一种基于图像处理的鸟鸣声特征强化方法与流程
本发明涉及图像处理、深度学习和鸟类识别技术领域,特别是涉及一种基于图像处理的鸟鸣声特征强化方法。
背景技术:
生物多样性是人类赖以生存的条件,是社会可持续发展的战略资源,是生态安全和粮食安全的重要保障。由于分布范围广、研究资料齐全和对环境的敏感性,鸟类是生物多样性的重要指示类群。掌握鸟类种群现状及其动态变化信息,对保护和评估生态系统都具有重要意义。鸟类鸣声多种多样,包含了重要的行为意义、物种特异性和丰富的生物学信息,同时也是对其进行物种识别的主要手段。鸟鸣声的分类学意义,目前已成为鸟声研究与鸟类系统分类学研究交叉的热点。
生物频谱作为声景观生态学理论分析的重要组成部分,是监测、研究和分析生态系统多样性的重要途径。利用适当的方法对其进行分析能够充分展现声音的时频特性,从而有效地识别出生物的差异性。鸟鸣声谱图作为研究鸟的物种属性的重要途径,其频谱分析对鸟类多样性监测至关重要。
深度学习是目前机器学习学科发展最蓬勃的分支,也是整个人工智能领域中应用前景最为广阔的技术。随着深度学习在计算机视觉领域的不断突破,运用其处理图像识别任务已成为一种高效且专业的技术。在该技术背景的支持下,本发明结合鸟鸣声特性,对鸟鸣声谱图进行了针对性的处理。
技术实现要素:
本发明旨在提供一种基于图像处理的鸟鸣声特征强化方法,以解决现有技术在识别过程中的鸣声特征不突出、噪声干扰严重和生物频谱信息不全面的问题。
为实现上述目的,本发明的技术方案为:
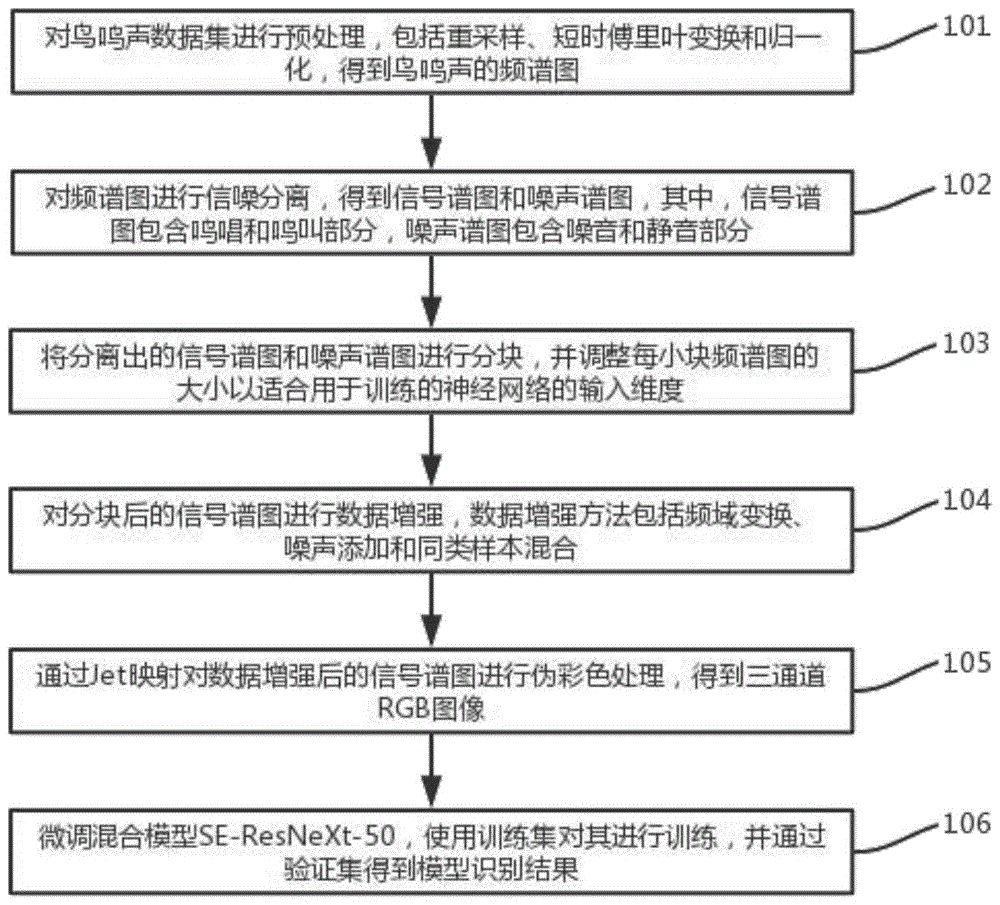
具体地说,一种基于图像处理的鸟鸣声特征强化方法包括以下步骤:
①对鸟鸣声数据集进行预处理,包括重采样和归一化,得到鸟鸣声的频谱图;
②对频谱图进行信噪分离,得到信号谱图和噪声谱图;其中,信号谱图包含鸣唱和鸣叫部分,噪声谱图包含噪音和静音部分,信号谱图作为原始训练样本,噪声谱图用于背景噪声增强的一种途径;
③对步骤②中信噪分离后的所有频谱图进行分块,并调整每小块频谱图的大小以适合用于训练的神经网络的输入维度;
④对步骤③中分块后的信号谱图进行数据增强,由于频谱图不同于传统图像,之间的差异限制了广泛的图像处理技术的直接应用;综合考量鸟鸣声和频谱图的特性,本数据增强处理特别方法包括频域变换、噪声添加和同类样本混合:
⑤为增强灰度图像的视觉感知力,同时方便对不同的神经网络进行迁移学习,通过jet映射对数据增强后的灰度图像进行伪彩色处理,得到三通道rgb彩色图像,将这些三通道rgb彩色图像分为训练集和测试集,其中训练集占80%,测试集占20%;
⑥通过迁移学习方式,选取合适的神经网络模型,对其进行微调并使用步骤⑤中的训练集进行训练,最终通过验证集验证模型准确率,得到识别结果。
相较于现有技术,本发明的有益效果是:
①针对自然复杂声学环境下基于鸟鸣声的物种分类问题,提出一种基于图像处理的鸟鸣声特征强化方法;缓解了鸟鸣声在识别过程中的背景噪声高、鸣声特征不突出、鸣声数据不平衡和生物频谱信息不全面等问题,用于高效地进行鸟类自动识别;
②通过将一维时域的鸟鸣声信号转换为二维时频域的生物频谱信息,再灵活运用一系列图像处理的方法突显频谱图中的鸟鸣声特征,增强生物频谱信息的可视化呈现,并能通过深度学习的方法得以验证;
