一种结合卷积网络和递归网络的视频目标检测方法与流程
本发明涉及计算机视觉和视频图像处理领域,具体涉及一种结合卷积网络和递归网络的视频目标检测方法。
背景技术:
随着计算机视觉技术的进步,监控视频智能处理得到了学术界和工业界的广泛研究,视频目标检测作为视频监控的一个重要功能,一直是研究热点。视频目标检测常常采用背景建模的方式来分割前景目标。然而,当背景存在动态景观(如喷泉、颤动的树叶、波浪等),或者摄像机存在微小抖动(如大型车辆通过时造成振动、强风造成相机抖动等)等情况,传统的基于背景建模的视频目标检测方法常常遇到严重的困难。
近年来,深度学习技术的兴起给计算机视觉领域带来了广泛而深刻的影响,它使越来越多的视觉研究得到产业化应用,例如人脸识别、服装分类、车辆检测等等。深度学习网络主要有两种,一种是卷积神经网络(convolutionalneuralnetworks,cnn),网络主要结构是卷积层(convolutionallayer)和池化层(poolinglayer),具有非常强的信息抽象能力,主要用来进行图像特征的提取,另一种是递归神经网络(recurrentneuralnetworks,rnn),是一种具有内部状态的网络,适用于处理和预测时序数据。
基于以上分析,本发明提出了一种结合卷积网络和递归网络的视频目标检测方法。本发明致力于无缝集成卷积神经网络和递归神经网络,构建端到端的视频目标检测深度学习模型,发挥两种神经网络在单帧图像特征提取和多帧图像时序信号处理方面的优势,研究和探索出一种具有高可靠性和准确度的视频目标检测方法。
技术实现要素:
本发明为了提高视频目标检测系统的可靠性和准确度,提供了一种结合卷积网络和递归网络的视频目标检测方法。所发明的方法,其输入为多帧连续的视频图像序列,输出为一张黑白图像,视频目标为白色标记。本发明所述设计的结合卷积网络和递归网络的视频目标检测方法,包含以下步骤:
步骤s1,构建视频数据样本集,所述数据集中的每一个样本包含多帧连续视频图像;
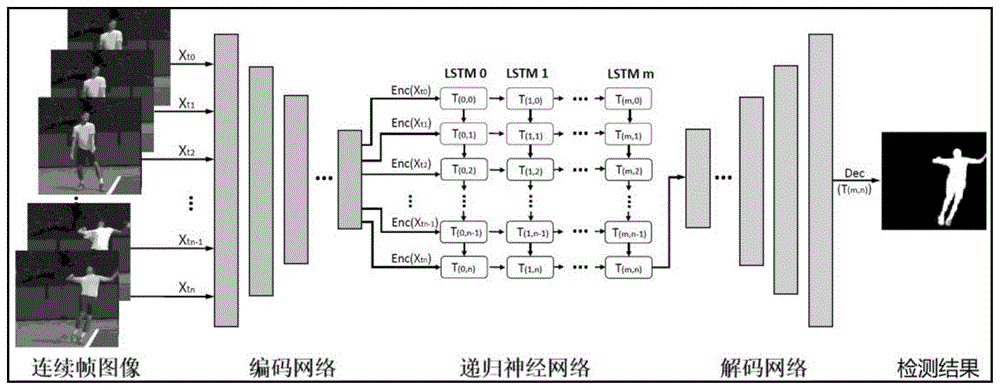
步骤s2,构建深度学习网络模型,该模型包括编码网络、递归神经网络和解码网络;
步骤s3,利用s1构建的视频数据样本集对步骤s2构建的深度学习模型进行训练;
步骤s4,利用步骤s3训练好的模型进行视频目标检测。
进一步地,所述步骤s1具体为:
步骤s1-1,采集m个图像序列,每个序列包含l帧连续的视频图像;对每个序列的最后一帧图像(即第l帧图像)标注视频目标的真值,得到标签;
步骤s1-2,为了适应不同帧率条件的视频目标检测,对上述每个图像序列进行多步长等间隔采样,步长分别为1,2,和3,从而每个图像序列可以生成3个数据样本,使每个样本包含n帧图像;
步骤s1-3,经过上面两步的处理,得到3×m个数据样本,每个样本包含n帧图像,并且第n帧标注有视频目标真值;将3×m个样本作为视频数据样本集。
更进一步地,所述n大于等于5。
进一步地,所述构建深度学习网络为一个端到端网络。
进一步地,所述编码网络为全卷积网络,包含卷积层和池化层。
进一步地,所述递归神经网络为卷积长短时记忆神经网络。
进一步地,所述解码网络为全卷积网络,包括反卷积层和卷积层。
本发明还包括一种电子设备,其特殊之处在于,包括:
一个或多个处理器;
存储装置,用于存储一个或多个程序;
当一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上所述的结合卷积网络和递归网络的视频目标检测方法。
本发明还包括一种计算机可读介质,其上存储有计算机程序,其特殊之处在于:所述程序被处理器执行时实现如上所述的结合卷积网络和递归网络的视频目标检测方法。
本发明的优点:
1.本发明创新性地构建了一个端到端的深度学习网络,它由编码网络、递归神经网络和解码网络组成,编码网络和解码网络为全卷积网络,能发挥卷积神经网络对单幅图像信息抽取的能力,而递归神经网络能高效处理时序的多帧图像数据;将两种类型网络无缝地集成,实现了高可靠性和高准确度的视频目标检测,有效克服由背景动态景观和相机抖动带来的影响。
2.本发明在构建图像数据集时,采用了多步长的等间隔采样策略,使得训练样本包含不同帧率拍摄条件下的数据,大幅提高了所发明方法对不同视频帧率的适应性。
附图说明
图1是本发明实施例的深度学习神经网络总体架构图。
图2是本发明的系统流程图。
具体实施方式
传统的视频目标检测方法在面对背景动态景观、相机抖动等情况时,检测效果差。本发明提出一种结合卷积网络和递归网络的视频目标检测方法,利用深度学习构建视频目标分割模型,实现高可靠性和高准确度的视频目标检测。
本发明提供的方法设计了一种新型的深度学习网络模型,其总体结构参见图1。其具体实施例包含以下步骤:
步骤s1,构建视频数据样本集,所述数据集中的每一个样本包含n帧连续视频图像。具体实施过程说明如下:
步骤s1-1,采集m个图像序列,每个序列包含l帧连续的视频图像;对每个序列的最后一帧图像(即第l帧图像)标注有视频目标真值,得到标签。
步骤s1-2,为了适应不同帧率条件下的视频目标检测,对上述每个图像序列进行等间隔采样,间隔距离为1,2,和3,从而每个图像序列可以生成3个数据样本,使每个样本包含n帧图像。
