一种左右递归新词发现方法与流程
本发明属于搜索引擎技术领域,来源于词法分析和快速检索的构建和使用实践。本发明既可以用于通用商业数据的高效分类和检索又可以作为公安、军事等特殊领域的专业分检。
背景技术:
随着各个行业信息化的快速发展,当今各个垂直领域的数据越来越多,而其中有很多数据是无用的,不需要特殊处理。
如何快速、高效从垂直领域内的海量数据中检索、智能挖掘出有用的信息成为现在智能搜索引擎发展的一大难题。随着搜索引擎技术的发展,出现了各种各样的搜索引擎技术,但绝大部分搜索引擎技术针对特殊领域中的特殊术语和特殊表达方式不能进行有效的检索和智能推荐,所以现有的搜索引擎技术不能满足当前行业的需求,这就促进了分布式智能搜索引擎的发展。
针对垂直领域往往会出现很多特定的专业词汇以及新词汇,对于这些词汇,现有词典中是没有的,如果语料中包含了这些词汇,那么词法分析逻辑处理模块处理时将会造成一定的误差。所以需要针对这些专业词汇、新词汇进行自动化的搜集功能,并把这些词汇加入到词库中构建出该垂直领域的特殊词库,这样就能提高搜索引擎中词法分析逻辑处理模块的处理效率、精度,从而提高搜索引擎的搜索效率、精确度。
一般而言,当数据进入分布式搜索引擎时,同时也进入新词词库构建流程,对输入语料数据进行新词发现,如果发现的新词没有在现有词库中出现过,就把这个新词加入到新词词库。
现有的新词发现方法一般是采用基于规则的新词发现或者基于统计的新词发现。最早采用的新词发现方法都是采用的基于规则的新词发现方法,它通过研究新词的内部构造规则和外部构造规则来形成对应的规则库,以此规则库为准则来发现新词。而基于统计的新词发现方法是通过找到长度不大于n的所有词汇,对这些词汇进行词频、互信息的计算,如果计算指标满足预先设定的指标阈值就作为新词。
在新词发现方法中,前述两种方法都各有利弊。基于规则的方法,新词发现的准确度、效率都相对较高,但在规则库的创建上需要耗费大量的人力去进行规则提取,随着语言的发展,规则库需要不断的更新,因此该方法不是自适应的,扩展性不好;基于统计的方法,新词发现的过程是自动化的,但这种方式会发现很多词频较高的垃圾串,而且不能发现长度非常长的新词,例如,少数民族人名、音译名。
通过对各种新词发现技术的调研,发现当前大部分的新词发现方法都是基于窗口的模式去发现新词,这种模式使得长度较长的新词不能被发现。我们发明一种基于左右递归的新词发现方法,在进行新词发现时,大大提高了新词发现的准确度。利用这种新词发现方法可以很方便地建立高准确度的自适应垂直领域词典,并且随着数据量的增加,词典越来越健全。针对特殊的领域,可以大幅度提高索引数据时分词的准确度。
通过一种左右递归新词发现方法能够有效解决现有方法面临的上述问题。
技术实现要素:
本发明公开了一种左右递归新词发现方法。一种左右递归新词发现方法由语料预处理、位置集合计算、集合遍历、收纳性判断、词频计算、左递归、右递归、合并八个步骤组成。
下面具体设计这种左右递归新词发现方法:
一种左右递归新词发现方法按照三个指标评定一个新词,即词频、互信息、信息熵。
(1)词频
统计词汇在语料中出现的频率,出现的频率越高就越可能是新词,当词频达到某个阈值就认为可能成为一个新词,计算公式如下:
其中,N(X)表示字符串X出现的次数;N表示语料的总字数。
(2)互信息
互信息是最早出现在信息论中的信息度量指标,标识了一个事件集合与另一个事件集合关系的信息量。两个事件集合之间的互信息越大就表明相关性越大,反之越小。互信息作为计算语言学模型分析的常用方法,由于它对特征词和分类之间关系的性质没有任何限制,所以互信息常常用于文本分类的特征和类别的配准。
在新词发现方法中,利用互信息能够发现字符串与字符串之间的一个关联程度,字符串X,Y互信息的计算公式如下:
其中,X、Y表示字符串或者单字;p(XY)表示字符串X和字符串Y在输入语料中同时出现的概率;p(X)和p(Y)分别表示字符串X在输入语料中出现的概率和字符串Y在输入语料中出现的概率。
举例说明:如果在3000万字的语料中,“飞机场”出现了215次,出现的概率约为7.1667×10-6;“飞机”出现了2899次,出现的概率约为9.6633×10-5;“场”出现了5384次,出现的概率约为1.7947×10-4。理论上如果“飞机”和“场”之间毫无关系,“飞机场”出现的概率应该为9.6633×10-5×1.7947×10-4,约为1.7345×10-8。但是,实际值却是理论值的约5571倍,这表明“飞机”和“场”搭配到一起不是偶然拼在一起的,而是两个字符串有某种必然的联系。不过“飞机场”也可能是由“飞”和“机场”组合的,所以在新词发现技术中,我们常常使用平均互信息来衡量字符串的互信息,平均互信息如下:
其中X1,X2,…,Xn表示字符串或者单字;p(X1,X2,…,Xn)表示字符串X1,X2,…,Xn在输入语料中同时出现的概率。
(3)信息熵
信息熵表示信息量的多少,其中,信息量随着信息熵的增大而减小。信息熵的计算公式如下:
其中,p(Xi)表示事件Xi发生的概率。
在新词发现技术中,我们用信息熵来衡量一个字符串的左邻集合和右邻集合的随机性,随机性越高成为新词的可能性就越大。例如“我爱吃重庆火锅,我爱看重庆美女。”这段语料中,“重庆”出现了2次,它的左邻集合为{吃,看},它的右邻集合为{火,美},根据信息熵计算方法,我们可以得到:
在新词发现方法中,计算某个字符串的信息熵,我们一般采用左右平均信息熵来衡量该字符串的自由度,计算方法如下:
其中,HL(X)表示字符串X的左信息熵;HR(X)表示字符串X的右信息熵。
现有新词发现技术存在无法发现长度较长的新词、发现一些垃圾串等问题,而本方法可以有效地解决这些问题。
(1)输入预料预处理
由于输入的语料往往存在格式不规范,或者中英文语料中包含一些没有用的垃圾串,这对新词发现造成了很大的干扰使得对新词指标的计算存在误差。本方法针对输入的语料进行文本预处理,主要步骤如下:
第一步:通过正则过滤,删除了语料中包含的Html标签、Xml标签等与文本无关的特殊标签。
第二步:对语料中的符号进行全角转半角操作,中文繁体转简体操作以及规范首行等操作。
第三步:删除语料中多余的空格、换行符、制表符等空白符号。
第四步:删除语料中包含的特殊符号,包括ASCII编码、特殊编码、乱码等与文本无关的特殊符号。
第五步:删除文本中的非文本数据,包括图片、声音、视频等数据。
第六步:通过断句标志,即“。”、“!”、“?”、“…”、“;”、空格、换行符等将语料切分成一个一个的句子。如果句中包含对称的符号,例如引号、书名号等则要求左右匹配。最后还需要把分好的句子进行编号。
第七步:为了避免语料中大量完全相同的句子对新词指标的计算造成误差,针对步骤四中分好的句子进行Hash求值,对Hash码完全相同的句子进行去重,避免输入语料中出现大量完全相同的句子或者段落。
一种左右递归新词发现方法采用的预处理技术可以使语料规范、准确、有意义的,很大情况下避免了因为语料本身的缺陷、误差造成的错误指标计算,提高了新词发现的准确性。
(2)新词分类设计
一种左右递归新词发现方法根据实体名词、派生词、缩略词、复合词和数字组合词对新词进行分类设计。在新词发现中,针对中文语料的处理要比英文语料的处理困难,这是由于中文的语法规则特别的复杂。英文的词语之间是直接可以用空格分开的,这使得新词的发现就很简单,只需要利用空格进行分词,在对分好的词与词库进行匹配就可以了;在词汇的形态变化上,英文词汇虽然变化较为复杂但全部都是规则化的变换,而中文的变换是没有规律可循的;中文是有严格词序的,不同的词序代表了完全不同的意思,比如“不完全认同”和“完全不认同”就代表了截然不同的意思;中文中对于虚词的使用是非常广泛的,通过研究表明“的”和“了”字的使用频率高达3%-5%,所以在进行新词发现时,往往会把“属丝”这个新词发现为“屌丝的”;中文中的汉字是一个比较稳定的集合,尽管汉字组成的词汇是千变万化的,但是很少会有新的汉字出现,所以这是对中文的新词发现比较有利的一点。综上所述,中文的语言特点相对于其他语言的特点是完全不同的,我们必须找到专门的信息处理方法和规则才能有效的提高中文新词发现的准确度。