③图像处理包括:鸟鸣声信噪分离、特异性数据增强和视觉感知力增强;本发明区别于一般可视化任务的图像分类方法,始终围绕各个识别环节中鸟鸣声特征的呈现,做出针对性强的图像处理策略,为深度学习在鸟类自动识别领域的探索更进一步。
附图说明
图1为本方法的流程图。
具体实施方式
一、方法
1、鸟鸣声信噪分离
步骤②对频谱图进行信噪分离,得到信号谱图和噪声谱图;
信号谱图的分离方法为:设定一个阈值n,如果频谱图中某个像素值高于相应行及其相应列的中值的n倍,则将其置为1,否则置为0;
噪声谱图的分离方法为:设定一个阈值n(n<n),如果某个像素值高于相应行及其相应列的中值的n倍,则将其置为0,否则置为1。
2、特异性数据增强
步骤④对分块后的信号谱图进行数据增强,包括频域变换、噪声添加和同类样本混合;
a、频域变换
a、对原始鸟鸣声音频的音高进行随机改变,变动幅度不宜超过5%,然后重复步骤①②③;
b、对原始鸟鸣声音频的音量进行随机改变,变动幅度不宜超过5%,然后重复步骤①②③;
b、噪声添加
a、将随机高斯噪声添加到步骤②中的信号谱图,并重新标准化得到的图像;
b、将步骤②中的噪声部分随机添加到步骤②中的信号谱图,作为训练样本;
c、同类样本混合
对同一种鸟的不同音频信噪分离后的信号谱图进行随机混合。
3、视觉感知力增强
为进一步增强灰度图像的视觉感知力,同时考虑到迁移学习对模型输入前数据维度的限定,通过jet映射进行伪彩色处理,增加不同强度区域之间的对比度以提高识别性能。不同区域分别映射成红、绿、蓝三个单色图像,并对应高、中、和低功率频谱信息,红色表示最高能量的声音特性,近似为鸣唱/鸣叫特性。
根据上述鸟鸣声频谱图的图像处理方法,选取混合模型se-resnext-50进行迁移学习可以从大量鸟鸣声谱图中得到精确高效的识别结果。
二、实施例
本方法是将一维时域的鸟鸣声信号转换为二维时频域的生物频谱信息,再灵活运用一系列图像处理的方法突显频谱图中的鸟鸣声特征,相较于一般通用的图像识别方法,本发明更具针对性和识别高效性。
实验数据来源于xeno-canto数据库,该数据库大多数音频文件采样率为44.1khz,16bit,单声道,也作为前期数据格式的统一标准。
①对已知的鸟鸣声数据集进行预处理,重采样为44.1khz采样率,使用具有汉宁窗函数的短时傅里叶变换(stft)计算鸟鸣声的频谱图,并对频谱图进行最大值归一化,使频谱信息的动态范围映射到[0,1]范围内,然后将频谱图处理为灰度图像。
②对频谱图进行信噪分离:信号谱图包含鸣唱和鸣叫部分,噪声谱图包含噪音和静音部分;大多数的鸟鸣声音频中,前景鸟鸣声信号的幅度高于背景噪声;我们利用这一规律降低背景噪声以分离出信号谱图:设定一个阈值n,如果频谱图中某个像素值高于相应行及其相应列的中值的n倍,则将其置为1,否则置为0。这种做法近似凸显了频谱图中所有重要的鸟鸣声信号,因为高振幅通常对应于鸟类的鸣唱或鸣叫;同时不同频率区域中的噪声水平得到补偿和缩减,由不可控因素的背景噪声所造成的宽带失真被衰减;
对于该步骤产生的背景噪声,应用二进制腐蚀和膨胀滤波器来消除噪声和连接段,或结合部分图像形态学处理的手段;
对于噪声谱图的分离,我们遵循相似的步骤:设定一个阈值n(n<n),如果某个像素值高于相应行及其相应列的中值的n倍,则将其置为0,否则置为1;与信号谱图的分离步骤之所以采用不同的阈值,是因为阈值n已经是为了凸显信号部分适当做出的过量选择,我们希望为此提供一个安全的缓减余地,处在该缓冲区的信号既不具备清晰的鸣声特征,也不影响后续用于进行数据增强的噪声部分的信息量;