步骤s1-3,经过上面两步的处理,得到3×m个数据样本,每个样本包含n帧图像,并且第n帧有标注的视频目标真值;将3×m个样本作为视频数据样本集。
优选地,取m=10000,l=13,n=5,则每个图像序列分别进行间隔为1,2,3的采样后,得到对应的三个数据样本的图像帧下标为[9,10,11,12,13],[5,7,9,11,13],和[1,4,7,10,13]。
步骤s2,构建深度学习网络模型,该模型包括编码网络、递归神经网络和解码网络;编码网络为全卷积网络,包含卷积层和池化层;递归神经网络采用卷积长短时记忆网络(convlstm);解码网络为全卷积网络,包含反卷积层和卷积层;具体的步骤为:
s2-1,将连续的n帧图像依次输入编码网络,输出n个特征向量;
s2-2,将上一步得到的n个特征向量作为n个时序信号输入卷积长短时记忆网络,输出为一个特征向量;
s2-3,将上一步得到的1个特征向量输入解码网络,输出一张视频目标的概率图,该图与原原始输入图像尺寸相同。
进一步的,所述步骤s2中编码网络包含16层,第1层为输入层,由n帧连续视频图像构成,第2、3层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为64,第4层为池化层,池化尺寸是2×2,第5、6层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为128,第7层为池化层,池化尺寸是2×2,第8、9层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为256,第10层为池化层,池化尺寸是2×2,第11、12层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为512,第13层为池化层,池化尺寸是2×2,第14、15层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为512,第16层为输出层。
优选地,池化层采用最大值池化法;
进一步地,所述步骤s2中长短期记忆网络采用双层结构;
进一步地,所述步骤s2中解码网络包含15层,第1、2层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为512,第3层为反卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为512,第4、5层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为256,第6层为反卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为256,第7、8层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为256,第9层为反卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为128,第10、11层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为128,第12层为反卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为64,,第13、14层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数均为64,第15层是卷积层,卷积核大小是3×3,步长为1,卷积核的个数为1,即输出视频目标概率图。
进一步地,采用加权交叉熵作为模型的损失函数εloss,其定义为:
其中ω={1,2…k},为类别标签的集合,l(x)∈{1,2…k},表示像素x对应的真实类别标签,p(x)表示预测值,而w(x)表示x对应类的权重。
步骤s3,利用s1构建的视频数据样本集对步骤s2构建的深度学习模型进行训练;
进一步地,网络的输入为n张连续的图像序列,输出为第n帧图像中视频目标的概率图,其中,像素点越接近1(白色)则代表此处为视频目标的概率越大,反之越接近0(黑色)则代表此处为视频目标的概率越小。
步骤s4,利用步骤s3训练好的深度学习模型,输入的n帧连续的视频图像,检测得到其中第n帧图像包含的视频目标。
本发明的优点:
1.本发明创新性地构建了一个端到端的深度学习网络,它由编码网络、递归神经网络和解码网络组成,编码网络和解码网络为全卷积网络,能发挥卷积神经网络对单幅图像信息抽取的能力,而递归神经网络能高效处理时序的多帧图像数据;将两种类型网络无缝地集成,实现了高可靠性和高准确度的视频目标检测,有效克服由背景动态景观和相机抖动带来的影响。
2.本发明在构建图像数据集时,采用了多步长的等间隔采样策略,使得训练样本包含不同帧率拍摄条件下的数据,大幅提高了所发明方法对不同视频帧率的适应性。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!