一种左右递归新词发现方法主要针对现有词库中不包含的词汇进行发现,经过研究表明大部分新词主要分为以下五大类:
第一类是实体名词:主要包括了人名、地名、组织名,其中人名根据特点的不同又分为了汉族人名、少数名族人名、英译人名等。实体名词是本方法发现的主要词汇之一。
第二类是派生词:主要是指根据已有的词汇添加特定的后缀形成的新词,比如“老年化”,在进行新词发现时,本方法可以发现一些类似的派生词。
第三类是缩略词:这种词汇主要针对一些非常长的词汇,这些词汇使用其中的某几个字代表该词,例如“中国国家足球队”的缩略词为“国足”、“美国男子职业篮球联赛”的缩略词为“NBA”。
第四类是复合词:这种词汇主要由动词、名词等组合而成,通过两个或两个以上词的合并而形成,例如“软件工程”、“中国重庆沙坪坝区重庆大学A区”,前者就是两个名词组合成的词汇,后者则是由“中国”、“沙坪坝区”、“重庆大学”、“A区”多个地名词组合成的词汇。
第五类是数字组合词:这种词汇是通过对数字、日期、电话号码、编码等组合而形成的词汇。
针对以上提到的规则,我们设计了相关的规则库。规则库中的规则既可以自动添加也可以手工追加。随着规则库中规则的增加,新词发现就越来越准确。
由于规则和规则之间,有时候存在排斥关系,本方法采取了优先级排序策略,当规则与规则冲突时就利用优先级进行规则的选择。
(3)新词评定指标设计
新词评定指标为词频、互信息以及信息熵。词频表明了字符串出现的次数,只有词频到达阈值后,我们才会考虑这个字符串可能是一个新词。如果仅仅是看字符串出现的次数还是不够的,例如“的电影”出现了492次,“电影院”出现了323次,“的电影”出现的频次是大于“电影院”出现的频次的,但我们更倾向于“电影院”作为一个词,因为我们感觉“电影”和“院”的凝固程度比“的”和“电影”的凝固程度更大,所以当词频达到阈值后,我们还需要用互信息来表明词的内部凝固程度。如果我们只是通过词频、互信息两个指标来判断是否为新词,这还是不够的,我们还需要用信息熵来看它外部的表现。例如“世纪”和“事迹”两个字符串,我们只可以说“上世纪”、“下世纪”、“本世纪”等有限几个,可见“世纪”这个字符串左邻集合很小,所以我们更倾向“上世纪”、“下世纪”、“本世纪”作为一个新词;而对“事迹”这个字符串,我们可以说“辉煌事迹”、“优秀事迹”、“人物事迹”、“候选人事迹”等等很多,它的左邻集合非常大,所以我们可以直接把“事迹”作为一个新词。信息熵衡量了一个字符串的自由运用程度,如果一个字符串的左邻集合和右邻集合越大,那么这个字符串就更有可能作为一个新词。计算出字符串的左信息熵和右信息熵之后,再根据左信息熵或右信息熵进行左递归或右递归的计算。
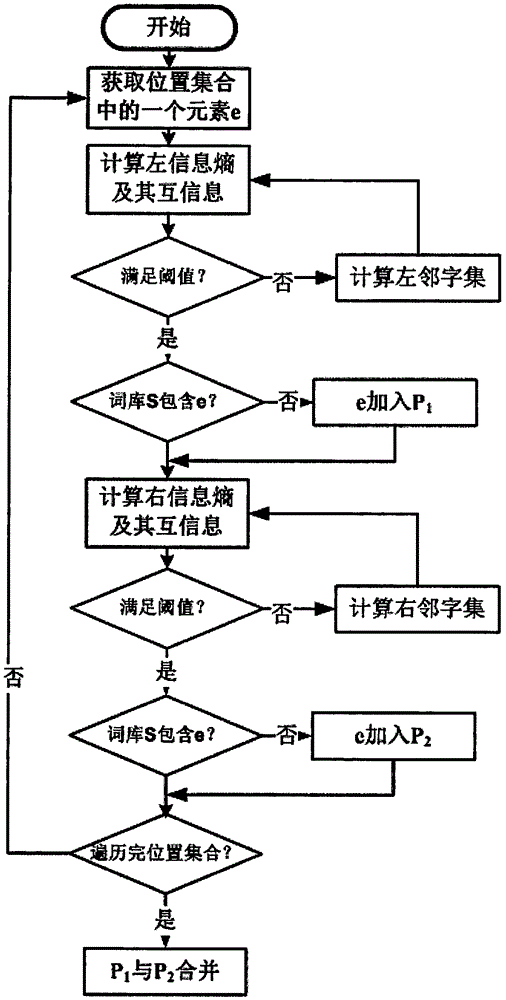
一种左右递归新词发现方法可以发现任何长度的新词,其步骤如下:
步骤一:语料预处理。具体参见前述步骤。
步骤二:位置集合计算,即计算:
其中w1,w2,…,wm表示输入语料中出现过且互不相同的字;(wi,POSi)表示一个集合而是该集合的一个元素,表示第i个字wi在输入语料中第j次出现的位置;表示第i个字wi在位置出现过。
例如,针对语料“我是中国人,我爱中国”那么集合W为{(‘我’,{0,6}),(‘是’,{1}),(‘中’,{2,8}),(‘国’,{3,9}),(‘人’,{4}),(‘爱’,{7})}。位置集合W记录了每个字出现的位置;