综上,未被选为信号或噪声谱图的所有内容几乎不向后续的神经网络提供任何有效信息。
③对信噪分离后的信号谱图和噪声谱图进行分块,考虑到后续迁移学习用到的神经网络模型,将每一块裁剪到299×299像素;
④对分块后的灰度谱图进行数据增强,数据增强技术能够缓解数据集中普遍存在的部分鸟鸣声数据稀少和不同鸟类之间出现数据严重失衡的情况;而且通过丰富训练数据集,能够减轻模型训练过程中的过拟合,增强模型的泛化能力;不同于普通图像的常用数据增强手段,针对鸟鸣声的频谱图的时频特性,本发明采用如下技术进行数据增强:
(1)频域变换:包括对输入的原始鸟鸣声音频的音高和音量进行随机改变,变动幅度不超过5%;
(2)噪声添加:噪声包括噪声样本和随机高斯噪声;在步骤②的时候,鸟鸣声被分成信号谱图和噪声谱图,可以随机选择噪声部分的样本,将其添加到信号谱图的训练样本中,该步骤能改善分类结果并加快整个训练过程;随机高斯噪声同样也能帮助神经网络凸显图像特征,该步骤能还原真实情况下的背景噪声,有助于帮助模型学习噪声的特性,甚至能够抵抗现实中的噪声源;
(3)同类样本混合:自然环境下,经常会出现多只鸟同时鸣唱/鸣叫,为模拟这一真实情况,添加同一种鸟不同音频的频谱图,并随机组合;该步骤不会影响样本标签的分布,并且能够提高模型的收敛速度,增加识别精确度。
⑤为进一步增强信号部分灰度图像的视觉感知力,增加不同强度区域之间的对比度以提高识别性能,通过jet映射对其进行伪彩色处理。即量化频谱图的动态范围到不同区域,不同区域分别映射成红、绿、蓝三个单色图像,并对应高、中、和低功率频谱信息,红色表示最高能量的声音特性,即鸣唱/鸣叫特性;这一步骤的另一主要目的是转换灰度频谱图为三通道rgb图像,以作为后续神经网络的输入。最后将得到的三通道rgb子图像分为训练集和测试集,训练集和测试集的比例为4:1;
⑥以上为基于图像处理的鸟鸣声识别方法的主要内容,为体现出和现有技术特别是常规图像分类方法的优异性,本发明不对后续的神经网络做过多处理,采取视觉任务中常见的迁移学习方法;选用2017ilsvr竞赛中取得冠军的图像识别结构squeeze-and-excitationnetworks(senet),它通过对特征通道间的相关性进行建模,强化重要通道的特征,弱化非重要通道的特征,本发明认为这一思路吻合处理带噪鸟鸣声数据时的“突显鸟鸣声,抑制噪声”想法;
因此,最终选择混合模型se-resnext-50,对其进行微调,冻结神经网络的前几层权重,并结合需要识别鸟类的种数重新定义全连接层,得到预训练模型。通过将用于测试的80%的三通道rgb子图像输入到预训练模型中进行训练,保留神经网络参数得到识别模型,再将剩余的20%的三通道rgb子图像用于预测模型准确率,得到识别结果。
以上所述,仅为本发明较佳的具体实施方式,并非对本发明做任何形式上的限制,任何熟悉本专业的技术人员,在不脱离本发明技术方案范围内,可利用上述揭示的技术内容作出些许更动或修饰为等同变化的等效实施例,但凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作出的任何简单修改、等同变化与修饰,均仍属于本发明技术方案的范围内。
- 还没有人留言评论。精彩留言会获得点赞!