络或去模糊网络的权重,直到损失最小化。
在一些实施例中,通过将估计的清晰图像与地面实况图像进行比较而确定的损失不用于训练去模糊网络。
参考图3,像素级模糊核估计过程300接收光流(框302)。光流可以由方程式3和4确定,并且方程式10可以用于确定模糊核k。
其中,
rl:x∈[0,τut+1→t(p)],y∈[0,τυt+1→t(p)]
r2:x∈[0,τut-i→t(p)i,y∈[0,τvt-i→t(p)]
并且τ是曝光时间。在一些实施例中,曝光时间可以是1。
因此,像素级模糊核估计过程300将光流映射到模糊核查找表以确定要在双线性插值中使用的权重ωi(框304)。然后使用双线性插值来确定模糊核(框306)。方程式11可用于执行双线性插值。
其中n是计算模糊核的光流范围。n的值可以设置为33×33,其在两个方向上利用-16到16个像素。然后,重新模糊器利用模糊核来重新模糊清晰的图像。
图4是计算系统400的一个实施例的框图,其中可以实现本发明的一个或更多个方面。计算系统400包括系统数据总线436、cpu426、输入设备430、系统存储器404、图形处理系统402和显示设备428。在可选的实施例中,cpu426、图形处理系统402的部分、系统数据总线436或其任何组合可以集成到单个处理单元中。此外,图形处理系统402的功能可以包括在芯片组或一些其他类型的专用处理单元或协同处理器中。
如图所示,系统数据总线436连接cpu426、输入设备430、系统存储器404和图形处理系统402。在可选实施例中,系统存储器404可以直接连接到cpu426。cpu426从输入设备430接收用户输入,执行存储在系统存储器404中的编程指令,对存储在系统存储器404中的数据进行操作,并配置图形处理系统402以执行图形管线中的特定任务。系统存储器404通常包括用于存储编程指令和数据以供cpu426和图形处理系统402处理的动态随机存取存储器(dram)。图形处理系统402接收由cpu426发送的指令并处理指令以在显示设备428上渲染和显示图形图像。
还如图所示,系统存储器404包括应用程序412、api418(应用程序编程接口)和图形处理单元驱动器422(gpu驱动器)。应用程序412生成对api418的调用以产生期望的一组结果,例如以图像序列的形式。应用程序412还将图像处理命令发送到api418以在图形处理单元驱动器422内进行处理。高级着色程序通常是高级编程指令的源代码文本,其被设计为操作图形处理系统402。api418功能通常在图形处理单元驱动器422内实现。图形处理单元驱动器422被配置为将高级程序转换为针对图像处理是最优化的机器代码程序。
图形处理系统402包括gpu410(图形处理单元)、片上gpu存储器416、片上gpu数据总线432、gpu本地存储器406和gpu数据总线434。gpu410被配置为经由片上gpu数据总线432与片上gpu存储器416通信并且经由gpu数据总线434与gpu本地存储器406通信。gpu410可以接收由cpu426发送的指令,处理该指令以渲染图形数据和图像,并将这些图像存储在gpu本地存储器406中。随后,gpu410可以在显示设备428上显示存储在gpu本地存储器406中的某些图形图像。
当如本文所述被操作为锐化图像时,gpu410包括一个或更多个逻辑块414。逻辑块414包括结合图1-3描述的处理功能中的一个或更多个,尤其是图形密集的功能,例如生成模糊核。cpu426还可以结合gpu410提供逻辑块的处理,以执行本文描述的图像处理和训练功能。例如,cpu426可以处理更多计算通用的(非图形密集的)过程特征,例如网络训练的各方面。
gpu410可以具有任何数量的片上gpu存储器416和gpu本地存储器406,包括没有,并且可以以任何组合使用片上gpu存储器416、gpu本地存储器406和系统存储器404用于存储器操作。
片上gpu存储器416被配置为包括gpu编程420和片上缓冲器424。gpu编程420可以经由系统数据总线436从图形处理单元驱动器422被传输到片上gpu存储器416。片上缓冲器424可用于存储需要快速访问以减少图形管线的延迟的帧数据。因为片上gpu存储器416占据了宝贵的裸晶面积,它相对昂贵。
gpu本地存储器406通常包括较便宜的片外动态随机存取存储器(dram),并且还用于存储gpu410所使用的数据和编程。如图所示,gpu本地存储器406包括帧缓冲器408。帧缓冲器408存储可用于驱动显示设备428的至少一个二维表面的数据。此外,帧缓冲器408可包括多于一个的二维表面,使得gpu410可渲染为一个二维表面,而第二二维表面用于驱动显示设备428。
显示设备428是能够发射对应于输入数据信号的视觉图像的一个或更多个输出设备。例如,可以使用液晶显示器或任何其他合适的显示系统来构建显示设备。通常通过扫描存储在帧缓冲器408中的图像数据的一个或更多个帧的内容来生成到显示设备428的输入数据信号。
实现方式和解释
本文,引用“一个实施例”或“实施例”不一定是指相同的实施例,尽管它们可以。除非上下文明确要求,否则在整个说明书和权利要求书中,词语“包括”、“包含”等应被解释为包含性意义而不是排他性或穷举性意义;也就是说,意味着“包括但不限于”。除非明确地限于单个或多个,否则使用单数或复数的词语也分别包括复数或单数。另外,当在本申请中使用时,词语“本文”、“以上”,“以下”和类似含义的词语作为整体而不是指本申请的任何特定部分来参考本申请。当声明使用“或”一词来引用两个或更多项目的列表时,该词语将涵盖对该词语的所有以下解释:列表中的任何项目,列表中的所有项目以及列表中的项目的任何组合,除非明确限于一个或另一个。本文未明确定义的任何术语具有其相关领域的技术人员通常理解的常规含义。
“逻辑”指的是机器存储器电路、非暂时性机器可读介质和/或电路,其通过其材料和/或材料-能量配置包括控制和/或程序信号,和/或设置和值(例如电阻、阻抗、电容、电感、电流/电压额定值等),其可用于影响器件的操作。磁介质、电子电路、电学和光学存储器(易失性和非易失性的)和固件都是逻辑的示例。逻辑特别排除纯信号或软件本身(但不排除包含软件从而形成其配置的机器存储器)。
该上下文中的“硬件”指的是体现为模拟电路或数字电路的逻辑。
该上下文中的“软件”是指实现为机器存储器(例如,读/写易失性或非易失性的存储器或介质)中的处理器可执行指令的逻辑。
该上下文中的“固件”是指体现为存储在只读存储器或介质中的处理器可执行指令的软件逻辑。
本文所公开的方法可以体现为硬件、软件或固件或其组合。例如,该方法可以实现为计算机系统、汽车、移动电话、相机或其他设备的逻辑。
- 还没有人留言评论。精彩留言会获得点赞!