步骤三:集合遍历,即遍历集合W,依次取出每个字wi,即word=wi,i=i+1。
步骤四:收纳性判断,即判断word是否满足规则库收纳规则的要求,如果不满足,跳回步骤三,如果满足进行步骤五。收纳性是指新词是否符合新词分类标准,新词分类标准包括实体名词、派生词、缩略词、复合词、数字组合词。针对这五类词,我们设计了相应的规则库,规则库中的规则既可以自动添加也可以手工追加。因此在进行收纳时,要按照这五种类型进行。
步骤五:词频计算,即计算word出现的频次,如果小于阈值,跳回步骤三,如果大于阈值则进行步骤六。
步骤六:左递归,即针对word执行左递归,记为createPrefixTree(word,W),得到左递归新词集合P1,其具体又分为以下几步:
a.通过W计算出word的左信息熵和互信息,如果左信息熵和互信息满足阈值要求,则进行步骤b;如果左信息熵和互信息不满足阈值要求,则进行步骤c;
b.若已有词库S中不包含word,则把word加入到新词集合P1;判断集合W是否遍历完,若没有遍历完,则跳回步骤三,反之,进入步骤七;
c.计算word的左邻字集pre{pre1,pre2,…,prek}:
步骤七:右递归,即针对word执行createSufTree(word,W),得到右递归新词集合P2。
a.通过W计算出word的右信息熵和互信息,如果右信息熵和互信息满足阈值要求,则进行步骤b;如果右信息熵和互信息不满足阈值要求,则进行步骤c;
b.若现有词库S中不包含word,则把word加入到新词集合P2;判断集合W是否遍历完,若没有遍历完,则跳回步骤三,反之,进入步骤八;
c.计算word的右邻字集suf{suf1,suf2,…,sufk}
步骤八:合并,即计算集合P1和集合P2的交集得到发现的新词集合P3。
附图说明
以下参考附图是对本发明的结构和工作流程进行说明,其中:
图1 是一种左右递归新词发现方法的流程图
图2 是输入语料预处理框图
图3 是左递归流程图
图4 是右递归流程图
具体实施方式
下面结合附图来对本发明所述的“一种左右递归新词发现方法”的实施方式作进一步的说明。
(1)输入语料预处理
输入语料预处理涉及到正则过滤、半角转换、空白符号删除、特殊符号删除、非文本符删除、切分句子和Hash去重七个步骤。
输入语料预处理涉及的几个步骤可以互换,本方法提供了其中一种实施方法作为验证,即按照正则过滤、半角转换、空白符号删除、特殊符号删除、非文本符删除、切分句子、Hash去重的顺序进行输入语料预处理。其中:正则过滤的作用是删除语料中包含的Html标签、Xml标签等与文本无关的特殊标签;半角转换是对语料中的符号进行全角转半角操作、中文繁体转简体操作以及规范首行操作;空白符号删除是删除语料中多余的空格、换行符、制表符;特殊符号删除是删除语料中包含的ASCII编码、特殊编码、乱码;非文本符删除是删除文本中的非文本数据;切分句子是通过断句标志,即“。”、“!”、“?”、“…”、“;”、空格、换行符将语料切分成一个一个的句子,如果句中包含对称的符号,例如引号、书名号等则要求左右匹配,最后还需要把分好的句子进行编号;Hash去重是对分好的句子进行Hash求值,对Hash码完全相同的句子进行去重。
这种预处理技术可以使语料规范、准确、有意义的,避免了因为语料本身的缺陷、误差造成的错误指标计算。
(2)新词发现方法
本新词发现方法基于左右递归,可以有效的发现少数名族人名、英译人名、英译地名等字符串长度很长的新词。它的基本流程是:从位置集合中任取一个元素,记为e,首先计算它的左信息熵和互信息,然后与阈值比较,若左信息熵和互信息大于等于阈值并且词库S中没有包含e,就将e加入词库P1;若左信息熵和互信息小于阈值则计算e的左邻字集,然后再计算左邻字集,并针对左邻字集中每个元素的左信息熵和互信息并作进一步阈值判断和是否加入词库P1的判断,符合条件则加入,否则递归进行计算。同理进行右递归,并将符合条件的新词加入词库P2中。最后,求P1和P2的交集,即可得到最终的新词集合。
我们具体实施了新词发现方法,采用的是百度百科200篇以“电影”为主题的真实文章作为实验数据。在这200篇文章中频繁地出现了少数名族人名、音译人名、音译地名等词语。
具体实施步骤如下:
①使用现有的新词发现方法对这200篇文章进行新词发现,记录发现的新词,并计算出正确率、召回率和F值。
②使用本新词发现方法对这200篇文章进行新词发现,记录发现的新词,并计算出正确率、召回率和F值。
③针对现有的新词发现方法和本新词发现方法的新词发现结果做对比和分析。
实验结果与分析
表1新词发现方法结果对比
从表1看出在窗口大小设为4的情况下传统的新词发现方法只能发现字符串长度不超过4的新词,可以明显的看出“妮丝·帕”、“莱昂纳多”、“里弗”、“速度与激”、“汉弗莱”等词只是新词的一部分,由于现有的新词发现方法发现出的新词与窗口设定的大小息息相关,新词的长度不能超过窗口的大小;而本新词发现方法是基于左右递归的新词发现方法,它发现的新词不受字符串的长度限制。
我们采用了正确率(precision)、召回率(recall)和F值(F-measure)三个指标来对新词发现结果进行评判,其中
正确率计算公式如下:
召回率计算公式如下:
F值计算公式如下:
在以上公式中,n1代表了正确识别出的新词个数;n2代表了识别出的词串的总个数;n3代表了语料中新词的总个数。
表2各个指标评测结果
如表2各个指标评测结果所示,我们的新词发现方法对于长度较长的新词发现效果有显著提高,在其他指标方面,我们的方法提高。
(3)左递归方法
左递归的实施如下:
首先获取从位置集合中任取一个元素,记为word;
接着根据公式(4)及其示例计算word的左信息熵;
第三,根据预设的信息熵阈值,检测计算出的左信息熵是否满足阈值,若不满足则计算word的左邻集合。并在左邻集合中任取一个元素pre,将pre与word组合成pre+word返回上一步重新计算左信息熵,并再次做判断,以此类推;
第四,如果计算出的左信息熵满足阈值,则根据公式(2)和(3)计算互信息;
第五,根据预设的互信息阈值,检测计算出的互信息是否满足阈值,若不满足则计算对应的左邻集合,并在左邻集合中任取一个元素pre,将pre与word组合成pre+word返回上一步重新计算左信息熵,并再次做判断,以此类推;
第六,如果计算出的互信息满足阈值,则判断word或者pre+word是否已经存在于词库,如果没有存在则加入词库P1,如果存在则从位置集合中再取出一个新的word,重复进行前述步骤。
(4)右递归方法
右递归的实施如下:
首先从位置集合中任取一个元素,记为word;
接着根据公式(4)及其示例计算右信息熵;
第三,根据预设的信息熵阈值,检测计算出的右信息熵是否满足阈值,如不满足则计算word的右邻集合,并在右邻集合中任取一个元素suf,将word与suf组合成word+suf返回上一步重新计算右信息熵,并再次做判断,以此类推;
第四,如果计算出的右信息熵满足阈值,则根据公式(2)和(3)计算互信息;
第五,根据预设的互信息阈值,检测计算出的互信息是否满足阈值,若不满足则计算对应的右邻集合,并在右邻集合中任取一个元素suf,将word与suf组合成word+suf返回上一步重新计算右信息熵,并再次做判断,以此类推;
第六,如果计算出的互信息满足阈值,则判断word或者word+suf是否已经存在于词库,如果没有存在则加入词库P2,如果存在则从位置集合中再取出一个新的word,重复进行前述步骤。
- 还没有人留言评论。精彩留言会获得点赞!